Download presentation
Presentation is loading. Please wait.

1
CS590M 2008 Fall: Paper Presentation
Deep Belief Nets Presenters: Sael Lee, Rongjing Xiang, Suleyman Cetintas, Youhan Fang Department of Computer Science, Purdue University Major reference paper: Hinton, G. E, Osindero, S., and Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural Computation, 18:
. A fast learning algorithm for deep belief nets. Neural Computation, 18:")
2
Outline Introduction Complementary prior Restricted Boltzmann machines
Deep Belief networks Applications Papers

3
What is Deep Belief Network(DBN)?
DBNs are stacks of restricted Boltzmann machines forming deep (multi-layer) architecture. 2000 top-level neurons 500 neurons 28x28 pixel image (784 neurons) h2 data h1 h3 RBM
 architecture top-level neurons. 500 neurons. 28x28 pixel image (784 neurons) h2. data. h1. h3. RBM.")
4
Deep Networks Why go deep?? Problem with deep?
Insufficient depth can require more computational elements, than architectures whose depth is matches to the task. Provide simpler more descriptive model of many problems. Problem with deep? Many cases, deep nets are hard to optimize. Neural Networks Deep Networks Deep Belief Nets.

5
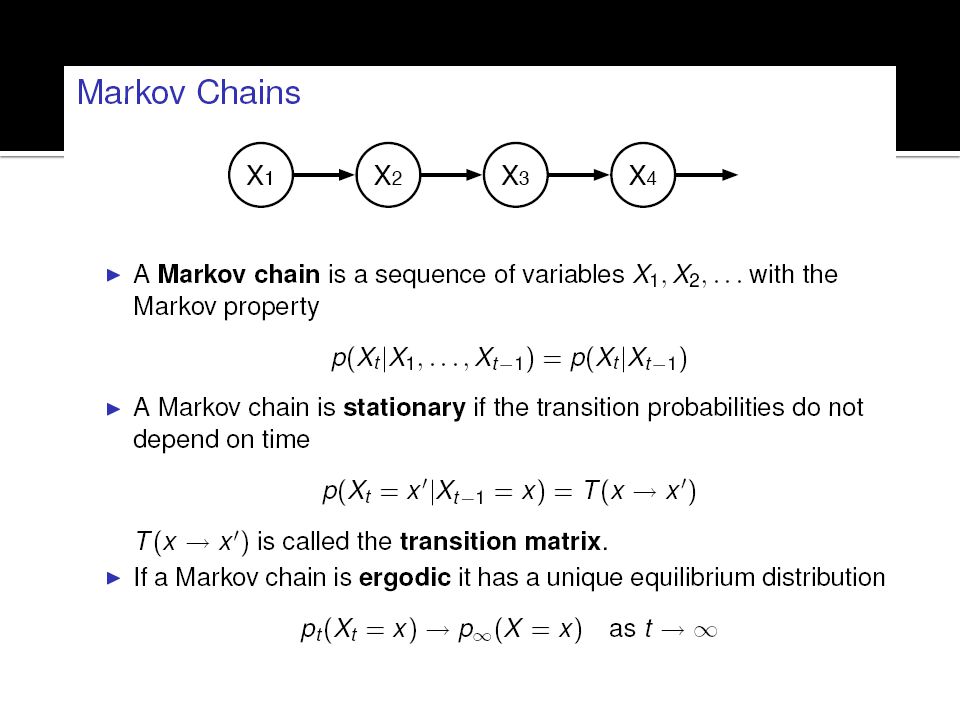
Belief Nets (Bayesian Network)
A belief net is a directed acyclic graph composed of stochastic variables. It is easy to generate an unbiased samples at the leaf nodes, so we can see what kinds of data the network believes in. It is hard to infer the posterior distribution over all possible configurations of hidden causes. (explaining away effect) It is hard to even get a sample from the posterior. So how can we learn deep belief nets that have millions of parameters? -> use Restrictive Boltzmann machines for each layer!! Stochastic hidden cause visible effect We will use nets composed of layers of stochastic binary variables with weighted connections
 It is hard to even get a sample from the posterior. So how can we learn deep belief nets that have millions of parameters -> use Restrictive Boltzmann machines for each layer!! Stochastic hidden cause. visible effect. We will use nets composed of layers of stochastic binary variables with weighted connections.")
6
Why it is usually very hard to learn belief nets one layer at a time
To learn W, we need the posterior distribution in the first hidden layer. Problem 1: The posterior is typically intractable because of “explaining away”. Problem 2: The posterior depends on the prior as well as the likelihood. So to learn W, we need to know the weights in higher layers, even if we are only approximating the posterior. All the weights interact. Problem 3: We need to integrate over all possible configurations of the higher variables to get the prior for first hidden layer. data hidden variables W prior likelihood

