Download presentation
Presentation is loading. Please wait.

1
컴퓨터 과학부 김명재

2
Introduction Data Preprocessing Model Selection Experiments

3
Support Vector Machine

4
SVM (Support vector machine) ◦ Training set of instance-label pairs ◦ where ◦ Objective function subject to
 ◦ Training set of instance-label pairs ◦ where ◦ Objective function subject to")
5
Dual space form ◦ Objective function maximize subject to

6
Nonlinear SVM ◦ Kernel method Training vectors Mapped into a higher dimensional space Maybe infinite Mapping function Objective function

7
◦ Kernel function Linear Polynomial Radial basis function Sigmoid are kernel parameter

8
Example ◦ Data url http://www.csie.ntu.edu.tw/~cjlin/papers/guide/data/ http://www.csie.ntu.edu.tw/~cjlin/papers/guide/data/ Application#training data #testing data #features#classes Astroparticle3, 0894,00042 Bioinfomatics3910203 Vehicle1,24341212

9
Proposed Procedure ◦ Transform data to format of an SVM package ◦ Conduct simple scaling on the data ◦ Consider the RBF kernel ◦ Use cross-validation to find the best parameter and ◦ Use the best parameter and to train the whole training set ◦ Test

10
Categorical Feature ◦ Example Three-category such as {red, green, blue} can be represented as (0, 0, 1), (0, 1, 0), and (1, 0, 0) Scaling ◦ Scaling before applying SVM is very important. ◦ Linearly scaling each attribute to the range [-1, +1] or [0, 1].

11
RBF kernel ◦ RBF kernel is a reasonable first choice ◦ Nonlinearly maps samples into a higher dimensional space ◦ The number of hyperparameters which influences the complexity of model selection. ◦ Fewer numerical difficulties

12
Cross-validation

13
◦ Find the good ◦ Avoid the overfitting problem ◦ v-fold cross-validation Divide the training set into v subsets of equal size Sequentially, on subset is tested using the classifier trained on the remaining v-1 subsets.

14
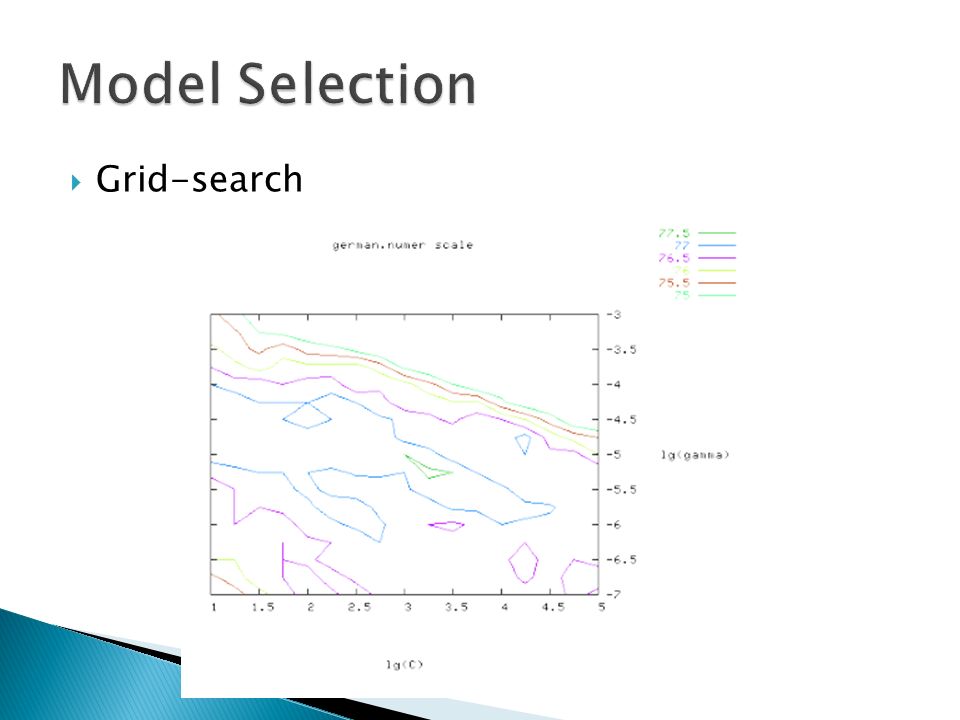
Grid-search ◦ Various pairs of ◦ Find a good parameter for example

15
Grid-search

17
Astroparticle Physics ◦ original accuracy 66.925 % ◦ after scaling 96.15 % ◦ after grid-search 96.875 % (3875/4000)
")
18
Bioinformatics ◦ original cross validation accuracy 56.5217 % ◦ after scaling cross validation accuracy 78.5166 % ◦ after grid-search 85.1662 %

19
Vehicle ◦ original accuracy 2.433902 % ◦ after scaling 12.1951 % ◦ after grid-searching 87.8049 % (36/41)
")
20
libSVM ◦ http://www.csie.ntu.edu.tw/~cjlin/libsvm/ http://www.csie.ntu.edu.tw/~cjlin/libsvm/ A Training Algorithm for optimal Margin classifiers ◦ Bernhard E. Boser, Isabelle M. Guyon, Vladimir N. Vapnik 수업교재

21
end of pages

Similar presentations
>")


>")

 of the slides are taken from Prof.>")









 Chapter 5 (Duda et al.)>")



