Download presentation
Presentation is loading. Please wait.

1
Three Frameworks for Statistical Analysis

2
Sample Design Forest, N=6 Field, N=4 Count ant nests per quadrat

3
Data Id #HabitatNumber of ant nest per quadrat 1Forest9 2 6 3 4 4 6 5 7 6 10 7Field12 8Field9 9 12 10Field10

4
Three Frameworks for Statistical Analysis Monte Carlo Analysis Parametric Analysis Bayesian Analysis

5
The model y i = is a measurement on a “continuous” scale, which belongs to an individual type of habitat “i” x i = is an indicator or dummy variable for groups (0,1) The model includes three parameters: α: the mean for groups β: the mean difference between groups, and The variance (σ 2 ) of the normal distribution from which the residuals ε i are assumed to have come from. For the Parametric and Bayesian

6
Monte Carlo Analysis Involves a number of methods in which data are randomized or reshuffled so that observations are randomly reassigned to different treatment groups. This randomization specifies the null hypothesis under consideration

7
Monte Carlo Analysis 1.Specify a test statistic or index to describe the pattern in the data 2.Create a distribution of the test statistic that would be expected under the null hypothesis 3.Decide on one- or two-tailed test 4.Compare the observed test statistic to a distribution of simulated values and estimate the appropriate P value as a tail probability

8
1. Specifying the Test Statistic

9
2. Creating the Null Distribution

10
3. Deciding on a One or Two tailed Test Abs (difference) = 3.750 P = 0.036 Threshold
 = P = Threshold")
11
4. Calculating the Tail Probability InequalityN DIF sim > DIF obs 7 DIF sim = DIF obs 29 DIF sim < DIF obs 964 36/1000=0.036

12
Differences between means Difference = 3.7500 P1 = 0.0228

13
Assumptions The data collected represent random, independent samples The test statistic describes the pattern of interest The randomization creates an appropriate null distribution for the question

14
Advantages It makes clear and explicit the underlying assumptions and the structure of the null hypothesis It does not require the assumption that the data are sampled from a specified probability distribution, such as the normal

15
Disadvantages It is computer intensive and is not included in most traditional statistical packages Different analyses of the same data set can yield slightly different answers The domain of inference for a Monte Carlo analysis is subtly more restrictive than that for a parametric analysis

16
Parametric analysis Refers to statistical tests built on the assumption that the data being analyzed were sampled from a specified distribution Most statistical tests specify the normal distribution

17
Parametric analysis 1.Specify the test statistic 2.Specify the null distribution 3.Calculate the tail probability

18
1. Specify the test statistic t test

19
Specify the test statistic Null hypothesis Forest Field

20
2. Specify the null distribution Critical value

21
3. Calculate the tail probability: Student’s t table df\p 0.40.250.10.050.0250.010.0050.0005 1 0.3249213.0776846.31375212.706231.8205263.65674636.6192 2 0.2886750.8164971.8856182.9199864.302656.964569.9248431.5991 3 0.2766710.7648921.6377442.3533633.182454.54075.8409112.924 4 0.2707220.7406971.5332062.1318472.776453.746954.604098.6103 5 0.2671810.7266871.4758842.0150482.570583.364934.032146.8688 6 0.2648350.7175581.4397561.943182.446913.142673.707435.9588 7 0.2631670.7111421.4149241.8945792.364622.997953.499485.4079 8 0.2619210.7063871.396815 1.859548 2.3062.896463.355395.0413 http://www.statsoft.com/textbook/sttable.html#t

22
Results of t-test Levene's Test for Equality of Variancest-test for Equality of Means FSig.tdf Sig. (2- tailed) Mean Difference Equal variances assumed0.42550.5324-2.9631980.018-3.75 Equal variances not assumed-3.212657.950.012-3.75 HabitatNMeanStd. Deviation Std. Error Mean Forest672.190.89 Field410.751.50.75
 Mean Difference Equal variances assumed Equal variances not assumed HabitatNMeanStd. Deviation Std. Error Mean Forest Field")
23
Assumptions The data collected represent random, independent samples The data were sampled from a specified distribution

24
Advantages It uses a powerful framework based on known probability distributions

25
Disadvantages It may not be as powerful as sophisticated Monte Carlo models that are tailored to particular questions or data It rarely incorporates a priori information or results from other experiments

26
What About Non-Parametric Analyses? Essentially, these analyses give the P-values that would be obtained by ranking the observations and then performing randomization tests on the ranked data Like other resampling methods, non-parametric analyses do not require distributional assumptions. However, they have less power than the equivalent parametric tests and can only be used with simple experimental designs.