7
Energy-Based Models Deep Belief nets are composed of Restricted Boltzmann machines which are energy based models Energy based models define probability distribution through an energy function: Data log likelihood gradient “f” is the expert

8
Boltzmann machines One type of Generative Neural network that connect binary stochastic neurons using symmetric connections. b and c are bias of x and h, W,U,V are weights

9
Restricted Boltzmann machines (RBM)
hidden i j visible We restrict the connectivity to make learning easier. Only one layer of hidden units. We will deal with more layers later No connections between hidden units. In an RBM, the hidden units are conditionally independent given the visible states. So we can quickly get an unbiased sample from the posterior distribution when given a data-vector. This is a big advantage over directed belief nets Approximation of the log-likelihood gradient: Contrastive Divergence weight between units i and j Energy with configuration v on the visible units and h on the hidden units binary state of visible unit i binary state of hidden unit j

10
Deep Belief Networks Stacking RBMs to from Deep architecture
DBN with l layers of models the joint distribution between observed vector x and l hidden layers h. Learning DBN: fast greedy learning algorithm for constructing multi-layer directed networks on layer at a time v h1 h2 h3

11
Inference in Directed Belief Networks: Why Hard?
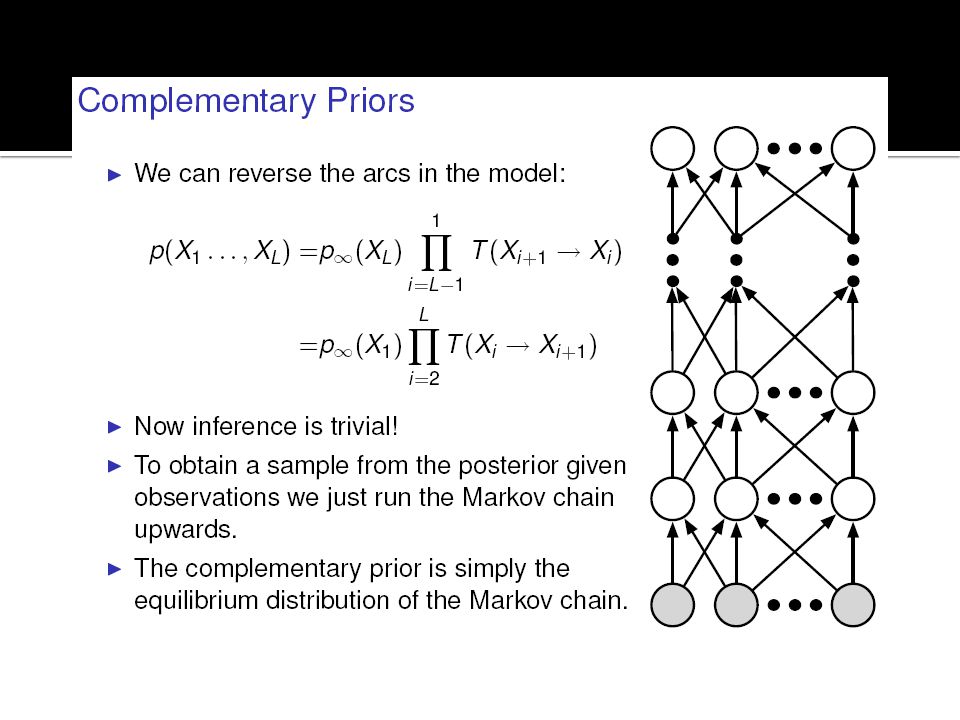
Explaining Away Posterior over Hidden Vars. <-> intractable Variational Methods approximate the true posterior and improve a lower bound on the log probability of the training data this works, but there is a better alternative: Eliminating Explaining Away in Logistic (Sigmoid) Belief Nets Posterior(non-indep) = prior(indep.) * likelihood (non-indep.) Eliminate Explaining Away by Complementary Priors Add extra hidden layers to create CP that has opposite correlations with the likelihood term, so (when likelihood is multiplied by the prior), post. will become factorial
 Belief Nets. Posterior(non-indep) = prior(indep.) * likelihood (non-indep.) Eliminate Explaining Away by Complementary Priors. Add extra hidden layers to create CP that has opposite correlations with the likelihood term, so (when likelihood is multiplied by the prior), post. will become factorial.")
22
An infinite sigmoid belief net equivalent to an RBM
