Download presentation
Presentation is loading. Please wait.

1
Bayesian inference PHILOSOPHY OF SCIENCE: Thomas Bayes 1702-1761
Zoltán Dienes

2
Subjective probability:
Personal conviction in an opinion – to which a number is assigned that obeys the axioms of probability. Probabilities reside in the mind of the individual not the external world. Your subjective probability/conviction in a proposition is just up to you – but you must revise your probability in the light of data in ways consistent with the axioms of probability.

3
Personal probabilities:
Which of the following alternatives would you prefer? If your choice turns out to be true I will pay you 10 pounds: It will rain tomorrow in Brighton I have a bag with one blue chip and one red chip. I randomly pull out one chip and it is red.

4
Personal probabilities:
Which of the following alternatives would you prefer? If your choice turns out to be true I will pay you 10 pounds: It will rain tomorrow in Brighton I have a bag with one blue chip and one red chip. I randomly pull out one and it is red. If you chose 2, your p(‘it will rain’) is less than .5 If you chose 1, your p(‘it will rain’) is greater than .5
 is less than .5. If you chose 1, your p(‘it will rain’) is greater than .5.")
5
Assume you think it more likely than not that it will rain.
Now which do you chose? I will give you 10 pounds if your chosen statement turns out correct. It will rain tomorrow in Brighton. I have a bag with 3 red chips and 1 blue. I randomly pick a chip and it is red.

6
Assume you think it more likely than not that it will rain.
Now which do you chose? I will give you 10 pounds if your chosen statement turns out correct. It will rain tomorrow in Brighton. I have a bag with 3 red chips and 1 blue. I randomly pick a chip and it is red. If you chose 2, your p(‘it will rain’) is less than .75 (but more than .5) If you chose 1, your p(‘it will rain’) is more than .75.
 is less than .75 (but more than .5) If you chose 1, your p(‘it will rain’) is more than .75.")
7
By imagining a bag with differing numbers of red and blue chips, you can make your personal probability as precise as you like.

8
This is a notion of probability that applies to the truth of theories
(Remember objective probability does not apply to theories) So that means we can answer questions about p(H) – the probability of a hypothesis being true – and also p(H|D) – the probability of a hypothesis given data (which we cannot do on the Neyman-Pearson approach).
 So that means we can answer questions about p(H) – the probability of a hypothesis being true – and also p(H|D) – the probability of a hypothesis given data (which we cannot do on the Neyman-Pearson approach).")
9
Consider a theory you might be testing in your project.
What is your personal probability that the theory is true?

10
ODDS in favour of a theory = P(theory is true)/P(theory is false)
For example, for the theory you may be testing ‘extroverts have high cortical arousal’ Then you might think (it’s completely up to you) P(theory is true) = 0.5 It follows you think that P(theory is false) = 1 – P(theory is true) = 0.5 So odds in favour of theory = 0.5/0.5 = 1 Even odds
 P(theory is true) = 0.5. It follows you think that. P(theory is false) = 1 – P(theory is true) = 0.5. So odds in favour of theory = 0.5/0.5 = 1. Even odds.")
11
If you think P(theory is true) = 0.8 Then you must think P(theory is false) = 0.2 So your odds in favour of the theory are 0.8/0.2 = 4 (4 to 1) What are your odds in favour of the theory you are testing in your project?

12
Odds before you have collected your data are called your prior odds
Experimental results tell you by how much to increase your odds (the Bayes Factor, B) Odds after collecting your data are called your posterior odds Posterior odds = B * Prior odds For example, a Bayesian analysis might lead to a B of 5. What would your posterior odds for your project hypothesis be?
 Odds after collecting your data are called your posterior odds. Posterior odds = B * Prior odds. For example, a Bayesian analysis might lead to a B of 5. What would your posterior odds for your project hypothesis be")
13
You can convert back to probabilities with the formula:
P (Theory is true) = odds/(odds + 1) So if your prior odds had been 1 and the Bayes factor 5 Then posterior odds = 5 Your posterior probability of your theory being true = 5/6 = .83 Not a black and white decision like significance testing (conclude one thing if p = .048 and another if p = .052)
 = odds/(odds + 1) So if your prior odds had been 1 and the Bayes factor 5. Then posterior odds = 5. Your posterior probability of your theory being true = 5/6 = .83. Not a black and white decision like significance testing (conclude one thing if p = .048 and another if p = .052)")
14
While your prior odds are subjective
ALL assumptions going into B are explicit, and can be argued about until - in principle - agreed on by everyone Then B is to that degree objective Contrast Neyman Pearson – e.g. nobody might know what the actual stopping rule was. Assumptions are not necessarily explicit. People can “cheat” in this way with Neyman Pearson – one can’t in Bayes.

