Download presentation
Presentation is loading. Please wait.

1
PHILOSOPHY OF SCIENCE: Bayesian inference Zoltán Dienes, Philosophy of Psychology Thomas Bayes 1702-1761

2
Subjective probability: Personal conviction in an opinion – to which a number is assigned that obeys the axioms of probability. Probabilities reside in the mind of the individual not the external world. There are no true or objective probabilities. You can’t be criticized for your subjective probability regarding any uncertain proposition – but you must revise your probability in the light of data in ways consistent with the axioms of probability.

3
Personal probabilities: Which of the following alternatives would you prefer? If your choice turns out to be true I will pay you 10 pounds: 1.It will rain tomorrow in Brighton 2.I have a bag with one blue chip and one red chip. I randomly pull out one chip and it is red.

4
Personal probabilities: Which of the following alternatives would you prefer? If your choice turns out to be true I will pay you 10 pounds: 1.It will rain tomorrow in Brighton 2.I have a bag with one blue chip and one red chip. I randomly pull out one and it is red. If you chose 2, your p(‘it will rain’) is less than.5 If you chose 1, your p(‘it will rain’) is greater than.5
 is less than.5 If you chose 1, your p(‘it will rain’) is greater than.5.")
5
Assume you think it more likely than not that it will rain. Now which do you chose? I will give you 10 pounds if your chosen statement turns out correct. 1.It will rain tomorrow in Brighton. 2.I have a bag with 3 red chips and 1 blue. I randomly pick a chip and it is red.

6
Assume you think it more likely than not that it will rain. Now which do you chose? I will give you 10 pounds if your chosen statement turns out correct. 1.It will rain tomorrow in Brighton. 2.I have a bag with 3 red chips and 1 blue. I randomly pick a chip and it is red. If you chose 2, your p(‘it will rain’) is less than.75 (but more than.5) If you chose 1, your p(‘it will rain’) is more than.75.
 is less than.75 (but more than.5) If you chose 1, your p(‘it will rain’) is more than.75..")
7
By imagining a bag with differing numbers of red and blue chips, you can make your personal probability as precise as you like. e.g. if you prefer, in order to get 10 pounds, gambling on ‘It will rain tomorrow in brighton’ Rather than on ‘Selecting one red chip out of a bag composed of 6 reds and 4 blues’ Then your personal probability that it will rain is greater than 0.6.

8
This is a notion of probability that applies to the truth of theories (Remember objective probability does not apply to theories) So that means we can answer questions about p(H) – the probability of a hypothesis being true – and also p(H|D) – the probability of a hypothesis given data (which we cannot do on the Neyman-Pearson approach).
 So that means we can answer questions about p(H) – the probability of a hypothesis being true – and also p(H|D) – the probability of a hypothesis given data (which we cannot do on the Neyman-Pearson approach).")
9
Consider a theory you might be testing in your project. What is your personal probability that the theory is true?

10
ODDS in favour of a theory = P(theory is true)/P(theory is false) For example, for the theory you may be testing ‘extroverts have high cortical arousal’ Then you might think (it’s completely up to you) P(theory is true) = 0.5 It follows you think that P(theory is false) = 1 – P(theory is true) = 0.5 So odds in favour of theory = 0.5/0.5 = 1 Even odds
/P(theory is false) For example, for the theory you may be testing ‘extroverts have high cortical arousal’ Then you might think (it’s completely up to you) P(theory is true) = 0.5 It follows you think that P(theory is false) = 1 – P(theory is true) = 0.5 So odds in favour of theory = 0.5/0.5 = 1 Even odds")
11
If you think P(theory is true) = 0.8 Then you must think P(theory is false) = 0.2 So your odds in favour of the theory are 0.8/0.2 = 4 (4 to 1) What are your odds in favour of the theory you are testing in your project?
 = 0.8 Then you must think P(theory is false) = 0.2 So your odds in favour of the theory are 0.8/0.2 = 4 (4 to 1) What are your odds in favour of the theory you are testing in your project")
12
Odds before you have collected your data are called your prior odds Experimental results tell you by how much to increase your odds (the Bayes Factor, B) Odds after collecting your data are called your posterior odds Posterior odds = B * Prior odds For example, a Bayesian analysis might lead to a B of 5. What would your posterior odds for your project hypothesis be?

