Download presentation
Presentation is loading. Please wait.

1
Advanced AI Neural Networks

2
Introduction Artificial Neural Network is based on the biological nervous system as Brain It is composed of interconnected computing units called neurons ANN like human, learn by examples

3
3 Science: Model how biological neural systems, like human brain, work? How do we see? How is information stored in/retrieved from memory? How do you learn to not to touch fire? How do your eyes adapt to the amount of light in the environment? Related fields: Neuroscience, Computational Neuroscience, Psychology, Psychophysiology, Cognitive Science, Medicine, Math, Physics.

5
History Roots of work on NN are in: Neurobiological studies (more than one century ago): How do nerves behave when stimulated by different magnitudes of electric current? Is there a minimal threshold needed for nerves to be activated? Given that no single nerve cel is long enough, how do different nerve cells communicate among each other? Psychological studies: How do animals learn, forget, recognize and perform other types of tasks? Psycho-physical experiments helped to understand how individual neurons and groups of neurons work. McCulloch and Pitts introduced the first mathematical model of single neuron, widely applied in subsequent work.

6
History Widrow and Hoff (1960): Adaline Minsky and Papert (1969): limitations of single-layer perceptrons (and they erroneously claimed that the limitations hold for multi-layer perceptrons) Stagnation in the 70's: Individual researchers continue laying foundations von der Marlsburg (1973): competitive learning and self-organization Big neural-nets boom in the 80's Grossberg: adaptive resonance theory (ART) Hopfield: Hopfield network Kohonen: self-organising map (SOM)
: Adaline Minsky and Papert (1969): limitations of single-layer perceptrons (and they erroneously claimed that the limitations hold for multi-layer perceptrons) Stagnation in the 70 s: Individual researchers continue laying foundations von der Marlsburg (1973): competitive learning and self-organization Big neural-nets boom in the 80 s Grossberg: adaptive resonance theory (ART) Hopfield: Hopfield network Kohonen: self-organising map (SOM)")
7
12/16/20157 Brief History Old Ages: Association (William James; 1890) McCulloch-Pitts Neuron (1943,1947) Perceptrons (Rosenblatt; 1958,1962) Adaline/LMS (Widrow and Hoff; 1960) Perceptrons book (Minsky and Papert; 1969) Dark Ages: Self-organization in visual cortex (von der Malsburg; 1973) Backpropagation (Werbos, 1974) Foundations of Adaptive Resonance Theory (Grossberg; 1976) Neural Theory of Association (Amari; 1977)
 McCulloch-Pitts Neuron (1943,1947) Perceptrons (Rosenblatt; 1958,1962) Adaline/LMS (Widrow and Hoff; 1960) Perceptrons book (Minsky and Papert; 1969) Dark Ages: Self-organization in visual cortex (von der Malsburg; 1973) Backpropagation (Werbos, 1974) Foundations of Adaptive Resonance Theory (Grossberg; 1976) Neural Theory of Association (Amari; 1977)")
8
12/16/20158 History Modern Ages: Adaptive Resonance Theory (Grossberg; 1980) Hopfield model (Hopfield; 1982, 1984) Self-organizing maps (Kohonen; 1982) Reinforcement learning (Sutton and Barto; 1983) Simulated Annealing (Kirkpatrick et al.; 1983) Boltzmann machines (Ackley, Hinton, Terrence; 1985) Backpropagation (Rumelhart, Hinton, Williams; 1986) ART-networks (Carpenter, Grossberg; 1992) Support Vector Machines
 Hopfield model (Hopfield; 1982, 1984) Self-organizing maps (Kohonen; 1982) Reinforcement learning (Sutton and Barto; 1983) Simulated Annealing (Kirkpatrick et al.; 1983) Boltzmann machines (Ackley, Hinton, Terrence; 1985) Backpropagation (Rumelhart, Hinton, Williams; 1986) ART-networks (Carpenter, Grossberg; 1992) Support Vector Machines")
9
12/16/20159 McCulloch-Pitts McCulloch-Pitts (1943): The first computational neuron model. Showed that networks made from these neurons can implement logic functions, such as AND, OR, XOR. Therefore these networks are universal computation devices. Assumptions made: Neuron activation is binary. At least a certain number of excitatory inputs are needed to excite the neuron. Even a single inhibitory input can inhibit the neuron. No delay. Network structure is fixed. No adaptation!

