Download presentation
Presentation is loading. Please wait.

1
Stone Soup revisited: or the unity and disintegration of MT Yorick Wilks University of Sheffield www.dcs.shef.ac.uk/yorick www.dcs.shef.ac.uk/ ~ yorickwww.nlp.shef.ac.uk

2
Shameless plug: Nirenburg, S., Somers, H. and Wilks, Y.(eds.) (2002) Readings in Machine Translation. MIT Press: Cambridge MA. Wilks, Y. (late 2002) Machine Translation: its scope and limits. Cambridge Univ. Press: Cambridge UK and NYC.
 (2002) Readings in Machine Translation. MIT Press: Cambridge MA. Wilks, Y. (late 2002) Machine Translation: its scope and limits. Cambridge Univ. Press: Cambridge UK and NYC..")
3
Main points of the talk: The empirical-rational MT stand off in the early Nineties: what happened then and next? What was the ‘stone soup’ metaphor?: the piecemeal research agenda for the Nineties that took over all NLP. The underlying problem for statistical MT was ‘data sparseness’, but was the answer just more data? The web as ultimate data: gains and losses. Meanwhile, MT not only disintegrated as a task but itself became integrated into others! E.g. information retrieval, extraction, and question answering. Difficulty now of locating MT intellectually, but its continuing paramount importance to NLP.

4
Stone soup days (some who were there can’t remember the point of the metaphor!!): IBMs CANDIDE, a wholly statistical, corpus-based F-E E-F MT system, was evaluated against commercial systems and other DARPA ‘symbolic’ systems, e.g. PANGLOSS. CANDIDE never beat SYSTRAN over texts on which neither had been trained. The ‘stone soup’ analogy focussed on the way that Jelinek and Brown at IBM began to add such modules to CANDIDE which, were statisically based, but linguistically motivated: Hence, what was the statistical ‘magic stone’ that made the soup?? CANDIDE was composed of statistically-based modules (e.g. alignment) and more such modules, of greater complexity (e.g. wordsense disambiguation) became the NLP agenda But the component modules were not all evaluable against gold- standard data in the way MT was. Hence the problem of losing MT as an evaluation paradigm for NLP/CL.
 and more such modules, of greater complexity (e.g. wordsense disambiguation) became the NLP agenda But the component modules were not all evaluable against gold- standard data in the way MT was. Hence the problem of losing MT as an evaluation paradigm for NLP/CL..")
5
The barrier to further advance with the CANDIDE paradigm was data sparseness You can think about this as the way the repetitions of ngrams drop off with increasing n for a corpus of any imaginable size. A system that had noted COWS EAT and LIONS EAT would probably have no idea what to do with ELEPHANTS EAT (not to mention PRINTERS EAT PAPER). A standard way of putting this is that language consists of large numbers of rare events, but the scale of this is not always realised.
. A standard way of putting this is that language consists of large numbers of rare events, but the scale of this is not always realised..")
6
A home-grown example Suppose you ask the following: In the British National Corpus (BNC, 200m words), suppose we find all the finite verbs with objects and ask what proportion of them are unique in the corpus…………?
, suppose we find all the finite verbs with objects and ask what proportion of them are unique in the corpus…………")
7
85%! For quite other (lexical semantic) reasons, a student and I concentrated on those where both the verb and the object word were frequent (I.e. avoiding rare words which give separate problems--the issue here is only combinatorial!) We looked for ones not present at all in 1990, once in 1991-2, but occurring more than 8 times in 1993:
 reasons, a student and I concentrated on those where both the verb and the object word were frequent (I.e. avoiding rare words which give separate problems--the issue here is only combinatorial!) We looked for ones not present at all in 1990, once in , but occurring more than 8 times in 1993:.")
8
Books made:358, 15822 Eyes studied:4040, 483 Police closed:2551, 1774 Directors make:340, 3757 Eyes shadowed:4040, 21 Eyes lanced:4040, 19 Phone began:328, 3654 Body opened:1612, 2176 Enhancements include:20, 3660 Probe follows:78, 3581 Mouth became:816, 2816 Look says:644, 2976

