Download presentation
Presentation is loading. Please wait.

1
What’s in a Corpus? School of Computing
FACULTY OF ENGINEERING What’s in a Corpus? Eric Atwell, Language Research Group (with thanks to Katja Markert, Marti Hearst, and other contributors)
")
2
Reminder Why NLP is difficult: language is a complex system
How to solve it? Corpus-based machine-learning approaches Motivation: applications of “The Language Machine” BACKGROUND READING: (Atwell 99) The Language Machine Intro to NLTK Visit the website:
 The Language Machine. Intro to NLTK. Visit the website:")
3
Today The main areas of linguistics
Rationalism: language models based on expert introspection Empiricism: models via machine-learning from a corpus Corpus: text selected by language, genre, domain, … Brown, LOB, BNC, Penn Treebank, MapTask, CCA, … Corpus Annotation: text headers, PoS, parses, … Corpus size is no. of words – depends on tokenisation We can count word tokens, word types, type-token distribution Lexeme/lemma is “root form”, v inflections (be v am/is/was…)
")
4
The main sub-areas of linguistics
◮ Phonetics and Phonology: The study of linguistic sounds or speech. ◮ Morphology: The study of the meaningful components of words. ◮ Syntax (grammar): The study of the order and links between words. ◮ Semantics: The study of meanings of words, phrases, sentences. ◮ Discourse: The study of linguistic units larger than a single utterance. ◮ Pragmatics: The study of how language is used to accomplish goals.
: The study of the order and links between words. ◮ Semantics: The study of meanings of words, phrases, sentences. ◮ Discourse: The study of linguistic units larger than a single utterance. ◮ Pragmatics: The study of how language is used to accomplish goals.")
5
Why is NLP hard? Main reason: Ambiguity in all areas and on all levels, e.g: ◮ Phonetic Ambiguity: 1 expression being pronounced in several ways ◮ POS Ambiguity: 1 word having several different Parts of Speech (adjective/noun...) ◮ Lexical Ambiguity: 1 word having several different meanings ◮ Syntactic/Structural Ambiguity: 1 phrase or sentence having several different possible structures ◮ Pragmatic Ambiguity: 1 sentence communicating several different intentions ◮ Referential Ambiguity: 1 expression having several different possible references Key Task in NLP: Disambiguation in context!
 ◮ Lexical Ambiguity: 1 word having several different meanings. ◮ Syntactic/Structural Ambiguity: 1 phrase or sentence having several. different possible structures. ◮ Pragmatic Ambiguity: 1 sentence communicating several different intentions. ◮ Referential Ambiguity: 1 expression having several different possible references. Key Task in NLP: Disambiguation in context!")
6
Rationalism v Empiricism
Rationalism: the doctrine that knowledge is acquired by reason without regard to experience (Collins English Dictionary) Noam Chomsky, 1957 Syntactic Structures Argued that we should build models through introspection: A language model is a set of rules thought up by an expert Like “Expert Systems”… Chomsky thought data was full of errors, better to rely on linguists’ intuitions…
 Noam Chomsky, 1957 Syntactic Structures. Argued that we should build models through introspection: A language model is a set of rules thought up by an expert. Like Expert Systems … Chomsky thought data was full of errors, better to rely on linguists’ intuitions…")
7
Empiricism v Rationalism
Empiricism: the doctrine that all knowledge derives from experience (Collins English Dictionary) The field was stuck for quite some time: rationalist linguistic models for a specific example did not generalise. A new approach started around 1990: Corpus Linguistics Well, not really new, but in the 50’s to 80’s, they didn’t have the text, disk space, or GHz Main idea: machine learning from CORPUS data How to do corpus linguistics: Get large text collection (a corpus; plural: several corpora) Compute statistical models over the words/PoS/parses/… in the corpus Surprisingly effective
 The field was stuck for quite some time: rationalist. linguistic models for a specific example did not generalise. A new approach started around 1990: Corpus Linguistics. Well, not really new, but in the 50’s to 80’s, they didn’t have the text, disk space, or GHz. Main idea: machine learning from CORPUS data. How to do corpus linguistics: Get large text collection (a corpus; plural: several corpora) Compute statistical models over the words/PoS/parses/… in the corpus. Surprisingly effective.")
8
What is a corpus? A corpus is a finite machine-readable body of naturally occurring text, selected according to specified criteria, eg: ◮ Language and type: English/German/Arabic/…, dialects v. “standard”, edited text v. spontaneous speech, … ◮ Genre and Domain: 18th century novels, newspaper text, software manuals, train enquiry dialogue... ◮ Web as Corpus: URL “domain” = country: .uk .ar ◮ Media: “Written” Text, Audio, Transcriptions, Video. ◮ Size: 1000 words, 50K words, 1M words, 100M words, ???

