Download presentation
Presentation is loading. Please wait.

1
VBM Voxel-based morphometry
Nicola Hobbs & Marianne Novak Thanks to Susie Henley

2
Overview Background Pre-processing steps Analysis Multiple comparisons
Pros and cons of VBM Optional extras

3
Background VBM is a voxel-wise comparison of local tissue volumes within a group or across groups Whole-brain analysis, does not require a priori assumptions about ROIs; unbiased way of localising structural changes Can be automated, requires little user intervention compare to manual ROI tracing

4
Basic Premise Spatial normalisation (alignment) into standard space
Segmentation of tissue classes Modulation - adjust for volume changes during normalisation Smoothing - each voxel is a weighted average of surrounding voxels Statistics - localise & make inferences about differences

5
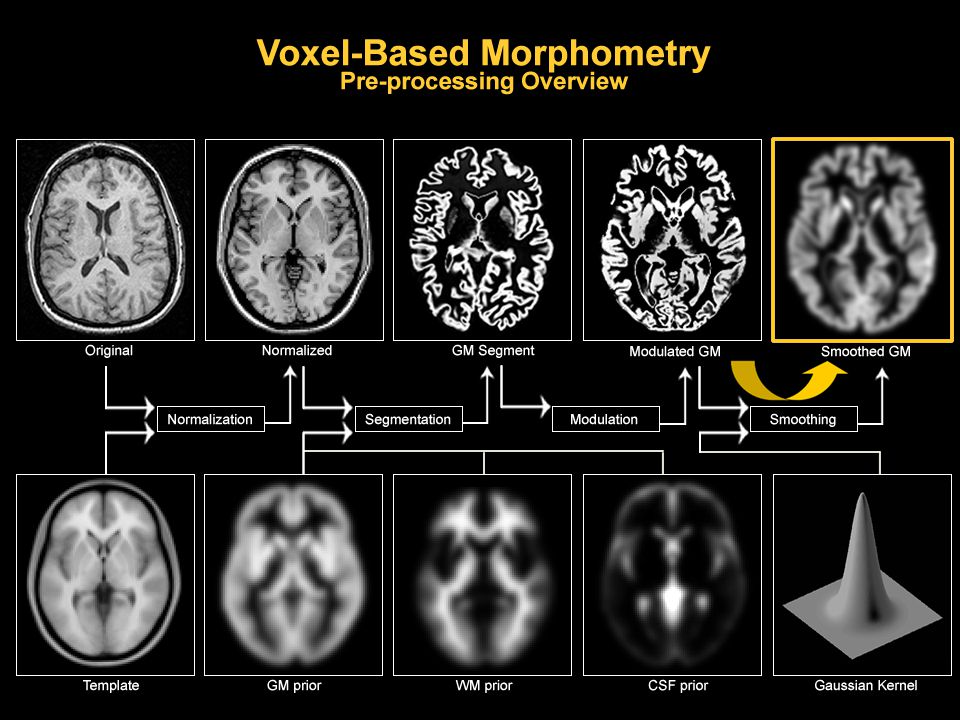
VBM Processing

7
Step 1: normalisation Aligns images by warping to standard stereotactic space Affine step – translation, rotation, scaling, shearing Non-linear step Adjust for differences in head position/orientation in scanner global brain shape Any remaining differences (detectable by VBM) are due to smaller-scale differences in volume
 are due to smaller-scale differences in volume.")
8
SPATIALLY NORMALISED IMAGE
NORMALISATION ORIGINAL IMAGE SPATIALLY NORMALISED IMAGE TEMPLATE IMAGE

10
SPATIALLY NORMALISED IMAGE
2. Tissue segmentation Aims to classify image as GM, WM or CSF Two sources of information a) Spatial prior probability maps b) Intensity information in the image itself GREY MATTER WHITE MATTER CSF SPATIALLY NORMALISED IMAGE Assigns each voxel a (probable) tissue type based on a combination of spatial prior probability maps and the voxel intensity Also includes image intensity non-uniformity correction;
 Spatial prior probability maps. b) Intensity information in the image itself. GREY MATTER. WHITE MATTER. CSF. SPATIALLY NORMALISED IMAGE. Assigns each voxel a (probable) tissue type based on a combination of spatial prior probability maps and the voxel intensity. Also includes image intensity non-uniformity correction;")
11
a) Spatial prior probability maps
Smoothed average of GM from MNI Intensity at each voxel represents probability of being GM SPM compares the original image to this to help work out the probability of each voxel in the image being GM (or WM, CSF)
")
12
b) Image intensities Intensities in the image fall into roughly 3 classes SPM can also assign a voxel to a tissue class by seeing what its intensity is relative to the others in the image Each voxel has a value between 0 and 1, representing the probability of it being in that particular tissue class Includes correction for image intensity non-uniformity