9
What morals to draw here? The figures may suggest that even very very large corpora may not help in the way that a pure statistics method requires (Jelinek now recognises this). Note: Amsler’s recent call on the corpora list for a new approach to smaller corpora. It seems clear people are working with some classification that they cannot have derived purely bottom up from corpora. Google creates sets over the whole web of 2.5bn pages it uses: look at labs.google.com/sets and they arent all that good! Such empirical semantic set construction was a major research enterprise for Jelinek and Brown in 1990 Hence all the current efforts to use Wordnet (or to do more Stonesoupery by creating a Wordnet substitute on empirical principles). The web has provided a new market for MT but, as a vast corpus, it has not yet provided a solution to our problems in MT, given the tools we have Warning note on what may or may not help: look at the ‘success’ of WSD!
. Note: Amsler’s recent call on the corpora list for a new approach to smaller corpora. It seems clear people are working with some classification that they cannot have derived purely bottom up from corpora. Google creates sets over the whole web of 2.5bn pages it uses: look at labs.google.com/sets and they arent all that good. Such empirical semantic set construction was a major research enterprise for Jelinek and Brown in 1990 Hence all the current efforts to use Wordnet (or to do more Stonesoupery by creating a Wordnet substitute on empirical principles). The web has provided a new market for MT but, as a vast corpus, it has not yet provided a solution to our problems in MT, given the tools we have Warning note on what may or may not help: look at the ‘success’ of WSD!.")
10
Transition to looking at MT and near by methodologies (IE, IR etc.): but staying with very large corpora for the moment. Consider Greffenstette’s ‘vast lexicon’ concept. Example 1: you want to translate the collocation XY into another language, and have an appropriate bilingual dictionary with: n equivalents for X and m for Y giving mn combinations. You throw all the mn versions of X’Y’ at a large target language corpus and rank order the target collocations. Take the top one. This sounds like asking the audience in Who Wants To Be A Millionaire, but it works rather well! But the earlier 85% figure makes you think that maybe it shouldn’t OR that the BNC really is too small.

