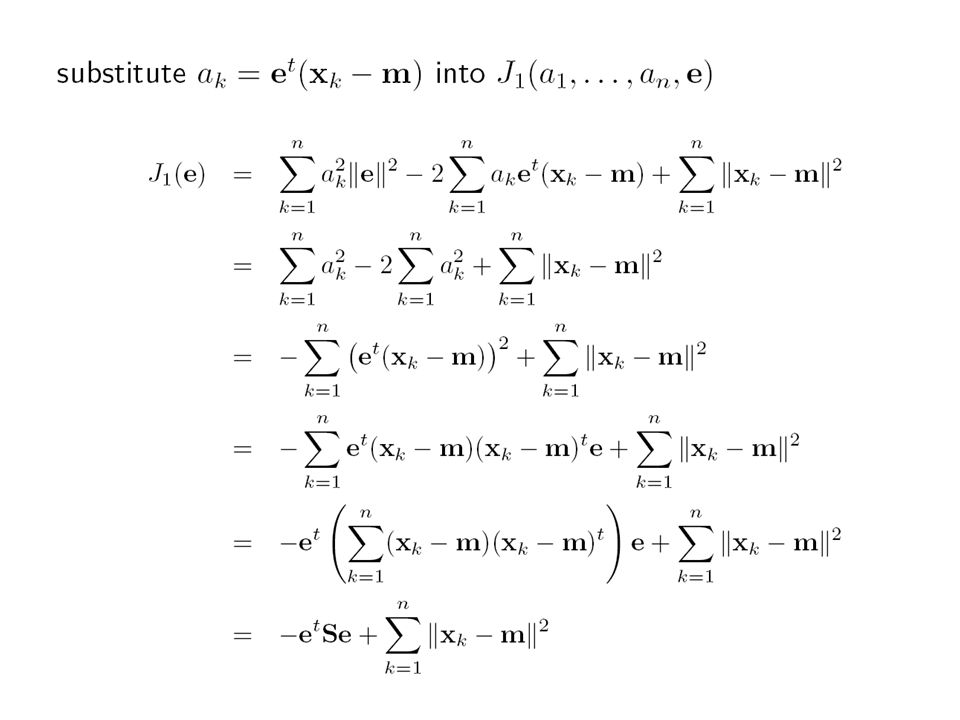Download presentation
Presentation is loading. Please wait.

1
Linear Regression and least square error solution

2
What is “Linear”? Remember this: Y=mX+B? B m

3
Simple linear regression The linear regression model: Love of Math = 5 +.01*math SAT score interceptslope P=.22; not significant

4
Prediction If you know something about X, this knowledge helps you predict something about Y. (Sound familiar?…sound like conditional probabilities?)
.")
5
EXAMPLE The distribution of baby weights at Stanford ~ N(3400, 360000) Your “Best guess” at a random baby’s weight, given no information about the baby, is what? 3400 grams But, what if you have relevant information? Can you make a better guess?

6
Predictor variable X=gestation time Assume that babies that gestate for longer are born heavier, all other things being equal. Pretend (at least for the purposes of this example) that this relationship is linear. Example: suppose a one-week increase in gestation, on average, leads to a 100-gram increase in birth- weight
 that this relationship is linear. Example: suppose a one-week increase in gestation, on average, leads to a 100-gram increase in birth- weight.")
7
Y depends on X Y=birth- weight (g) X=gestation time (weeks) Best fit line is chosen such that the sum of the squared (why squared?) distances of the points (Yi’s) from the line is minimized: Or mathematically… (remember max and mins from calculus)… Derivative[ (Yi-(mx+b)) 2 ]=0
![Y depends on X Y=birth- weight (g) X=gestation time (weeks) Best fit line is chosen such that the sum of the squared (why squared ) distances of the points (Yi’s) from the line is minimized: Or mathematically… (remember max and mins from calculus)… Derivative[ (Yi-(mx+b)) 2 ]=0](http://images.slideplayer.com/8/2342952/slides/slide_7.jpg "Y depends on X Y=birth- weight (g) X=gestation time (weeks) Best fit line is chosen such that the sum of the squared (why squared ) distances of the points (Yi’s) from the line is minimized: Or mathematically… (remember max and mins from calculus)… Derivative[ (Yi-(mx+b)) 2 ]=0")
8
But… Note that not every Y-value (Y i ) sits on the line. There’s variability. Y=baby weights (g) X=gestation times (weeks) 203040 Y/X=40 weeks ~ N(4000, 2 ) Y/X=30 weeks ~ N(3000, 2 ) Y/X=20 weeks ~ N(2000, 2 )
 X=gestation times (weeks) Y/X=40 weeks ~ N(4000, 2 ) Y/X=30 weeks ~ N(3000, 2 ) Y/X=20 weeks ~ N(2000, 2 ).")
9
Mean values fall on the line E(Y/X=40 weeks)=4000 E(Y/X=30 weeks)=3000 E(Y/X=20 weeks)=2000 E(Y/X)= Y/X = 100 grams/week*X weeks
=4000 E(Y/X=30 weeks)=3000 E(Y/X=20 weeks)=2000 E(Y/X)= Y/X = 100 grams/week*X weeks")
10
Linear Regression Model Y’s are modeled… Y i = 100*X + random error i Follows a normal distribution Fixed – exactly on the line