13
Generative model Segmentation into tissue types Bias Correction
Normalisation These steps cycled through until normalisation and segmentation criteria are met

15
Step 3: modulation Corrects for changes in volume induced by normalisation Voxel intensities are multiplied by the local value in the deformation field from normalisation, so that total GM/WM signal remains the same Allows us to make inferences about volume, instead of concentration

16
Modulation i modulation i / δV normalisation X δV
E.g. During normalisation TL in AD subject expands to double the size Modulation multiplies voxel intensities by Jacobian from normalisation process (halve intensities in this case). Intensity now represents relative volume at that point
. Intensity now represents relative volume at that point.")
17
Is modulation optional?
Unmodulated data: compares “the proportion of grey or white matter to all tissue types within a region” Hard to interpret Not useful for looking at e.g. the effects of degenerative disease Modulated data: compares volumes Unmodulated data may be useful for highlighting areas of poor registration (perfectly registered unmodulated data should show no differences between groups)
")
19
Step 4: Smoothing Convolve with an isotropic Gaussian kernel
Each voxel becomes weighted average of surrounding voxels Smoothing renders the data more normally distributed (Central Limit theorem) Required if using parametric statistics Smoothing compensates for inaccuracies in normalisation Makes mass univariate analysis more like multivariate analysis Filter size should match the expected effect size Usually between 8 – 14mm
 Required if using parametric statistics. Smoothing compensates for inaccuracies in normalisation. Makes mass univariate analysis more like multivariate analysis. Filter size should match the expected effect size. Usually between 8 – 14mm.")
20
Smoothing SMOOTH WITH 8MM KERNEL 8 mm
Images are smoothed using a Gaussian kernel (we usually use 8mm FWHM) The intensity of each voxel is therefore a weighted average of the surrounding voxels Makes data more normally distrubuted 8 mm
 The intensity of each voxel is therefore a weighted average of the surrounding voxels. Makes data more normally distrubuted. 8 mm.")
21
VBM: Analysis What does the SPM show in VBM? Cross-sectional VBM
Multiple comparison corrections Pros and cons of VBM Optional extras

22
VBM: Cross-sectional analysis overview
T1-weighted MRI from one or more groups at a single time point Analysis compares (whole or part of) brain volume between groups, or correlates volume with another measurement at that time point Generates map of voxel intensities: represent volume of, or probability of being in, a particular tissue class Get map of voxel intensities Eg memory test and hippo vol
 brain volume between groups, or correlates volume with another measurement at that time point. Generates map of voxel intensities: represent volume of, or probability of being in, a particular tissue class. Get map of voxel intensities. Eg memory test and hippo vol.")
23
What is the question in VBM analysis?
Control AD Take a single voxel, and ask: “are the intensities in the AD images significantly different to those in the control images for this particular voxel?” eg is the GM intensity (volume) lower in the AD group cf controls? ie do a simple t-test on the voxel intensities
 lower in the AD group cf controls ie do a simple t-test on the voxel intensities.")
24
Statistical Parametric Maps (SPM)
Repeat this for all voxels Highlights all voxels where intensities (volume) are significantly different between groups: the SPM SPM showing regions where Huntington’s patients have lower GM intensity than controls Colour bar shows the t-value
 are significantly different between groups: the SPM. SPM showing regions where Huntington’s patients have lower GM intensity than controls. Colour bar shows the t-value.")
25
VBM: group comparison Intensity for each voxel (V) is a function that models the different things that account for differences between scans: V = β1(AD) + β2(control) + β3(covariates) + β4(global volume) + μ + ε + β3(age) + β4(gender) + β5(global volume) + μ + ε V = β1(AD) + β2(control) In practice, the contrast of interest is usually t-test between β1 and β2 Voxel intensity is a function that models all the different things that account for differences between scans. Use AD vs controls as example. Beta value is slope of association of scans or values at that voxel Covariates are explanatory or confounding variables eg “is there significantly more GM in the control than in the AD scans?”
 + β2(control) + β3(covariates) + β4(global volume) + μ + ε. + β3(age) + β4(gender) + β5(global volume) + μ + ε. V = β1(AD) + β2(control) In practice, the contrast of interest is usually t-test between β1 and β2. Voxel intensity is a function that models all the different things that account for differences between scans. Use AD vs controls as example. Beta value is slope of association of scans or values at that voxel. Covariates are explanatory or confounding variables. eg is there significantly more GM in the control than in the AD scans")
26
VBM: correlation Correlate images and test scores (eg Alzheimer’s patients with memory score) SPM shows regions of GM or WM where there are significant associations between intensity (volume) and test score V = β1(test score) + β2(age) + β3(gender) + β4(global volume) + μ + ε Contrast of interest is whether β1 (slope of association between intensity & test score) is significantly different to zero Combine group comparison and correlation analyses.
 and test score. V = β1(test score) + β2(age) + β3(gender) + β4(global volume) + μ + ε. Contrast of interest is whether β1 (slope of association between intensity & test score) is significantly different to zero. Combine group comparison and correlation analyses.")
27
Correcting for Multiple Comparisons
200,000 voxels per scan ie 200,000 t-tests If you do 200,000 t-tests at p<0.05, by chance 10,000 will be false positives Bad practice… A strict Bonferroni correction would reduce the p value for each test to However, voxel intensities are not independent, but correlated with their neighbours Bonferroni is therefore too harsh a correction and will lose true results