9
Brown and LOB ◮ Brown: Famous first corpus! (well, first widely-used corpus) ◮ by Nelson Francis and Henry Kucera, Brown University USA ◮ A balanced corpus: representative of a whole language ◮ Brown: balanced corpus of written, published American English from 1960s (newspapers, books, … NOT handwritten) ◮ 1 million words, Part-of-Speech tagged. ◮ LOB: Lancaster-Oslo/Bergen corpus: British English version ◮ published British English text from equivalent 1960s sources ◮FROWN, FLOB: US, UK text from equivalent 1990s sources
 ◮ 1 million words, Part-of-Speech tagged. ◮ LOB: Lancaster-Oslo/Bergen corpus: British English version. ◮ published British English text from equivalent 1960s sources. ◮FROWN, FLOB: US, UK text from equivalent 1990s sources.")
10
Some recent corpora Corpus features: Size, Domain, Language
British National Corpus: 100M words, balanced British English Newswire Corpus: 600M words, newswire, American English UN or EU proceedings: 20M+ words, legal, 10 language pairs Penn Treebank: 2M words, newswire American English MapTask: 128 dialogues, British English Corpus of Contemporary Arabic: 1M words, balanced Arabic Web: 8 billion(?) words, many domains and languages Web-as-Corpus: harvest your own corpus from WWW, via “seed terms” Google API web-pages Corpus! Marco Baroni: BootCat, Adam Kilgarriff: SketchEngine, …
 words, many domains and languages. Web-as-Corpus: harvest your own corpus from WWW, via seed terms Google API web-pages Corpus! Marco Baroni: BootCat, Adam Kilgarriff: SketchEngine, …")
11
Corpus Annotation Annotation is a process in which linguistics experts add (linguistic) information to the corpus that is not explicitly there (increases utility of a corpus), e.g.: ◮Text Headers: meta-data for each text: author, date, type,… ◮ Part-of-speech tag for each word (very common!). ◮ Syntactic structure: parse-tree for each sentence ◮ Word Sense label for each word ◮ Prosodic information: pauses, rise and fall in pitch, etc.
 information to the corpus that is not explicitly there (increases utility of a corpus), e.g.: ◮Text Headers: meta-data for each text: author, date, type,… ◮ Part-of-speech tag for each word (very common!). ◮ Syntactic structure: parse-tree for each sentence. ◮ Word Sense label for each word. ◮ Prosodic information: pauses, rise and fall in pitch, etc.")
12
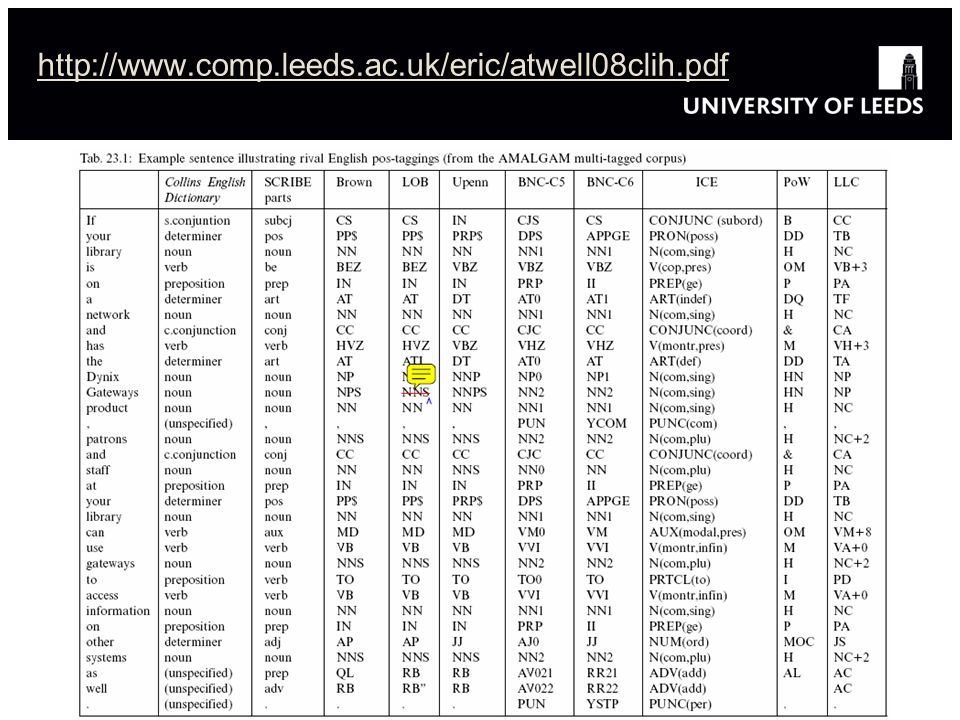
Annotation example: POS tagging
◮ Some texts are annotated with Part-of-speech (POS) tags. ◮ POS tags encode simple grammatical functions. <s><w pos=RN> Here </w> <w pos=BEZ> is </w> <w pos=AT> a </w> <w pos=NN> sentence </w>.</s> ◮ Several tag sets: ◮ Brown tag set (87 tags) in Brown corpus ◮ CLAWS / LOB tag set (132 tags) in LOB corpus ◮ Penn tag set (45 tags) in Penn Treebank ◮ CLAWS c5 tag set (62 tags) in BNC (British National Corpus) ◮ Tagging is usually done automatically (then proofread and corrected)
 tags. ◮ POS tags encode simple grammatical functions. <s><w pos=RN> Here </w> <w pos=BEZ> is </w> <w pos=AT> a </w> <w pos=NN> sentence </w>.</s> ◮ Several tag sets: ◮ Brown tag set (87 tags) in Brown corpus. ◮ CLAWS / LOB tag set (132 tags) in LOB corpus. ◮ Penn tag set (45 tags) in Penn Treebank. ◮ CLAWS c5 tag set (62 tags) in BNC (British National Corpus) ◮ Tagging is usually done automatically (then proofread and corrected)")
15
What’s a word? How many words do you find in the following short text?
What is the biggest/smallest plausible answer to this question? What problems do you encounter? It’s a shame that our data-base is not up-to-date. It is a shame that um, data base A costs $ and that database B costs $5000. All databases cost far too much. Time: 1 minute