15
If B is greater than 1 then the data supported your experimental hypothesis over the null
If B is less than 1, then the data supported the null hypothesis over the experimental one If B = about 1, experiment was not sensitive. (Automatically get a notion of sensitivity; contrast: just relying on p values in significance testing.)
")
16
For each experiment you run, just keep updating your odds/personal probability by multiplying by each new Bayes factor No need for p values at all! No need for power calculations! No need for critical values of t-tests! And as we will see: No need for post hoc tests! No need to plan number of subjects in advance!

17
To know which theory data support need to know what the theories predict
The null is normally the prediction of e.g. no difference Need to decide what difference or range of differences are consistent with one’s theory Difficult - but forces one to think clearly about one’s theory. And this is what is required for power calculations, so psychologists should be doing it anyway. Bayes forces one to.

18
Contrasts with Neyman-Pearson:
A) A non-significant result can mean one should decrease one’s confidence in the null hypothesis.
 A non-significant result can mean one should decrease one’s confidence in the null hypothesis.")
19
A theory predicts a difference between conditions, but a null result is obtained.
Prediction of null Mean of data SE Difference between conditions Should one be less confident in the theory relative to the null hypothesis?

20
What does the theory predict?

21
What does the theory predict?
Mean of data Prediction of null If theory predicts a difference of 10 units, should slightly increase confidence in theory over null SE Difference between conditions

22
What does the theory predict?
But if theory predicts a difference of 20 units, data should decrease confidence in theory over null Mean of data Prediction of null SE Difference between conditions

23
NB It is simplistic to think the theory predicts only one value – but Bayes can deal with a range of values (it typically does)
")
24
Contrasts with Neyman-Pearson:
A) A non-significant result can mean one should decrease one’s confidence in the null. Conversely B) A significant result (i.e. accepting the experimental hypothesis on Neyman Pearson) can mean one should increase one’s confidence in the null
 A non-significant result can mean one should decrease one’s confidence in the null. Conversely. B) A significant result (i.e. accepting the experimental hypothesis on Neyman Pearson) can mean one should increase one’s confidence in the null.")
25
A theory predicts a difference between conditions, and one is obtained
A theory predicts a difference between conditions, and one is obtained. Should one be more confident in the theory relative to the null? Data mean Prediction of null SE Difference between conditions

26
What does the theory predict?

27
Data mean If theory predicts e.g. 20 or more, then significant result is evidence against theory Prediction of null SE Difference between conditions

28
More normally it is because the theory is vague that a significant result leads to less confidence in the theory i.e. many of the possible predictions of the theory are far from the data

29
i.e. because the theory makes no precise prediction at all!
The fact the null makes a precise prediction makes it more falsifiable, and hence preferred – this CAN mean one should be more confident in null Bayesian inference would encourage scientists to make more falsifiable theories; significance testing (without power) encourages theories of low falsifiability
 encourages theories of low falsifiability.")
30
2. On Neyman Pearson, it matters whether you formulated your hypothesis before or after looking at the data. Post hoc vs planned comparisons Predictions made in advance of rather than before looking at the data are treated differently Bayesian inference: It does not matter what day of the week you thought of your theory The evidence for your theory is just as strong regardless of its timing

31
3. On Neyman Pearson standardly you should plan in advance how many subjects you will run.
If you just miss out on a significant result you can’t just run 10 more subjects and test again. You cannot run until you get a significant result. Bayes: It does not matter when you decide to stop running subjects. You can always run more subjects if you think it will help.

32
4. On Neyman Pearson you must correct for how many tests you conduct in total.
For example, if you ran 100 correlations and 4 were just significant, researchers would not try to interpret those significant results. On Bayes, it does not matter how many other statistical hypotheses you investigated. All that matters is the data relevant to each hypothesis under investigation.

