Download presentation
Presentation is loading. Please wait.

1
1 CSC 4510, Spring 2012. © Paula Matuszek 2012. CSC 4510 Support Vector Machines (SVMs)
")
2
2 CSC 4510, Spring 2012. © Paula Matuszek 2012. A Motivating Problem People who set up bird feeders want to feed birds. We don’t want to feed squirrels –they eat too fast –they drive the birds away So how do we create a bird feeder that isn’t a squirrel feeder?

3
3 CSC 4510, Spring 2012. © Paula Matuszek 2012. Birds vs Squirrels How are birds and squirrels different? Take a moment and write down a couple of features that distinguish birds from squirrels.

4
4 CSC 4510, Spring 2012. © Paula Matuszek 2012. Birds vs Squirrels How are birds and squirrels different? Take a moment and write down a couple of features that distinguish birds from squirrels. And now take another and write down how YOU tell a bird from a squirrel.

5
5 CSC 4510, Spring 2012. © Paula Matuszek 2012. Possible Features Birds – Squirrels – And what do people actually do?

6
6 CSC 4510, Spring 2012. © Paula Matuszek 2012. The Typical Bird Feeder Solutions Squirrels are heavier Squirrels can’t fly

7
7 CSC 4510, Spring 2012. © Paula Matuszek 2012. And Then There’s This: http://youtu.be/_mbvqxjFZpE http://www.slideshare.net/kgrandis/pycon-2012-militarizing-your- backyard-computer-vision-and-the-squirrel-hordes

8
8 CSC 4510, Spring 2012. © Paula Matuszek 2012. Knowledge for SVMs We are trying here to emulate our human decision making about whether something is a squirrel. So we will have: –Features –A classification As we saw in our discussion, there are a couple of obvious features, but mostly we decide based on a number of visual cues: size, color, general arrangement of pixels.

9
9 CSC 4510, Spring 2012. © Paula Matuszek 2012. Kurt Grandis’ Squirrel Gun The water gun is driven by a system which –uses a camera to watch the bird feeder –detects blobs –determines whether the blob is a squirrel –targets the squirrel –shoots! Mostly in Python, using openCV for the vision. Of interest to us is that decision about whether a blob is a squirrel is made by an SVM.

10
10 CSC 4510, Spring 2012. © Paula Matuszek 2012. So What’s an SVM? A Support Vector Machine (SVM) is a classifier –It uses features of instances to decide which class each instance belongs to It is a supervised machine-learning classifier –Training cases are used to calculate parameters for a model which can then be applied to new instances to make a decision It is a binary classifier –it distinguishes between two classes For the squirrel vs bird, Grandis used size, a histogram of pixels, and a measure of texture as the features
 is a classifier –It uses features of instances to decide which class each instance belongs to It is a supervised machine-learning classifier –Training cases are used to calculate parameters for a model which can then be applied to new instances to make a decision It is a binary classifier –it distinguishes between two classes For the squirrel vs bird, Grandis used size, a histogram of pixels, and a measure of texture as the features.")
11
11 CSC 4510, Spring 2012. © Paula Matuszek 2012. Basic Idea Underlying SVMs Find a line, or a plane, or a hyperplane, that separates our classes cleanly. –This is the same concept as we have seen in regression. By finding the greatest margin separating them –This is not the same concept as we have seen in regression. What does it mean?

12
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Linear Classifiers denotes +1 denotes -1 How would you classify this data?

13
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Linear Classifiers denotes +1 denotes -1 How would you classify this data?

14
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Linear Classifiers denotes +1 denotes -1 Any of these would be fine....but which is best?

15
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Classifier Margin denotes +1 denotes -1 Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint.

16
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Maximum Margin denotes +1 denotes -1 The maximum margin linear classifier is the linear classifier with the maximum margin.