10
12/16/201510 Hebb’s Learning Law In 1949, Donald Hebb formulated William James’ principle of association into a mathematical form. If the activation of the neurons, y 1 and y 2, are both on (+1) then the weight between the two neurons grow. (Off: 0) Else the weight between remains the same. However, when bipolar activation {-1,+1} scheme is used, then the weights can also decrease when the activation of two neurons does not match.
 then the weight between the two neurons grow. (Off: 0) Else the weight between remains the same. However, when bipolar activation {-1,+1} scheme is used, then the weights can also decrease when the activation of two neurons does not match..")
11
Applications Classification: –Image recognition –Speech recognition –Diagnostic –Fraud detection –… Regression: –Forecasting (prediction on base of past history) –… Pattern association: –Retrieve an image from corrupted one –… Clustering: –clients profiles –disease subtypes –…
 –… Pattern association: –Retrieve an image from corrupted one –… Clustering: –clients profiles –disease subtypes –…")
12
12 Biological Neurons Human brain = tens of thousands of neurons Each neuron is connected to thousands other neurons A neuron is made of: –The soma: body of the neuron –Dendrites: filaments that provide input to the neuron –The axon: sends an output signal –Synapses: connection with other neurons – releases certain quantities of chemicals called neurotransmitters to other neurons

13
13 The biological neuron The pulses generated by the neuron travels along the axon as an electrical wave. Once these pulses reach the synapses at the end of the axon open up chemical vesicles exciting the other neuron.

14
Neural Network

15
Simple Neuron X1 X2 Xn OutputInputs

16
Neural Network Application Pattern recognition can be implemented using NN The figure can be T or H character, the network should identify each class of T or H.

17
12/16/201517 Navigation of a car Done by Pomerlau. The network takes inputs from a 34X36 video image and a 7X36 range finder. Output units represent “drive straight”, “turn left” or “turn right”. After training about 40 times on 1200 road images, the car drove around CMU campus at 5 km/h (using a small workstation on the car). This was almost twice the speed of any other non-NN algorithm at the time.
. This was almost twice the speed of any other non-NN algorithm at the time..")
18
18 Automated driving at 70 mph on a public highway Camera image 30x32 pixels as inputs 30 outputs for steering 30x32 weights into one out of four hidden unit 4 hidden units

19
NN ● An Artificial Neural Network is specified by: − neuron model: the information processing unit of the NN, − an architecture: a set of neurons and links connecting neurons. Each link has a weight, − a learning algorithm: used for training the NN by modifying the weights in order to model a particular learning task correctly on the training examples. ● The aim is to obtain a NN that is trained and generalizes well. ● It should behaves correctly on new instances of the learning task.

20
Neuron Model A neuron has more than one input x 1, x 2,..,x m Each input is associated with a weight w 1, w 2,..,w m The neuron has a bias b The net input of the neuron is n = w 1 x 1 + w 2 x 2 +….+ w m x m + b

21
The Neuron Diagram Input values weights Summing function Bias b Activation function Induced Field v Output y x1x1 x2x2 xmxm w2w2 wmwm w1w1

22
Bias of a Neuron ● The bias b has the effect of applying a transformation to the weighted sum u v = u + b ● The bias is an external parameter of the neuron. It can be modeled by adding an extra input. ● v is called induced field of the neuron

23
Neuron output The neuron output is y = f (n) f is called transfer function
 f is called transfer function")
24
Transfer Function We have 3 common transfer functions –Hard limit transfer function –Linear transfer function –Sigmoid transfer function

25
Hard Limit Transfer Function It returns 0 if the input is less than 0 or 1 if the input is greater than or equal to 0

26
Linear Function The linear transfer function gives the output is equal to the input y= n

27
Sigmoid function

28
Simple Neuron Inputs f X1 X2 Xn Output W1 W2 Wn

29
The Gaussian function is the probability function of the normal distribution. Sometimes also called the frequency curve.

30
Exercises The input to a single-input neuron is 2.0, its weight is 2.3 and the bias is –3. What is the output of the neuron if it has transfer function as: –Hard limit –Linear –sigmoid

31
Exercises The input to a single input neuron is 2.0, its weight is 1.3 and the bias is 3.0. What possible transfer function to get the output as: –1.6 –1.0 –0.9963

32
Exercises Consider a single input neuron with a bias. We the output to be –1 for inputs less than 3 and +1 for inputs greater than or equal 3. What kind of transfer function is required and bias. Draw the network and state the weights.