11
Example 2 I’m sure this one is Greffenstette’s (not the last!) Expand the last idea by storing from a vast corpus all forms of Agent-Action- Object triples (I.e. all examples of who does what to whom etc.). Use these to resolve ambiguity and interpretation problems of the kind that obsess people who are into concepts like ‘coercion’ ‘projection’, ‘metonymy’ etc. in lexical semantics. E.g. if in doubt what ‘my car drinks gasoline’ means, look at the things cars do with gasoline and take a guess. This isnt a very good algorithm, but it should stir memories of Bar Hillel’s (1959) argument against MT, namely that you couldn’t store all the facts in the world you would need to interpret sentences For me, of course, it stirs quite different memories of an empirical version of the old Preference Semantics (1967) notion of doing interpretation by means of a list of all possible interlingual Agent-Action-Object triples! (only I made the list up!)
. Use these to resolve ambiguity and interpretation problems of the kind that obsess people who are into concepts like ‘coercion’ ‘projection’, ‘metonymy’ etc. in lexical semantics. E.g. if in doubt what ‘my car drinks gasoline’ means, look at the things cars do with gasoline and take a guess. This isnt a very good algorithm, but it should stir memories of Bar Hillel’s (1959) argument against MT, namely that you couldn’t store all the facts in the world you would need to interpret sentences For me, of course, it stirs quite different memories of an empirical version of the old Preference Semantics (1967) notion of doing interpretation by means of a list of all possible interlingual Agent-Action-Object triples. (only I made the list up!).")
12
The man drove down the road in a car ((The man)(drove (down the road)(in a car)))) ((The man)(drove(down the road(in a car))))
(drove (down the road)(in a car)))) ((The man)(drove(down the road(in a car))))")
13
More on the Bar-Hillelish car/road example: Where one might hope to find that there are not ROADS IN CARS but there are CARS ON ROADS But, conversely and for identical syntactic structure in HE CANOED DOWN A RIVER IN BRAZIL There would be, in the supposed corpus, RIVERS IN BRAZIL but not BRAZIL IN RIVERS. So, may there be hope for a vast ‘lexicon of proto-facts’ derived from a corpus to settle questions of interpretation? Will there be enough in a corpus of weblike size? But so many webfacts are nonfacts (but maybe we need only their forms not their truth) Yet the above example suggests we made need negative facts as well, and there is an INFINITE number of them! Maybe no escape from some cognitive approach, or is this one too?
 Yet the above example suggests we made need negative facts as well, and there is an INFINITE number of them. Maybe no escape from some cognitive approach, or is this one too .")
14
OK, let’s now stand back and look at MT in a wider context: Well-known tasks that may be MT or involve MT Machine-aided translation (Kay’s defence of this as a separate task to be fused with editing technology; remember that came from his total pessimism about MT’s future!) Multilingual IE based on templates (Gaizauskas, Azzam, Humphries – templates as interlingua) Cross-language IR (CLIR): initially Salton using a thesaurus as interlingua between documents in different languages; later work used Machine Readable Bilingual Dictionaries (MRDs) to build lexical taxonomies in one language from another, and derived search clusters from bilingual texts.
 Multilingual IE based on templates (Gaizauskas, Azzam, Humphries – templates as interlingua) Cross-language IR (CLIR): initially Salton using a thesaurus as interlingua between documents in different languages; later work used Machine Readable Bilingual Dictionaries (MRDs) to build lexical taxonomies in one language from another, and derived search clusters from bilingual texts.")
15
CLIR and MT –One main difference is that CLIR can still be useful at low precision (recall more important) –But MT hard to use if alternatives are included in the output
 –But MT hard to use if alternatives are included in the output")
16
Forms of CLIR Multi/crosslingual IR without interlinguas (significant terms expanded, texts not necessarily aligned, result nearly as good as monolingual) Use of a priori resources: – MRDs for CLIR (Davis, Ballasteros and Croft) –Use of Wordnets (I.e EWN) for CLIR (original aim of EWN project!) Crosslingual Question Answering (QA) (not quite there yet, could be seen again as a form of template-as- interlingua, as in CLIE).
 Use of a priori resources: – MRDs for CLIR (Davis, Ballasteros and Croft) –Use of Wordnets (I.e EWN) for CLIR (original aim of EWN project!) Crosslingual Question Answering (QA) (not quite there yet, could be seen again as a form of template-as- interlingua, as in CLIE).")
17
