Download presentation
Presentation is loading. Please wait.

1
C ONTEXT AS S UPERVISORY S IGNAL : D ISCOVERING O BJECTS WITH P REDICTABLE C ONTEXT Carl Doersch, Abhinav Gupta, Alexei Efros

2
Unsupervised Object Discovery Children learn to see without millions of labels Is there a cue hidden in the data that we can use to learn better representations? …

3
How hard is unsupervised object discovery? In state of the art literature it is still commonplace to select 20 categories from Caltech 101 1 : Le et al. got in the New York Times for spending 1M+ CPU hours and reporting just 3 objects. 2 1 Faktor & Irani, “Clustering by Composition” – Unsupervised Discovery of Image Categories, ECCV 2012 2 Le et al, Building High-level Features Using Large Scale Unsupervised Learning, ICML 2012

4
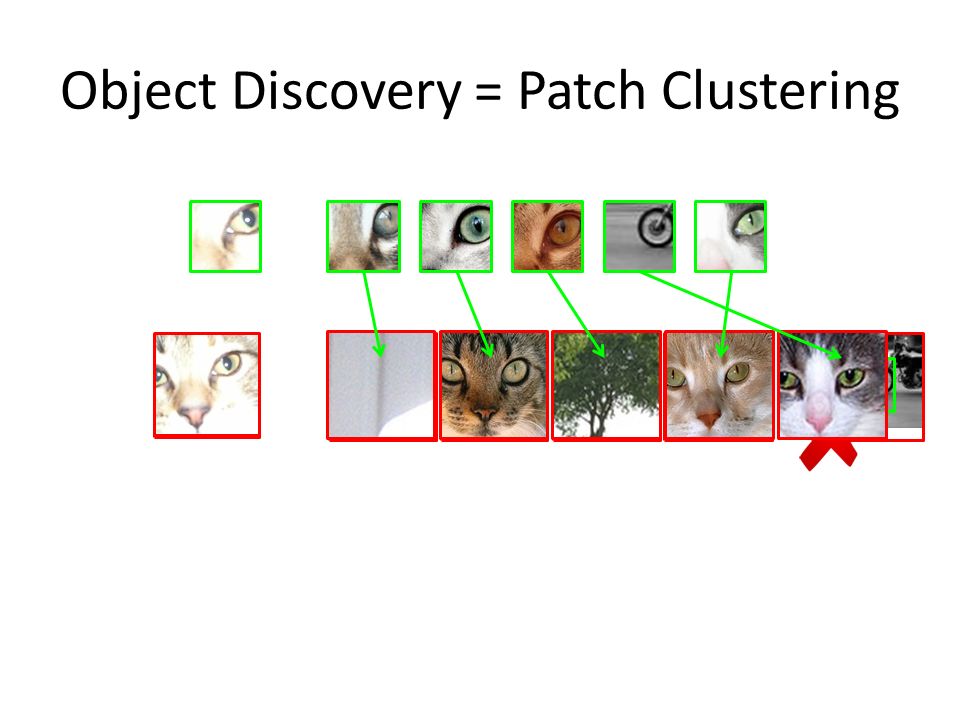
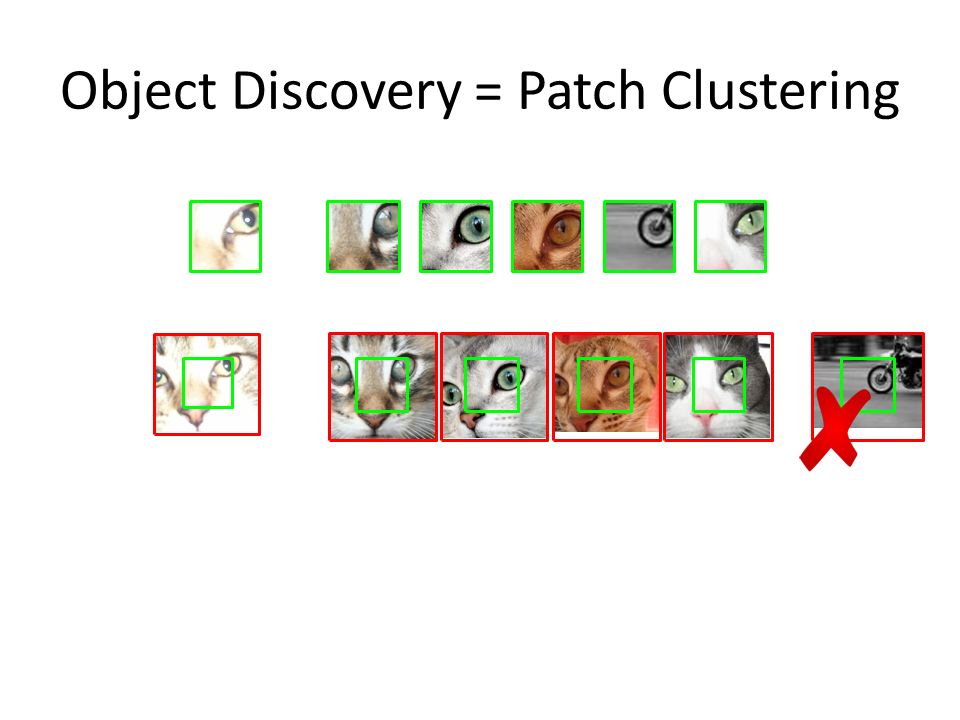
Object Discovery = Patch Clustering