33
Neural Network Input LayerHidden 1Hidden 2Output Layer

34
Network Layers The common type of ANN consists of three layers of neurons: a layer of input neurons connected to the layer of hidden neuron which is connected to a layer of output neurons.

35
Network Layers The activity of input units represents the information that is fed into the network The activity of hidden unit is determined by activities of input units and weights between input and hidden units The activity of output unit is determined by activities of hidden units and weights between hidden and output units

36
Architecture of ANN Feed-Forward networks Allow the signals to travel one way from input to output Feed-Back Networks The signals travel as loops in the network, the output is connected to the input of the network

37
Network Architectures ● Three different classes of network architectures − single-layer feed-forward − multi-layer feed-forward − recurrent ● The architecture of a neural network is linked with the learning algorithm used to train

38
Learning Rule The learning rule modifies the weights of the connections. The learning process is divided into Supervised and Unsupervised learning

39
Supervised Network Which means there exists an external teacher. The target is to minimization of the error between the desired and computed output

40
Unsupervised Network Uses no external teacher and is based upon only local information.

41
Perceptron It is a network of one neuron and hard limit transfer function Inputs f X1 X2 Xn Output W1 W2 Wn

42
Perceptron: Neuron Model (Special form of single layer feed forward) − The perceptron was first proposed by Rosenblatt (1958) is a simple neuron that is used to classify its input into one of two categories. − A perceptron uses a step function that returns +1 if weighted sum of its input 0 and -1 otherwise x1x1 x2x2 xnxn w2w2 w1w1 wnwn b (bias) vy (v)
 vy (v).")
43
Perceptron The perceptron is given first a randomly weights vectors Perceptron is given chosen data pairs (input and desired output) Preceptron learning rule changes the weights according to the error in output
 Preceptron learning rule changes the weights according to the error in output")
44
Perceptron Learning Rule W new = W old + (t-a) X Where W new is the new weight W old is the old value of weight X is the input value t is the desired value of output a is the actual value of output
 X Where W new is the new weight W old is the old value of weight X is the input value t is the desired value of output a is the actual value of output")
45