Using existing MT systems for IR Using an MT system to determine terminology in unknown language with MT (Oh et al. 2001, J-K system) Use of strong established MT system for CLIR (e.g. SYSTRAN, Gachot et al. In Grefenstette (ed.) Cross Language Information Retrieval)
 Use of strong established MT system for CLIR (e.g. SYSTRAN, Gachot et al. In Grefenstette (ed.) Cross Language Information Retrieval).")
18
Partial MT processing for MRD construction Hierarchies in one language created from another (E-ESP, Guthrie, Farwell, Cowie, using LDOCE and Collins) Eurowordnet construction from bilingual and monolingual resources (easy and hard way! The easy way is straight lexical MT; the hard way is monolingual models plus the EWN interlingua)
.")
19
Vice-Versa: MT and IR metaphors changing places over ten years. Some developments in IR are now deemed “MT” by IR researchers. Treating retrieval of one string by another as a form of or use of an MT algorithm The last also applied to any use of alignment (or any of the IBM Jelinek/Brown tools), now used to mean “MT” by transfer when applied back to IR-like tasks More technically, the use of language models in IR (Ponte and Croft SIGIR 98, Laferty and Croft 2000) The reverse of what Sparck Jones predicted in her 2000 article in AIJournal on the use of IR in AI! (cf. IR as Statistical Translation, Berger and Laferty, 2001).
, now used to mean MT by transfer when applied back to IR-like tasks More technically, the use of language models in IR (Ponte and Croft SIGIR 98, Laferty and Croft 2000) The reverse of what Sparck Jones predicted in her 2000 article in AIJournal on the use of IR in AI. (cf. IR as Statistical Translation, Berger and Laferty, 2001)..")
20
Treating retrieval of one string by another as a form of an MT algorithm This metaphoric shift rests on using techniques used to develop MT by IBM (including alignment above); deeming pairs of strings in a retrieval relationship to be in some sense different languages. Extreme case: treating QA as a form of MT between two ‘languages’: FAQ questions and their answer (texts) taken to define a pair of languages in a translation relationship (Berger et al. 2000) “theoretical underpinning” is matching of language models i.e. what is the most likely query given this answer (cf. IBM/Jelinek----search for most probable source given the translation)..
 taken to define a pair of languages in a translation relationship (Berger et al. 2000) theoretical underpinning is matching of language models i.e. what is the most likely query given this answer (cf. IBM/Jelinek----search for most probable source given the translation)...")
21
Return of Garvin’s MT pivot in CLIR Metaphor strengthened by use of (old MT) notion of ‘pivot languages’ in IR. Multiple pivot languages to reach same target documents, thus strengthening retrieval (Gollins and Sanderson SIGIR 01) (parallel CLIR) Also Latvian-English and Latvian-Russian could in principle reach any EU language from e.g. Latvian via multiple CLIR pivot retrievals (sequential CLIR). You could do this with MT but would not call it a pivot approach (which by definition comes BETWEEN languages).(CLARITY project Sanderson and Gaizauskas: www.nlp.shef.ac.uk). This IR usage this differs from MT use where pivot was an interlingua not a language (except in BSO Esperanto case and Aymara) and was used once not iteratively
 (parallel CLIR) Also Latvian-English and Latvian-Russian could in principle reach any EU language from e.g. Latvian via multiple CLIR pivot retrievals (sequential CLIR). You could do this with MT but would not call it a pivot approach (which by definition comes BETWEEN languages).(CLARITY project Sanderson and Gaizauskas: This IR usage this differs from MT use where pivot was an interlingua not a language (except in BSO Esperanto case and Aymara) and was used once not iteratively.")
22
Looking in a liitle more detail (and plugging Sheffield stuff!) at work a little like MT in: Cross language IR IE and multilingual IE Question answering
 at work a little like MT in: Cross language IR IE and multilingual IE Question answering")
23
The parallel CLIR Idea Gollins and Sanderson (2001, www.ir.shef.ac.uk) Retrieve documents in another language even though bilingual dictionaries may be unavailable, sparse, incomplete etc. IDEA: Use different transitive routes and compare (merge) the results Hope to reduce the introduced error –Assume that errors are independent on the different routes –Assume translations in common are the “best” ones and thus eliminate “independent errors”
 the results Hope to reduce the introduced error –Assume that errors are independent on the different routes –Assume translations in common are the best ones and thus eliminate independent errors .")
24
Lexical Triangulation German English fisch Dutch Translate Spanish Translate vis pez, pescado Pitch, fish, tar, food fish pisces the fishes, pisces, fish fish fish, Merge

