Download presentation
Presentation is loading. Please wait.

1
Intel’s Tara-scale computing project 100 cores, >100 threads Datacenter-on-a-chip Sun’s Niagara2 (T2) 8 cores, 64 Threads Key design issues Architecture Challenges and Tradeoffs Architecture Challenges and Tradeoffs Packaging and off-chip memory bandwidth Software and runtime environment Tara-Scale CMP CDA5155sp08 peir
 8 cores, 64 Threads Key design issues Architecture Challenges and Tradeoffs Architecture Challenges and Tradeoffs Packaging and off-chip memory bandwidth Software and runtime environment Tara-Scale CMP CDA5155sp08 peir")
2
Many-Core CMPs – High-level View Cores L2 L1I/D What are the key architecture issues in many-cores CMP CDA5155sp08 Peir 2 On-die interconnect Cache organization & Cache coherence I/O and Memory architecture

3
The General Block Diagram FFU: Fixed Function Unit, Mem C: Memory Controller, PCI-E C: PCI- based Controller, R: Router, ShdU: Shader Unit, Sys I/F: System Interface, TexU: Texture Unit CDA5155sp08 Peir 3

4
On-Die Interconnect 2D Embedding of a 64-core 3D-mesh network The longest hop of the topological distance is extended from 9 to 18!

5
On-Die Interconnect Must satisfy bandwidth and latency within power/area Ring or 2D mesh/torus Ring or 2D mesh/torus are good candidate topology Wiring density, router complexity, design complexity Multiple source/dest. pairs can be switched together; avoid packets stop and buffered, save power, help throughput Xbar, general router are power hungry Fault-tolerant interconnect Provide spare modules, allow fault-tolerant routing Partition for performance isolation

6
Performance Isolation in 2D mesh Performance isolation in 2D mesh with partition 3 rectangular partitions Intra-communication confined within partition Traffic generated in a partition will not affect others Virtualization of network interfaces Interconnect as an abstraction of applications Allow programmers fine-tune application’s inter-processor communication

7
Many-Core CMPs Cores L2 L1I/D How about on-die cache organization with so many cores? Shared vs. Private Cache capacity vs. accessibility Data replication vs. block migration Cache partition

8
CMP Cache Organization

9
Capacity vs. Accessibility, A Tradeoff Capacity – favor Shared cache No data replication, no cache coherence No data replication, no cache coherence Longer access time, contention issue Longer access time, contention issue Flexible cache capacity sharing Flexible cache capacity sharing Fair sharing among cores – Cache partition Fair sharing among cores – Cache partition Accessibility – favor Private cache Fast local access with data replication, capacity may suffer Fast local access with data replication, capacity may suffer Need maintain coherence among private caches Need maintain coherence among private caches Equal partition, inflexible Equal partition, inflexible Many works to take advantage of both Capacity sharing on private– cooperative caching Capacity sharing on private– cooperative caching Utility-based cache partition on shared Utility-based cache partition on shared

10
Analytical Data Replication Model Reuse distance histogram f(x): # of accesses with distance x Cache size S: Total # hits => Area beneath the curve => Cache misses increase Capacity decreases Cache hits now Local hits increase R/S of hits to replica Local hits increase R/S of hits to replica L of replica hits: local P: Miss Penalty Cycles; G: Local Gain Cycles Net memory access cycle increase:
: # of accesses with distance x Cache size S: Total # hits => Area beneath the curve => Cache misses increase Capacity decreases Cache hits now Local hits increase R/S of hits to replica Local hits increase R/S of hits to replica L of replica hits: local P: Miss Penalty Cycles; G: Local Gain Cycles Net memory access cycle increase:")
11
Get Histogram f(x) for OLTP Step 2: Matlab Curve Fitting Find math expr. Step 1: Stack simulation Collect discrete reuse distance X10 6

12
Data Replication Effects f(x) G =15 P = 400 L = 0.5 S = 2M S = 4M S = 8M: (R/S) S = 2M 0% best S = 4M 40% best S = 8M 65% best Data Replication Impacts vary with different cache sizes
 G =15 P = 400 L = 0.5 S = 2M S = 4M S = 8M: (R/S) S = 2M 0% best S = 4M 40% best S = 8M 65% best Data Replication Impacts vary with different cache sizes")
13
Many-Core CMPs Cores L2 L1I/D How about Cache Coherence with so many cores&caches ? Snooping bus: Broadcast requests Directory-based: maintaining memory block information Review Culler’s book