11
Assumptions (or the fine print) Linear regression assumes that… – 1. The relationship between X and Y is linear – 2. Y is distributed normally at each value of X – 3. The variance of Y at every value of X is the same (homogeneity of variances) Why? The math requires it—the mathematical process is called “least squares” because it fits the regression line by minimizing the squared errors from the line (mathematically easy, but not general—relies on above assumptions).
 Why. The math requires it—the mathematical process is called least squares because it fits the regression line by minimizing the squared errors from the line (mathematically easy, but not general—relies on above assumptions)..")
12
Non-homogenous variance Y=birth- weight (100g) X=gestation time (weeks)
 X=gestation time (weeks)")
13
Least squares estimation ** Least Squares Estimation A little calculus…. What are we trying to estimate? β, the slope, from What’s the constraint? We are trying to minimize the squared distance (hence the “least squares”) between the observations themselves and the predicted values, or (also called the “residuals”, or left-over unexplained variability) Differencei = yi – (βx + α) Differencei 2 = (yi – (βx + α)) 2 Find the β that gives the minimum sum of the squared differences. How do you maximize a function? Take the derivative; set it equal to zero; and solve. Typical max/min problem from calculus…. From here takes a little math trickery to solve for β…
 between the observations themselves and the predicted values, or (also called the residuals , or left-over unexplained variability) Differencei = yi – (βx + α) Differencei 2 = (yi – (βx + α)) 2 Find the β that gives the minimum sum of the squared differences. How do you maximize a function. Take the derivative; set it equal to zero; and solve. Typical max/min problem from calculus…. From here takes a little math trickery to solve for β….")
14
Residual Residual = observed value – predicted value At 33.5 weeks gestation, predicted baby weight is 3350 grams 33.5 weeks This baby was actually 3380 grams. His residual is +30 grams: 3350 grams

15
Y=baby weights (g) X=gestation times (weeks) 203040 The standard error of Y given X is the average variability around the regression line at any given value of X. It is assumed to be equal at all values of X. Sy/x

16
Residual Analysis: check assumptions The residual for observation i, e i, is the difference between its observed and predicted value Check the assumptions of regression by examining the residuals – Examine for linearity assumption – Examine for constant variance for all levels of X (homoscedasticity) – Evaluate normal distribution assumption – Evaluate independence assumption Graphical Analysis of Residuals – Can plot residuals vs. X

17
Residual Analysis for Linearity Not Linear Linear x residuals x Y x Y x Slide from: Statistics for Managers Using Microsoft® Excel 4th Edition, 2004 Prentice-Hall

18
Residual Analysis for Homoscedasticity Non-constant variance Constant variance xx Y x x Y residuals Slide from: Statistics for Managers Using Microsoft® Excel 4th Edition, 2004 Prentice-Hall

19
Residual Analysis for Independence Not Independent Independent X X residuals X Slide from: Statistics for Managers Using Microsoft® Excel 4th Edition, 2004 Prentice-Hall

20
Other types of multivariate regression Multiple linear regression is for normally distributed outcomes Logistic regression is for binary outcomes Cox proportional hazards regression is used when time-to-event is the outcome