25
Concept Of Triangulation A simple noise or error cancellation technique A special case of the more general approach of using multiple evidence for retrieval –Singhal on spoken documents, Bartell on Monolingual and McCarley on CLIR The three languages used as pivots are not equally independent Expect Spanish - Dutch and Italian - Dutch to be better than Spanish - Italian.

26
Why better than Direct? Transitive translations improve translation recall (at the cost of precision) –0.54 (Direct) to 0.67 (Transitive) Loss of translation precision predominates 3 Way triangulation may eliminate sufficient erroneous translations to allow translation recall effect to show through.
 –0.54 (Direct) to 0.67 (Transitive) Loss of translation precision predominates 3 Way triangulation may eliminate sufficient erroneous translations to allow translation recall effect to show through..")
29
What is IE? getting information from content of huge document collections by computer at high speed looking not for key words but information that fits some tempate pattern or scenario. delivery of information as a structured database of the template fillers (usually pieces of text) classic IE phase is over and methods now have to be machine learning based (AMILCARE at Sheffield)
 classic IE phase is over and methods now have to be machine learning based (AMILCARE at Sheffield).")
30
The Sheffield LaSIE system (for IE) LaSIE was Sheffield’s MUC-6 entry and is one IE system under on-going development at Sheffield Distinctive features of LaSIE: use of a feature-based unification grammar with bottom-up chart parser to do partial parsing parsing of tags rather than lexical entries (no conventional lexicon for parsing) construction a semantic representation of all of the text reliance on a coreference algorithm and a domain model to extend semantic links not discovered during partial parsing
 LaSIE was Sheffield’s MUC-6 entry and is one IE system under on-going development at Sheffield Distinctive features of LaSIE: use of a feature-based unification grammar with bottom-up chart parser to do partial parsing parsing of tags rather than lexical entries (no conventional lexicon for parsing) construction a semantic representation of all of the text reliance on a coreference algorithm and a domain model to extend semantic links not discovered during partial parsing")
31
Challenges for IE: Multilinguality Most work to date on IE is English only – DARPA MUC’s. Exceptions: MUC-5 – included Japanese extraction task; MET – DARPA Multilingual Extraction Task – named entity recognition in Chinese, Japanese and Spanish; recent CEC LE projects: ECRAN, AVENTINUS, SPARKLE, TREE, FACILE. French AUPELF ARC-4 – potential IE evaluation exercise for French systems Japanese Information Retrieval and Extraction Exercise (IREX) – IR and NE evaluation
 – IR and NE evaluation.")
32
What is a Multilingual IE System? Two possibilities: 1.An IE system that does monolingual IE in multiple languages. Monolingual IE: IE where source language and extraction language are the same. Extraction language: language of template fills and/or of summaries that an IE system generates. 2.An IE system that does cross-lingual IE. Cross-lingual IE (CLIE): IE where source language and extraction language differ.
: IE where source language and extraction language differ..")
36
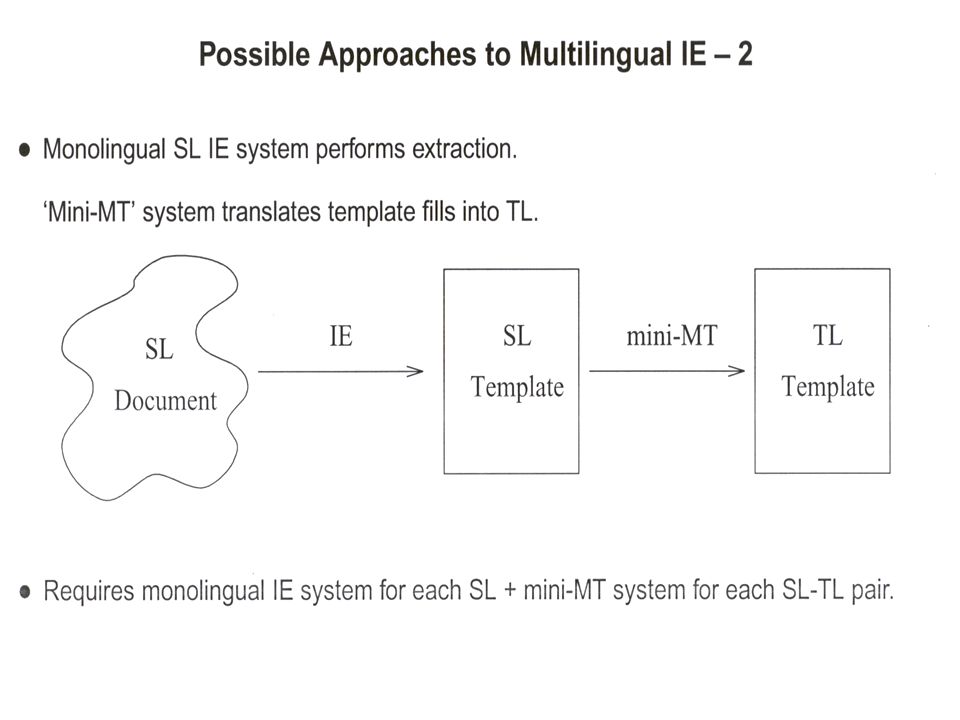
An Architecture for Multilingual IE Design objectives for a multilingual IE system: maximise reuse of algorithmic and domain model components; minimise language-specific mechanisms and data resources. Given these requirements we have opted for approach 3. Advantages: new languages can be added independently (no need to consider language pairs); single language-independent conceptual model of domain. Is it possible ? …
; single language-independent conceptual model of domain. Is it possible . ….")
39
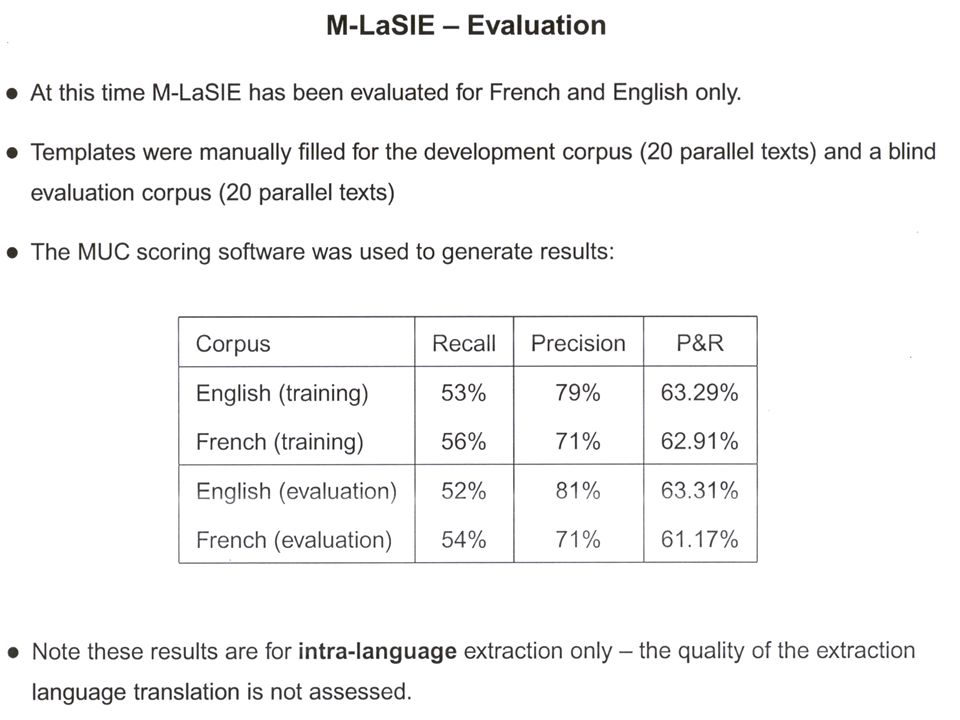
M-LaSIE – Development M-LaSIE has been developed for French, English and Spanish. English Same modules as the LaSIE system; all developed at Sheffield, except the Brill part-of-speech tagger. French Morpho-tokenizer module developed at U. de Fribourg; other modules at Sheffield. Spanish Tokeniser and parser developed at UPC, Barcelona; these and morphological analyser and tagger integrated into GATE (www.gate.ac.uk) by UPC; other modules at Sheffield.

