Download presentation
Presentation is loading. Please wait.

1
Data reduction & classification Mark Tranmer CCSR

2
Introduction Data reduction techniques involve an investigation of the inter-relationships in a set number of variables of interest, either as an exploratory technique, or as a way of constructing an index from those variables. PCA is the most commonly used data reduction technique and is used to reduce the number of dimensions in a large number of variables to just a few dimensions.

3
Data reduction: examples Examples include: Construct validity of questionnaires Factorial ecology – geographical studies: characteristics of areas. Latent variables – intelligence, numeracy Constructing deprivation indices – we will consider this in detail later

4
Data Reduction Today we will focus on Principal Component Analysis (PCA) as a data reduction technique. If you want to read more about the distinction between Factor Analysis and PCA, see Chatfield & Collins (1992) and Field (2005) in the reading list.
 and Field (2005) in the reading list..")
5
Data Classification Data classification techniques involve a way of grouping together cases that are similar in a dataset. The most common way of doing this is through a cluster analysis. An example of the use of this technique is to identify similar areas on the basis of a set of census variables.

6
Today we will look at data reduction and classification from a theoretical perspective with some examples. We will also try out some of these techniques using SPSS. The examples will be based on data from the 1991 UK census.

7
Principal Component Analysis (PCA) What is it? PCA is a multivariate statistical technique Used to examine the relationships among p correlated variables. It may be useful to transform the original set of variables to a new set of uncorrelated variables called principal components.

8
Principal Component Analysis (PCA) These new variables are linear combinations of the original variables and are derived in decreasing order of importance. If we start with p variables, we can obtain p principal components. The first principal component accounts for the most variation in the original data. We do not have a dependent variable and explanatory variables in PCA.

9
Principal Component Analysis (PCA) The usual objective is to see if the first few components account for most of the variation in the data. If they do, it is argued that dimensionality of the problem is less than p. E.g. if we have 20 variables, and these are explained largely by the first 2 components, we might say that we do not have a 20 dimensional problem, but in fact a 2 dimensional problem.

10
Principal Component Analysis (PCA) Hence, Principal components analysis is also sometimes described as a data reduction technique. We can also use the principal components to construct indices (e.g. an index of deprivation) We can sometimes use a PCA (or factor analysis) as an EDA procedure, to get a feel for the data.
 We can sometimes use a PCA (or factor analysis) as an EDA procedure, to get a feel for the data..")
11
Principal Component Analysis (PCA) Finally we can use the principal component scores in other analyses like regression to get around the problem of multicollinearity, but interpretation may be difficult. If the original variables are nearly uncorrelated it is not worth carrying out the PCA. No statistical model is assumed in PCA. It is in fact a mathematical technique. When the components are extracted one of the mathematical constraints is that these components are uncorrelated with one another.

12
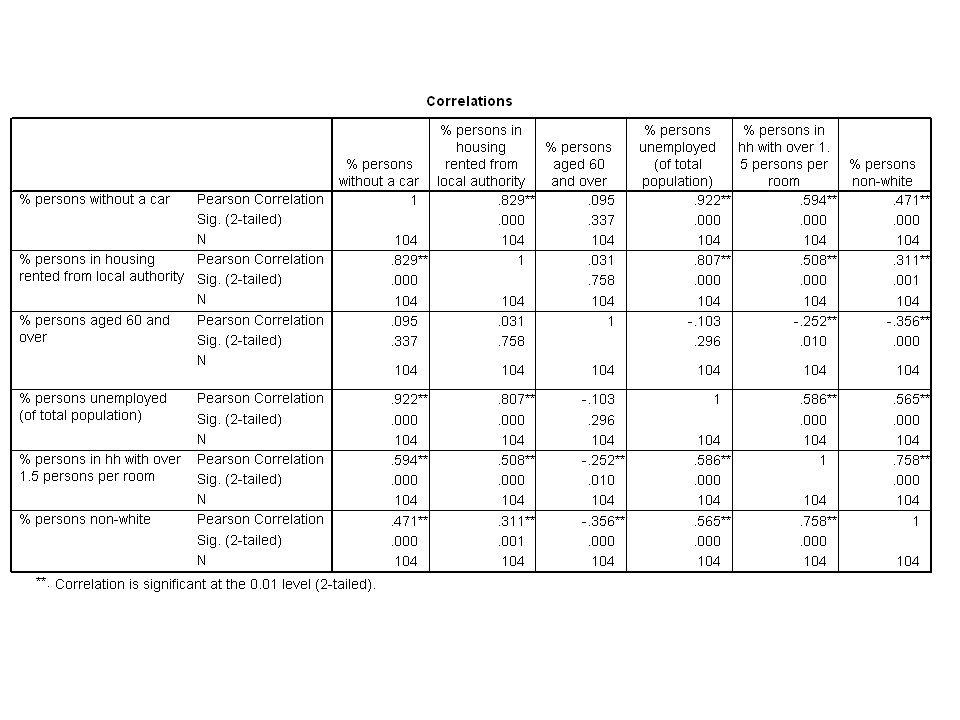
Principal Component Analysis (PCA) Example: making a deprivation index from census data. We have 6 census variables for 104 districts and we wish to make a district level index of deprivation from them.

