Download presentation
Presentation is loading. Please wait.

1
Introduction to modelling extremes
Marian Scott NERC Sept 2010

2
Introduction what is an extreme?- examples of extremes in environmental contexts Some statistical models for extremes Block maxima, Peak over threshold Including return levels Return period Statistical models for extremes are concerned with the tails of the distributions

3
problems Normal distribution inappropriate- so we need some new distributions Bulk of data not informing us about extremes Extremes are rare, so not much data Some statistical models for extremes Block maxima, Peak over threshold require parameter estimation which may prove difficult

4
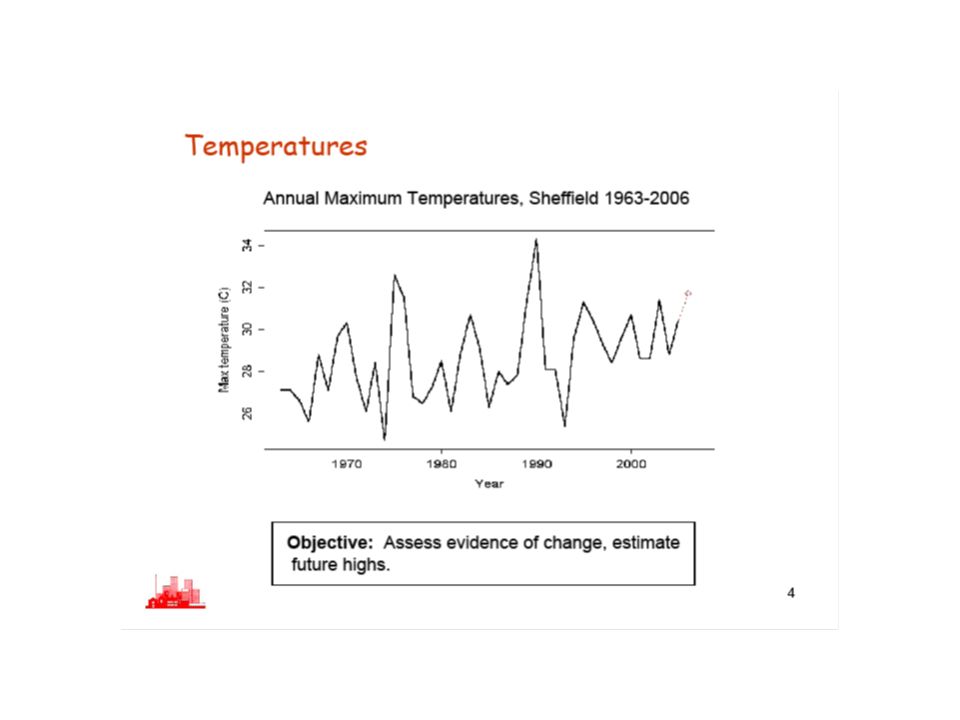
Introduction Modelling extremes, because we need to know about maxima and minima in many environmental systems to ensure that we know How strong to make buildings How high to make sea walls How to plan for floods etc

11
very common application
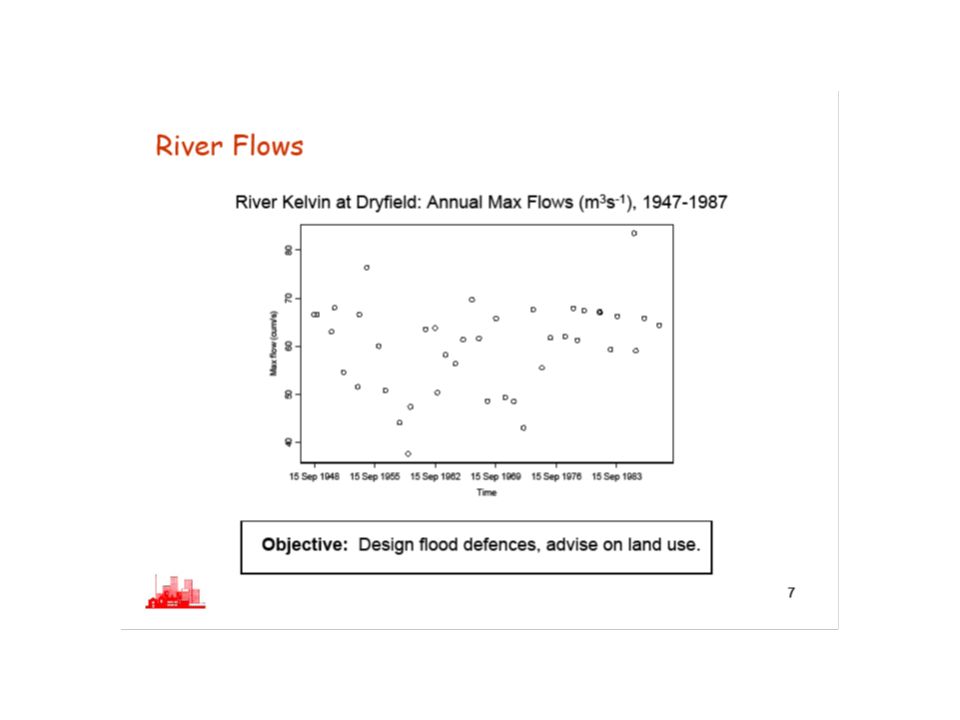
Flood Risk Management Act 2009 approved on 13th May 2009 River flow records studied to assess flood risk

