Download presentation
Presentation is loading. Please wait.

2
Linear Least Squares Approximation By Kristen Bauer, Renee Metzger, Holly Soper, Amanda Unklesbay

3
Linear Least Squares Is the line of best fit for a group of points It seeks to minimize the sum of all data points of the square differences between the function value and data value. It is the earliest form of linear regression

4
Gauss and Legendre The method of least squares was first published by Legendre in 1805 and by Gauss in 1809. Although Legendre’s work was published earlier, Gauss claims he had the method since 1795. Both mathematicians applied the method to determine the orbits of bodies about the sun. Gauss went on to publish further development of the method in 1821.

5
Example Consider the points (1,2.1), (2,2.9), (5,6.1), and (7,8.3) with the best fit line f(x) = 0.9x + 1.4 The squared errors are: x 1 =1f(1)=2.3y 1 =2.1 e 1 = (2.3 – 2.1)² =.04 x 2 =2f(2)=3.2y 2 =2.9 e 2 = (3.2 – 2.9)² =. 09 x 3 =5f(5)=5.9y 3 =6.1 e 3 = (5.9 – 6.1)² =.04 x 4 =7f(7)=7.7y 4 =8.3 e 4 = (7.7 – 8.3)² =.36 So the total squared error is.04 +.09 +.04 +.36 =.53 By finding better coefficients of the best fit line, we can make this error smaller…
=5.9y 3 =6.1 e 3 = (5.9 – 6.1)² =.04 x 4 =7f(7)=7.7y 4 =8.3 e 4 = (7.7 – 8.3)² =.36 So the total squared error is =.53 By finding better coefficients of the best fit line, we can make this error smaller….")
6
We want to minimize the vertical distance between the point and the line. E = (d 1 )² + (d 2 )² + (d 3 )² +…+(d n )² for n data points E = [f(x 1 ) – y 1 ]² + [f(x 2 ) – y 2 ]² + … + [f(x n ) – y n ]² E = [mx 1 + b – y 1 ]² + [mx 2 + b – y 2 ]² +…+ [mx n + b – y n ]² E= ∑( mx i + b – y i )²
² + (d 2 )² + (d 3 )² +…+(d n )² for n data points E = [f(x 1 ) – y 1 ]² + [f(x 2 ) – y 2 ]² + … + [f(x n ) – y n ]² E = [mx 1 + b – y 1 ]² + [mx 2 + b – y 2 ]² +…+ [mx n + b – y n ]² E= ∑( mx i + b – y i )².")
7
E must be MINIMIZED! How do we do this? E = ∑(mx i + b – y i )² Treat x and y as constants, since we are trying to find m and b. So…PARTIALS! E/ m = 0 and E/ b = 0 But how do we know if this will yield maximums, minimums, or saddle points?
² Treat x and y as constants, since we are trying to find m and b. So…PARTIALS. E/ m = 0 and E/ b = 0 But how do we know if this will yield maximums, minimums, or saddle points .")
8
Minimum Point Maximum Point Saddle Point

9
Minimum! Since the expression E is a sum of squares and is therefore positive (i.e. it looks like an upward paraboloid), we know the solution must be a minimum. We can prove this by using the 2 nd Partials Derivative Test.
, we know the solution must be a minimum. We can prove this by using the 2 nd Partials Derivative Test..")
10
2 nd Partials Test And form the discriminant D = AC – B 2 1) If D < 0, then (x 0,y 0 ) is a saddle point. 2) If D > 0, then f takes on A local minimum at (x 0,y 0 ) if A > 0 A local maximum at (x 0,y 0 ) if A < 0 Suppose the gradient of f(x 0,y 0 ) = 0. (An instance of this is E/ m = E/ b = 0.) We set
 If D > 0, then f takes on A local minimum at (x 0,y 0 ) if A > 0 A local maximum at (x 0,y 0 ) if A < 0 Suppose the gradient of f(x 0,y 0 ) = 0. (An instance of this is E/ m = E/ b = 0.) We set.")
11
Calculating the Discriminant

