Download presentation
Presentation is loading. Please wait.

2
The exam is of 2 hours & Marks :40 The exam is of two parts ( Part I & Part II) Part I is of 20 questions. Answer any 15 questions Each question is of 2 marks. Total 30 marks. Part II is of 15 questions. Answer any 10 questions Each question is of 1 mark. Total 10 marks. No MCQ’s. You should write the answers. No major calculations. No need to memorize the formulas. Bring your own calculator. Cell phones are not allowed to use as a calculator.

3
Study Designs Levels of measurements (Type of data) Sampling Distribution of Means and proportions Normal Distribution Hypothesis testing & Z- test Student’s t-test Chi -square test, MacNemar’s Chi-square test Confidence Intervals How to write a research paper ? ----- ( 40 marks)
.")
4
QUALITATIVE DATA (Categorical data) DISCRETE QUANTITATIVE CONTINOUS QUANTITATIVE
 DISCRETE QUANTITATIVE CONTINOUS QUANTITATIVE")
5
Nominal – qualitative classification of equal value: gender, race, color, city Ordinal - qualitative classification which can be rank ordered: socioeconomic status of families Interval - Numerical or quantitative data: can be rank ordered and sizes compared : temperature Ratio - Quantitative interval data along with ratio: time, age.

8
Standard error of mean is calculated by:

9
The standard deviation (s) describes variability between individuals in a sample. The standard error describes variation of a sample statistic. The standard deviation describes how individuals differ. The standard error of the mean describes the precision with which we can make inference about the true mean.

10
Standard error of the mean (sem): Comments: n = sample size even for large s, if n is large, we can get good precision for sem always smaller than standard deviation (s)
: Comments: n = sample size even for large s, if n is large, we can get good precision for sem always smaller than standard deviation (s)")
11
The standard deviation of the sampling distribution of a proportion:

12
Two Steps in Statistical Inferencing Process 1.Calculation of “confidence intervals” from the sample mean and sample standard deviation within which we can place the unknown population mean with some degree of probabilistic confidence 2.Compute “test of statistical significance” (Risk Statements) which is designed to assess the probabilistic chance that the true but unknown population mean lies within the confidence interval that you just computed from the sample mean.
 which is designed to assess the probabilistic chance that the true but unknown population mean lies within the confidence interval that you just computed from the sample mean.")
13
Many biologic variables follow this pattern Hemoglobin, Cholesterol, Serum Electrolytes, Blood pressures, age, weight, height One can use this information to define what is normal and what is extreme In clinical medicine 95% or 2 Standard deviations around the mean is normal Clinically, 5% of “normal” individuals are labeled as extreme/abnormal We just accept this and move on.

15
Symmetrical about mean, Mean, median, and mode are equal Total area under the curve above the x-axis is one square unit 1 standard deviation on both sides of the mean includes approximately 68% of the total area 2 standard deviations includes approximately 95% 3 standard deviations includes approximately 99%

16
Normal distribution is completely determined by the parameters and Different values of shift the distribution along the x-axis Different values of determine degree of flatness or peakedness of the graph

17
Sample z = x - x s Population z = x - µ Round to 2 decimal places Measures of Position z score

18
The Z score makes it possible, under some circumstances, to compare scores that originally had different units of measurement.

19
- 3- 2- 101 23 Z Unusual Values Unusual Values Ordinary Values Interpreting Z Scores

20
‘The mean sodium concentrations in the two populations are equal.’ Alternative hypothesis Logical alternative to the null hypothesis ‘The mean sodium concentrations in the two populations are different.’Hypothesis simple, specific, in advance