Learning Process for Perceptron ● Initially assign random weights to inputs between -0.5 and +0.5 ● Training data is presented to perceptron and its output is observed. ● If output is incorrect, the weights are adjusted accordingly using following formula. wi wi + (a* xi *e), where ‘e’ is error produced and ‘a’ (-1 a 1) is learning rate − ‘a’ is defined as 0 if output is correct, it is +ve, if output is too low and –ve, if output is too high. − Once the modification to weights has taken place, the next piece of training data is used in the same way. − Once all the training data have been applied, the process starts again until all the weights are correct and all errors are zero. − Each iteration of this process is known as an epoch.
, where ‘e’ is error produced and ‘a’ (-1 a 1) is learning rate − ‘a’ is defined as 0 if output is correct, it is +ve, if output is too low and –ve, if output is too high. − Once the modification to weights has taken place, the next piece of training data is used in the same way. − Once all the training data have been applied, the process starts again until all the weights are correct and all errors are zero. − Each iteration of this process is known as an epoch..")
46
Example: Perceptron to learn OR function ● Initially consider w1 = -0.2 and w2 = 0.4 ● Training data say, x1 = 0 and x2 = 0, output is 0. ● Compute y = Step(w1*x1 + w2*x2) = 0. Output is correct so weights are not changed. ● For training data x1=0 and x2 = 1, output is 1 ● Compute y = Step(w1*x1 + w2*x2) = 0.4 = 1. Output is correct so weights are not changed. ● Next training data x1=1 and x2 = 0 and output is 1 ● Compute y = Step(w1*x1 + w2*x2) = - 0.2 = 0. Output is incorrect, hence weights are to be changed. ● Assume a = 0.2 and error e=1 wi = wi + (a * xi * e) gives w1 = 0 and w2 =0.4 ● With these weights, test the remaining test data. ● Repeat the process till we get stable result.
 = 0. Output is correct so weights are not changed. ● For training data x1=0 and x2 = 1, output is 1 ● Compute y = Step(w1*x1 + w2*x2) = 0.4 = 1. Output is correct so weights are not changed. ● Next training data x1=1 and x2 = 0 and output is 1 ● Compute y = Step(w1*x1 + w2*x2) = = 0. Output is incorrect, hence weights are to be changed. ● Assume a = 0.2 and error e=1 wi = wi + (a * xi * e) gives w1 = 0 and w2 =0.4 ● With these weights, test the remaining test data. ● Repeat the process till we get stable result..")
47
Example Let –X1 = [0 0] and t =0 –X2 = [01] and t=0 –X3 = [10] and t=0 –X4 = [11] and t=1 W = [22] and b = -3
![Example Let –X1 = [0 0] and t =0 –X2 = [01] and t=0 –X3 = [10] and t=0 –X4 = [11] and t=1 W = [22] and b = -3](http://images.slideplayer.com/27/8928327/slides/slide_47.jpg "Example Let –X1 = [0 0] and t =0 –X2 = [01] and t=0 –X3 = [10] and t=0 –X4 = [11] and t=1 W = [22] and b = -3")
48
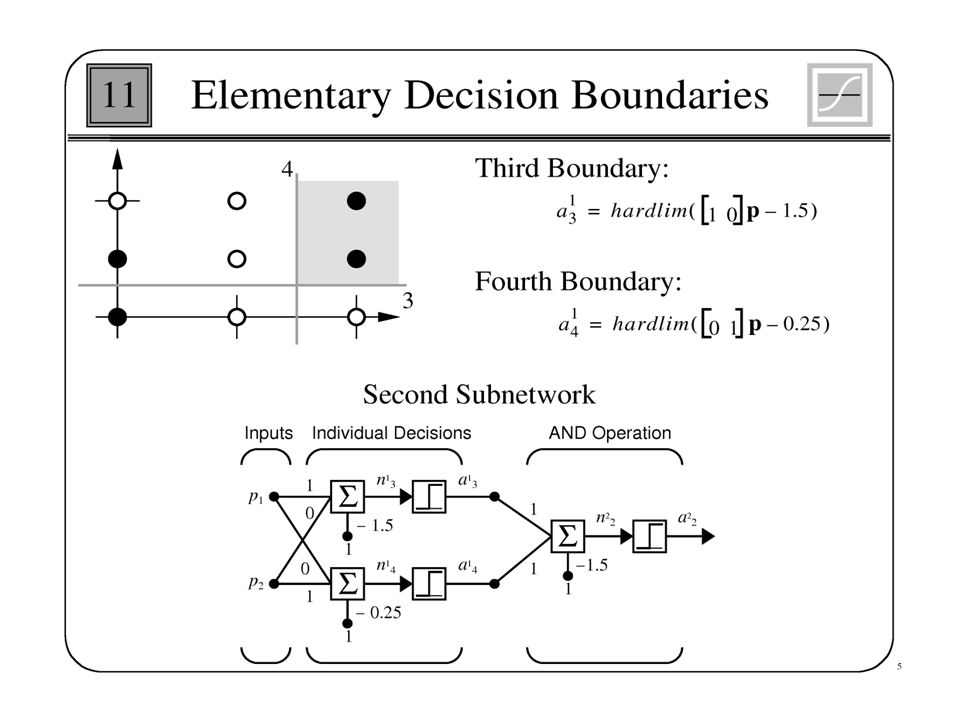
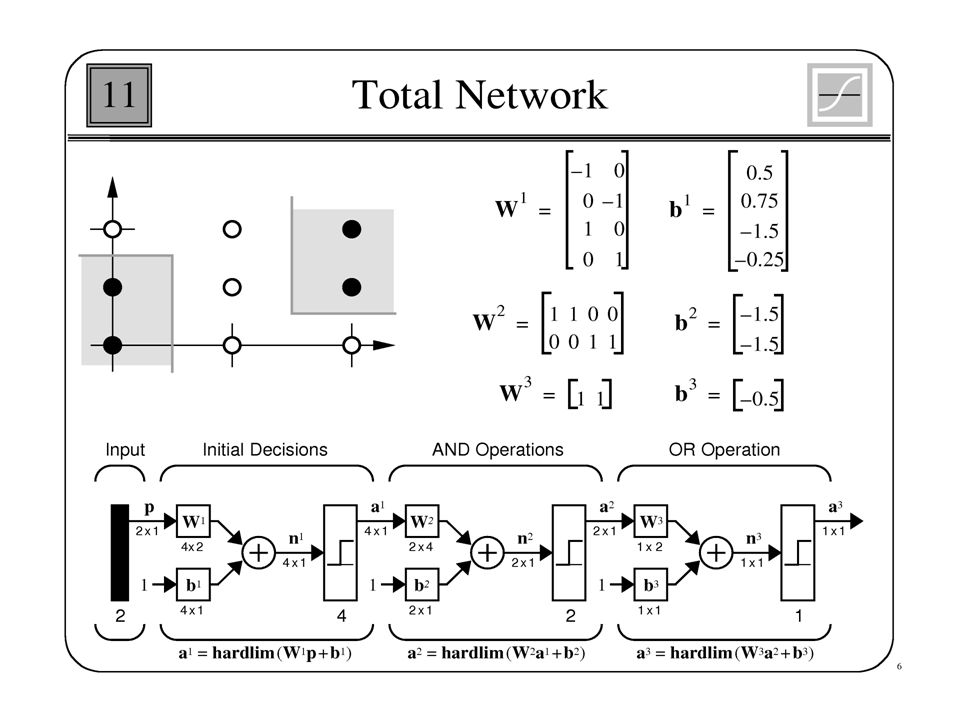
AND Network This example means we construct a network for AND operation. The network draw a line to separate the classes which is called Classification

