Download presentation
Presentation is loading. Please wait.

1
Dynamic Bayesian Networks
Representation Probabilistic Graphical Models Template Models Dynamic Bayesian Networks

2
Template Transition Model
Weather Weather’ Velocity Velocity’ Location Location’ Failure Failure’ Obs’ Time slice t Time slice t+1

3
Initial State Distribution
Weather0 Velocity0 Location0 Failure0 Obs0 Time slice 0

4
Ground Bayesian Network
Weather0 Weather1 Weather2 Velocity0 Velocity1 Velocity2 Location0 Location1 Location2 Failure0 Failure1 Failure2 Obs0 Obs1 Obs2 Time slice 0 Time slice 1 Time slice 2

5
Tim Huang, Dieter Koller, Jitendra Malik, Gary Ogasawara, Bobby Rao, Stuart Russell, J. Weber

6
Dynamic Bayesian Network
A transition model over X1,…,Xn is specified via A dynamic Bayesian network is specified via

7
Ground Network

8
Hidden Markov Models s1 s2 s3 s4 S S’ S1 O1 S0 S2 O2 S3 O3 O’ 0.5 0.7
0.3 0.4 0.6 0.1 0.9
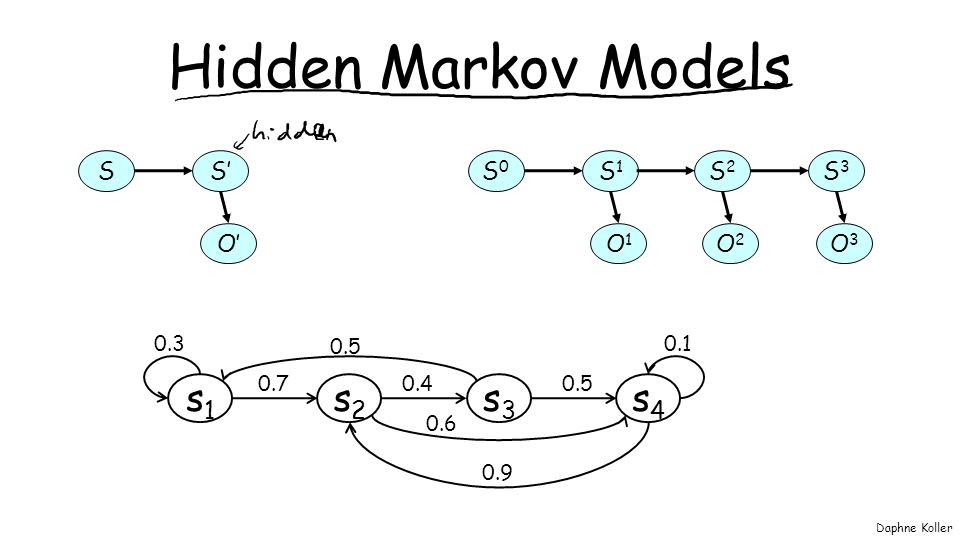
9
Hidden Markov Models s1 s2 s3 s4 S S’ S1 O1 S0 S2 O2 S3 O3 O’ 0.5 0.7
0.3 0.4 0.6 0.1 0.9
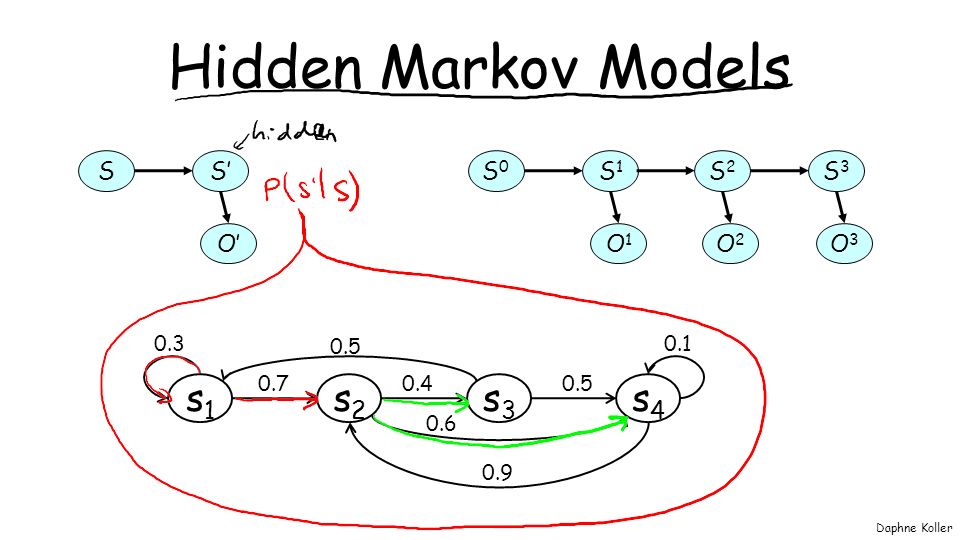
10
Consider a smoke detection tracking application, where we have 3 rooms connected in a row. Each room has a true smoke level (X) and a smoke level (Y) measured by a smoke detector situated in the middle of the room. Which of the following is the best DBN structure for this problem? X’1 Y’1 X1 X’2 Y’2 X2 X’3 Y’3 X3 X’1 Y’1 X1 X’2 Y’2 X2 X’3 Y’3 X3 X’1 Y’1 X1 X’2 Y’2 X2 X’3 Y’3 X3 X’1 Y’1 X1 X’2 Y’2 X2 X’3 Y’3 X3
![]()
11
Consider an application, where we have 3 sources, each making sound (X) simultaneously (e.g., a TV, a blender, and a ringing cellphone). We want to separate the observed aggregate signal (Y) into its unobserved constituent signals. Which of the following is the best DBN structure for this problem? X’1 X1 X’2 X2 X’3 Y X3 X1 X’1 X2 X’2 X3 X’3 Y X’1 Y’1 X1 X’2 Y’2 X2 X’3 Y’3 X3 X’1 Y’1 X1 X’2 Y’2 X2 X’3 Y’3 X3

12
Consider a situation where we have two people in a conversation, each wearing a sensitive lapel microphone. We want to separate each person’s speech (X) using the signal (Y) obtained from their microphone. Which of the following is the best DBN structure for this problem? X1 X’1 X1 X’1 Y’1 Y’1 X2 X’2 X2 X’2 Y’2 Y’2 X1 X’1 X1 X’1 Y’1 X2 X’2 Y’1 X2 X’2 Y’2 Y’2

13
Summary DBNS are a compact representation for encoding structured distributions over arbitrarily long temporal trajectories They make assumptions that may require appropriate model (re)design: Markov assumption Time invariance
design: Markov assumption. Time invariance.")
Similar presentations


>")









 Process A temporal process is the evolution of system state over time Often the system state.>")



 March, 25, 2009.>")