14
Simplicity: Shared L2, Write-through L1 Existing designs IBM Power4 & 5 Sun Niagara & Niagara 2 Small number of cores, Multiple L2 banks, Xbar Still need L1 coherence!! Inclusive L2, use L2 directory record L1 sharers in Power4&5 Non-inclusive L2, Shadow L1 directory in Niagara L2 (shared) coherence among multiple CMPs Private L2 is assumed
 coherence among multiple CMPs Private L2 is assumed.")
15
Other Considerations Broadcast Snooping Bus: loading, speed, space, power, scalability, etc. Ring: slow traversal, ordering, scalability Memory-based directory Huge directory space Directory cache, extra penalty Shadow L2 Directory: copy all local L2s Aggregated associativity = Cores * Ways/Core; 64*16 = 1024 way High power

16
Directory-Based Approach statelocation Directory needs to maintain the state and location of all cached blocks Directory is checked when the data cannot be accessed locally, e.g. cache miss, write-to-shared Directory may route the request to remote cache to fetch the requested block

17
Sparse Directory Approach Holds states for all cached blocks Low-cost set- associative design No backup Key issues: Centralized vs. Distributed Centralized vs. Distributed Indirect accesses Indirect accesses Extra invalidation due to conflicts Extra invalidation due to conflicts Presence bit vs. duplicated blocks Presence bit vs. duplicated blocks

18
Conflict Issues in Coherence Directory Coherence directory must be a superset of all cached blocks Uneven distribution of cached blocks in each directory set cause invalidations Potential solutions: High set associativity – costly Directory + victim directory Randomization and Skew associativity Bigger directory - Costly Others?

19
Impact of Invalidation due to Directory Conflict 8-core CMP, 1MB 8-way private L2 (total 8MB) Set-associative dir; # of dir entry = total # of cache blocks Each cached block occupies a directory entry 75% 96% 72% 93%
 Set-associative dir; # of dir entry = total # of cache blocks Each cached block occupies a directory entry 75% 96% 72% 93%")
20
Presence bits Issue in Directory Presence bits (or not?) Extra space, useless for multi-programs Coherence directory must cover all cached blocks (consider no sharing) Potential solutions Coarse-granularity present bits, imprecise not suitable for CMP Sparse presence vectors – record core-ids Allow duplicated block addresses with few core-ids for each shared block, enable multiple hits on directory search Others?
 Extra space, useless for multi-programs Coherence directory must cover all cached blocks (consider no sharing) Potential solutions Coarse-granularity present bits, imprecise not suitable for CMP Sparse presence vectors – record core-ids Allow duplicated block addresses with few core-ids for each shared block, enable multiple hits on directory search Others")
21
Valid Blocks Presence Bit: Multiprogrammed -> No Multithreaded -> Yes Skew, and 10w-1/4 helps; No difference 64v

22
Challenge in Memory Bandwidth Increase in off-chip memory bandwidth to sustain chip-level IPC Need power-efficient high-speed off-die I/O Need power-efficient high-bandwidth DRAM access Potential Solutions: Embedded DRAM Integrated DRAM, GDDR inside processor package 3D stacking of multiple DRAM/processor dies Many technology issues to overcome

23
Memory Bandwidth Fundamental BW = # of bits x bit rate A typical DDR2 bus is 16 bytes (128 bits) wide and operating at 800Mb/s. The memory bandwidth of that bus is 16 bytes x 800Mb/s, which is 12.8GB/s Latency and Capacity Fast, but small capacity on-chip SRAM (caches) Slow large capacity off-chip DRAM
 Slow large capacity off-chip DRAM.")
24
Memory Bus vs. System Bus Bandwidth Scaling of bus capability has usually involved a combination of increasing the bus width while simultaneously increasing the bus speed

25
Integrated CPU with Memory Controller Eliminate off-chip controller delay Fast, but difficult to adapt new DRAM technology The entire burden of pin count and interconnect speed to sustain increases in memory bandwidth requirements now falls on the CPU package alone

26
Challenge in Memory Bandwidth and Pin Count

27
Challenge in Memory Bandwidth Historical trend for memory bandwidth demand Current generation: 10-20 GB/s Next generation: >100GB/s and could go 1TB/s