12
Where do we start? Look at river flow records
Influenced by climate change in which way? Interest in studying seasonal pattern Is it constant? Nature of its changes over the years Changes in seasonal pattern might imply changes in extreme events

13
Data – River Nith South West of Scotland Catchment area of 799km2
18993 observations - 51 years (1/10/57 - 1/10/08) unusually long record! Log transformed
 unusually long record! Log transformed.")
14
Data(2)- consider the monthly maxima
- consider the monthly maxima")
15
Background Assume typically that we have a time series of observations (eg maximum daily temperature for the last 20 years) Assume that the data are independent and identically distributed (e.g might a Normal or Exponential be sensible or do we need other types of distributions?) Interest is in predicting unusually high (or low) temperatures Our statistical model needs to be good for the ‘tails’ of the distribution Meet the distribution and cumulative distribution function
 Interest is in predicting unusually high (or low) temperatures. Our statistical model needs to be good for the ‘tails’ of the distribution. Meet the distribution and cumulative distribution function.")
16
Background The usual notation is to assume we have a series of random variables X1,X2,… each with cumulative distribution function G Then G(x) is the probability (X<= x) The inverse cumulative distribution function G-1(zp) is such that zp is the value of X such that Prob(X<=zp) =p
 is the probability (X<= x) The inverse cumulative distribution function G-1(zp) is such that zp is the value of X such that Prob(X<=zp) =p.")
17
the pdf and cdf for X, where X is N(0,1)
")
18
the pdf and cdf for X, where X is exponential

19
Background There exists a class of statistical models developed specifically for dealing with this situation Generalised Extreme value (GEV) distribution, with three parameters and depending on the values of such parameters, can simplify to give Gumbel, Frechet and Weibull distributions for the maximum over particular blocks of time. Special distributions Assumptions relating to the original time series: should be stationary (ie no trend)- see Richard’s section
 distribution, with three parameters and depending on the values of such parameters, can simplify to give Gumbel, Frechet and Weibull distributions for the maximum over particular blocks of time. Special distributions. Assumptions relating to the original time series: should be stationary (ie no trend)- see Richard’s section.")
20
G(z) =exp{-[1+ (z- )/ ]-1/ }
GEV distribution Generalised Extreme value (GEV) distribution, has three parameters, location, scale and shape (usually written as , (>0) and . G(z) is the distribution function G(z) =exp{-[1+ (z- )/ ]-1/ } The Gumbel, Frechet and Weibull are all special cases depending on value of
![G(z) =exp{-[1+ (z- )/ ]-1/ }](http://slideplayer.com/slide/776295/3/images/20/G%28z%29+%3Dexp%7B-%5B1%2B+%EF%81%B8%28z-+%EF%81%AD%29%2F+%EF%81%B3%5D-1%2F+%EF%81%B8%7D.jpg "GEV distribution. Generalised Extreme value (GEV) distribution, has three parameters, location, scale and shape (usually written as , (>0) and . G(z) is the distribution function. G(z) =exp{-[1+ (z- )/ ]-1/ } The Gumbel, Frechet and Weibull are all special cases depending on value of ")
21
Block maxima We can also break our time series X1, X2..into blocks of size n and only deal with the maximum or minimum in the block. E.g if we have a daily series for 50 years, we could calculate the annual maximum and fit one of the statistical models mentioned earlier to the 50 realisations of the maxima. GEV can then be applied to the block maxima etc Quite wasteful of data (throws lots away)
")
22
Model fitting for GEV estimates for the parameters of the distribution given observed ‘annual’ maxima X1,…., Xk various approaches graphical likelihood based for GEV it is possible to write down the likelihood, which is then numerically maximised all this done in specialised software how good is the model?