21
Principal Component Analysis (PCA) Given: n d-dimensional points x1,..., xn Goal: find the “right” features from the data
 Given: n d-dimensional points x1,..., xn Goal: find the right features from the data")
22
Zero-D Representation Task: find x0 to “represent” x1,..., xn Criterion: find x0 such that the sum of the squared distances between x0 and the various xk is as small as possible the “best” zero-dimensional representation of the data set is the sample mean

23
One-D Representation Consider: represent the set of points by a line through m x = m+ ae, e: unit vector along the line

24
Cont’d

27
Finding eigenvector problem

28
Geometrical Interpretation

31
Finding least square error solution Finding the direction such that the least square errors is minimized Solution: Eigenvector with smallest eigenvalue Minimize

32
Solving big matrix systems Ax=b You can use Matlab’s \ – But not very scalable There is also sparse matrix library in C\C++, e.g. TAUCS, that provides routine for solving this sparse linear system Good News ! You can use existing library to avoid the ``trouble’’ implementation of linear equation solver But, you need to understand what is happening within the linear solver 32

33
Conjugate gradient “The Conjugate Gradient Method is the most prominent iterative method for solving sparse systems of linear equations. Unfortunately, many textbook treatments of the topic are written with neither illustrations nor intuition, and their victims can be found to this day babbling senselessly in the corners of dusty libraries. For this reason, a deep, geometric understanding of the method has been reserved for the elite brilliant few who have painstakingly decoded the mumblings of their forebears. Nevertheless, the Conjugate Gradient Method is a composite of simple, elegant ideas that almost anyone can understand. Of course, a reader as intelligent as yourself will learn them almost effortlessly.” 33

34
Ax=b A is square, symmetric and positive-definite When the A is dense, you’re stuck, use backsubstitution When A is sparse, iterative techniques (such as Conjugate Gradient) are faster and more memory efficient Simple example: (Yeah yeah, it’s not sparse) 34
 are faster and more memory efficient Simple example: (Yeah yeah, it’s not sparse) 34")
35
Turn Ax=b into a minimization problem Minimization is more logical to analyze iteration (gradient ascent/descent) Quadratic form – c can be ignored because we want to minimize Intuition: – the solution of a linear system is always the intersection of n hyperplanes – Take the square distance to them – A needs to be positive-definite so that we have a nice parabola 35
 Quadratic form – c can be ignored because we want to minimize Intuition: – the solution of a linear system is always the intersection of n hyperplanes – Take the square distance to them – A needs to be positive-definite so that we have a nice parabola 35")
36
Gradient of the quadratic form 36 since And since A is symmetric Not surprising: we turned Ax=b into the quadratic minimization (if A is not symmetric, conjuagte gradient finds solution for –Not our image gradient! –Multidimensional gradient (as many dim as rows in matrix)
.")
37
Steepest descent/ascent Pick gradient direction Find optimum in this direction 37 Gradient direction Energy along the gradient

38
Residual At iteration i, we are at a point x(i) Residual r(i)=b-Ax(i) Cool property of quadratic form: residual = - gradient 38
 Residual r(i)=b-Ax(i) Cool property of quadratic form: residual = - gradient 38")
39
Behavior of gradient descent Zigzag or goes straight depending if we’re lucky – Ends up doing multiple steps in the same direction 39

40
Conjugate gradient Smarter choice of direction – Ideally, step directions should be orthogonal to one another (no redundancy) – But tough to achieve – Next best thing: make them A-orthogonal (conjugate) That is, orthogonal when transformed by A: 40
 – But tough to achieve – Next best thing: make them A-orthogonal (conjugate) That is, orthogonal when transformed by A: 40")
41
Conjugate gradient For each step: – Take the residual (gradient) – Make it A-orthogonal to the previous ones – Find minimum along this direction Plus life is good: – In practice, you only need the previous one – You can show that the new residual r(i+1) is already A-orthogonal to all previous directions p but p(i) 41
 – Make it A-orthogonal to the previous ones – Find minimum along this direction Plus life is good: – In practice, you only need the previous one – You can show that the new residual r(i+1) is already A-orthogonal to all previous directions p but p(i) 41")
Similar presentations