49
Perceptron Geometric View The equation below describes a (hyper-)plane in the input space consisting of real valued m-dimensional vectors. The plane splits the input space into two regions, each of them describing one class. x2x2 C1C1 C2C2 x1x1 decision boundary w 1 x 1 + w 2 x 2 + w 0 = 0 decision region for C1 w 1 x 1 + w 2 x 2 + w 0 >= 0

50
Problems Four one-dimensional data belonging to two classes are X = [1-0.53-2] T = [1-11-1] W = [-2.51.75]
![Problems Four one-dimensional data belonging to two classes are X = [ ] T = [1-11-1] W = [ ]](http://images.slideplayer.com/27/8928327/slides/slide_50.jpg "Problems Four one-dimensional data belonging to two classes are X = [ ] T = [1-11-1] W = [ ]")
51
The First Neural Neural Networks AND Function 1 1 X1X1 X2X2 Y Threshold(Y) = 2
 = 2")
52
Simple Networks t = 0.0 y x W = 1.5 W = 1

53
Exercises Design a neural network to recognize the problem of X1=[22], t1=0 X=[1-2], t2=1 X3=[-22], t3=0 X4=[-11], t4=1 Start with initial weights w=[0 0] and bias =0
![Exercises Design a neural network to recognize the problem of X1=[22], t1=0 X=[1-2], t2=1 X3=[-22], t3=0 X4=[-11], t4=1 Start with initial weights w=[0 0] and bias =0](http://images.slideplayer.com/27/8928327/slides/slide_53.jpg "Exercises Design a neural network to recognize the problem of X1=[22], t1=0 X=[1-2], t2=1 X3=[-22], t3=0 X4=[-11], t4=1 Start with initial weights w=[0 0] and bias =0")
54
Example+1+1+1+1+1+1+1+1+1 - 1 +1+1+1+1+1

55
Example+1+1+1+1+1+1+1+1+1+1 - 1 +1+1+1+1+1

56
Perceptron: Limitations The perceptron linearly separable classes, The perceptron can only model linearly separable classes, like (those described by) the following Boolean functions: AND OR COMPLEMENT cannot XOR It cannot model the XOR. You can experiment with these functions in the Matlab practical lessons.

57
These two classes (true and false) cannot be separated using a line. Hence XOR is non linearly separable.

58
Types of decision regions x1 1 x2w2 w1 w0 Convex region L1 L2 L3 L4 -3.5 Network with a single node One-hidden layer network that realizes the convex region 1 1 1 1 1 x1 x2 1

59
Multi-layers Network Let the network of 3 layers –Input layer –Hidden layer –Output layer Each layer has different number of neurons The famous example to need the multi-layer network is XOR unction

