Download presentation
Presentation is loading. Please wait.

1
Data and Publication Discovery Brian Matthews, Information Management Group, STFC Rutherford Appleton Laboratory CLADDIER workshop, Chilworth, Southampton, UK 15 th May 2007

2
Microsofts Science 2020 Report Modern scientific communication relies on both journals and databases. At present these are not integrated. By 2020 mutual linking will be commonplace and publications just containing peer-reviewed data will become available. http://research.microsoft.com/towards2020science/downloads.htm

3
The Use Case Joanna, at the University of Southampton, has done some work on the biology of seawater off the coast of Cornwall. As part of her analysis she needs (from a number of locations): Publications and data describing prior or similar work. Oceanic profiles of salinity and temperature from the closest cruise in time and space, Meteorological data to accompany both her own sampling and the oceanic data, Remotely sensed ocean colour imagery (to add additional information on the biota). She will then publish a paper that cites the datasets, lodge the paper in her own institutional repository and also deposit her datasets in one or more appropriate data repositories (e.g. both the NOCS data archive, and the, BODC). The work Joanna has done is of interest in calibrating a global earth system model to compare simulations of oceanic CO 2 production with the scenarios used in the model. Fred, at Reading University needs to be able to find Joannas paper and data either via citations or directly from publication repositories. Having found the paper, the data should be obtainable via the citation and the data archive. As part of his work he checks back through the other datasets used and cited as inputs to Joannas data, as before he uses Joannas data, he suspects Joannas work could be recalibrated by using better quality meteorological re-analyses.
: Publications and data describing prior or similar work. Oceanic profiles of salinity and temperature from the closest cruise in time and space, Meteorological data to accompany both her own sampling and the oceanic data, Remotely sensed ocean colour imagery (to add additional information on the biota). She will then publish a paper that cites the datasets, lodge the paper in her own institutional repository and also deposit her datasets in one or more appropriate data repositories (e.g. both the NOCS data archive, and the, BODC). The work Joanna has done is of interest in calibrating a global earth system model to compare simulations of oceanic CO 2 production with the scenarios used in the model. Fred, at Reading University needs to be able to find Joannas paper and data either via citations or directly from publication repositories. Having found the paper, the data should be obtainable via the citation and the data archive. As part of his work he checks back through the other datasets used and cited as inputs to Joannas data, as before he uses Joannas data, he suspects Joannas work could be recalibrated by using better quality meteorological re-analyses..")
5
What does that need? 1.Joannas own data acquisition 2.Location and acquisition of prior publications and data 3.Location and acquisition of remote datasets required as part of the analysis 4.Creation of personal metadata for new data 5.Data analysis and paper writing 6.Citation of remote papers and datasets 7.Paper submission to a journal and acceptance 8.Repository submission of paper (maybe a preprint) 9.Repository submission of data 10.Further metadata creation for the data (at the data repository). 11.Further metadata creation for the publication (at the institutional repository) 12.Linking between institutional repositories and the data held at the discipline repository 13.All the datasets and publications cited need to be annotated with the citation information 1.Discovery of Joannas work by Fred (either from Joannas publication or datasets or citations thereof) 2.Acquisition of all the relevant publications and datasets by Fred 3.Analysis and Publication by Fred (and all the same steps from 5 as required by Joanna) 4.External Adjudicators need to be able to find and acquire citation information.
 9.Repository submission of data 10.Further metadata creation for the data (at the data repository). 11.Further metadata creation for the publication (at the institutional repository) 12.Linking between institutional repositories and the data held at the discipline repository 13.All the datasets and publications cited need to be annotated with the citation information 1.Discovery of Joannas work by Fred (either from Joannas publication or datasets or citations thereof) 2.Acquisition of all the relevant publications and datasets by Fred 3.Analysis and Publication by Fred (and all the same steps from 5 as required by Joanna) 4.External Adjudicators need to be able to find and acquire citation information..")
6
So what services do we need? In order to achieve this scenario we need to provide a set of key services Publishing of Data Browsing and searching –across different repositories –across data and publication Cross-citation of data and publication –forward and backward citation –need to maintain currency of citation links

7
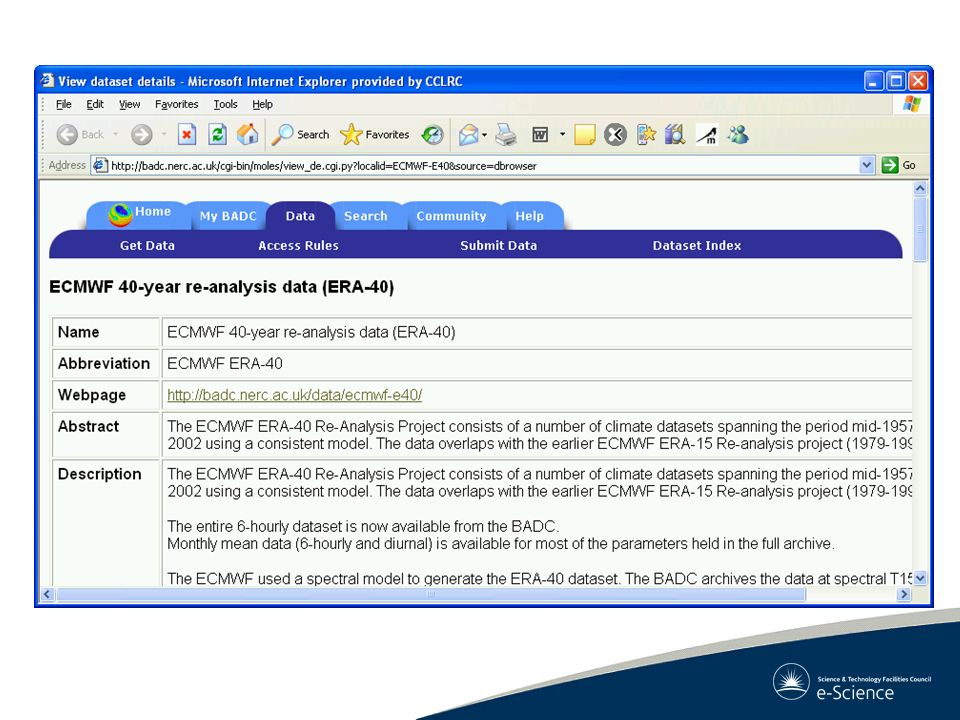
Browsing and Searching Browsing and searching –across different repositories –across data and publication CLADDIER has provided a harvesting and search tool to support cross-repository searching Uses OAI-PMH – a conventional approach –Simple – but it works! –Simple key-word searching –Three participating repositories in the pilot –BADC, STFC ePubs, e-Prints Soton