13
You can convert back to probabilities with the formula: P (Theory is true) = odds/(odds + 1) So if your prior odds had been 1 and the Bayes factor 5 Then posterior odds = 5 Your posterior probability of your theory being true = 5/6 =.83 Not a black and white decision like significance testing (conclude one thing if p =.048 and another if p =.052)
 = odds/(odds + 1) So if your prior odds had been 1 and the Bayes factor 5 Then posterior odds = 5 Your posterior probability of your theory being true = 5/6 =.83 Not a black and white decision like significance testing (conclude one thing if p =.048 and another if p =.052)")
14
If B is greater than 1 then the data supported your experimental hypothesis over the null If B is less than 1, then the data supported the null hypothesis over the experimental one If B = about 1, experiment was not sensitive. (Automatically get a notion of sensitivity; contrast: just relying on p values in significance testing.)
.")
15
For each experiment you run, just keep updating your odds/personal probability by multiplying by each new Bayes factor No need for p values at all! No need for power calculations! No need for critical values of t-tests! And as we will see: No need for post hoc tests! No need to plan number of subjects in advance!

16
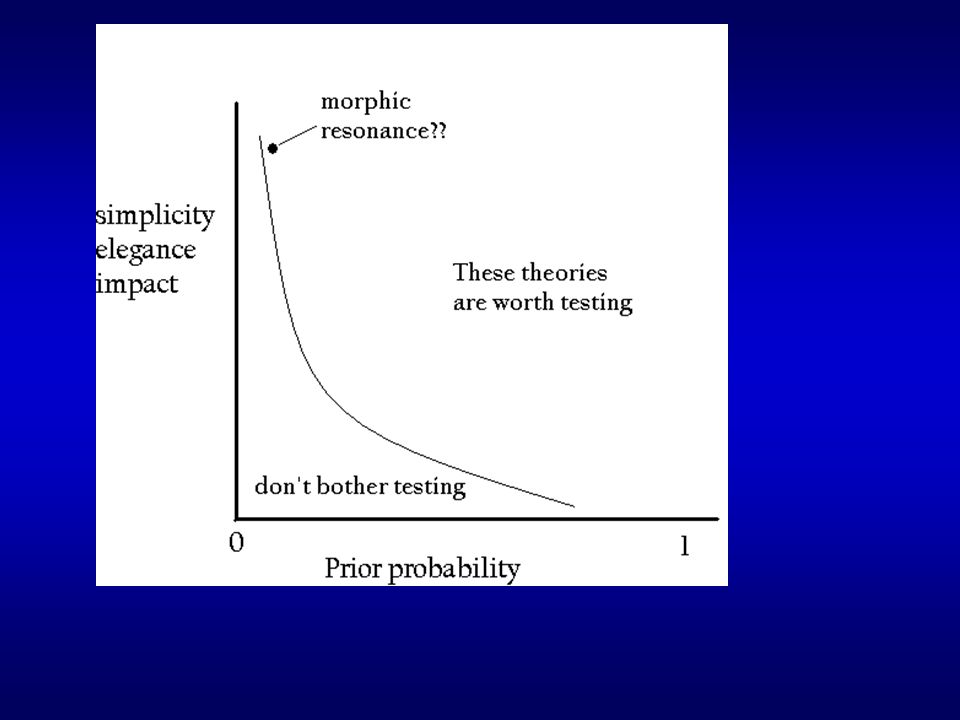
EXAMPLE WITH REAL DATA: Sheldrake’s (1981) theory of morphic resonance
 theory of morphic resonance")
17
EXAMPLE WITH REAL DATA: Sheldrake’s (1981) theory of morphic resonance - Any system by virtue of assuming a particular form, becomes associated with a “morphic field” - The morphic field then plays a causal role in the development and maintenance of future systems, acting perhaps instantaeously through space and without decay through time - The field guides future systems to take similar forms - The effect is stronger the more similar the future system is to the system that generated the field - The effect is stronger the more times a form has been assumed by previous similar systems - The effect occurs at all levels of organization
 theory of morphic resonance - Any system by virtue of assuming a particular form, becomes associated with a morphic field - The morphic field then plays a causal role in the development and maintenance of future systems, acting perhaps instantaeously through space and without decay through time - The field guides future systems to take similar forms - The effect is stronger the more similar the future system is to the system that generated the field - The effect is stronger the more times a form has been assumed by previous similar systems - The effect occurs at all levels of organization")
18
Nature editorial by John Maddox 1981: The “book is the best candidate for burning there has been in many years... Sheldrake’s argument is pseudo-science... Hypotheses can be dignified as theories only if all aspects of them can be tested.” Wolpert, 1984: “... It is possible to hold absurd theories which are testable, but that does not make them science. Consider the hypothesis that the poetic Muse resides in tiny particles contained in meat. This could be tested by seeing if eating more hamburgers improved one’s poetry”