h1 v0 h0 v2 h2 etc. The distribution generated by this infinite directed net with replicated weights is the equilibrium distribution for a compatible pair of conditional distributions: p(v|h) and p(h|v) that are both defined by W A top-down pass of the directed net = letting a Restricted Boltzmann Machine settle to equilibrium. So this infinite directed net defines the same distribution as an RBM.
 and p(h|v) that are both defined by W. A top-down pass of the directed net = letting a Restricted Boltzmann Machine settle to equilibrium. So this infinite directed net defines the same distribution as an RBM.")
23
Inference in a directed net with replicated weights
The variables in h0 are conditionally independent given v0. Inference is trivial. We just multiply v0 by W transpose (gives product of the likelihood term and the prior term). The model above h0 implements a complementary prior. Unlike other directed nets, we can sample from the true posterior dist over all of the hidden layers. Start from visible units, use W^T to infer factorial dist over each hidden unit Computing exact posterior dist in a layer of the infinite logistic belief net = each step of Gibbs sampling in RBM The Maximum Likelihood learning rule for the infinite logistic belief net with tied weights is the same with the learning rule of RBM Contrastive Divergence can be used instead of Maximum likelihood learning which is expensive RBM creates good generative models that can be fine-tuned v1 h1 v0 h0 v2 h2 etc. +
. The model above h0 implements a complementary prior. Unlike other directed nets, we can sample from the true posterior dist over all of the hidden layers. Start from visible units, use W^T to infer factorial dist over each hidden unit. Computing exact posterior dist in a layer of the infinite logistic belief net = each step of Gibbs sampling in RBM. The Maximum Likelihood learning rule for the infinite logistic belief net with tied weights is the same with the learning rule of RBM. Contrastive Divergence can be used instead of Maximum likelihood learning which is expensive. RBM creates good generative models that can be fine-tuned. v1. h1. v0. h0. v2. h2. etc. +")
24
Deep Belief Networks (DBN)
Joint distribution: Where

25
A Greedy Training Algorithm
Learn W0 assuming all the weight matrices are tied. Freeze W0 and use W0T to infer factorial approximate posterior distributions over the states of the variable in the first hidden layer. Keeping all the higher weight matrices tied to each other, but untied from W0, learn an RBM model of the higher-level “data” that was produced by using W0T to transform the original data.