21
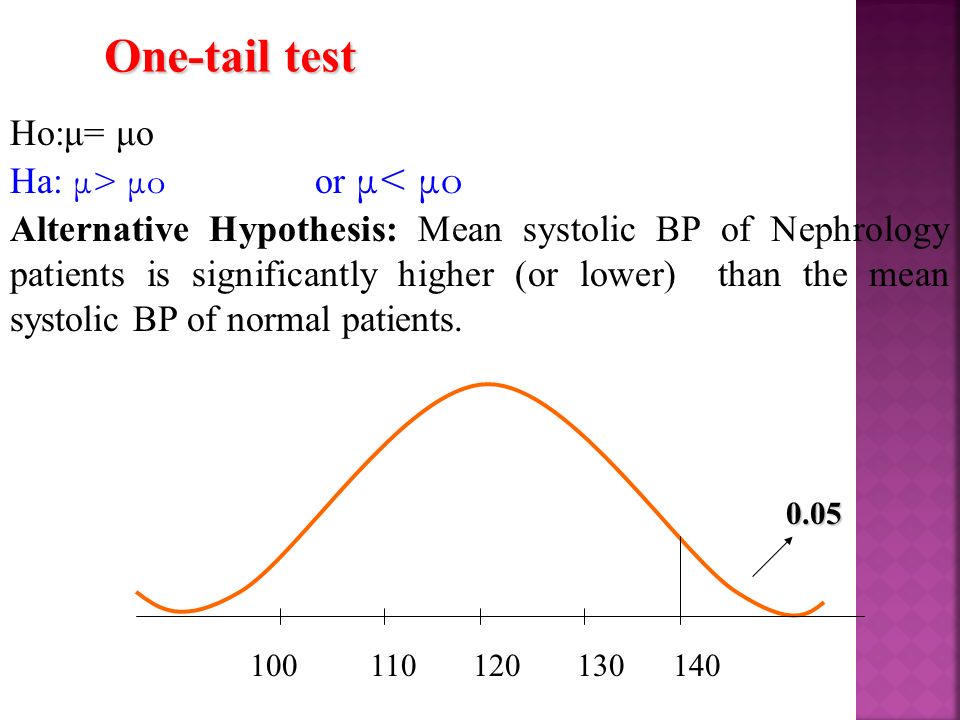
100 110 120 130 140 One-tail test Ho:μ= μo Ha: μ> μo or μ< μo Alternative Hypothesis: Mean systolic BP of Nephrology patients is significantly higher (or lower) than the mean systolic BP of normal patients. 0.05
22
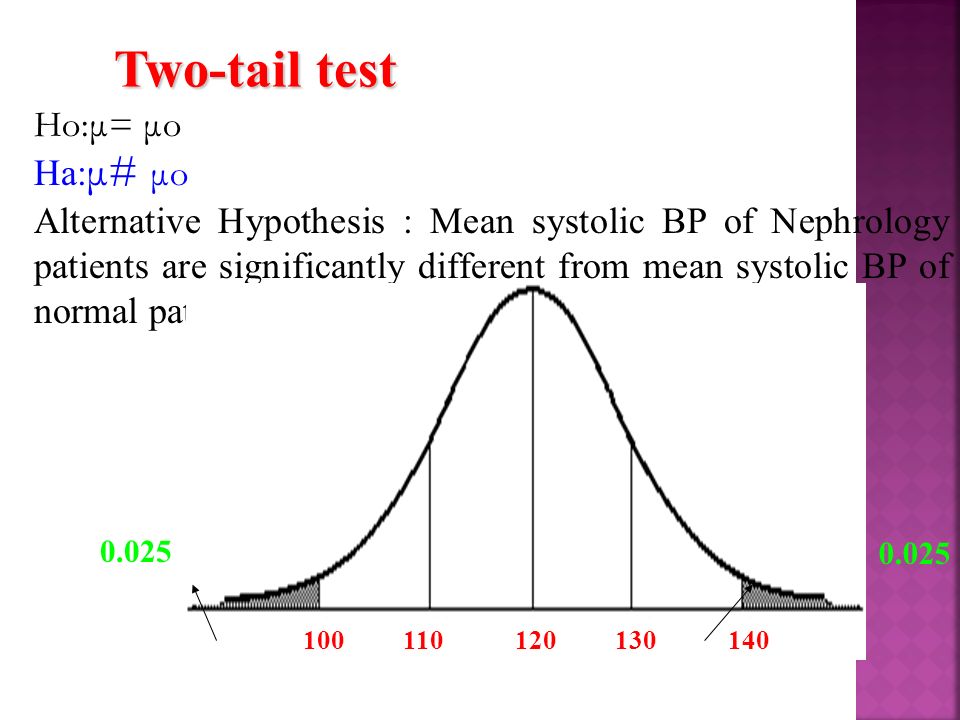
Two-tail test Ho:μ= μo Ha: μ# μo Alternative Hypothesis : Mean systolic BP of Nephrology patients are significantly different from mean systolic BP of normal patients. 100 110 120 130 140 0.025
23
Every decisions making process will commit two types of errors. “We may conclude that the difference is significant when in fact there is not real difference in the population, and so reject the null hypothesis when it is true. This is error is known as type-I error, whose magnitude is denoted by the Greek letter ‘α ’. On the other hand, we may conclude that the difference is not significant, when in fact there is real difference between the populations, that is the null hypothesis is not rejected when actually it is false. This error is called type-II error, whose magnitude is denoted by ‘ β ’.