60
FFNN for XOR ● The ANN for XOR has two hidden nodes that realizes this non-linear separation and uses the sign (step) activation function. ● Arrows from input nodes to two hidden nodes indicate the directions of the weight vectors (1,-1) and (-1,1). ● The output node is used to combine the outputs of the two hidden nodes.
 and (-1,1). ● The output node is used to combine the outputs of the two hidden nodes..")
65
Learning rule The perceptron learning rule can not be applied to multi-layer network We use BackPropagation Algorithm in learning process

66
66 Feed-forward + Backpropagation Feed-forward : –input from the features is fed forward in the network from input layer towards the output layer Backpropagation: –Method to asses the blame of errors to weights –error rate flows backwards from the output layer to the input layer (to adjust the weight in order to minimize the output error)
")
67
Backprop Back-propagation training algorithm illustrated: Backprop adjusts the weights of the NN in order to minimize the network total mean squared error. Network activation Error computation Forward Step Error propagation Backward Step

68
68 Backpropagation In a multilayer network… Computing the error in the output layer is clear. Computing the error in the hidden layer is not clear, because we don’t know what output it should be Intuitively: A hidden node h is “responsible” for some fraction of the error in each of the output node to which it connects. So the error values ( δ ) are divided according to the weight of their connection between the hidden node and the output node and are propagated back to provide the error values ( δ ) for the hidden layer.
 are divided according to the weight of their connection between the hidden node and the output node and are propagated back to provide the error values ( δ ) for the hidden layer..")
69
12/16/201569 The delta rule w ij

70
12/16/201570 The generalized delta rule w ij w jk o pi oioi

71
12/16/201571 Cont’d w ij

72
12/16/201572

73
12/16/201573 w jk o pj j w jk

74
12/16/201574 In short.. w jk w ij

75
Bp Algorithm The weight change rule is Where is the learning factor <1 Error is the error between actual and trained value f’ is is the derivative of sigmoid function = f(1-f)
")
76
Delta Rule Each observation contributes a variable amount to the output The scale of the contribution depends on the input Output errors can be blamed on the weights A least mean square (LSM) error function can be defined (ideally it should be zero) E = ½ (t – y) 2
 error function can be defined (ideally it should be zero) E = ½ (t – y) 2")
77
Stopping criterions ● Total mean squared error change: − Back-prop is considered to have converged when the absolute rate of change in the average squared error per epoch is sufficiently small (in the range [0.1, 0.01]). ● Generalization based criterion: − After each epoch, the NN is tested for generalization. − If the generalization performance is adequate then stop. − If this stopping criterion is used then the part of the training set used for testing the network generalization will not used for updating the weights.
![Stopping criterions ● Total mean squared error change: − Back-prop is considered to have converged when the absolute rate of change in the average squared error per epoch is sufficiently small (in the range [0.1, 0.01]).](http://images.slideplayer.com/27/8928327/slides/slide_77.jpg "● Generalization based criterion: − After each epoch, the NN is tested for generalization. − If the generalization performance is adequate then stop. − If this stopping criterion is used then the part of the training set used for testing the network generalization will not used for updating the weights..")
78
Example For the network with one neuron in input layer and one neuron in hidden layer the following values are given X=1, w1 =1, b1=-2, w2=1, b2 =1, =1 and t=1 Where X is the input value W1 is the weight connect input to hidden W2 is the weight connect hidden to output B1 and b2 are bias T is the training value

79
Exercises Design a neural network to recognize the problem of X1=[22], t1=0 X=[1-2], t2=1 X3=[-22], t3=0 X4=[-11], t4=1 Start with initial weights w=[0 0] and bias =0
![Exercises Design a neural network to recognize the problem of X1=[22], t1=0 X=[1-2], t2=1 X3=[-22], t3=0 X4=[-11], t4=1 Start with initial weights w=[0 0] and bias =0](http://images.slideplayer.com/27/8928327/slides/slide_79.jpg "Exercises Design a neural network to recognize the problem of X1=[22], t1=0 X=[1-2], t2=1 X3=[-22], t3=0 X4=[-11], t4=1 Start with initial weights w=[0 0] and bias =0")
80
Exercises Perform one iteration of backprpgation to network of two layers. First layer has one neuron with weight 1 and bias –2. The transfer function in first layer is f=n2 The second layer has only one neuron with weight 1 and bias 1. The f in second layer is 1/n. The input to the network is x=1 and t=1

81
Neural Network Construct a neural network to solve the problem X1X2Output 1.0 1 9.46.4 2.52.11 8.07.7 0.52.21 7.98.4 7.0 2.80.81 1.23.01 7.86.1 Initialize the weights 0.75, 0.5, and –0.6

82
Neural Network Construct a neural network to solve the XOR problem X1X2Output 110 000 101 011 Initialize the weights –7.0, -7.0, -5.0 and –4.0

83
-0.5 -2 3 1 1 1 1 0.5 The transfer function is linear function.