7
Clustering algorithms

9
Clustering algorithms?

10
Clustering as Prediction Y value is here Prediction: Actual

11
Clustering as Prediction Y value is here Prediction: Actual

12
What cue is used for clustering here? The datapoints are redundant! – Within a cluster, knowing one coordinate tells you the other Images are redundant too! Contribution #1 (of 3): use patch-context redundancy for clustering.
: use patch-context redundancy for clustering..")
13
More rigorously Unlike standard clustering, we measure the affinity of a whole cluster rather than pairs Datapoints x can be divided into x=[p,c] Affinity is defined by how ‘learnable’ is the function c=F(p) – Or P(c|p) – Measure how well the function has been learned via leave-one-out cross validation
![More rigorously Unlike standard clustering, we measure the affinity of a whole cluster rather than pairs Datapoints x can be divided into x=[p,c] Affinity is defined by how ‘learnable’ is the function c=F(p) – Or P(c|p) – Measure how well the function has been learned via leave-one-out cross validation](http://images.slideplayer.com/31/9753182/slides/slide_13.jpg "More rigorously Unlike standard clustering, we measure the affinity of a whole cluster rather than pairs Datapoints x can be divided into x=[p,c] Affinity is defined by how ‘learnable’ is the function c=F(p) – Or P(c|p) – Measure how well the function has been learned via leave-one-out cross validation")
14
Previous whispers of this idea Weakly supervised methods Probabilistic clustering – choose clusters s.t. dataset can be compressed Autoencoders & RBM’s (Olshausen & Field 1997)
.")
15
Clustering as Prediction Y value is here Prediction: Actual

16
When is a prediction “good enough”? Image distance metrics are unreliable Min distance: 2.59e-4 Max distance: 1.22e-4 InputNearest neighbor

17
It’s even worse during prediction Horizontal gratings are very close together in HOG feature space, and are easy to predict Cats have more complex shape that is farther apart and harder to predict. ??

18
Our task is more like this:

19
P 2 (X|Y) P 1 (X|Y) Y value is here Contribution #2 (of 3): Cluster Membership as Hypothesis Testing
 P 1 (X|Y) Y value is here Contribution #2 (of 3): Cluster Membership as Hypothesis Testing")
20
What are the hypotheses? thing hypothesis – The patch is a member of the proposed cluster – Context is best predicted by transferring appearance from other cluster members stuff hypothesis – Patch is ‘miscellaneous’ – The best we can do is model the context as clutter or texture, via low-level image statistics.

21
Our Hypotheses True Region: High Likelihood Low Likelihood Stuff Model … Stuff-based Prediction Thing Model Thing-based Prediction Predicted Correspondence Condition Region (Patch) Prediction Region (Context)
 Prediction Region (Context)")
22
Real predictions aren’t so easy!

23
What to do? Generate multiple predictions from different images, and take the best Take bits and pieces from many images Still not enough? Generate more with warping. With arbitrarily small pieces and lots of warping, you can match anything!