28
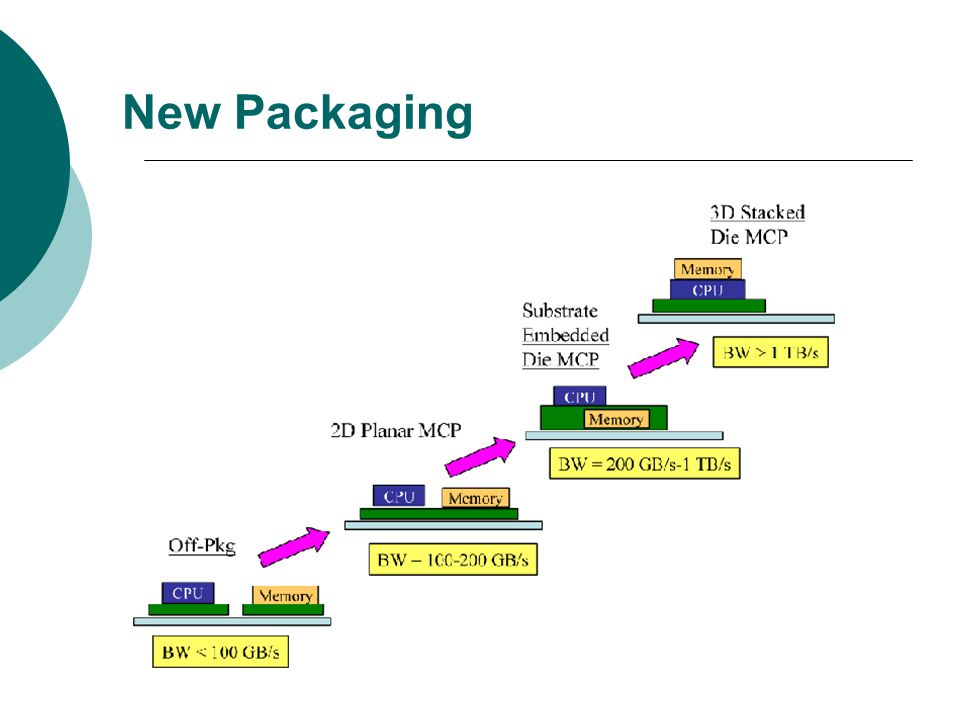
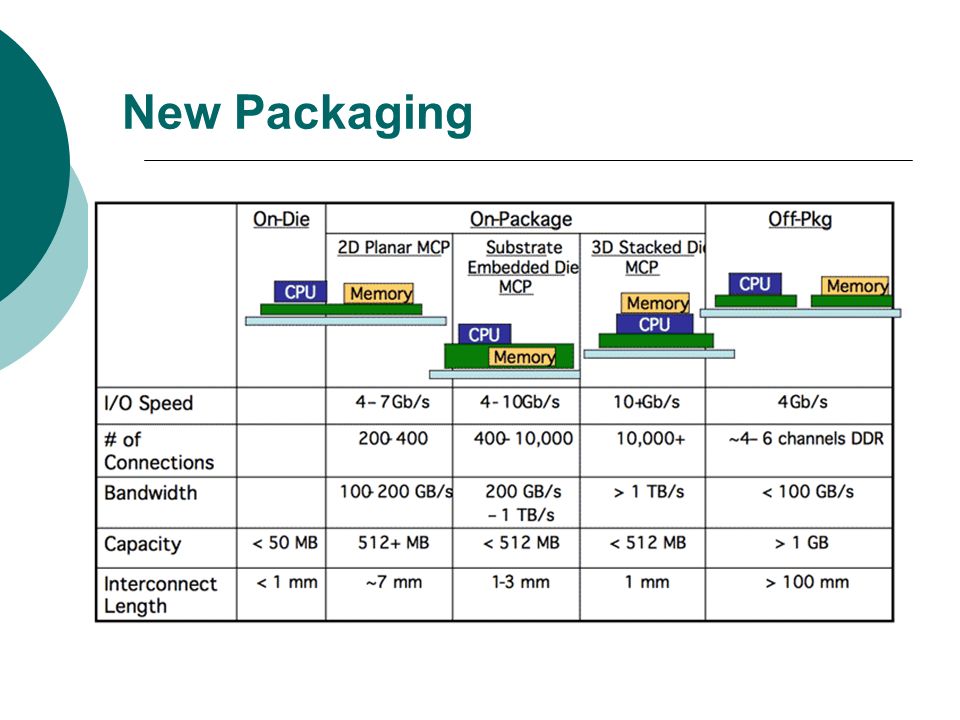
New Packaging

Similar presentations







 Multilevel Caches: A second level cache (L2) is added between the original Level-1 cache and main memory.>")






: Co-Operative Caching for Chip Multiprocessors, Chang and Sohi, ISCA’06 Victim Replication,>")