84
Consider a transfer function as f(n) = n2. Perform one iteration of BackPropagation with a= 0.9 for neural network of two neurons in input layer and one neuron in output layer. The input values are X=[1 -1] and t = 8, the weight values between input and hidden layer are w11 = 1, w12 = - 2, w21 = 0.2, and w22 = 0.1. The weight between input and output layers are w1 = 2 and w2= -2. The bias in input layers are b1 = -1, and b2= 3.

85
Building Neural Networks Define the problem in terms of neurons –think in terms of layers Represent information as neurons –operationalize neurons –select their data type –locate data for testing and training Define the network Train the network Test the network

86
● Data representation depends on the problem. ● In general ANNs work on continuous (real valued) attributes. Therefore symbolic attributes are encoded into continuous ones. ● Attributes of different types may have different ranges of values which affect the training process. ● Normalization may be used, like the following one which scales each attribute to assume values between 0 and 1. for each value x i of i th attribute, min i and max i are the minimum and maximum value of that attribute over the training set. Data Representation
 attributes. Therefore symbolic attributes are encoded into continuous ones. ● Attributes of different types may have different ranges of values which affect the training process. ● Normalization may be used, like the following one which scales each attribute to assume values between 0 and 1. for each value x i of i th attribute, min i and max i are the minimum and maximum value of that attribute over the training set. Data Representation.")
87
12/16/201587 The local minima problem Unlike LMS, the error function is not smooth with a single minima. Local minima can occur, in which case a true gradient descent is not desirable.Momentum, incremental updates, and a large learning rate make “jiggly” path that can avoid local minimas.

88
12/16/201588 Some variations True gradient descent assumes infinitesmall learning rate ( ). If is too small then learning is very slow. If large, then the system's learning may never converge. Some of the possible solutions to this problem are: –Add a momentum term to allow a large learning rate. –Use a different activation function –Use a different error function –Use an adaptive learning rate –Use a good weight initialization procedure. –Use a different minimization procedure

89
12/16/201589 Momentum The most widely used trick is to remember the direction of earlier steps.Weight update becomes: w ij (n+1) = ( pj o pi ) + w ij (n) The momentum parameter is chosen between 0 and 1, typically 0.9. This allows one to use higher learning rates. The momentum term filters out high frequency oscillations on the error surface. What would the learning rate be in a deep valley?

90
12/16/201590 Genetic algorithms

91
● How are the weights initialized? ● How is the learning rate chosen? ● How many hidden layers and how many neurons? ● How many examples in the training set? Network parameters

92
Initialization of weights ● In general, initial weights are randomly chosen, with typical values between -1.0 and 1.0 or -0.5 and 0.5. ● If some inputs are much larger than others, random initialization may bias the network to give much more importance to larger inputs. ● In such a case, weights can be initialized as follows: For weights from the input to the first layer For weights from the first to the second layer

93
● The right value of depends on the application. ● Values between 0.1 and 0.9 have been used in many applications. ● Other heuristics is that adapt during the training as described in previous slides. Choice of learning rate

94
Recurrent Network ● FFNN is acyclic where data passes from input to the output nodes and not vice versa. − Once the FFNN is trained, its state is fixed and does not alter as new data is presented to it. It does not have memory. ● Recurrent network can have connections that go backward from output to input nodes and models dynamic systems. − In this way, a recurrent network’s internal state can be altered as sets of input data are presented. It can be said to have memory. − It is useful in solving problems where the solution depends not just on the current inputs but on all previous inputs. ● Applications − predict stock market price, − weather forecast

95
● Recurrent Network with hidden neuron: unit delay operator d is used to model a dynamic system d d d Recurrent Network Architecture input hidden output

96
Learning and Training ● During learning phase, − a recurrent network feeds its inputs through the network, including feeding data back from outputs to inputs − process is repeated until the values of the outputs do not change. ● This state is called equilibrium or stability ● Recurrent networks can be trained by using back- propagation algorithm. ● In this method, at each step, the activation of the output is compared with the desired activation and errors are propagated backward through the network. ● Once this training process is completed, the network becomes capable of performing a sequence of actions.

