Download presentation
Presentation is loading. Please wait.

1
M. Tiwari, B. Agrawal, S. Mysore, J. Valamehr, T. Sherwood, CS & ECE of UCSB Reading Group Presentation by Theo

2
DIFT Lifeguards very interesting ◦ TaintCheck ◦ MemCheck Can help detect a series of bugs or extract useful information for the program running Hardware Accelerators used to achieve reasonable performance

3
All hardware approaches so far use “normal” cache for metadata storage ◦ In the normal cache hierarchy ◦ Or in extended bits (RAKSHA) ◦ Or in dedicated L1-T (Flexitaint) Conventional approaches very effective for 1- or 2-bit states But what about word/word or even word/byte lifeguards?
 ◦ Or in dedicated L1-T (Flexitaint) Conventional approaches very effective for 1- or 2-bit states But what about word/word or even word/byte lifeguards")
4
Word/Word ◦ Lockset ◦ TaintCheck with full tracking / word ◦ “Super MemCheck” with alloc/free and NULLing PC Word/Byte ◦ Super MemCheck per byte ◦ Tomography Lifeguard L/G similar to TaintCheck, stores exactly how each input byte was used to calculate each byte in the app Extended-State L/Gs very useful, but where can we store their state?

5
Previous caching schemes are ineffective for byte/byte L/Gs ◦ Extending cache lines impractical ◦ Using normal cache will pollute the hierarchy ◦ Dedicated small L1-T will miss frequently avg max

6
Observation ◦ Tags exhibit high spatial locality ◦ If one byte is tagged as ‘A’, neighboring bytes will be ‘A’ also Replace normal cache with range cache Consecutive addresses with same metadata will only occupy a single entry Address Metadata From This (L1-T) Start Addr Start Addr Metadata To This (Range Cache) End Addr End Addr
 Start Addr Start Addr Metadata To This (Range Cache) End Addr End Addr")
7
Updates and Reads must be handled fast ◦ Especially common case ones (R/W in a single area) Regions must be identified on the fly ◦ Split, Combine, Increase ranges automatically ◦ Extremely important since areas are usually increased slowly Only few L/Gs (eg AddrCheck) get to know areas always
 Regions must be identified on the fly ◦ Split, Combine, Increase ranges automatically ◦ Extremely important since areas are usually increased slowly Only few L/Gs (eg AddrCheck) get to know areas always")
8
Assuming infinite number of entries 0+1→1 1+1→1 1+1→2 1+1→1 1+1→3

9
N+1→3 2+X+1→3 MISS ??? 1+1→2 2+1→2 2+X+1→1 ???

10
We need index table to detect internal segments Not frequent, but not that rare, handled by H/W state machine All entries considered dirty. S/W deals with evictions. LRU Replacement

11
Fast Case: Hit in a single range ◦ Return tag for that segment Medium Case: Multiple ranges, all cached ◦ Consecutive ranges must have different tags ◦ How to combine? Multiple Solutions: Reduce algorithm (eg Raksha style rules) Call S/W Bad Case: One or more segments miss ◦ S/W brings 64B segments to cache Main Memory: 2-Level table with 64B 2 nd level segments ◦ Reduce and repeat until read is serviced
 Call S/W Bad Case: One or more segments miss ◦ S/W brings 64B segments to cache Main Memory: 2-Level table with 64B 2 nd level segments ◦ Reduce and repeat until read is serviced.")
12
Double linked list for detecting internal segments

13
3 L/Gs ◦ TaintCheck 1-bit/byte ◦ MemCheck 2-bit/byte ◦ Tomography 32-bit/byte Apps ◦ SPEC, Java App, Store Webserver Verilog RTL Model ◦ 3000 gates for controller of cache Single issue, in-order CPU model

14
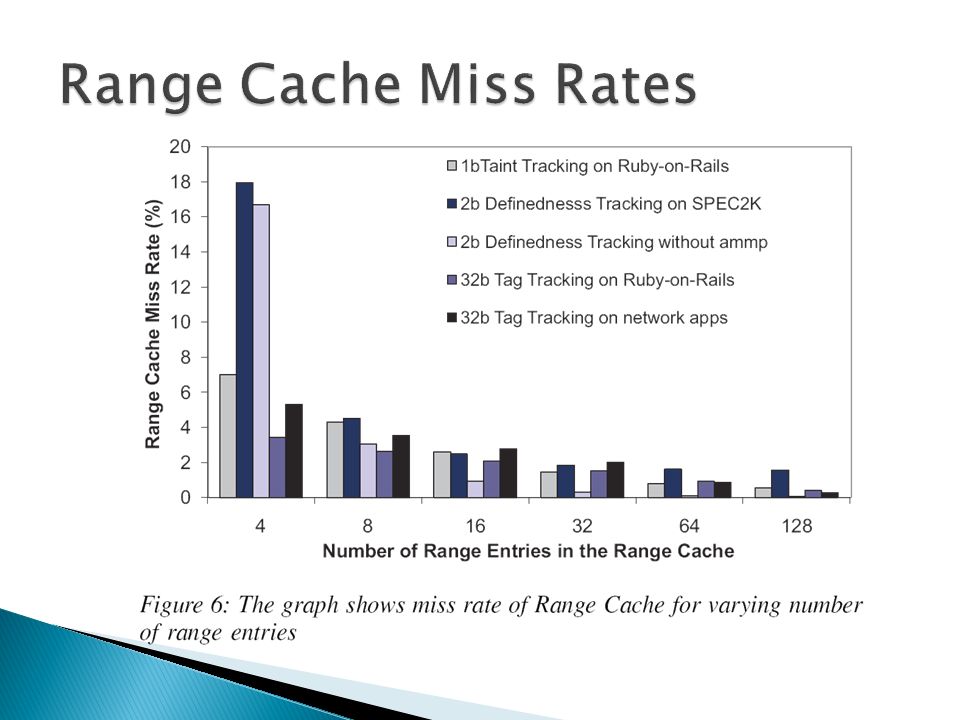
Maximum number of Tagged Ranges varies greatly: cannot be stored fully in cache ◦ Must support swapping Gcc: Snapshot of 128-entry cache 100/122 < 64B Largest > 2MB Fixed range-size ill-advised

15
Everyone spends time on simple read hits and silent updates ◦ TaintCheck spends time on “other updates” ◦ Other L/Gs have simple hits TaintCheck 1-bitMemCheck 2-bit Tomography 32-bit

17
4KB L1-T vs 128 entry Range Cache For Large States Range Cache winner For Small States almost equal Base=∞ L1-T with 0 misses

18
L2 misses increased caused by Increased mem refs (previous slide) L2 pollution by tags
 L2 pollution by tags")
19
Base=∞ L1-T with 0 misses TaintCheck 1-bit MemCheck 2-bit Difference usually minimal between L1-T and Range Cache for small states

20
Base=∞ L1-T with 0 misses L/G: 32-bit Tomography Significant Difference for large States

21
L1-T is a very simple scheme, easily handled by H/W ◦ Misses can be hidden with prefetch Will have the increase memory pressure, but hide the latency ◦ Prefetch can bypass L2 and bring tags directly to L1 Minimize the L2 pollution Range Cache scheme too complicated for H/W ◦ Must have S/W miss handler or complex H/W walk mechanism ◦ Effect on L1-I and TLB unaccounted for

22
Interesting approach to exploit the metadata spatial stability with good results ◦ Assuming fair comparison The equivalent of monochromatic-pages only Multiprocessor consistency quite tricky… Questions?

Similar presentations













 size of.>")
 November 6, 2008 Nael Abu-Ghazaleh.>")