28
Familywise Error SPM uses Gaussian Random Field theory (GRF)1
Using FWE, p<0.05: 5% of ALL our SPMs will contain a false positive voxel This effectively controls the number of false positive regions rather than voxels Can be thought of as a Bonferroni-type correction, allowing for multiple non-independent tests Good: a “safe” way to correct Bad: but we are probably missing a lot of true positives 1

29
False Discovery Rate FDR more recent
q value FDR q<0.05 False Discovery Rate FDR more recent It controls the expected proportion of false positives among suprathreshold voxels only Using FDR, q<0.05: we expect 5% of the voxels for each SPM to be false positives (1,000 voxels) Bad: less stringent than FWE so more false positives Good: fewer false negatives (ie more true positives) But: assumes independence of voxels: avoid….? Voxel
 Bad: less stringent than FWE so more false positives. Good: fewer false negatives (ie more true positives) But: assumes independence of voxels: avoid…. Voxel.")
30
VBM Pros VBM Cons 1. Objective analysis
2. Do not need priors – more exploratory 3. Automated VBM Cons 1. False positives: misregistration, FDR False negatives: FWE More difficult to pick up differences in areas with high inter-subject variance: low signal to noise ratio Comparing VBM to less automated or more manual tools measuring regional tissue volumes

31
Other VBM Issues Optimised VBM: GM to GM warping, then applied to whole brain image (better GM alignment); Good et al, Neuroimage (SPM 2) Diffeomorphic warping: DARTEL Multivariate techniques: including classification/SVM Longitudinal scan analysis: two time points especially

32
18 iterations to form template
Ashburner Neuroimage 2007

33
Standard preprocessing: areas of decreased volume in depressed subjects
DARTEL preprocessing: areas of decreased volume in depressed subjects

34
Longitudinal VBM Baseline and follow-up image are registered together non-linearly (fluid registration), NOT using spm software Voxels at follow-up are warped to voxels at baseline Represented visually as a voxel compression map showing regions of contraction and expansion

35
Fluid Registered Image
FTD (semantic dementia) Voxel compression map 1 year expanding contracting
 Voxel compression map. 1 year. expanding. contracting.")
36
Optimised VBM Native space images Standard space images
1. Affine registration to SPM2 T1 template 4. Normalisation using parameters from step 3; GM is well-aligned Standard space images Standard space images 2. Segmentation 5. Segmentation GM segments GM segments 3. Estimate normalisation parameters for GM segments to SPM2 GM template 6. Modulation: correcting for spatial changes introduced in normalisation Normalisation parameters GM to GM Mod GM 7. Masking: segments are multiplied by binary region to exclude any non-brain Masked GM 8. Smoothed at 8mm FWHM Smoothed, Masked, mod GM

37
Resources and references
(the SPM homepage) (neurimaging wiki homepage) (for multiple comparisons info) Ashburner J, Friston KJ. Voxel-based morphometry--the methods. Neuroimage 2000; 11: (the original VBM paper) Good CD, Johnsrude IS, Ashburner J, Henson RN, Friston KJ, Frackowiak RS. A voxel-based morphometric study of ageing in 465 normal adult human brains. Neuroimage 2001; 14: (the optimised VBM paper) Ridgway GR, Henley SM, Rohrer JD, Scahill RI, Warren JD, Fox NC. Ten simple rules for reporting voxel-based morphometry studies. Neuroimage 2008.
 (neurimaging wiki homepage) (for multiple comparisons info) Ashburner J, Friston KJ. Voxel-based morphometry--the methods. Neuroimage 2000; 11: (the original VBM paper) Good CD, Johnsrude IS, Ashburner J, Henson RN, Friston KJ, Frackowiak RS. A voxel-based morphometric study of ageing in 465 normal adult human brains. Neuroimage 2001; 14: (the optimised VBM paper) Ridgway GR, Henley SM, Rohrer JD, Scahill RI, Warren JD, Fox NC. Ten simple rules for reporting voxel-based morphometry studies. Neuroimage")
Similar presentations







>")




 Brain Data for Studying Tissue Microstructure, Macroscopic Morphology and Morphometry.>")



>")





