Download presentation
Presentation is loading. Please wait.

1
Computational Diagnostics A new research group at the Max Planck Institute for molecular Genetics, Berlin

2
Will the patient respond to this drug? ?

3
computational diagnostics A simple solution for simple problems Find all genes that are induced at least x-fold and use them to predict clinical outcomes

4
computational diagnostics Statistical Modeling Experimental Design, Quality Control, Scaling, Normalization, Dimension Reduction, Predictive Classification, Quantifying the Evidence, Identifying the Evidence

5
computational diagnostics Computational Infrastructure and more Data Databases, Automatic Uploading, Standard Analysis Protocols, Analysis Software, Query Language, Understanding the disease, Designing a small Diagnostic Chip

6
computational diagnostics Clinical Practice Large Patient Databases complemented by expression profiles monitoring the Epidemiology of the disease

7
Breast Cancer, Expression Profiles and Binary Regression in 7000 Dimensions Rainer Spang, Harry Zuzan, Carrie Blanchette, Erich Huang, Holly Dressman, Jeff Marks, Joe Nevins, Mike West Duke Medical Center & Duke University

8
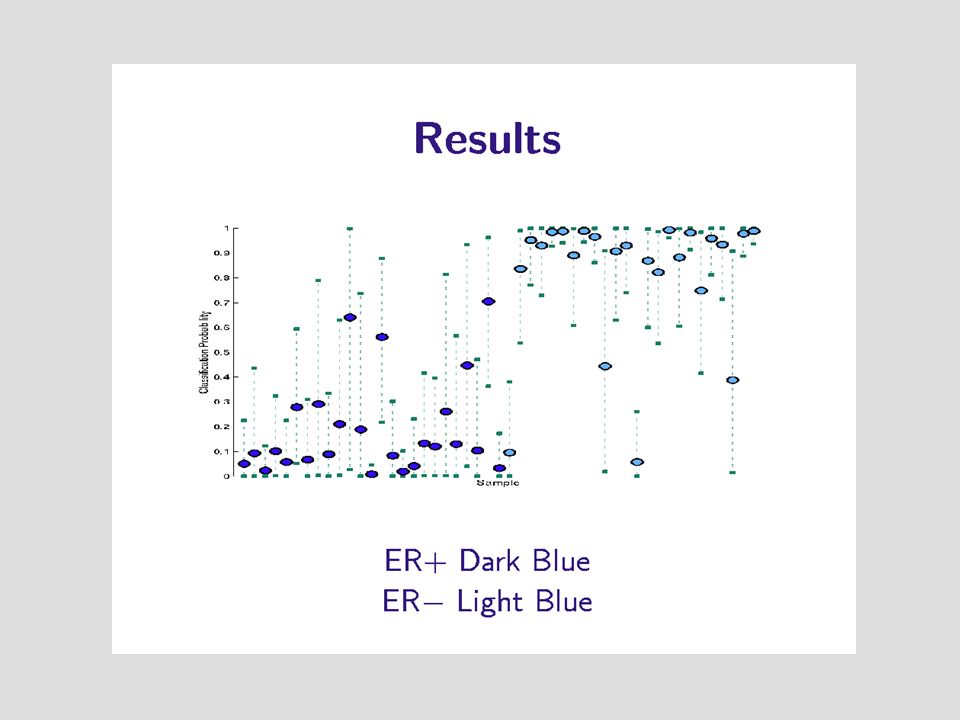
Estrogen Receptor Status 7000 genes 49 breast tumors 25 ER+ 24 ER-

9
Tumor – Chip - 7000 Numbers

10
We Assume That the Following Steps Are Done: Choosing the patients Doing the surgery Handling the tissues Preparing mRNA Hybridizing the chips Image analysis Excluding low quality data Normalization Scaling

12
How Much Evidence Is There? I am 80% sure The probability that I know it the patient has xxx It was a guess given the profile is 0.8, 1, 0.5

13
Given 7000 Numbers Wanted 89% The probability that the tumor is ER+

14
7000 Numbers Are More Numbers Than We Need Predict ER status based on the expression levels of super-genes

16
Overfitting: We Can Not Identify a Model There are many different models that assign high probabilities for ER+ tumors and low probabilities for ER- tumors in the training set For a new patient we find among these models some that support that she is ER+ and others that predict she is ER- ???

17
Given the Few Profiles With Known Diagnosis: The uncertainty on the right model is high The variance of the model-weights is large The likelihood landscape is flat We need additional model assumptions to solve the problem

18
Informative Priors LikelihoodPriorPosterior

19
If the Prior Is Chosen Badly: We can not reproduce the diagnosis of the training profiles any more We still can not identify the model The diagnosis is driven mostly by the additional assumptions and not by the data

20
The Prior Needs to Be Designed in 49 Dimensions Shape? Center? Orientation? Not to narrow... not to wide

21
Shape multidimensional normal for simplicity

22
Center Assumptions on the model correspond to assumptions on the diagnosis

23
Orientation orthogonal super-genes !

24
Not to Narrow... Not to Wide Auto adjusting model Scales are hyper parameters with their own priors

25
What are the additional assumptions that came in by the prior? The model can not be dominated by only a few super-genes ( genes! ) The diagnosis is done based on global changes in the expression profiles influenced by many genes The assumptions are neutral with respect to the individual diagnosis
 The diagnosis is done based on global changes in the expression profiles influenced by many genes The assumptions are neutral with respect to the individual diagnosis.")
27
Which Genes Have Driven the Prediction ? GeneWeight nuclear factor 3 alpha0.853 cysteine rich heart protein0.842 estrogen receptor0.840 intestinal trefoil factor0.840 x box binding protein 10.835 gata 30.818 ps 20.818 liv10.812... many many more......

28
Cysteine Rich Heart Protein

29
Summary... so far We have solved a relatively simple computational diagnostics problem (ER-status in human breast cancers) Probit model Overfitting is a problem Additional model assumptions do the trick
 Probit model Overfitting is a problem Additional model assumptions do the trick.")
30
A Common Problem With Expression Profiles We do not have enough samples to answer a certain question A possible strategy: Introduce additional model assumptions

31
Differential Expression I Setup: Two conditions ( healthy vs sick ), some repetitions, 10 000 genes Which genes are up or down regulated ? The most basic question Good because it is a hypothesis free approach

32
Differential Expression II 10 000 degrees of freedom A very bad multiple testing problem It is possible in principal, but might require many replications depending on signal to noise ratios SAM: regularized t-statistic + permutation based false positive rates Hard to improve the analysis because it is a hypothesis free approach

33
Clustering of Genes Setup: many different conditions - time series - multiple knock-outs 100% explorative analysis Essentially it is rearranging the data Good for finding hypotheses but not for verifying them

34
Clustering of Profiles (Patients) Maybe we can find new disease types or refine existing ones Completely different results when different sets of genes are used No predictive analysis
 Maybe we can find new disease types or refine existing ones Completely different results when different sets of genes are used No predictive analysis")
35
Think About Data Analysis Ahead of Time Collect possible questions on the data Which of them are easy ? - Biologists and Bioinformaticians might have a different take on that - Compare: number of samples vs. degrees of freedom It is possible to compensate lack of data with model assumptions: Which assumptions make sense ? More complex question can be the easier ones if they allow for an appropriate model

Similar presentations
















>")

 Naomi Altman Nov '06.>")