24
Disease (Gold Standard) Present Correct Negative Total Positive Test False Negative a+b a+b+c+d Total Correct a+cb+d c+d False Positive Result Absent a b cd
 Present Correct Negative Total Positive Test False Negative a+b a+b+c+d Total Correct a+cb+d c+d False Positive Result Absent a b cd")
25
This level of uncertainty is called type 1 error or a false-positive rate ( More commonly called a p-value In general, p ≤ 0.05 is the agreed upon level In other words, the probability that the difference that we observed in our sample occurred by chance is less than 5% Therefore we can reject the H o

26
Stating the Conclusions of our Results When the p-value is small, we reject the null hypothesis or, equivalently, we accept the alternative hypothesis. “Small” is defined as a p-value , where acceptable false (+) rate (usually 0.05). When the p-value is not small, we conclude that we cannot reject the null hypothesis or, equivalently, there is not enough evidence to reject the null hypothesis. “Not small” is defined as a p-value > , where = acceptable false (+) rate (usually 0.05).
 rate (usually 0.05). When the p-value is not small, we conclude that we cannot reject the null hypothesis or, equivalently, there is not enough evidence to reject the null hypothesis. Not small is defined as a p-value > , where = acceptable false (+) rate (usually 0.05)..")
27
P-value A standard device for reporting quantitative results in research where variability plays a large role. Measures the dissimilarity between two or more sets of measures or between one set of measurements and a standard. “ the probability of obtaining the study results by chance if the null hypothesis is true” “The probability of obtaining the observed value (study results) as extreme as possible”
 as extreme as possible .")
28
P-value - continued “ The p-value is actually a probability, normally the probability of getting a result as extreme as or more extreme than the one observed if the dissimilarity is entirely due to variability of measurements or patients response, or to sum up, due to chance alone”. Small p value - the rare event has occurred Large p value - likely event

29
-1.96 0 Area =.025 Area =.005 Z -2.575 Area =.025 Area =.005 1.96 2.575

30
1.Test for single mean Whether the sample mean is equal to the predefined population mean ?. Test for difference in means 2. Test for difference in means Whether the CD4 level of patients taking treatment A is equal to CD4 level of patients taking treatment B ? Test for paired observation 3. Test for paired observation Whether the treatment conferred any significant benefit ?

31
t is a measure of: How difficult is it to believe the null hypothesis? High t Difficult to believe the null hypothesis - accept that there is a real difference. Low t Easy to believe the null hypothesis - have not proved any difference.

32
Student ‘s t-test will be used: --- When Sample size is small, for mean values and for the following situations: (1) to compare the single sample mean with the population mean (2) to compare the sample means of two indpendent samples (3) to compare the sample means of paired samples
 to compare the single sample mean with the population mean (2) to compare the sample means of two indpendent samples (3) to compare the sample means of paired samples")
34
BACKGROUND AND NEED OF THE TEST Data collected in the field of medicine is often qualitative. --- For example, the presence or absence of a symptom, classification of pregnancy as ‘high risk’ or ‘non-high risk’, the degree of severity of a disease (mild, moderate, severe)
.")
35
The measure computed in each instance is a proportion, corresponding to the mean in the case of quantitative data such as height, weight, BMI, serum cholesterol. Comparison between two or more proportions, and the test of significance employed for such purposes is called the “Chi-square test”

36
McNemar’s test Situation: Two paired binary variables that form a particular type of 2 x 2 table e.g. matched case-control study or cross-over trial