27
Bayesian analysis It includes prior information and then uses current data to build on earlier results It also allows us to quantify the probability of the observed difference [i.e., P(H a |data)]
![Bayesian analysis It includes prior information and then uses current data to build on earlier results It also allows us to quantify the probability of the observed difference [i.e., P(H a |data)]](http://images.slideplayer.com/26/8577984/slides/slide_27.jpg "Bayesian analysis It includes prior information and then uses current data to build on earlier results It also allows us to quantify the probability of the observed difference [i.e., P(H a |data)]")
28
Bayesian analysis 1.Specify the hypothesis 2.Specify parameters as random variables 3.Specify the prior probability distribution 4.Calculate the likelihood 5.Calculate the posterior probability distribution 6.Interpret the results

29
1. Specify the hypothesis The primary goal of a Bayesian analysis is to determine the probability of the hypothesis given the data P(H | data) The hypothesis needs to be quite specific, and need to be quantitative: P(diff>2 | diff obs =3.75)
 The hypothesis needs to be quite specific, and need to be quantitative: P(diff>2 | diff obs =3.75).")
30
P(hypothesis | data) The left hand side of the equation is called the posterior probability distribution, and is the quantity of interest
 The left hand side of the equation is called the posterior probability distribution, and is the quantity of interest")
31
P(hypothesis | data) The right hand side of the equation consists of a fraction. In the numerator, the term P(hypothesis) is the prior probability distribution, and is the probability of the hypothesis of interest before you conducted the experiment
 is the prior probability distribution, and is the probability of the hypothesis of interest before you conducted the experiment.")
32
P(hypothesis | data) The next term in the numerator is referred as the likelihood of the data; it reflects the probability of observing the data given the hypothesis
 The next term in the numerator is referred as the likelihood of the data; it reflects the probability of observing the data given the hypothesis")
33
P(hypothesis | data) The denominator is a normalizing constant that reflects the probability of the data given all possible hypotheses. It scales the posterior probability distribution to the range [0,1].

34
P(hypothesis | data) We can focus our attention on the numerator
 We can focus our attention on the numerator")
35
2. Specify the parameters as random variables The type of random variable used for each population parameter should reflect biological reality or mathematical convenience

36
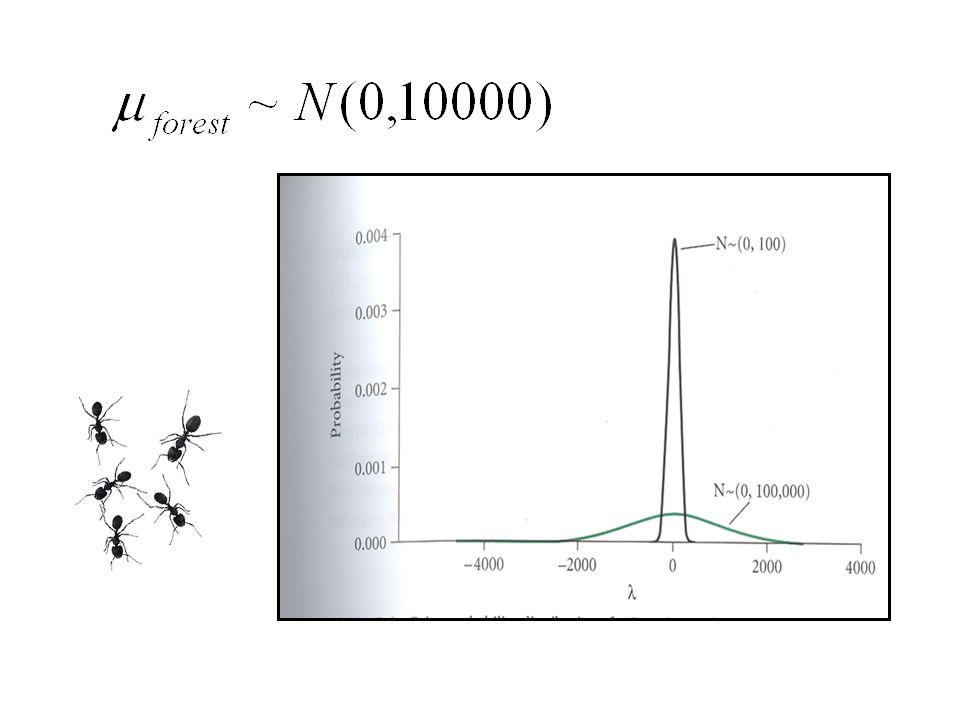
3. Specify the prior probability distribution We can combine and re-analyze data from the literature, talk to experts, etc. to come up with reasonable estimates for the density of ant nests in fields and forests OR, we can use an “uninformative prior”, for which we initially estimate the density of ant nests to be equal to zero and the variances to be very large