12
1) If D < 0, then (x 0,y 0 ) is a saddle point. 2) If D > 0, then f takes on A local minimum at (x 0,y 0 ) if A > 0 A local maximum at (x 0,y 0 ) if A < 0 Now D > 0 by an inductive proof showing that Those details are not covered in this presentation. We know A > 0 since A = 2 ∑ x 2 is always positive (when not all x’s have the same value).
 If D > 0, then f takes on A local minimum at (x 0,y 0 ) if A > 0 A local maximum at (x 0,y 0 ) if A < 0 Now D > 0 by an inductive proof showing that Those details are not covered in this presentation. We know A > 0 since A = 2 ∑ x 2 is always positive (when not all x’s have the same value)..")
13
Therefore… Setting E/m and E/b equal to zero will yield two minimizing equations of E, the sum of the squares of the error. Thus, the linear least squares algorithm (as presented) is valid and we can continue.
 is valid and we can continue..")
14
E = ∑(mx i + b – y i )² is minimized (as just shown) when the partial derivatives with respect to each of the variables is zero. ie: E/ m = 0 and E/ b = 0 E/ b = ∑2(mx i + b – y i ) = 0set equal to 0 m∑x i + ∑b = ∑y i mSx + bn = Sy E/ m = ∑2x i (mx i + b – y i ) = 2∑(mx i ² + bx i – x i y i ) = 0 m∑x i ² + b∑x i = ∑x i y i mSxx + bSx = Sxy NOTE: ∑x i = Sx∑y i = Sy∑x i ² = Sxx∑x i y i = SxSy
 = 0set equal to 0 m∑x i + ∑b = ∑y i mSx + bn = Sy E/ m = ∑2x i (mx i + b – y i ) = 2∑(mx i ² + bx i – x i y i ) = 0 m∑x i ² + b∑x i = ∑x i y i mSxx + bSx = Sxy NOTE: ∑x i = Sx∑y i = Sy∑x i ² = Sxx∑x i y i = SxSy.")
15
Next we will solve the system of equations for unknowns m and b: nmSxx + bnSx = nSxy Multiply by n mSxSx + bnSx = SySx Multiply by Sx nmSxx – mSxSx = nSxy – SySx Subtract m(nSxx – SxSx) = nSxy – SySx Factor m Solving for m…
 = nSxy – SySx Factor m Solving for m…")
16
Next we will solve the system of equations for unknowns m and b: mSxSxx + bSxSx = SxSxy Multiply by Sx mSxSxx + bnSxx = SySxx Multiply by Sxx bSxSx – bnSxx = SxySx – SySxx Subtract b(SxSx – nSxx) = SxySx – SySxx Solve for b Solving for b…
 = SxySx – SySxx Solve for b Solving for b…")
17
Example: Find the linear least squares approximation to the data: (1,1), (2,4), (3,8) Sx = 1+2+3= 6 Sxx = 1²+2²+3² = 14 Sy = 1+4+8 = 13 Sxy = 1(1)+2(4)+3(8) = 33 n = number of points = 3 The line of best fit is y = 3.5x – 2.667 Use these formulas:
, (2,4), (3,8) Sx = 1+2+3= 6 Sxx = 1²+2²+3² = 14 Sy = = 13 Sxy = 1(1)+2(4)+3(8) = 33 n = number of points = 3 The line of best fit is y = 3.5x – Use these formulas:")
18
Line of best fit: y = 3.5x – 2.667

19
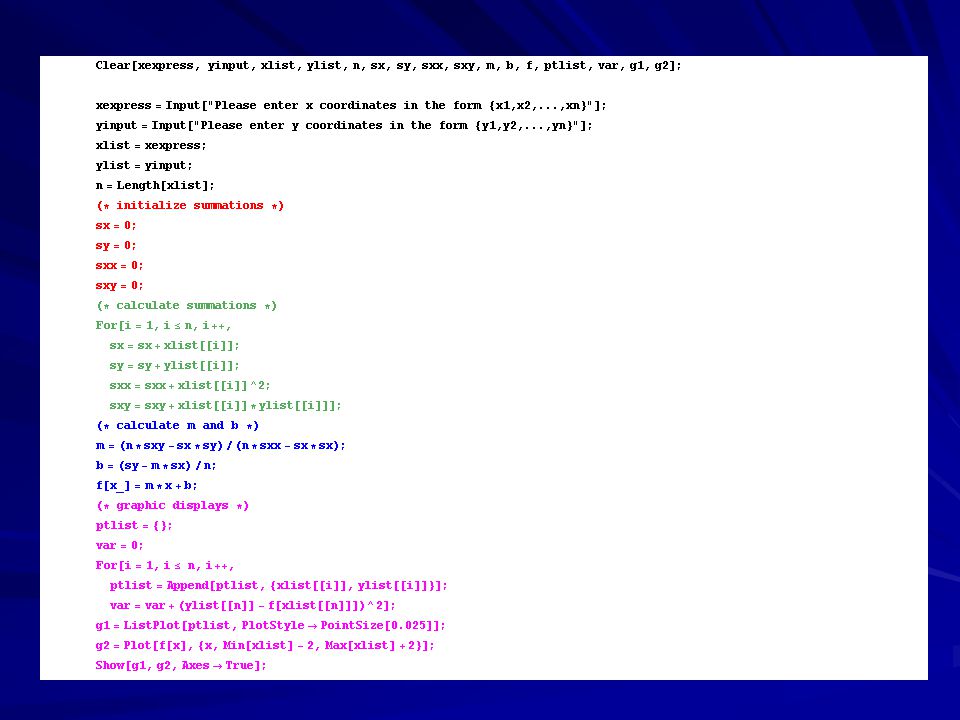
THE ALGORITHM in Mathematica

22
Activity For this activity we are going to use the linear least squares approximation in a real life situation. You are going to be given a box score from either a baseball or softball game. With the box score you are given you are going to write out the points (with the x coordinate being the number of hits that player had in the game and the y coordinate being the number of at-bats that player had in the game). After doing that you are going to use the linear least squares approximation to find the best fitting line. The slope of the besting fitting line you find will be the team’s batting average for that game.
. After doing that you are going to use the linear least squares approximation to find the best fitting line. The slope of the besting fitting line you find will be the team’s batting average for that game..")
23
In Conclusion… E = ∑(mx i + b – y i )² is the sum of the squared error between the set of data points {(x 1,y 1 ),…,(x i,y i ),…,(x n,y n )} and the line approximating the data f(x) = mx + b. By minimizing the error by calculus methods, we get equations for m and b that yield the least squared error:

24
Advantages Many common methods of approximating data seek to minimize the measure of difference between the approximating function and given data points. Advantages for using the squares of differences at each point rather than just the difference, absolute value of difference, or other measures of error include: –Positive differences do not cancel negative differences –Differentiation is not difficult –Small differences become smaller and large differences become larger

25
Disadvantages Algorithm will fail if data points fall in a vertical line. Linear Least Squares will not be the best fit for data that is not linear.

26
The End

Similar presentations




















 To make the chart, you simply take any number and plug it in for x in the equation and the value you get is the y.>")
 = ax2+bx+c, where a, b, c, are constants and Some.>")