13
Principal components analysis in SPSS. PCA is one of the data reduction techniques in SPSS We choose the factor analysis option from the data reduction menu. PCA is the default. We can save the factor scores – useful if we want to look at an index of deprivation.

14
Session 3: Principal components analysis practical We will focus on six variables: % of people in h/h with no car (CAR0) % of people in h/h renting from local authority (RLA) % of people aged 60 and over (A60P) % Adults unemployed (UNEM) % of people in households with more than 1 person per room (DENS) % Adults from non-white ethnic groups (NONW)
 % of people in h/h renting from local authority (RLA) % of people aged 60 and over (A60P) % Adults unemployed (UNEM) % of people in households with more than 1 person per room (DENS) % Adults from non-white ethnic groups (NONW)")
15
graphs

19
N Minimu m Maximu mMean Std. Deviation % persons without a car 1046.5157.2227.297312.32367 % persons in housing rented from local authority 1043.6960.9320.776310.70068 % persons aged 60 and over 10413.0626.2819.39412.36919 % persons unemployed (of total population) 1042.1210.594.99481.86621 % persons in hh with over 1.5 persons per room 104.1613.151.35171.63813 % persons non- white 104.4544.889.335110.15503 Valid N (listwise) 104
 % persons in hh with over 1.5 persons per room % persons non- white Valid N (listwise) 104.")
22
Principal components analysis.

30
We can save the factor scores in the data worksheet

32
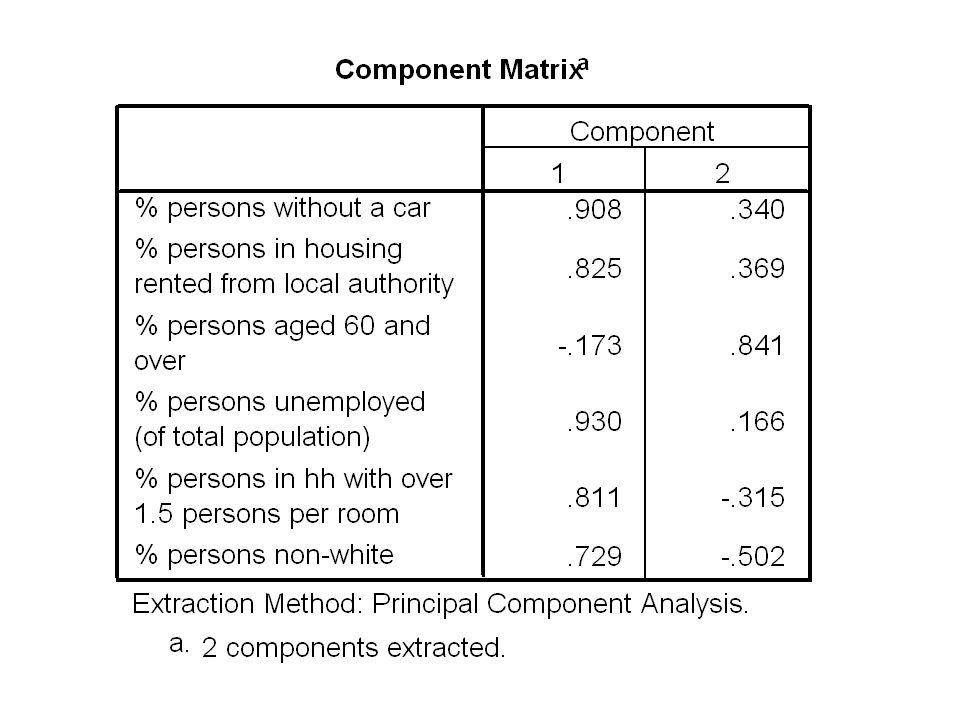
Principal components analysis By default, SPSS stops extracting components when the eigenvalues are smaller than 1. The eigenvalues get smaller for each component and many text books suggest that we should only consider components that have eigenvalues greater than 1. For our example, using this criterion, we have reduced our 6 dimensions to two components.