38
sigma ~ dunif(0,10)
")
39
WinBugs code model { #Priors mu1 ~ dnorm(0,0.001) delta ~ dnorm(0,0.001) tau <- 1/(sigma*sigma) sigma ~ dunif(0,10) #Likelihood for (i in 1:n) { y[i]~ dnorm(mu[i],tau) mu[i] <- mu1 + delta*x[i] residual[i] <- y[i]-mu[i] } # Derived quantities mu2 <- mu1 + delta }
![WinBugs code model { #Priors mu1 ~ dnorm(0,0.001) delta ~ dnorm(0,0.001) tau <- 1/(sigma*sigma) sigma ~ dunif(0,10) #Likelihood for (i in 1:n) { y[i]~ dnorm(mu[i],tau) mu[i] <- mu1 + delta*x[i] residual[i] <- y[i]-mu[i] } # Derived quantities mu2 <- mu1 + delta }](http://images.slideplayer.com/26/8577984/slides/slide_39.jpg "WinBugs code model { #Priors mu1 ~ dnorm(0,0.001) delta ~ dnorm(0,0.001) tau <- 1/(sigma*sigma) sigma ~ dunif(0,10) #Likelihood for (i in 1:n) { y[i]~ dnorm(mu[i],tau) mu[i] <- mu1 + delta*x[i] residual[i] <- y[i]-mu[i] } # Derived quantities mu2 <- mu1 + delta }")
40
Comparison between approaches Parametric Null hypothesis: P(data | H 0 ) P(t obs = 2.96 |t>F theoretical =1.86) Parameters are fixed Bayesian Hypothesis: P(H | data) P(diff> 2 | diff obs =3.75) Parameters are random variables
 P(t obs = 2.96 |t>F theoretical =1.86) Parameters are fixed Bayesian Hypothesis: P(H | data) P(diff> 2 | diff obs =3.75) Parameters are random variables")
41
4. Calculate the likelihood Field Forest The likelihood is a distribution that is proportional to the probability of the observed data given the hypothesis Maximum likelihood Field mean Field variance

42
5. Calculate the posterior probability distribution We multiply the prior by the likelihood, and divide by the normalizing constant In contrast to the results of the parametric or Monte Carlo analysis, the result of a Bayesian analysis is a probability distribution, not a single P-value

43
Bayesian output Field Forest Delta (difference)
")
44
Estimates Estimator Analysis delta (slope) λ Forest λ Field σ Forest σ Field Parametric3.75 (1.27) 7.0010.750.980.87 Bayesian uniformed prior 3.75 (1.61) 7.0010.741.011.22
 λ Forest λ Field σ Forest σ Field Parametric3.75 (1.27) Bayesian uniformed prior 3.75 (1.61)")
45
6. Interpreting the Results Given the Bayesian estimate of mean diff= 3.698; [P(diff>2 | 3.75)=0.87 (2607/2997), In other words, the analysis indicates that there is a P=0.87 that ant nest densities between the two habitats are different by > 2 nests.
=0.87 (2607/2997), In other words, the analysis indicates that there is a P=0.87 that ant nest densities between the two habitats are different by > 2 nests..")
46
Assumptions The data collected represent random, independent samples The parameters to be estimated are random variables with known distributions

47
Advantages It allows for the explicit incorporation of prior information, and the results from one experiment can be used to inform subsequent experiments The results are interpreted in an intuitively straightforward way, and the inferences are conditional on both the observed data and the prior information

48
Disadvantages It has computational challenges and the requirement to condition the hypothesis on the data Potential lack of objectivity, because different results will be obtained using different priors

Similar presentations



 There are two types of hypothesis : 1) Simple hypothesis :A statistical.>")

>")