23
Model diagnostics for GEV
Probability plot Quantile plot Return level plot- will come back to this Density plot Probability and quantile plot should be straight lines.

24
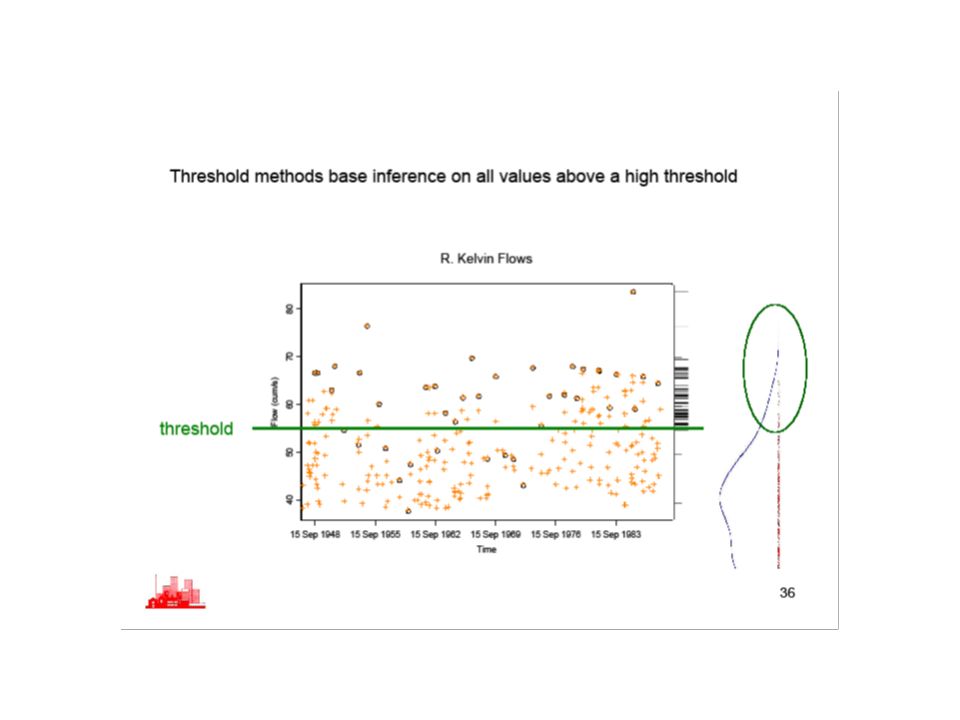
POT modelling There exists another type of statistical model developed specifically for dealing with this situation- known as Peak over threshold- (POT) modelling Again we assume that we have a time series of observations, and define (somehow) a threshold u. Typical distributions used here are Pareto, Beta and Exponential derived from the Generalised Pareto distribution (GPD) How to define the threshold u is the big practical question
 modelling. Again we assume that we have a time series of observations, and define (somehow) a threshold u. Typical distributions used here are Pareto, Beta and Exponential derived from the Generalised Pareto distribution (GPD) How to define the threshold u is the big practical question.")
26
GPD model Asymptotic (so as u-> ) then G(y) = 1-(1+y/)-1/
and are shape and scale parameters =0 gives the exponential distribution with mean = How to define the threshold u is the big practical question one answer is to try different values,

27
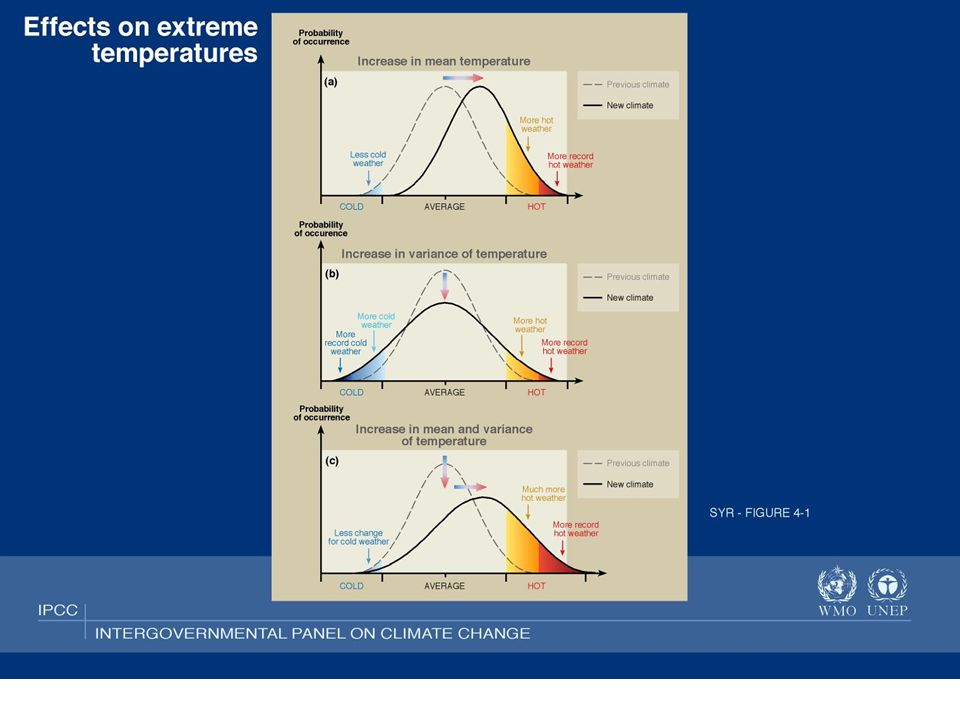
issues Non-stationarity- eg in climate change there are trends in frequency and intensity of extreme weather events There are cycles- annual, diurnal etc these are rather common other. What should be done|? If there is a trend or cyclical component, then we need to de-trend/deseasonalise Perhaps introduce covariates that can explain the non-stationarity