33
Principal components analysis Our two components (labelled U 1 and U 2 ) are: U 1 =.253*CAR0 +.230*RLA -.048*A60P +.259*UNEM +.226*DENS +.203*NONW U 2 =.254*CAR0 +.276*RLA -.629*A60P +.124*UNEM -.235*DENS -.375*NONW
 are: U 1 =.253*CAR *RLA -.048*A60P +.259*UNEM +.226*DENS +.203*NONW U 2 =.254*CAR *RLA -.629*A60P +.124*UNEM -.235*DENS -.375*NONW")
34
Principal components analysis We can look at the size of the loadings (coefficients) to see the relative importance of each variable in each component. The first component has an eigenvalue of 3.59 and explains 59.82 % of the total variance. This component has high positive coefficients for all variables except A60P.

35
Principal components analysis The second component has an eigenvalue of 1.34 and explains 22.30 % of the total variance. This component has high positive coefficient for A60P. Other variables have relatively small coefficients. This is because the components are assumed to be uncorrelated.

36
Principal components analysis Collectively, the two components explain around 82.12 % of the total variance in the original 6 variables (quite a lot!). We can save the component scores in SPSS. In this case they are called fac1 and fac2 (and the scores have been standardised: i.e. (score – mean(score))/(sd(score)).
)/(sd(score))..")
37
Principal components analysis Suppose we use the first component to construct a deprivation score. The first component is: U 1 =.25*CAR0 +.23*RLA -.05A60P +.26*UNEM +.23*DENS +.20*NONW Hence, higher scores on this component will tend to indicate higher deprivation. By substituting in the values of each variable for each district we can get a deprivation score for each district. In fact, SPSS will calculate the scores for us.

38
Principal components analysis Comparing two districts, we can see that Hackney, London has score on component 1 of 2.92 Chiltern, Bucks has a score on component 1 of –1.73

39
Principal components analysis Higher scores indicate higher deprivation. Hence, we might conclude that at the district level, Hackney, London is more deprived than Chiltern, bucks.

40
Data classification Introduction to cluster analysis The aim of cluster analysis is to classify a set of cases, such as individuals or areas, into a small number of groups. These groups are usually non- overlapping. Two main types of cluster analysis that we will discuss today are: Hierarchical cluster analysis (e.g. single linkage, group linkage, average linkage, Wards method). Non hierarchical cluster analysis (e.g. k-means) Other methods of cluster analysis are covered in detail in Everitt and Dunn (2001)
. Non hierarchical cluster analysis (e.g. k-means) Other methods of cluster analysis are covered in detail in Everitt and Dunn (2001).")
41
Data classification Note that the techniques covered here are based on assumption that there is no prior information on the groupings of cases. For situations where we know the number and composition of groups for existing cases, and we wish to allocate new cases to particular groups we can use techniques such as discriminant analysis (see, for example Everitt and Dunn (2001), Chapter 11.)
, Chapter 11.).")
42
Hierarchical Clustering Techniques (Agglomerative) hierarchical clustering techniques A hierarchical classification is achieved in a number of steps. Starting from n clusters - one for each individual and running through to one cluster which contains all n individuals. Once fusions (i.e putting cases into a particular cluster) are made these cases cannot be re-allocated to different clusters.
 are made these cases cannot be re-allocated to different clusters..")
43
Hierarchical Clustering Techniques Pro : no need to decide how many clusters you need Pro: can be ideal for things like biological classifications (see Everitt and Dunn, page 129) Con: imposes a structure on the data that may be inappropriate. Con: once a case has been allocated to a particular cluster it cannot then be re-allocated to a particular cluster. However, these techniques may still be useful in an exploratory sense to get some idea how many clusters there are before doing a non- hierarchical analysis (which does require the required number of clusters to be specified).
..")
44
Hierarchical Clustering Techniques Distance (or similarity measures) are often used to determine whether two observations are from a particular cluster the most common measures that are used are The minimum distance between observations in two clusters (single linkage) The maximum distance between observations in two clusters (complete linkage) The average distance between observations in two clusters (group average)
 are often used to determine whether two observations are from a particular cluster the most common measures that are used are The minimum distance between observations in two clusters (single linkage) The maximum distance between observations in two clusters (complete linkage) The average distance between observations in two clusters (group average)")
45
Hierarchical Clustering techniques Wards method An alternative approach, wards method, does not use distance measure to determine clusters. Instead, clusters are formed with this method by maximizing the within cluster homogeneity