17
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Maximum Margin denotes +1 denotes -1 The maximum margin linear classifier is the linear classifier with the maximum margin. Called Linear Support Vector Machine (SVM)
.")
18
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Maximum Margin denotes +1 denotes -1 The maximum margin linear classifier is the linear classifier with the, um, maximum margin. Called Linear Support Vector Machine (SVM) Support Vectors are those datapoints that the margin pushes up against
 Support Vectors are those datapoints that the margin pushes up against.")
19
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Why Maximum Margin? denotes +1 denotes -1 f ( x, w,b) = sign( w. x - b) The maximum margin linear classifier is the linear classifier with the, um, maximum margin. This is the simplest kind of SVM (Called an LSVM) Support Vectors are those datapoints that the margin pushes up against 1.If we’ve made a small error in the location of the boundary (it’s been jolted in its perpendicular direction) this gives us least chance of causing a misclassification. 2.Empirically it works very very well.
 = sign( w. x - b) The maximum margin linear classifier is the linear classifier with the, um, maximum margin. This is the simplest kind of SVM (Called an LSVM) Support Vectors are those datapoints that the margin pushes up against 1.If we’ve made a small error in the location of the boundary (it’s been jolted in its perpendicular direction) this gives us least chance of causing a misclassification. 2.Empirically it works very very well..")
20
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials Copyright © 2001, 2003, Andrew W. Moore Maximum Margin Classifier (SVM) Find the linear classifier separates documents of the positive class from those of the negative class has the largest classification margin +1 Compute the classification margin Search the linear classifier with the largest classification margin Classification margin Plus-Plane Minus-Plane Classifier Boundary
 Find the linear classifier separates documents of the positive class from those of the negative class has the largest classification margin +1 Compute the classification margin Search the linear classifier with the largest classification margin Classification margin Plus-Plane Minus-Plane Classifier Boundary.")
21
21 CSC 4510, Spring 2012. © Paula Matuszek 2012. Concept Check For which of these could we use a basic linear SVM? –A: Classify the three kinds of iris in the Orange data set? –B: Classify email into spam and non-spam? –C: Classify students into likely to pass or not? Which of these is the SVM margin? BA

22
22 CSC 4510, Spring 2012. © Paula Matuszek 2012. Messy Data This is all good so far. Suppose our aren’t that neat:

23
23 CSC 4510, Spring 2012. © Paula Matuszek 2012. Soft Margins Intuitively, it still looks like we can make a decent separation here. –Can’t make a clean margin –But can almost do so, if we allow some errors We introduce slack variables, which measure the degree of misclassification A soft margin is one which lets us make some errors, in order to get a wider margin Tradeoff between wide margin and classification errors

24
24 CSC 4510, Spring 2012. © Paula Matuszek 2012. Only Two Errors, Narrow Margin

25
25 CSC 4510, Spring 2012. © Paula Matuszek 2012. Several Errors, Wider Margin

26
26 CSC 4510, Spring 2012. © Paula Matuszek 2012. Slack Variables and Cost In order to find a soft margin, we allow slack variables, which measure the degree of misclassification. –Takes into account the distance from the margin as well we the number of misclassified instances We then modify this by a cost (C) for these misclassified instances. –High cost will give relatively narrow margins –Low cost will give broader margins but misclassify more data. How much we want it to cost to misclassify instances depends on our domain -- what we are trying to do
 for these misclassified instances. –High cost will give relatively narrow margins –Low cost will give broader margins but misclassify more data. How much we want it to cost to misclassify instances depends on our domain -- what we are trying to do.")
27
27 CSC 4510, Spring 2012. © Paula Matuszek 2012. Concept Check Which of these represents a soft margin? AB

28
28 CSC 4510, Spring 2012. © Paula Matuszek 2012. Evaluating SVMs As with any classifier, we need to know how well our trained model performs on other data Train on sample data, evaluate on test data (why?) Some things to look at: –classification accuracy: percent correctly classified –confusion matrix –sensitivity and specificity
 Some things to look at: –classification accuracy: percent correctly classified –confusion matrix –sensitivity and specificity.")
29
29 CSC 4510, Spring 2012. © Paula Matuszek 2012. Confusion Matrix Is it spam?Predicted yesPredicted no Actually yesTrue positives False negatives Actually noFalse positives True negatives Note that “positive” vs “negative” is arbitrary

30
30 CSC 4510, Spring 2012. © Paula Matuszek 2012. Specificity and Sensitivity sensitivity: ratio of labeled positives to actual positives –how much spam are we finding? specificity: ratio of labeled negatives to actual negatives –how much “real” email are we calling email?