40
QA-LaSIE (Gaizauskas) Derived from LaSIE: Large Scale Information Extraction System LaSIE developed to participate in the DARPA Message Understanding Conferences (MUC-6/7) –Template filling (elements, relations, scenarios) –Named Entity recognition –Coreference identification QA-LaSIE is a pipeline of 9 component modules – first 8 are borrowed (with minor modifications) from LaSIE The question document and each candidate answer document pass through all nine components Key difference between MUC and QA task: IE template filling tasks are domain-specific; QA is domain-independent
 Derived from LaSIE: Large Scale Information Extraction System LaSIE developed to participate in the DARPA Message Understanding Conferences (MUC-6/7) –Template filling (elements, relations, scenarios) –Named Entity recognition –Coreference identification QA-LaSIE is a pipeline of 9 component modules – first 8 are borrowed (with minor modifications) from LaSIE The question document and each candidate answer document pass through all nine components Key difference between MUC and QA task: IE template filling tasks are domain-specific; QA is domain-independent")
41
TREC-9 250 Byte Runs

42
The TREC QA Track: Task Definition (TREC 8/9) Inputs: –4GB newswire texts (from the TREC text collection) –File of natural language questions (200 TREC-8/700 TREC-9) e.g. e.g. Where is the Taj Mahal? How tall is the Eiffel Tower? Who was Johnny Mathis’ high school track coach? Outputs: –Five ranked answers per question, including pointer to source document 50 byte category 250 byte category –Up to two runs per category per site Limitations: –Each question has an answer in the text collection –Each answer is a single literal string from a text (no implicit or multiple answers)
.")
43
Sheffield QA System Architecture Overall objective is to use: IR system as fast filter to select small set of documents with high relevance to query from the initial, large text collection IE system to perform slow, detailed linguistic analysis to extract answer from limited set of docs proposed by IR system

