Download presentation
Presentation is loading. Please wait.

1
Neural networks (2) Reminder Avoiding overfitting Deep neural network Brief summary of supervised learning methods
 Reminder Avoiding overfitting Deep neural network Brief summary of supervised learning methods")
2
Reminder K-class classification: K nodes in top layer Continuous outcome: Single node in top layer

3
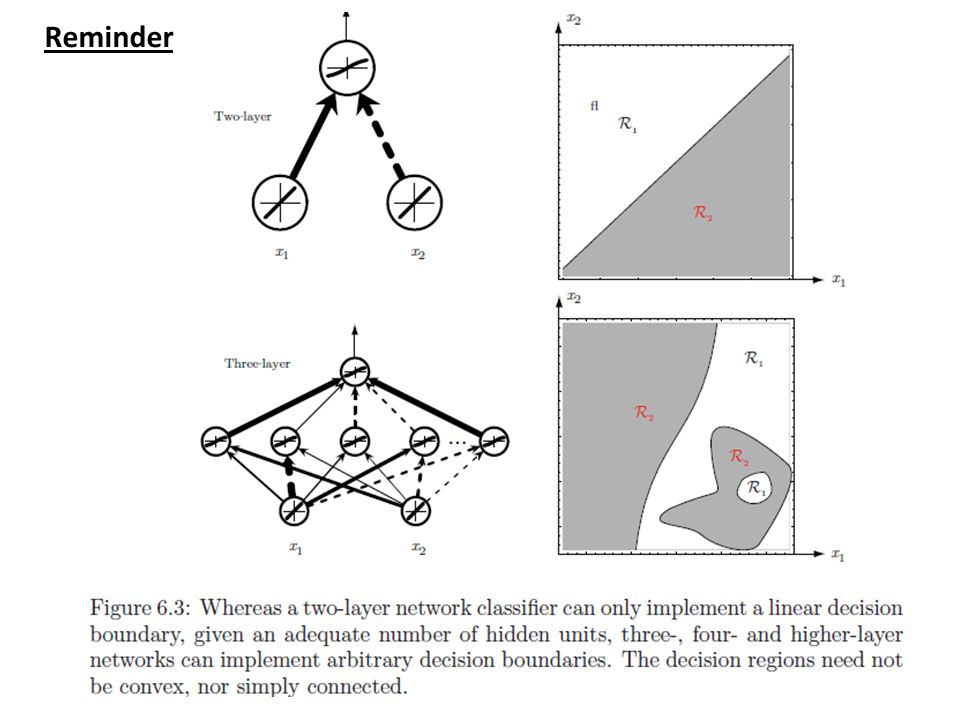
Each hidden node can be seen as a linear space partition. Reminder

5
Fitting Neural Networks Overfitting The model is too flexible, involving too many parameters. May easily overfit the data. Early stopping – do not let the algorithm converge. Because the model starts with linear, this is a regularized solution (towards linear). Explicit regularization (“weight decay”) – minimize tends to shrink smaller weights more. Cross-validation is used to estimate λ.
. Explicit regularization ( weight decay ) – minimize tends to shrink smaller weights more. Cross-validation is used to estimate λ..")
6
Fitting Neural Networks

8
Number of Hidden Units and Layers Too few – might not have enough flexibility to capture the nonlinearities in the data Too many – overly flexible, BUT extra weights can be shrunk toward zero if appropriate regularization is used. ✔ Typical range: 5-100 Cross-validation can be used.

9
Examples “A radial function is in a sense the most difficult for the neural net, as it is spherically symmetric and with no preferred directions.”