20
Repetition priming Subjects identify a stimulus more quickly or accurately with repeated presentation of the stimulus Lexical decision Subjects decide whether a presented letter string makes a meaningful English word or not (in the order actually presented). Two aspects of repetition priming are consistent with an explanation that involves morphic resonance: Durability, stimulus specificity Unique prediction of morphic resonance: Should get repetition priming between separate subjects! (ESP)
.")
21
Design: Stimuli:shared+uniquesharedshared+unique... Subject no:12..910,... Subject type:resonatorboostersresonator...

22
Design: Stimuli:shared+uniquesharedshared+unique... Subject no:12..910,... Subject type:resonatorboostersresonator... - There were 10 resonators in total with nine boosters between each. Resonators were assigned randomly in advance to their position in the sequence. - The shared stimuli received morphic resonance at ten times the rate as the unique stimuli - There was a distinctive experimental context (white noise, essential oil of ylang ylang, stimuli seen through a chequerboard pattern)
.")
23
Design: Stimuli:shared+uniquesharedshared+unique... Subject no:12..910,... Subject type:resonatorboostersresonator... Prediction of theory of morphic resonance: The resonators should become progressively faster on the shared as compared to the unique stimuli

24
Data for words. slope (ms/resonator) = - 5.0, SE = 1.5 Neyman-Pearson: p = 0.009 significant
 = - 5.0, SE = 1.5 Neyman-Pearson: p = significant")
25
With some plausible assumptions, Bayes factor = 12 i.e. whatever one’s prior odds in favour of morphic resonance you should multiply them by 12 in the light of the data. Contrast Neyman-Pearson: Result was significant so should categorically reject null hypothesis With Bayesian approach, if before you had a very low odds in favour of morphic resonance, they can still be very low afterwards.

26
NB: I ran further three further studies with same paradigm Including one in which boosters were run at Sussex and resonators run in Goetingen – could they show which word set was being boosted in Sussex?? All results flat as a pancake. Combined Bayes factor for non-word data = about 1 Combining with word data = about ½ Does not rule out morphic resonance – just changes our odds

27
Summary: A Bayes factor tells you how much to multiply your prior odds in the light of data. Advantages: Low sensitive experiments show up as having Bayes’ factors near 1. You are not tempted to accept the null hypothesis just because the experiment was insensitive.

28
Contrasts with Neyman-Pearson: 1.A significant result (i.e. accepting the experimental hypothesis on Neyman Pearson) can give rise to a very small Bayes factor!! See handout for example. (It arises for vague theories – vague theories are punished by Bayes)
 can give rise to a very small Bayes factor!. See handout for example. (It arises for vague theories – vague theories are punished by Bayes).")
29
2. On Neyman Pearson, it matters whether you formulated your hypothesis before or after looking at the data. Post hoc vs planned comparisons Predictions made in advance of rather than before looking at the data are treated differently Bayesian inference: It does not matter what day of the week you thought of your theory The evidence for your theory is just as strong regardless of its timing

30
3. On Neyman Pearson standardly you should plan in advance how many subjects you will run. If you just miss out on a significant result you can’t just run 10 more subjects and test again. You cannot run until you get a significant result. Bayes: It does not matter when you decide to stop running subjects. You can always run more subjects if you think it will help.

31
4. On Neyman Pearson you must correct for how many tests you conduct in total. For example, if you ran 100 correlations and 4 were just significant, researchers would not try to interpret those significant results. On Bayes, it does not matter how many other statistical hypotheses you investigated. All that matters is the data relevant to each hypothesis under investigation.

32
The strengths of Bayesian analyses are also its weaknesses: 1.Are our subjective convictions really susceptible to the assignment of precise numbers and are they really the sorts of things that do or should follow the axioms of probability? Should papers worry about the strength of our convictions in their result sections, or just the objective reasons for why someone might change their opinions? BUT can just report Bayes factor

33
2.Bayesian procedures – because they are not concerned with long term frequencies - are not guaranteed to control error probabilities (Type I, type II). Which is more important to you –to use a procedure with known long term error rates or to know the amount by which you should change your conviction in a hypothesis?

Similar presentations