16
Counting words: tokenization
Tokenisation is a processing step where the input text is automatically divided into units called tokens where each is either a word or a number or a punctuation mark… So, word count can ignore numbers, punctuation marks (?) Word: Continuous alphanumeric characters delineated by whitespace. Whitespace: space, tab, newline. BUT dividing at spaces is too simple: It’s, data base
 Word: Continuous alphanumeric characters delineated by whitespace. Whitespace: space, tab, newline. BUT dividing at spaces is too simple: It’s, data base.")
17
Counting words: types v tokens
◮ Word token: individual occurrence of words. ◮ Q: How big is the corpus (N)? = how many word tokens are there? (LOB: 1M; BNC: 100M) ◮Word type: the “word itself” regardless of context ◮ Q: How many “different words” (word types) are there? = Size of corpus vocabulary (LOB: 50K, BNC: 650K) ◮ Q: What is the frequency of each word type? = type-token distribution A few word=types (the of a …) are very frequent, but most are rare, and half of all word-types occur only once! Zipf’s Law
 = how many word tokens are there (LOB: 1M; BNC: 100M) ◮Word type: the word itself regardless of context. ◮ Q: How many different words (word types) are there = Size of corpus vocabulary (LOB: 50K, BNC: 650K) ◮ Q: What is the frequency of each word type = type-token distribution. A few word=types (the of a …) are very frequent, but most are rare, and half of all word-types occur only once! Zipf’s Law.")
18
Other sorts of “words” ◮ Lemma/Lexeme: dictionary form of a word. cost and costs are derived from the same lexeme “cost”. data-base, data base, database, databases – same lexeme Can include spaces: data base, New York Ambiguous tokenization: as well (= also), as well as (= and) Inflection: grammatical variant, eg cost v costs ◮ Morpheme: basic “atomic” indivisible unit of meaning or grammar, e.g. data, base, s ◮ For languages other than English, morphological analysis can be hard: root/stem, affixes (prefix, postfix, infix) morph ologi cal or morpho logic al ?
, as well as (= and) Inflection: grammatical variant, eg cost v costs. ◮ Morpheme: basic atomic indivisible unit of meaning or grammar, e.g. data, base, s. ◮ For languages other than English, morphological analysis can be hard: root/stem, affixes (prefix, postfix, infix) morph ologi cal or morpho logic al")
19
ب ت ك ? و ? ? مَ ? ِ? ا ? مكتوب كاتب b t k Arabic Morphology
Templatic Morphology ب ت ك Root b t k Pattern ? و ? ? مَ ? ِ? ا ? ū ma i ā Psycholinguistic reality format فرمت farmat Dictionary ordered Not all combinations possible مكتوب كاتب Lexeme maktūb written kātib writer Lexeme.Meaning = (Root.Meaning+Pattern.Meaning)*Idiosyncrasy.Random
*Idiosyncrasy.Random.")
20
Arabic Morphology Root Meaning + Pattern meaning + ??
ك ت ب KTB = notion of “writing” كتاب /kitāb/ book كتب /katab/ write مكتوب /maktūb/ written مكتبة /maktaba/ library مكتوب /maktūb/ letter مكتب /maktab/ office كاتب /kātib/ writer

21
Reminder Rationalism: language models based on expert introspection
Empiricism: models via machine-learning from a corpus Corpus: text selected by language, genre, domain, … Brown, LOB, BNC, Penn Treebank, MapTask, CCA, … Corpus Annotation: text headers, PoS, parses, … Corpus size is no. of words – depends on tokenisation We can count word tokens, word types, type-token distribution Morpheme: basic lexical unit, “root form”, plus affixes Lexeme: dictionary entry, can be multi-word: New York

Similar presentations







>")


 & Text Corpora.>")









 – Corpora – Treebanks Secondary resources – Designed for a.>")