Download presentation
Presentation is loading. Please wait.

1
Training Fields Parallel Pipes Maximum Likelihood Classifier Class 11. Supervised Classification

2
Unsupervised classification is a process of grouping pixels that have similar spectral values and labeling each group with a class Definition Supervised classification is to classify an image using known spectral information for each cover type

3
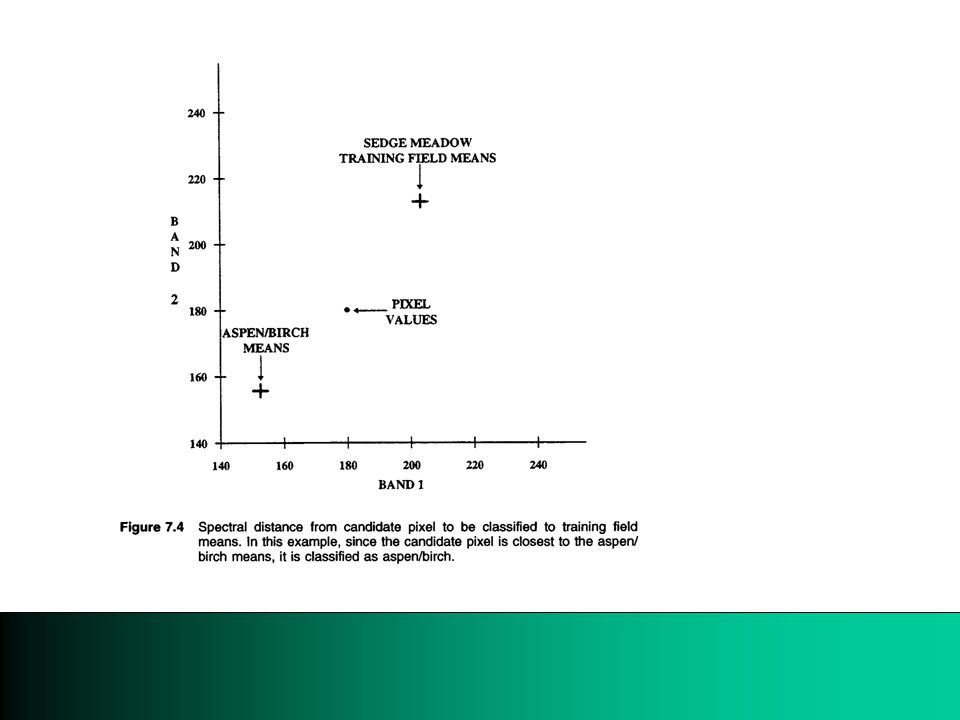
1.Training Fields (minimum spectral distance) A sample area for estimating representative spectral statistics, or spectral signatures. A seed-pixel approach can be used (page 137, Verbyla) according to the minimum distance classifier Verbyla 7.0
 according to the minimum distance classifier Verbyla 7.0.")
4
Two-band image AB: Aspen/Birch SM: Sedge/Medow

7
Lillisand & Keifer 7.0

10
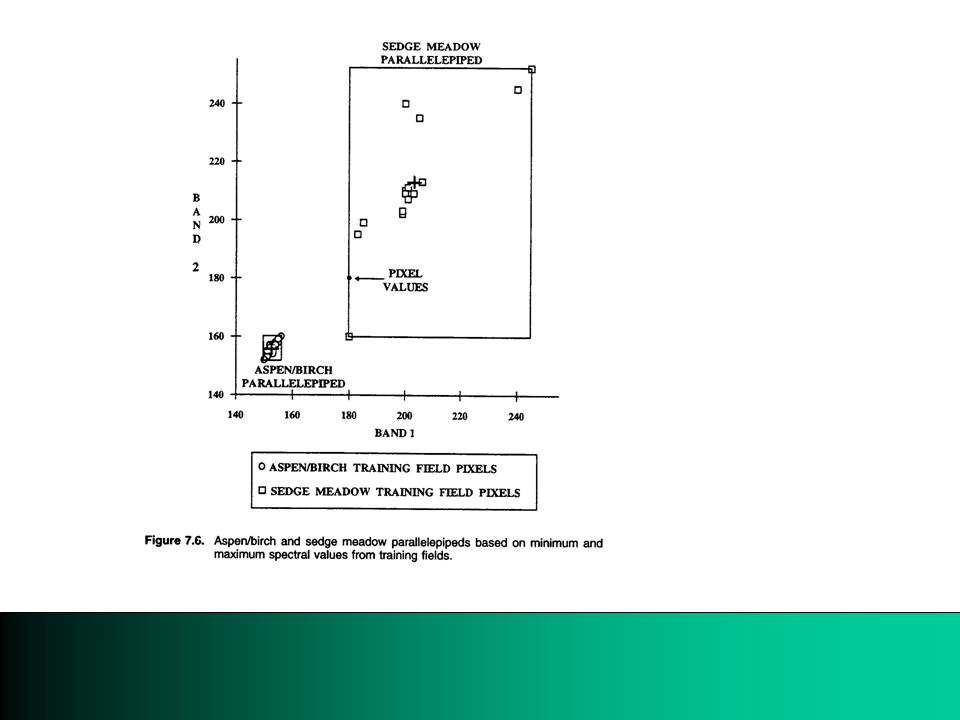
2. Parallelpiped classifier Define max/min for each band for each class If a class has normally distributed spectral values then 95% of pixels are within mean±2 standard deviations, i.e., Minimum = mean-2×SD Maximum = mean+2×SD Max/min can be adjusted according to needs