97
Hopfield Network ● A Hopfield network is a kind of recurrent network as output values are fed back to input in an undirected way. − It consists of a set of N connected neurons with weights which are symmetric and no unit is connected to itself. − There are no special input and output neurons. − The activation of a neuron is binary value decided by the sign of the weighted sum of the connections to it. − A threshold value for each neuron determines if it is a firing neuron. − A firing neuron is one that activates all neurons that are connected to it with a positive weight. − The input is simultaneously applied to all neurons, which then output to each other. − This process continues until a stable state is reached.

98
Activation Algorithm Active unit represented by 1 and inactive by 0. ● Repeat − Choose any unit randomly. The chosen unit may be active or inactive. − For the chosen unit, compute the sum of the weights on the connection to the active neighbours only, if any. If sum > 0 (threshold is assumed to be 0), then the chosen unit becomes active, otherwise it becomes inactive. − If chosen unit has no active neighbours then ignore it, and status remains same. ● Until the network reaches to a stable state
, then the chosen unit becomes active, otherwise it becomes inactive. − If chosen unit has no active neighbours then ignore it, and status remains same. ● Until the network reaches to a stable state.")
100
Stable Networks

101
Weight Computation Method ● Weights are determined using training examples. ● Here − W is weight matrix − Xi is an input example represented by a vector of N values from the set {–1, 1}. − Here, N is the number of units in the network; 1 and -1 represent active and inactive units respectively. − (Xi) T is the transpose of the input Xi, − M denotes the number of training input vectors, − I is an N × N identity matrix.
 T is the transpose of the input Xi, − M denotes the number of training input vectors, − I is an N × N identity matrix..")
102
Example ● Let us now consider a Hopfield network with four units and three training input vectors that are to be learned by the network. ● Consider three input examples, namely, X1, X2, and X3 defined as follows:

104
Contd.. ● The networks generated using these weights and input vectors are stable, except X2. ● X2 stabilizes to X1 (which is at hamming distance 1). ● Finally, with the obtained weights and stable states (X1 and X3), we can stabilize any new (partial) pattern to one of those
. ● Finally, with the obtained weights and stable states (X1 and X3), we can stabilize any new (partial) pattern to one of those.")
105
Radial-Basis Function Networks ● A function is said to be a radial basis function (RBF) if its output depends on the distance of the input from a given stored vector. − The RBF neural network has an input layer, a hidden layer and an output layer. − In such RBF networks, the hidden layer uses neurons with RBFs as activation functions. − The outputs of all these hidden neurons are combined linearly at the output node. ● These networks have a wide variety of applications such as − function approximation, − time series prediction, − control and regression, − pattern classification tasks for performing complex (non-linear).
..")
106
RBF Architecture ● One hidden layer with RBF activation functions ● Output layer with linear activation function. x2x2 xmxm x1x1 y w m1 w1w1

107
Cont... ● Here we require weights, w i from the hidden layer to the output layer only. ● The weights w i can be determined with the help of any of the standard iterative methods described earlier for neural networks. ● However, since the approximating function given below is linear w. r. t. w i, it can be directly calculated using the matrix methods of linear least squares without having to explicitly determine w i iteratively. ● It should be noted that the approximate function f(X) is differentiable with respect to w i.
 is differentiable with respect to w i..")
108
RBF NNFF NN Non-linear layered feed-forward networks. Non-linear layered feed-forward networks Hidden layer of RBF is non-linear, the output layer of RBF is linear. Hidden and output layers of FFNN are usually non-linear. One single hidden layerMay have more hidden layers. Neuron model of the hidden neurons is different from the one of the output nodes. Hidden and output neurons share a common neuron model. Activation function of each hidden neuron in a RBF NN computes the Euclidean distance between input vector and the center of that unit. Activation function of each hidden neuron in a FFNN computes the inner product of input vector and the synaptic weight vector of that neuron Comparison

Similar presentations






>")

>")

>")










 l Biological Neurons l Artificial Neurons l Perceptrons l Multilayer Neural Networks l Backpropagation.>")