37
When both the study variables and outcome variables are categorical (Qualitative): Apply (i) Chi square test (ii) Fisher’s exact test (Small samples) (iii) Mac nemar’s test ( for paired samples)
: Apply (i) Chi square test (ii) Fisher’s exact test (Small samples) (iii) Mac nemar’s test ( for paired samples)")
38
Z-test: Study variable: Qualitative Outcome variable: Quantitative or Qualitative Comparison: two means or two proportions Sample size: each group is > 50 Student’s t-test: Study variable: Qualitative Outcome variable: Quantitative Comparison: sample mean with population mean; two means (independent samples); paired samples. Sample size: each group <50 ( can be used even for large sample size)
.")
39
Chi-square test: Study variable: Qualitative Outcome variable: Qualitative Comparison: two or more proportions Sample size: > 20 Expected frequency: > 5 Fisher’s exact test: Study variable: Qualitative Outcome variable: Qualitative Comparison: two proportions Sample size:< 20 Macnemar’s test: (for paired samples) Study variable: Qualitative Outcome variable: Qualitative Comparison: two proportions Sample size: Any
 Study variable: Qualitative Outcome variable: Qualitative Comparison: two proportions Sample size: Any")
40
1.Number of Observations that Are Free to Vary After Sample Statistic Has Been Calculated 2.Example Sum of 3 Numbers Is 6 X 1 = 1 (or Any Number) X 2 = 2 (or Any Number) X 3 = 3 (Cannot Vary) Sum = 6 degrees of freedom = n -1 = 3 -1 = 2
 X 2 = 2 (or Any Number) X 3 = 3 (Cannot Vary) Sum = 6 degrees of freedom = n -1 = 3 -1 = 2")
41
P S Investigation S Sampling P value Confidence intervals!!! Inference Results

42
Two forms of estimation Point estimation = single value, e.g., x-bar is unbiased estimator of μ Interval estimation = range of values confidence interval (CI). A confidence interval consists of:

43
Mean, , is unknown PopulationRandom Sample I am 95% confident that is between 40 & 60. Mean X = 50 Estimation Process Sample

44
“ We are 95% sure that the TRUE parameter value is in the 95% confidence interval” “If we repeated the experiment many many times, 95% of the time the TRUE parameter value would be in the interval” “the probability that the interval would contain the true parameter value was 0.95.”

45
CI 90% corresponds to p 0.10 CI 95% corresponds to p 0.05 CI 99% corresponds to p 0.01 Note: p value only for analytical studies CI for descriptive and analytical studies

46
RR = 5.6 (95% CI = 1.2 ; 23.7) OR = 12.8 (95% CI = 3.6 ; 44,2) NNT = 12 (95% CI = 9 ; 26)
 OR = 12.8 (95% CI = 3.6 ; 44,2) NNT = 12 (95% CI = 9 ; 26)")
47
If p value <0.05, then 95% CI: exclude 0 (for difference), because if A=B then A-B = 0 p>0.05 exclude 1 (for ratio), because if A=B then A/B = 1, p>0.05
, because if A=B then A-B = 0 p>0.05 exclude 1 (for ratio), because if A=B then A/B = 1, p>0.05")
48
--The (im) precision of the estimate is indicated by the width of the confidence interval. --The wider the interval the less precision THE WIDTH OF C.I. DEPENDS ON: ---- SAMPLE SIZE ---- VAIRABILITY ---- DEGREE OF CONFIDENCE

49
p values (hypothesis testing) gives you the probability that the result is merely caused by chance or not by chance, it does not give the magnitude and direction of the difference Confidence interval (estimation) indicates estimate of value in the population given one result in the sample, it gives the magnitude and direction of the difference
 gives you the probability that the result is merely caused by chance or not by chance, it does not give the magnitude and direction of the difference Confidence interval (estimation) indicates estimate of value in the population given one result in the sample, it gives the magnitude and direction of the difference")
50
Abstract Introduction Methods Results Discussion and References

51
Wishing all of you Best of Luck !

Similar presentations





 Parameter Estimation of PDF and Fitting a Distribution Function.>")
 There are two types of hypothesis : 1) Simple hypothesis :A statistical.>")
