33
The strengths of Bayesian analyses are also its weaknesses:
1) P-values do not require specifying a predicted effect size so significance testing is simple. Bayes requires saying what the theory predicts – there may be argument over what effect size a theory predicts. Using p-values side steps this argument.
 P-values do not require specifying a predicted effect size so significance testing is simple. Bayes requires saying what the theory predicts – there may be argument over what effect size a theory predicts. Using p-values side steps this argument.")
34
The strengths of Bayesian analyses are also its weaknesses:
1) P-values do not require specifying a predicted effect size so is simple. Bayes requires saying what the theory predicts – there may be argument over what effect size a theory predicts. BUT isn’t this just the sort of argument the field needs? If someone disagrees they can argue their case – in Bayes all assumptions must be explicit. In Neyman Pearson some important aspects are hidden. Neyman Pearson done properly requires specifying effect size.
 P-values do not require specifying a predicted effect size so is simple. Bayes requires saying what the theory predicts – there may be argument over what effect size a theory predicts. BUT isn’t this just the sort of argument the field needs If someone disagrees they can argue their case – in Bayes all assumptions must be explicit. In Neyman Pearson some important aspects are hidden. Neyman Pearson done properly requires specifying effect size.")
35
The strengths of Bayesian analyses are also its weaknesses:
2) Bayesian procedures – because they are not concerned with long term frequencies - are not guaranteed to control error probabilities (Type I, type II).
 Bayesian procedures – because they are not concerned with long term frequencies - are not guaranteed to control error probabilities (Type I, type II).")
36
The strengths of Bayesian analyses are also its weaknesses:
2) Bayesian procedures – because they are not concerned with long term frequencies - are not guaranteed to control error probabilities (Type I, type II). Which is more important to you –to use a procedure with known long term error rates or to know the degree of support for your theory (the amount by which you should change your conviction in a theory)?
 Bayesian procedures – because they are not concerned with long term frequencies - are not guaranteed to control error probabilities (Type I, type II). Which is more important to you –to use a procedure with known long term error rates or to know the degree of support for your theory (the amount by which you should change your conviction in a theory)")
37
To calculate a Bayes factor must decide what range of differences is consistent with the theory
Uniform distribution Half normal Normal

38
Example: The theory predicts a difference will be in one direction.
Minimally informative prior, other than difference is positive: Probability density 5 10 20 Difference between conditions Maximum difference allowed

39
But how to scale the rate of drop?
Seems more plausible to think the larger effects are less likely than the smaller ones: Probability density Difference between conditions But how to scale the rate of drop?

40
Similar sorts of effects as those predicted in the past have been on the order of a 5% difference between conditions in classification accuracy. Probability density 5 Difference between conditions Implies: Smaller effects more likely than bigger ones; effects bigger than 10% very unlikely

41
Probability density 5 10 Difference between conditions

42
To calculate Bayes factor in a t-test situation
Need same information from the data as for a t-test: Mean difference, Mdiff SE of difference, SEdiff