44
QA in Detail (1): Question Parsing Phrase structure rules are used to parse different question types and produce a quasi-logical form (QLF) representation which contains: a qvar predicate identifying the sought entity a qattr predicate identifying the property or relation whose value is sought for the qvar (this may not always be present.) Q:Who released the internet worm? qvar(e1), qattr(e1,name), person(e1), release(e2), lsubj(e2,e1), lobj(e2,e3) worm(e3), det(e3,the), name(e4,’Internet’), qual(e3,e4) Question QLF:
, qattr(e1,name), person(e1), release(e2), lsubj(e2,e1), lobj(e2,e3) worm(e3), det(e3,the), name(e4,’Internet’), qual(e3,e4) Question QLF:.")
45
Question Answering in Detail: An Example Q:Who released the internet worm?A:Morris testified that he released the internet worm… Question QLF: qvar(e1), qattr(e1,name), person(e1), release(e2), lsubj(e2,e1), lobj(e2,e3) worm(e3), det(e3,the), name(e4,’Internet’), qual(e3,e4) Total (normalized): 0.97 person(e1), name(e1,’Morris'), testify(e2), lsubj(e2,e1), lobj(e2,e6), proposition(e6), main_event(e6,e3), release(e3), pronoun(e4,he), lsubj(e3,e4), worm(e5), lobj(e3,e5) Answer QLF: Shef50ea: “Morris” Shef50:“Morris testified that he released the internet wor” Shef250: “Morris testified that he released the internet worm …” Shef250p: “… Morris testified that he released the internet worm …” Answers: Sentence Score: 2 Entity Score (e1): 0.91
, qattr(e1,name), person(e1), release(e2), lsubj(e2,e1), lobj(e2,e3) worm(e3), det(e3,the), name(e4,’Internet’), qual(e3,e4) Total (normalized): 0.97 person(e1), name(e1,’Morris ), testify(e2), lsubj(e2,e1), lobj(e2,e6), proposition(e6), main_event(e6,e3), release(e3), pronoun(e4,he), lsubj(e3,e4), worm(e5), lobj(e3,e5) Answer QLF: Shef50ea: Morris Shef50: Morris testified that he released the internet wor Shef250: Morris testified that he released the internet worm … Shef250p: … Morris testified that he released the internet worm … Answers: Sentence Score: 2 Entity Score (e1): 0.91")
46
Conclusions on QA Our TREC-9 test results represent significant drop wrt to best training results –But, much better than TREC-8, vindicating the “looser” approach to matching answers QA-LaSIE scores better than Okapi-baseline, suggesting NLP is playing a significant role –But, a more intelligent baseline (e.g. selecting answer passages based on word overlap with query) might prove otherwise Computing confidence measures provides some support that our objective scoring function is sensible. They can be used for –User support –Helping to establish thresholds for “no answer” response –Tuning parameters in the scoring function (ML techniques?)
 might prove otherwise Computing confidence measures provides some support that our objective scoring function is sensible. They can be used for –User support –Helping to establish thresholds for no answer response –Tuning parameters in the scoring function (ML techniques ).")
47
QA and multilinguality Little cross/multi lingual QA has been done but it will soon appear, as has CLIE and CLIR It is also a form of MT, and has already been subjected monolingually to pure IR machine learning (Berger et al. 2000) using their new ‘IR is MT’ paradigm If Qs and As are actually in different languages it will reinforce their metaphor that they are monlingually as well!!! However, progress in CLIR and CLIE suggest this will be a largely symbolic task (even if large chunks can be machine learned). NO CONTRADICTION THERE!!
 using their new ‘IR is MT’ paradigm If Qs and As are actually in different languages it will reinforce their metaphor that they are monlingually as well!!. However, progress in CLIR and CLIE suggest this will be a largely symbolic task (even if large chunks can be machine learned). NO CONTRADICTION THERE!!.")
48
IE, QA, IR, MT form a complex of information access methods but which are now hard to distinguish methodologically IR is normally done before IE in an application to cut down text searched. The database that IE produces can then be searched with IR or QA – or can be translated by MT MT and IR now have very similar cross-language methodologies, and QA and summarization are close. But all these are real tasks (with associated and different evaluation methods), which is not true of all the partial modules that spread in the Stone Soup (WSD, syntax parsing etc.)
, which is not true of all the partial modules that spread in the Stone Soup (WSD, syntax parsing etc.).")
49
THE END

Similar presentations






 Learning for Semantic Parsing Advisor: Hsin-His.>")








 – Corpora – Treebanks Secondary resources – Designed for a.>")







, or Computational Linguistics, is concerned with theoretical.>")