28
Issues for POT modelling
Often threshold exceedances are not independent. Various ways to deal with this Model the dependence declustering Another approach (depending on the application) might be to model the frequency and intensity of threshold excesses Mean number of events in an interval [0, T] is T, where is the frequency of occurrence of an event (so a rate)
 might be to model the frequency and intensity of threshold excesses. Mean number of events in an interval [0, T] is T, where is the frequency of occurrence of an event (so a rate)")
29
How to communicate risk
Return level yp is the value associated with the return period 1/p. That is yp is the level expected to be exceeded on average once every 1/p years. yp =G-1(1-p) p=0.01 corresponds to the 100 year return period The return level and return period are some of the most important quantities to derive from the fitted model (and as such are subject to uncertainty).
 p=0.01 corresponds to the 100 year return period. The return level and return period are some of the most important quantities to derive from the fitted model (and as such are subject to uncertainty).")
30
for the GEV, we can define G(yp)=1-p
=1-p")
31
Definition of return levels for POT
The level xm that is exceeded once every m observations is the solution of u[1+ (x-u)/]-1/ = 1/m where u is Pr(X>u) Choose u such that GPD is a ‘good’ fit
/]-1/ = 1/m. where u is Pr(X>u) Choose u such that GPD is a ‘good’ fit.")
32
Flood Estimation AIM: to estimate the probability of an extreme event occurring in a given time period eg the probability of Glasgow being flooded In hydrology, there is a long history of methods designed to deal with extremes

33
Annual Floods pq = the probability that discharge equals or exceeds q at least once in any given year; pq = annual exceedence probability (1 – pq) = probability that this flood does NOT occur in a given year Assume: stationarity; no long-memory
 = probability that this flood does NOT occur in a given year. Assume: stationarity; no long-memory.")
34
Recurrence Interval Often refer to recurrence interval of floods (eg 1 in 200 year flood) Recurrence interval: the average time between floods equaling or exceeding q Recurrence interval (RIq) is the inverse of the exceedence probability (1/pq)
 is the inverse of the exceedence probability (1/pq)")
35
Extremes in space Temperature network, many stations, at each station, we have a time series of annual maxima (for instance). we need a spatio-temporal model (but this time it is extremes we are modelling) as an exploratory analysis, fit a GEV or GPD to each station, map the parameters
 as an exploratory analysis, fit a GEV or GPD to each station, map the parameters.")
36
Spatial extremes in river flows in Scotland
Exploratory analysis fitting GEV to each site study the spatial pattern in GEV parameters- an alternative to max-stable processes

37
Summary estimating extremes is inherently unreliable, even with large data sets many environmental data sets are short, various distributions may be used for estimation – which ones fit best in a particular situation is difficult to assess but diagnostic tools exist data are assumed to be stationary – changing driving conditions, and long memory processes, may violate this assumption for many environmental data but there are more complex models to deal with trends, seasonality etc

38
software some R packages available –ismev
Good book –Coles S, An introduction to modelling extremes. Lots of very recent work looking at statistical models for extremes over space and time try to work through the extremes.r script file and see handout in folder with some explanation of the results

Similar presentations



>")

 NERC August 2009.>")




 Frequency Analysis and Probability Plotting.>")










 has as objective to quantify the stochastic behavior.>")
