Download presentation
Presentation is loading. Please wait.

1
Cropland Mapping @30 using Google Earth Engine
Jun Xiong 29st Oct 2015

2
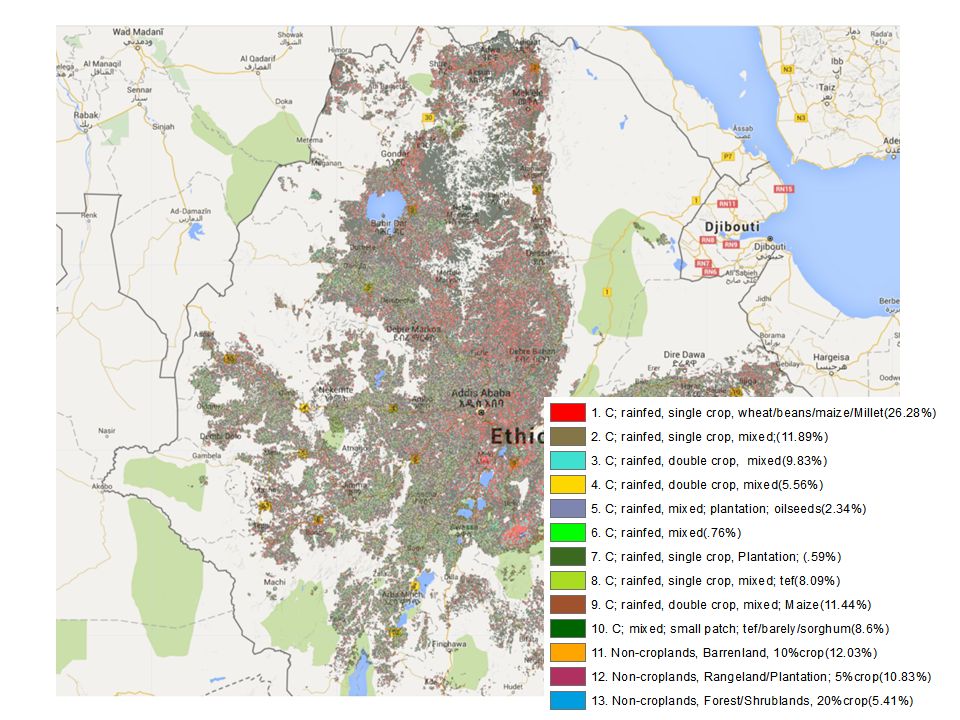
Ethiopia iso-data map @30m
Input Dataset: monthly Landsat EVI (id: LANDSAT/LC8_L1T_32DAY_EVI), Landsat image Band (5,4,3) in growing season (id: LANDSAT/LC8_L1T) Crop Extent Mask: resampled 250m GFSAD Crop-Extent integrated with 30m Global Land use map (Chen, 2014) Dimension: x x 12 bands (2.3e9 pixels, 2.5e8 after masking) Clustering: using GEE and Erdas2014 Results: 36 clusters from 30m NDVI Timeseries of 2014 Labeling: Scheme1 (13 classes) and Scheme2 (9 classes) were identified based on typical phenology, reference data and ground samples *Preliminary classification map was provided to Murali to help field work planning
, Landsat image Band (5,4,3) in growing season (id: LANDSAT/LC8_L1T) Crop Extent Mask: resampled 250m GFSAD Crop-Extent integrated with 30m Global Land use map (Chen, 2014) Dimension: x x 12 bands (2.3e9 pixels, 2.5e8 after masking) Clustering: using GEE and Erdas2014. Results: 36 clusters from 30m NDVI Timeseries of Labeling: Scheme1 (13 classes) and Scheme2 (9 classes) were identified based on typical phenology, reference data and ground samples. *Preliminary classification map was provided to Murali to help field work planning.")
3
Scheme1 signature (13 classes)
")
5
Comparison/Evaluation with 250m dataset

6
Regional Validation Green sites (n=567) are from image-interpretation results (partly provided by Curt, FAS. Red sites (n=278) from ground training part samples croplands.org (not used so far)
 from ground training part samples croplands.org (not used so far)")
7
ACCA development Future analysis to decide the final classes and labels in Ethiopia Can we define/separate smaller classes based on ground knowledge Can we get more information from other layers (Elevation, Indice…. etc) Automatic algorithm coding Scale the same approach to larger area
 Automatic algorithm coding. Scale the same approach to larger area.")
8
Oct 17-Oct 27: Ethiopia field work

9
Ethiopia field work using GFSAD mobile app following standard procedure (latest android version) When Dr. Gumma submitted Ethiopia ground samples to cropland.org, splitting of the samples to train/validation is demanded at once.

10
Kmeans available on GEE
Kmeans, Kmeans++ APIs available: WCascadeKMeans, wKmeans we are first exclusive testers on GEE. Not 100% Parallel Implement: Clustering computing still needs to be done in just one machine, while other I/O can be scaled to large dataset on multiply computers For large area/dataset, the size of samples is limited in 4GB memory 5 cases in different scale was tested ( from single Landsat scene to continental scale dataset) to locate the neck bottle Communication with GEE to make the APIs strong and more reliable for more users
 to locate the neck bottle. Communication with GEE to make the APIs strong and more reliable for more users.")
11
Concept of GEE-Kmeans // 1. create a small samples from dataset instead of using all the pixels. In the case, full image consists of 5e7 pixels. var training_features = image.sample({ region:geometry, scale:30, numPixels: 5e4 }); // 2. define a ‘cluster’ object var clusterer = ee.Clusterer.wCascadeKMeans({ minClusters:20, maxClusters:20, restarts:10, init:false, distanceFunction:"Euclidean", maxIterations:6}); // 3. Training & cluster clusterer = clusterer.train(training_features); var kmeans_image = image.cluster(clusterer); Because it is not 100% Parallel Implement. The clustering has been done on single machine, therefore, the size of sampling is limited by the physical memory of that machine. Once clustering of samples finished (cluster center and boundary is created), then the membership of entire dataset is simply determined.
; // 2. define a ‘cluster’ object var clusterer = ee.Clusterer.wCascadeKMeans({ minClusters:20, maxClusters:20, restarts:10, init:false, distanceFunction: Euclidean , maxIterations:6}); // 3. Training & cluster clusterer = clusterer.train(training_features); var kmeans_image = image.cluster(clusterer); Because it is not 100% Parallel Implement. The clustering has been done on single machine, therefore, the size of sampling is limited by the physical memory of that machine. Once clustering of samples finished (cluster center and boundary is created), then the membership of entire dataset is simply determined.")
12
* Scrips of all the cases could be running once your gee account be added to Kmeans whitelist

Similar presentations



 derived from the Visible Infrared Imaging Radiometer Suite (VIIRS) sensor onboard the SNPP satellite Zhangyan Jiang 1,2,>")






 Updates Pardhasaradhi.>")
 Updates Pardhasaradhi.>")


>")