15
Step-wise parallelpipes

16
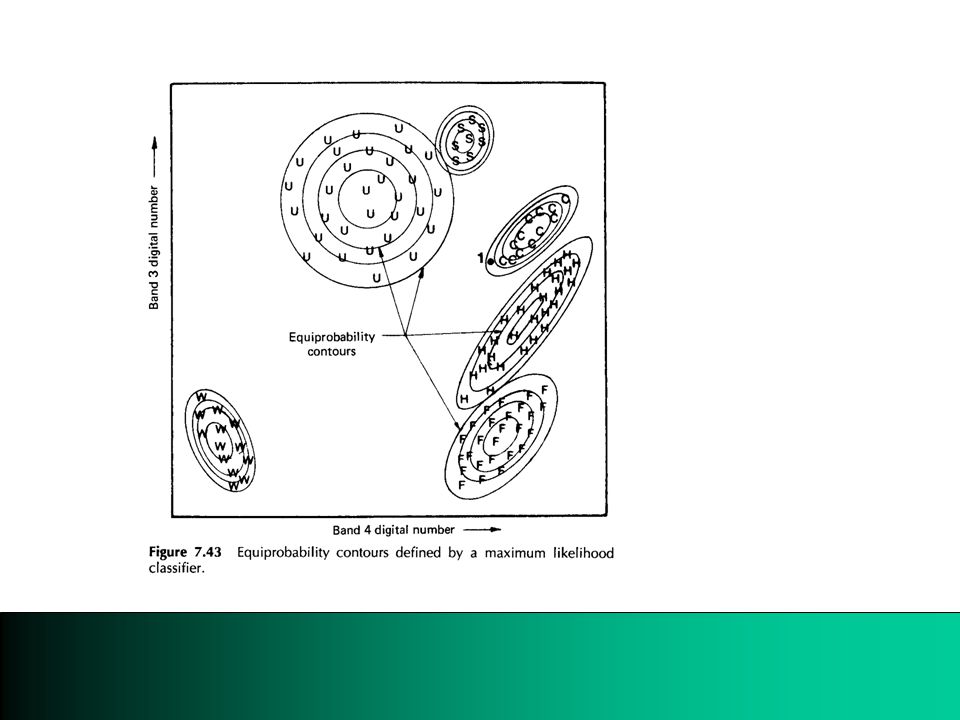
3. Maximum likelihood classifier From the training field, create contours of equal likelihood for each class. The highest likelihood for a candidate pixel determines the class of the pixel

17
Single-band example From training fields for cattail (CT) and smartweed (SW) Mean digital valueStandard deviation ( ) Number of pixels CT305100 SW205100
 and smartweed (SW) Mean digital valueStandard deviation ( ) Number of pixels CT SW205100")
22
Class 12 Assessment of classification Accuracy Error Matrix (confusion matrix) User’s Accuracy Producer’s Accuracy Overall Accuracy Kappa Statistics
 User’s Accuracy Producer’s Accuracy Overall Accuracy Kappa Statistics")
23
Error Matrix Ground Truth 12345Row total 140003043 2030120143 303250230 420050052 5000032 Column total 4233375335200 Predicted class Verbyla 8.0

24
Overall Classification Accuracy It is the total number of correct class predictions (the sum of the diagonal cells) divided by the total number of cells. In this case, it is (40+30+25+50+32)/200 =88%
/200 =88%.")
25
Producer’s and user’s accuracy by cover type class ClassProducer’s AccuracyUser’s Accuracy 140/42=95%40/43=93% 230/33=91%30/43=70% 325/37=68%25/30=83% 450/53=94%50/52=96% 532/35=91%32/32=100%

26
Kappa Statistic KHAT= Overall Classification Accuracy – Expected Classification Accuracy 1 – Expected Classification Accuracy The expected classification accuracy is the accuracy expected based on chance, Or the expected accuracy if we randomly assigned class values to each pixel. In this case (see the next slide), it is (1806+1419+1110+2756+1120)/40,000=21% In this case, KHAT=(0.88-0.21)/(1-0.21)=0.85
, it is ( )/40,000=21% In this case, KHAT=( )/(1-0.21)=0.85.")
27
Products for KHAT Ground Truth 12345Row total (error matrix) 1 18061419159122791505 43 2 18061419159122791505 43 3 1260990111015901050 30 4 21841716192427561820 52 5 13441056118416961120 32 Column total (error matrix) 4233375335 200 Predicted class
 Column total (error matrix) Predicted class")
Similar presentations