26
Learning a deep directed network
etc. h2 First learn with all the weights tied This is exactly equivalent to learning an RBM Contrastive divergence learning is equivalent to ignoring the small derivatives contributed by the tied weights between deeper layers. v2 h1 v1 h0 h0 v0 v0

27
Then freeze the first layer of weights in both directions and learn the remaining weights (still tied together). This is equivalent to learning another RBM, using the aggregated posterior distribution of h0 as the data. etc. h2 v2 h1 v1 v1 h0 h0 v0

28
What happens when the weights in higher layers become different from the weights in the first layer?
The higher layers no longer implement a complementary prior. So performing inference using the frozen weights in the first layer is no longer correct. Using this incorrect inference procedure gives a variational lower bound on the log probability of the data. We lose by the slackness of the bound. The higher layers learn a prior that is closer to the aggregated posterior distribution of the first hidden layer. This improves the network’s model of the data. Hinton, Osindero and Teh (2006) prove that this improvement is always bigger than the loss.
 prove that this improvement is always bigger than the loss.")
29
Fine-tuning with a contrastive divergence version of the “wake-sleep” algorithm
After learning many layers of features, we can fine-tune the features to improve generation. 1. Do a stochastic bottom-up pass Adjust the top-down weights to be good at reconstructing the feature activities in the layer below. 2. Do a few iterations of sampling in the top level RBM Use CD learning to improve the RBM 3. Do a stochastic top-down pass Adjust the bottom-up weights to be good at reconstructing the feature activities in the layer above.

30
A neural model of digit recognition
2000 top-level neurons When training the top layer of weights, the labels were provided as part of the input 10 label neurons 500 neurons The labels were represented by turning on one unit in a ‘softmax’ group of 10 units: 500 neurons 28 x 28 pixel image

31
The result on MNIST Generative model based on RBM’s 1.25%
Support Vector Machine (Decoste et. al.) % Backprop with 1000 hiddens (Platt) ~1.6% Backprop with >300 hiddens ~1.6% K-Nearest Neighbor ~ 3.3% Training images: 60,000 Testing images: 10,000 The total training time: a week!
 1.4% Backprop with 1000 hiddens (Platt) ~1.6% Backprop with >300 hiddens ~1.6% K-Nearest Neighbor ~ 3.3% Training images: 60,000. Testing images: 10,000. The total training time: a week!")
32
Looking into the ‘mind’ of the machine Samples generated by letting the associative memory run with one label clamped.

33
Looking into the ‘mind’ of the machine Providing a random binary image as input

34
Reducing the Dimensionality of Data
They always looked like a really nice way to do non-linear dimensionality reduction: But it is very difficult to optimize deep autoencoders using backpropagation. We now have a much better way to optimize them: First train a stack of 4 RBM’s Then “unroll” them. Then fine-tune with backpropagation 1000 neurons 500 neurons 250 neurons 30 28x28

35
Learning Steps

36
Autoencoder vs. PCA

37
Autoencoder vs. LSA

38
Conclusion Restricted Boltzmann Machines provide a simple way to learn a layer of features without any supervision. Many layers of representation can be learned by treating the hidden states of one RBM as the visible data for training the next RBM This creates good generative models that can then be fine-tuned.

39
References G. Hinton, S. Osindero, Y. The, A fast learning algorithm for deep belief nets, Neural Computations, 2006. G. Hinton, R. Salakhutdinov, Reducing the dimensionality of data with neural networks, Science, 2006. Y. Bengio, Learning deep architectures for AI, 2007. M. Carreira-Perpinan, G. Hinton, On constrative divergence learning, AISTATS, 2005.

40
Thank you very much! And any questions?

Similar presentations


















![Stacking RBMs and Auto-encoders for Deep Architectures References:[Bengio, 2009], [Vincent et al., 2008] 2011/03/03 강병곤.](/13/3869655/big_thumb.jpg "Stacking RBMs and Auto-encoders for Deep Architectures References:[Bengio, 2009], [Vincent et al., 2008] 2011/03/03 강병곤.>")