46
Non hierarchical clustering methods non-hierarchical methods may also be used. The most common one, that will be discussed here is the k means cluster analysis. ( a full discussion of non hierarchical methods can be found in Sharma, page 202 ff.)
.")
47
Non hierarchical clustering methods non-hierarchical clustering techniques basically follow these steps. (see Sharma 1997 page 202). Select k initial cluster centroids, where k is the desired number of clusters Assign each case to the cluster that is the closest to it. Re-assign each case to one of the k clusters according to a pre-determined stopping rule.
. Select k initial cluster centroids, where k is the desired number of clusters Assign each case to the cluster that is the closest to it. Re-assign each case to one of the k clusters according to a pre-determined stopping rule..")
48
Non hierarchical clustering methods Methods used to obtain the initial cluster centroids include: use the first k observations as centroids Randomly select k non-missing observations as cluster centres. Use centroids supplied by the researcher e.g. from previous research

49
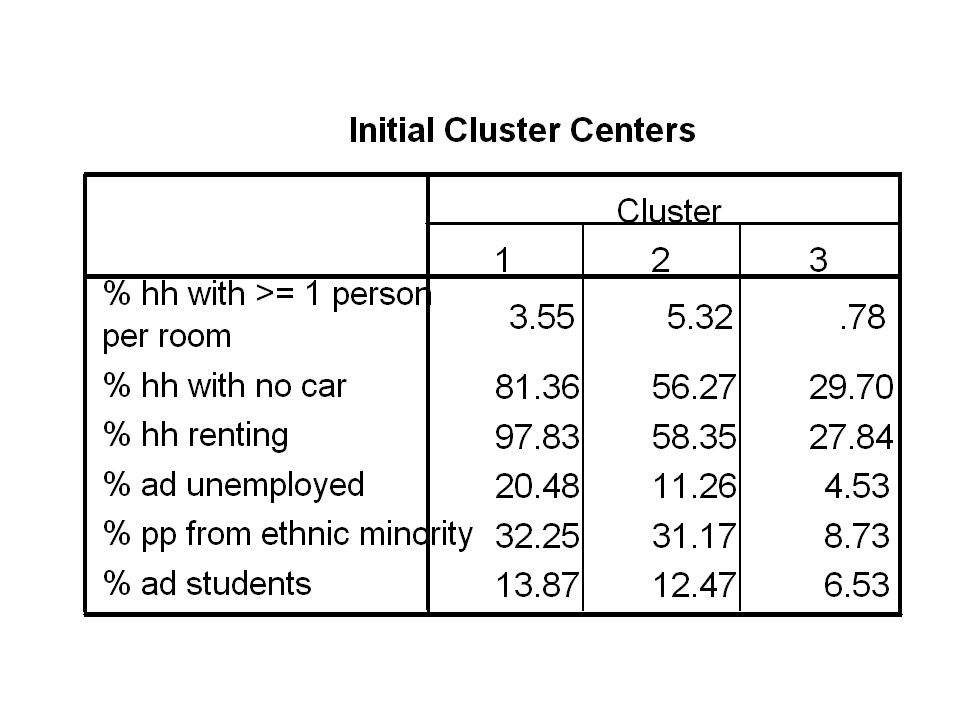
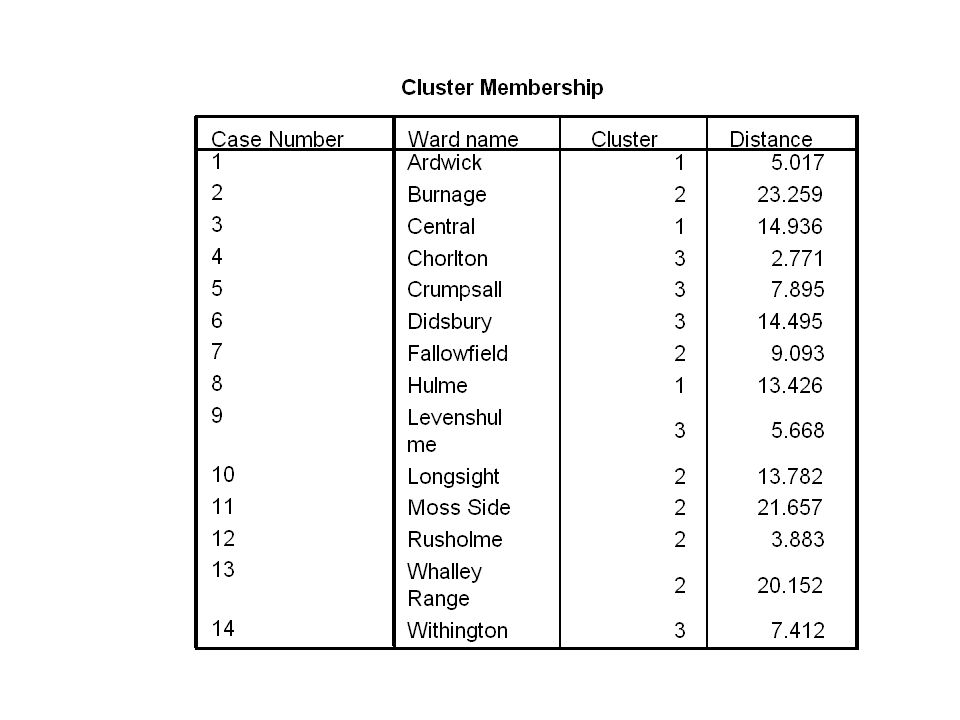
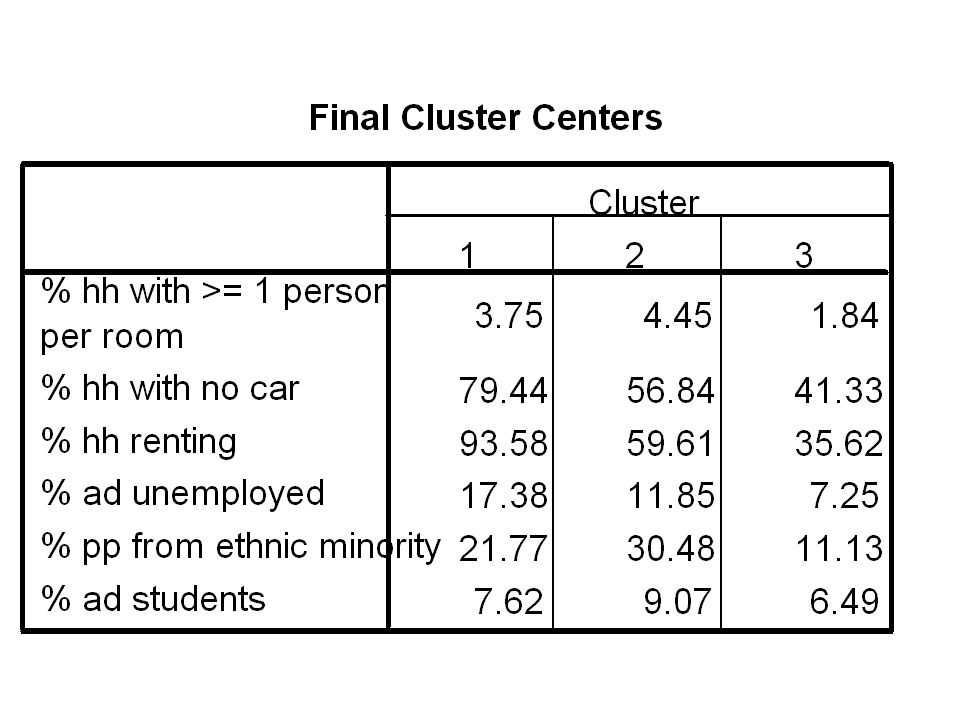
cluster analysis - example Data for 14 wards in manchester 1991 census data

50
cluster analysis - example Six variables Overcrowding No car Renting Unemployed Ethnic group Students

60
Reading List Applied multivariate techniques Subhash Sharma (1997) ISBN: 0-471-31064-6. Wiley. Applied multivariate data analysis Brian Everitt and Graham Dunn (2001) ISBN: 0-340-74122-8. Edward Arnold. Introduction to multivariate analysis Chatfield and Collins (1980 reprinted 1992). ISBN: 0 412 16040 4. Chapman and Hall Discovering Statistics Using SPSS. Andy Field (2005) ISBN: 0761944524. Sage Publications Ltd.
 ISBN: Edward Arnold. Introduction to multivariate analysis Chatfield and Collins (1980 reprinted 1992). ISBN: Chapman and Hall Discovering Statistics Using SPSS. Andy Field (2005) ISBN: Sage Publications Ltd..")
Similar presentations































 (1)to reduce the number of variables and (2) to detect structure in the relationships between variables, that is to classify.>")