10
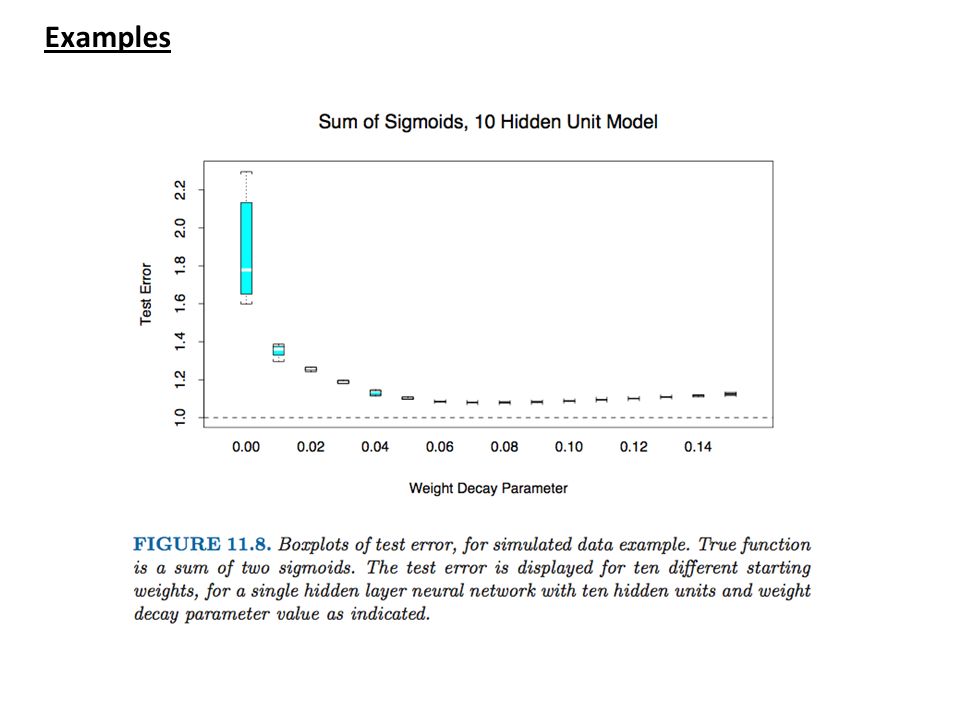
Examples

12
Going beyond single hidden layer A benchmark problem: classification of handwritten numerals.

13
3x3 1 5x5 1 Going beyond single hidden layer same operation on different parts each of the units in a single 8 × 8 feature map share the same set of nine weights (but have their own bias parameter) Decision boundaries of parallel lines 3x3 1 5x5 1 No weight sharing weight shared
 Decision boundaries of parallel lines 3x3 1 5x5 1 No weight sharing weight shared")
14
Going beyond single hidden layer

15
Going beyond single hidden layer

16
Deep learning

18
DataFeaturesModel Finding the correct features is critical in the success. -Kernels in SVM -Hidden layer nodes in neural network -Predictor combinations in RF A successful machine learning technology needs to be able to extract useful features (data representations) on its own. Deep learning methods: -Composition of multiple non-linear transformations of the data -Goal: more abstract – and ultimately more useful representations IEEE Trans Pattern Anal Mach Intell. 2013 Aug;35(8):1798-828
 on its own. Deep learning methods: -Composition of multiple non-linear transformations of the data -Goal: more abstract – and ultimately more useful representations IEEE Trans Pattern Anal Mach Intell Aug;35(8):")
19
Deep learning Learn representations of data with multiple levels of abstraction Example: image processing Layer 1: presence/absence of edge at particular location & orientation. Layer 2: motifs formed by particular arrangements of edges; allows small variations in edge locations Layer 3: assemble motifs into larger combinations of familiar objects Layer 4 and beyond: higher order combinations Key: the layers are not designed by an engineer, but learned from data using a general-purpose learner. Nature. 521:436-444

20
Deep learning Key to success: Detect minute differences Ignore irrelevant variations Nature. 521:436-444

21
Deep learning Nature 505, 146–148 IEEE Trans Pattern Anal Mach Intell. 2013 Aug;35(8):1798-828
:")
22
Deep learning Nature. 521:436-444

23
Deep learning c, The equations used for computing the forward pass in a neural net with two hidden layers and one output layer, each constituting a module through which one can backpropagate gradients. At each layer, we first compute the total input z to each unit, which is a weighted sum of the outputs of the units in the layer below. Then a non-linear function f(.) is applied to z to get the output of the unit. Common f(): rectified linear unit (ReLU) f(z) = max(0,z) Nature. 521:436-444
 is applied to z to get the output of the unit. Common f(): rectified linear unit (ReLU) f(z) = max(0,z) Nature. 521:")
24
Deep learning d, The equations used for computing the backward pass. At each hidden layer we compute the error derivative with respect to the output of each unit, which is a weighted sum of the error derivatives with respect to the total inputs to the units in the layer above. We then convert the error derivative with respect to the output into the error derivative with respect to the input by multiplying it by the gradient of f(z). At the output layer, the error derivative with respect to the output of a unit is computed by differentiating2the cost function. Nature. 521:436-444
. At the output layer, the error derivative with respect to the output of a unit is computed by differentiating2the cost function. Nature. 521:")
25
Deep learning RNNs process an input sequence one element at a time, maintaining in their hidden units a ‘state vector’ that implicitly contains information about the history of all the past elements of the sequence. Nature. 521:436-444

26
Deep learning IEEE Trans Pattern Anal Mach Intell. 2013 Aug;35(8):1798-828 Major areas of application -Speech Recognition and Signal Processing -Object Recognition -Natural Language Processing …… So far in bioinformatics -Training data size (subjects) is still too small compared to the number of variables (N<<p issue) -Neural network could be applied when human selection of variables is done first. -Biological knowledge, in the form of existing networks, are already explicitly used, instead of being learned from data. They are hard to beat with a limited amount of data.
: Major areas of application -Speech Recognition and Signal Processing -Object Recognition -Natural Language Processing …… So far in bioinformatics -Training data size (subjects) is still too small compared to the number of variables (N<<p issue) -Neural network could be applied when human selection of variables is done first. -Biological knowledge, in the form of existing networks, are already explicitly used, instead of being learned from data. They are hard to beat with a limited amount of data..")
27
Brief summary

28
Capability to learn highly abstract representations Need expert input to select representations Shallow classifiers (linear machines) Deep neural networks Kernel machines “Do not generalize well far from the training examples” Linear partition Nonlinear partition Parametric Nonlinear models Flexible Nonlinear partition Extract higher order information Brief summary
 Deep neural networks Kernel machines Do not generalize well far from the training examples Linear partition Nonlinear partition Parametric Nonlinear models Flexible Nonlinear partition Extract higher order information Brief summary")
29
Ensemble learning Combining weak learners Combining strong learners Bagging Boosting Random forest Stacking

30
Ensemble learning Uses cross validation to assess the individual performance of prediction algorithms Combines algorithms to produce an asymptotically optimal combination 1.For each predictor, predict each observation in a V-fold cross-validation 2.Find a weight vector: 3.Combine the prediction from individual algoriths using the weights. Stat in Med. 34:106–117

31
Ensemble learning Lancet Respir Med. 3(1):42-52
:42-52")
Similar presentations















 The hyperplanethat solves the minimization problem: realizes the maximal margin hyperplane.>")





