Download presentation
Presentation is loading. Please wait.

1
Karthik Gurumoorthy Ajit Rajwade Arunava Banerjee Anand Rangarajan Department of CISE University of Florida 1

2
A new approach to lossy image compression based on machine learning. Key idea: Learning of Matrix Ortho-normal Bases from training data to efficiently code images. Applied to compression of well-known face databases like ORL, Yale. Competitive with JPEG. 2

3
Vector Conventional learning methods in vision like PCA, ICA, etc. Image 3

4
Our approach following Rangarajan [EMMCVPR-2001] & Ye [JMLR-2004] Treated as a Image Matrix 4
![Our approach following Rangarajan [EMMCVPR-2001] & Ye [JMLR-2004] Treated as a Image Matrix 4](http://images.slideplayer.com/25/7720096/slides/slide_4.jpg "Our approach following Rangarajan [EMMCVPR-2001] & Ye [JMLR-2004] Treated as a Image Matrix 4")
5
Image of size divided into N patches of size each treated as a Matrix. Image 5

6
6 = PUSV U and V: Ortho-normal matrices S: Diagonal Matrix of singular values

7
7 useful for compression (e.g.: SSVD [Ranade et al- IVC 2007]).
![7 useful for compression (e.g.: SSVD [Ranade et al- IVC 2007]).](http://images.slideplayer.com/25/7720096/slides/slide_7.jpg "7 useful for compression (e.g.: SSVD [Ranade et al- IVC 2007]).")
8
8 Consider a set of N image patches: SVD of each patch gives: Costly in terms of storage as we need to store N ortho-normal basis pairs.

9
Produce ortho-normal basis-pairs, common for all N patches. Since storing the basis pairs is not expensive. 9

10
10 Non-diagonal Non-sparse

11
What sparse matrix will optimally reconstruct from ? Optimally = least error: Sparse = matrix has at most some non-zero elements. 11

12
We have a simple, provably optimal greedy method to compute such a 1. Compute the matrix. 2. In matrix, nullify all except the largest elements to produce. 12

13
A set of N image patches. Learning K << N ortho-normal basis pairs 13 Memberships Projection Matrices

14
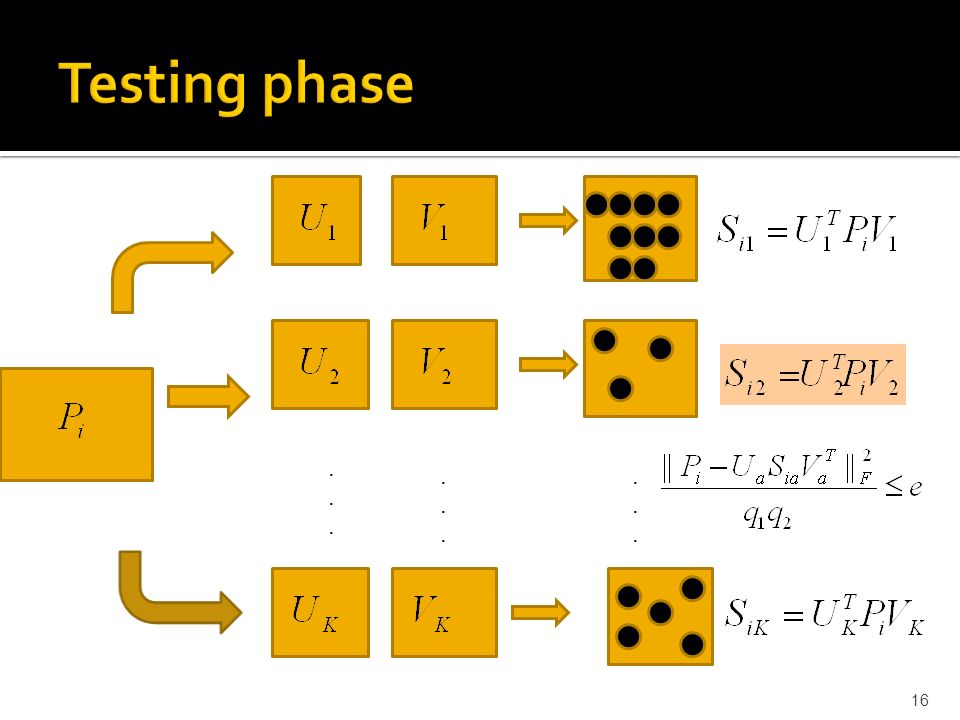
Input: N image patches of size. Output: K pairs of ortho-normal bases called as dictionary. 14

15
Divide each test image into patches of size Fix per-pixel average error (say e), similar to the “quality” user-parameter in JPEG. 15

16
16..................
17
RPP = number of bits per pixel 17

18
18 0.5 bits 0.92 bits1.36 bits 1.78 bits3.023 bits

19
Size of original database is 3.46 MB. Size of dictionary of 50 ortho-normal basis pairs is 56 KB=0.05MB. Size of database after compression and coding with our method with e = 0.0001 is 1.3 MB. Total compression rate achieved is 61%. 19

20
RPP = number of bits per pixel 20

21
New lossy image compression method using machine learning. Key idea 1: matrix based image representation. Key idea2: Learning small set of matrix ortho- normal basis pairs tuned to a database. Results competitive with JPEG standard. Future extensions: video compression. 21

22
A. Rangarajan, Learning matrix space image representations, Energy Minimizing Methods in Computer Vision and Pattern Recognition, 2001. J. Ye, Generalized low rank approximation of matrices, Journal of Machine Learning Research,2004. M. Aharon, M. Elad and A. Bruckstein, The K-SVD: An algorithm for designing of overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing, 2006. A. Ranade, S. Mahabalarao and S. Kale. A variation on SVD based image compression. Image and Vision Computing, 2007. 22

23
23

Similar presentations














 – Section 3.8>")