43
To calculate Bayes factor in a t-test situation
Need same information from the data as for a t-test: Mean difference, Mdiff SE of difference, SEdiff Note: t = Mdiff / SEdiff So if a paper gives Mdiff and t For any of between- or within-subjects or single-sample t-test you know SEdiff = Mdiff / t NB: F(1,x) = t2(x)
 = t2(x)")
44
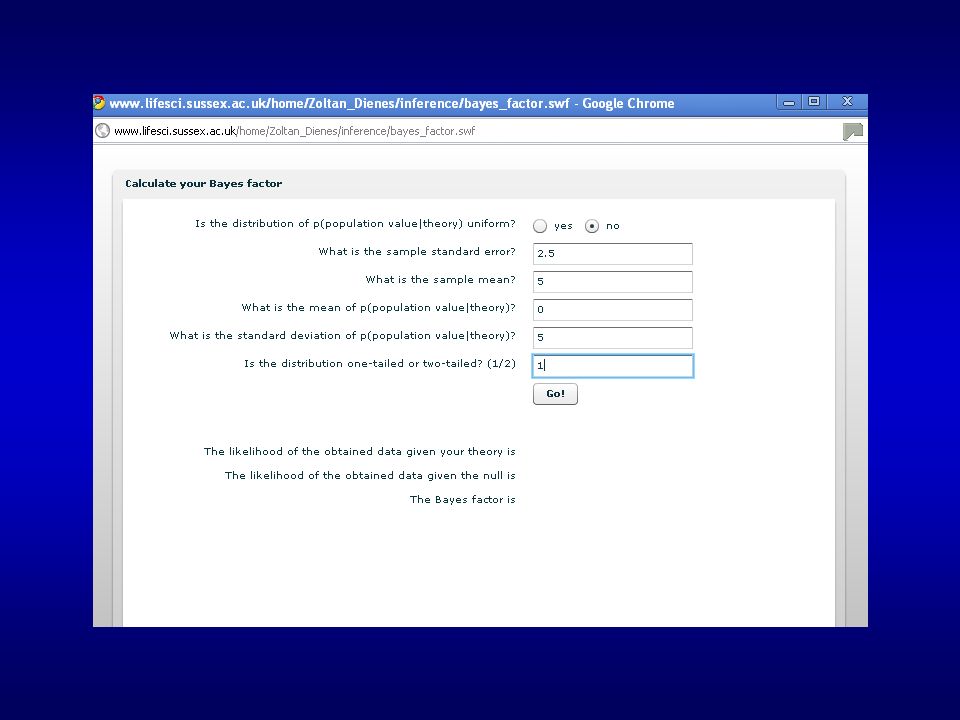
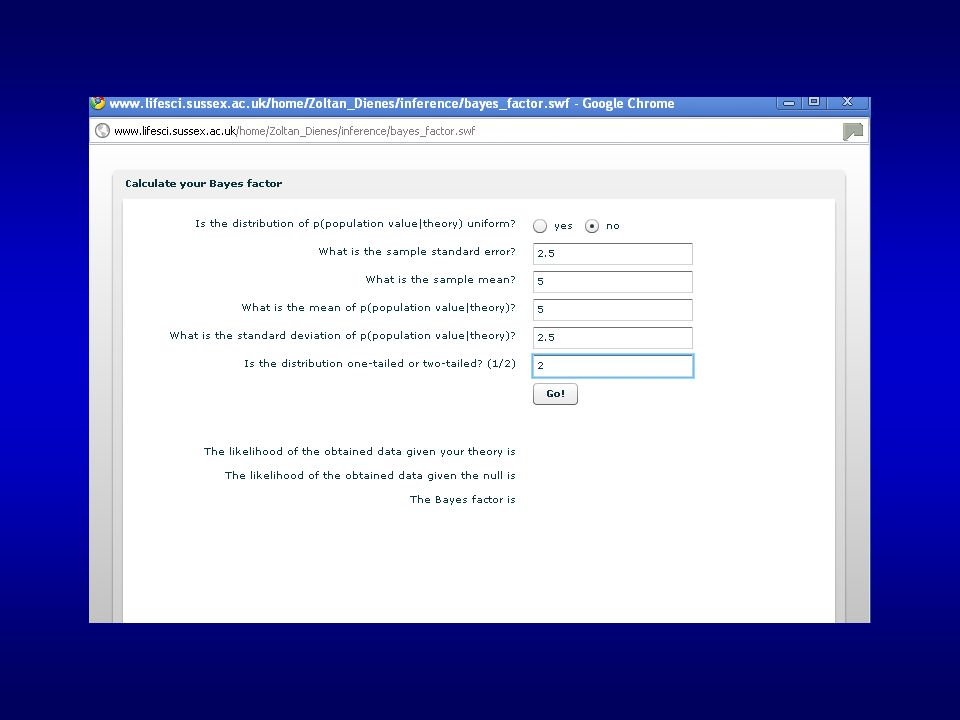
To calculate a Bayes factor:
1) Google “Zoltan Dienes” 2) First site to come up is the right one: 3) Click on link to book 4) Click on link to Chapter Four 5) Scroll down and click on “Click here to calculate your Bayes factor!”
 Google Zoltan Dienes 2) First site to come up is the right one: 3) Click on link to book. 4) Click on link to Chapter Four. 5) Scroll down and click on Click here to calculate your Bayes factor!")
47
difference = control condition – memory load condition
Example: On a task where people make binary classifications about 65% correct (i.e. 15% above chance) we load working memory to see if it interferes difference = control condition – memory load condition Probability density 5 10 15 Difference between conditions Maximum difference expected
 we load working memory to see if it interferes. difference = control condition – memory load condition. Probability density Difference between conditions. Maximum difference expected.")
49
Jeffreys, 1961: Bayes factors more than 3 or less than a third are substantial

51
Similar sorts of effects as those predicted in the past have been on the order of a 5% difference between conditions in classification accuracy. Probability density 5 Difference between conditions Implies: Smaller effects more likely than bigger ones; effects bigger than 10% very unlikely

54
Probability density 5 10 Difference between conditions

57
Assignment: 12) What was the mean difference obtained in the study? 13) What was the standard error of this difference? 14) Extending your answer in (7), specify a probability distribution for the difference expected by the theory and justify it 15) What is the Bayes factor in favour of the theory over the null hypothesis? 16) What does this Bayes factor tell you that the t-test does not?
 Extending your answer in (7), specify a probability distribution for the difference expected by the theory and justify it. 15) What is the Bayes factor in favour of the theory over the null hypothesis 16) What does this Bayes factor tell you that the t-test does not")
Similar presentations

















 REJECT Compute the Sample Mean.>")