24
Generative Image Models Long history in computer vision Come up with a distribution P(c|p), without looking at c Distribution is extremely complicated due to dependencies between features - Hinton et al. 1995 - Weber et al. 2000 - Fergus et al. 2003 - Fei-Fei et al. 2007 - Sudderth et al. 2005 - Wang et al. 2006

25
Generative Image Models Object Part Locations Features

26
Inference in Generative Models Object Part Locations Features

27
Contribution #3: Likelihood Factorization Let c be context and p be a patch Break c chunks c 1 …c k (e.g. HOG cells) Now the problem boils down to estimating
 Now the problem boils down to estimating.")
28
Our Hypotheses True Region: Stuff Model … Thing Model Predicted Correspondence Condition Region (Patch) Prediction Region (Context)
 Prediction Region (Context)")
29
Surprisingly many good properties This is not an approximation Broke a hard generative problem into a series of easy discriminative ones Latent variable inference can use maximum likelihood: it’s okay to overfit to condition region c i ’s do not need to be integrated out Likelihoods can be compared across models

30
Why did nobody think of this? We now have 1000 predictions per detection The original idea of generative models was to be based on real-world generative processes It’s not obvious that these conditional predictions actually capture what we want, or that they make the job easier.

31
Discriminative won over generative DPM’s can be seen as doing maximum likelihood estimation over latent parts. Overfits, but discriminative training doesn’t care (Felzenszwalb et al. 2008)
.")
32
Recap of Contributions Clustering as prediction Statistical hypothesis testing of stuff vs. thing to determine cluster membership Factorizing the computation of stuff and thing data likelihoods

33
Stuff Model Condition Region Find NN’s for this Region and transfer Prediction Region

34
Faster Stuff Model x1,000,000x5,000 Conditional: Random Image PatchesDictionary (GMM of patches)
")
35
Faster Stuff Model x5,000 Cond’l: (e) Estimate Cluster Membership Features from condition region Condition Region Prediction Region Prediction Region Specified In Dictionary x5,000 Cond’l: Marginalization
 Estimate Cluster Membership Features from condition region Condition Region Prediction Region Prediction Region Specified In Dictionary x5,000 Cond’l: Marginalization")
36
Thing Model Image i … … Query image … … Condition Region Prediction Region

37
Finite and Occluded ‘Things’ If the thing model believes it can’t predict well, ‘mimic’ the background model – When the thing model believes the prediction region corresponds to regions previously predicted poorly – When the thing model has been predicting badly nearby (handles occlusion!) Image i … … Query image … …
 Image i … … Query image … …")
38
Clusters discovered on 6 Pascal Categories 00.10.20.30.40.50.60.70.80.91 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Cumulative Coverage Visual Words.63 (.37) Russel et al..66 (.38) HOG Kmeans.70 (.40) Our Approach.83 (.48) Singh et al..83 (.47) Purity
 Russel et al..66 (.38) HOG Kmeans.70 (.40) Our Approach.83 (.48) Singh et al..83 (.47) Purity")
39
Results: Pascal 2011, unsupervised 1 2 5 6 RankInitialFinal

40
Results: Pascal 2011, unsupervised 19 20 31 47 RankInitialFinal

41
Results: Pascal 2011, unsupervised 153 200 220 231 RankInitialFinal

42
Errors

43
Unsupervised keypoint transfer L F Wheel Ctr R F Wheel Ctr L Headlight L Mirror R Headlight [sic] R Mirror R F Roof L B Roof L Taillight L B Wheel Ctr R B Wheel Ctr L F Roof R B Roof
![Unsupervised keypoint transfer L F Wheel Ctr R F Wheel Ctr L Headlight L Mirror R Headlight [sic] R Mirror R F Roof L B Roof L Taillight L B Wheel Ctr R B Wheel Ctr L F Roof R B Roof](http://images.slideplayer.com/31/9753182/slides/slide_43.jpg "Unsupervised keypoint transfer L F Wheel Ctr R F Wheel Ctr L Headlight L Mirror R Headlight [sic] R Mirror R F Roof L B Roof L Taillight L B Wheel Ctr R B Wheel Ctr L F Roof R B Roof")
44
Keypoint Precision-Recall

Similar presentations








 we will have a general Computer Vision.>")