14
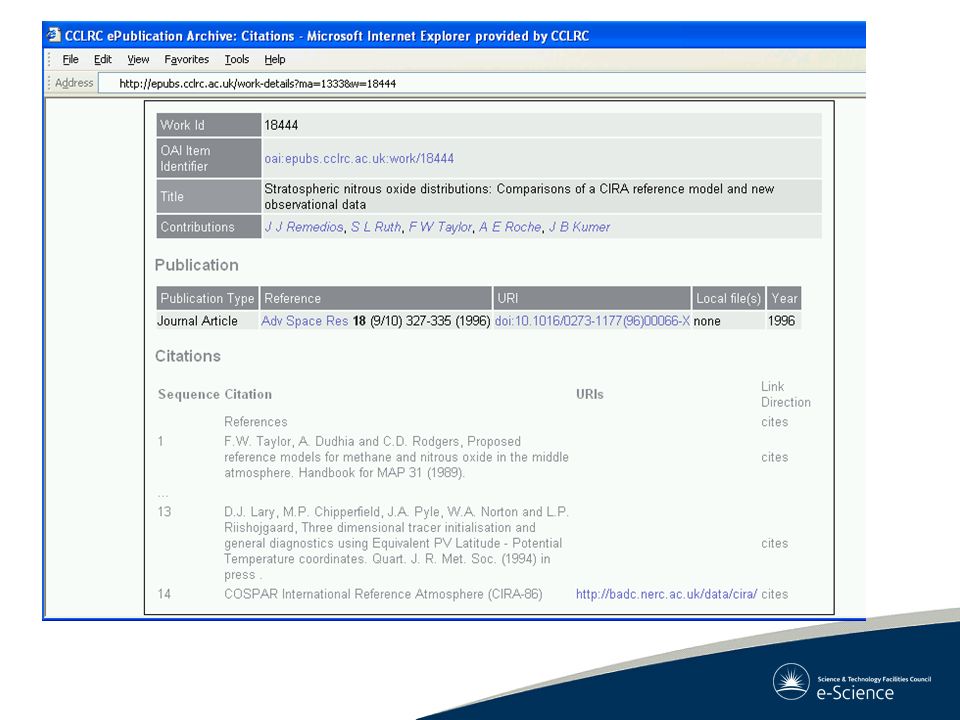
Adding cross-citation The Discovery Service gives a broad-brush search Give you both publications and data sets –which are indexed on a key word A Google across repositories Currently, cannot tell whether the data and publication are actually related –what data and publications inspire a piece of work (generating a new data set) –what publications arise from a data set We need to exploit the concept of citation to see whether relationships are actually related
 –what publications arise from a data set We need to exploit the concept of citation to see whether relationships are actually related")
15
Traditional Citations

16
Cross-citation

17
Adding Citations to the Metadata Model Adding Citations has been considered in standard metadata models. e.g. Scholarly Works Application Profile –JISC funded initiative –Dublin Core Application Profile –Describing Scholarly Publications (ePrints) –Based on the FRBR model –Does consider Citations –But breaks citations up into small components –This is highly labour intensive to enter –Does not have a notion of back citation
 –Based on the FRBR model –Does consider Citations –But breaks citations up into small components –This is highly labour intensive to enter –Does not have a notion of back citation.")
18
FRBR Model

19
ePubs and Cross-Citations STFC ePubs has a metadata model based on FRBR Need to extend this to support cross-citation Keep it simple Can support forward and back links Have developed a simple model for citations

20
Citation Model

23
Maintaining Links Ideally the archives holding the datasets and publications would be notified that a paper citing them had been submitted. Metadata associated with those records would be updated to reflect the citations. The metadata in the publication repository should also link to the data in the data archives and vice versa. It would be great if this notification could be done automatically.

24
Notification Services To support this, we need to provide a notification service. Federated Repositories register with the service Repositories notify the service of citations The service informs (via broadcasting or targeting) repositories of citation, Service provides sufficient information to update metadata Still under development. Note Blogging software.
 repositories of citation, Service provides sufficient information to update metadata Still under development. Note Blogging software..")
25
Conclusions The Use Case supports the scientific process with repositories This requires the cross-linking network of information objects Which needs to be stored, maintained and searched Tools and ideas relatively straightforward Lots of gluing of existing components Keep it simple – so it will get used

Similar presentations
























 *Annotation CLADDIER workshop,>")