31
31 CSC 4510, Spring 2012. © Paula Matuszek 2012. More on Evaluating SVMs Overfitting: very close fit to training data which takes advantage of irrelevant variations in instances –performance on test data will be much lower –may mean that your training sample isn’t representative –in SVMs, may mean that C is too high Is the SVM actually useful? –Compare to the “majority” classifier

32
32 CSC 4510, Spring 2012. © Paula Matuszek 2012. Concept Check For binary classifiers A and B, for balanced data: –Which is better: A is 80% accurate, B is 60% accurate –Which is better: A has 90% sensitivity, B has 70% sensitivity –Which is the better classifier: A has 100 % sensitivity, 50% specificity B has 80% sensitivity, 80% specificity Would you use a spam filter that was 80% accurate? Would you use a classifier for who needs major surgery that was 80% accurate? Would you ever use a binary classifier that is 50% accurate?

33
33 CSC 4510, Spring 2012. © Paula Matuszek 2012. Orange and SVMs We now know enough to start looking at the Orange SVM widget –create some linearly separable data –sample it –run a linear SVM and look at results

34
34 CSC 4510, Spring 2012. © Paula Matuszek 2012. Why SVMs? Focus on the instances nearest the margin is paying more attention to where the differences are critical Can handle very large feature sets effectively In practice has been shown to work well in a variety of domains

35
35 CSC 4510, Spring 2012. © Paula Matuszek 2012. But wait, there’s more!

36
36 CSC 4510, Spring 2012. © Paula Matuszek 2012. Non-Linearly-Separable Data Suppose we can’t do a good linear separation of our data? As with regression, allowing non-linearity will give us much better modeling of many data sets. In SVMs, we do this by using a kernel. A kernel is a function which maps our data into a higher-order order feature space where we can find a separating hyperplane

37
37 CSC 4510, Spring 2012. © Paula Matuszek 2012. Kernels for SVMs As we saw in Orange, we always specify a kernel for an SVM Linear is simplest, but seldom a good match to the data Other common ones are –polynomial –RBF (Gaussian Radial Basis Function)
.")
38
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials
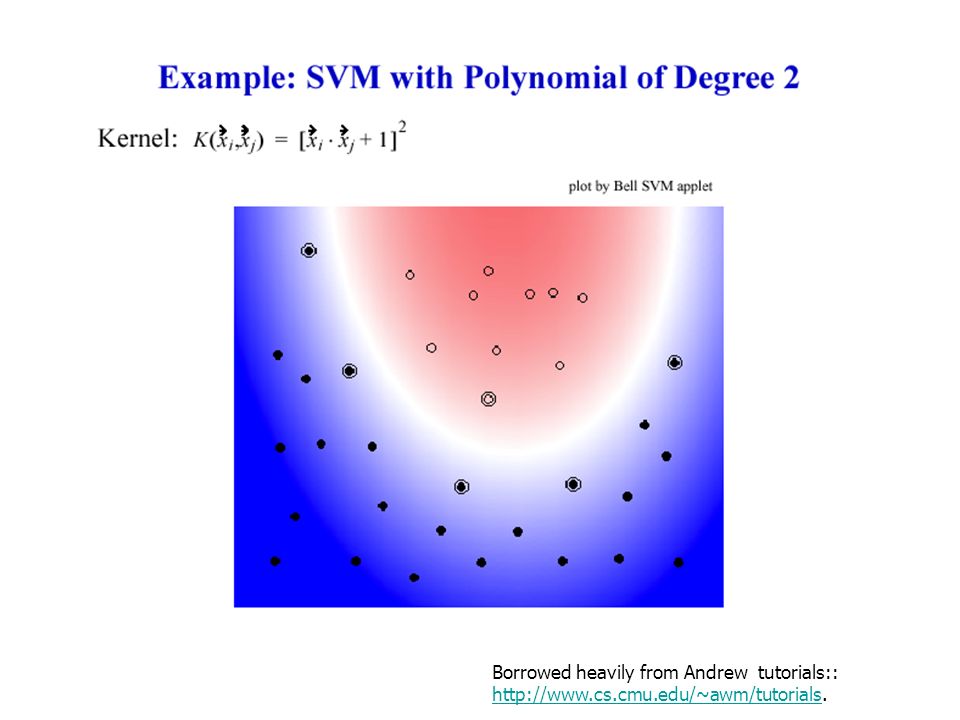
39
Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. http://www.cs.cmu.edu/~awm/tutorials

40
40 CSC 4510, Spring 2012. © Paula Matuszek 2012. Back to Orange Let’s try some

41
41 CSC 4510, Spring 2012. © Paula Matuszek 2012. To be continued next week

Similar presentations
>")

>")

 of the slides are taken from Prof.>")












 Chapter 5 (Duda et al.)>")

