Download presentation
Presentation is loading. Please wait.

1
Assignment 2: Papers read for this assignment Paper 1: PALMA: mRNA to Genome Alignments using Large Margin Algorithms Paper 2: Optimal spliced alignments of short sequence reads Badil Elhady, Michael Chan

2
Paper 1: PALMA: mRNA to Genome Alignments using Large Margin Algorithms

3
Motivation Question for the study? –The correct alignment of mRNA sequences to genomic DNA is still a challenging task. ( Due to the presence of sequencing errors, micro-exons, alternative splicing)
.")
4
Method Splice Site Prediction –SVM with large margin, decided under convex optimization Intron Length Model Dynamic Programming is used to maximize the scoring function, leading to Optimal Alignment. (Smith-Waterman Alignments with Intron Model) This leads to: –Tuning the parameters of scoring function leads to. A larger score Other alignment would score lower
 This leads to: –Tuning the parameters of scoring function leads to. A larger score Other alignment would score lower.")
5
–Accurately differentiates the exon-intron boundaries –Compartmentalize the local alignment of EST. –Claim: Robust to mutations, insertions and deletions, as well as noise levels in accurately identifying intron boundaries as well as boundaries of the optimal local alignment. Slice site prediction

6
Splice Site Predictions From a set of ETS, sequences were extracted of confirmed donor and acceptor slice sites. To recognize acceptor and donor slice sites, 2 SVM classifiers were trained. Using “ weighted degree ” kernel. kernel computes the similarity between sequences s and s’.

7
The main idea of the algorithm is to compute a local alignment by determining the maximum over all alignments of all prefixes – S E (1 : i) :=(S E (1),..., S E (i)) –S D (1 : j) := (S D (1),..., S D (j)) »S E EST Sequences »S D DNA Sequences –Running time is O(m*n*L) »m length of S E »n length of S D »Smith-Waterman does not distinguish between exons and introns. Intron Length Model

8
Scoring Function

9
In generalizing the Smith- Waterman algorithm by including an intron model taking splice site predictions as well as intron length into account. The information is then used to optimize the parameters used for alignment. Smith-Waterman Alignments with Intron Model Splice site prediction assisting params

10
Experimental setup Evaluating PALMA vs. exalin, sim4, and blat. Alignment of mRNA seq. artificially shorting the middle exon (3-50)nt as shown.
nt as shown..")
11
Artificially generating the data : as a control to know exactly what the correct alignment has to be. Add varying amounts of noise (p ¼ 0,1,5 and 10% of random mutations, deletions or insertions) to the query sequence. Replace a part of the DNA or mRNA sequence at its terminal ends with random sequence leading to a shortened correct alignment. Experimental setup cont.
 to the query sequence. Replace a part of the DNA or mRNA sequence at its terminal ends with random sequence leading to a shortened correct alignment. Experimental setup cont..")
12
PALMA vs. exalin, sim4, and blat. Add noise

13
PALMA vs. exalin, sim4, and blat. Varying lengths

14
Conclusion –Motivation: high sensitivity detection of short exons in the midst of noise. –Principles Splice Site Prediction Intron Length Model maximize scoring function, for Optimal Alignment. –Results: PALMA detects short exons while exalin, blat, etc, are unsuccessful

15
Further Topics vmatch svm convex optimization

16
Paper 2: Optimal spliced alignments of short sequence reads

17
Situation NGS has short length and inherent high error rate even compared to Sanger. It is fast but the accuracy? Many methods are efficient and accurate if the sequence blocks (exons) are sufficiently long and are highly similar to the genomic sequence. Reads from NG sequencing techniques do not have either of 2 properties.
 are sufficiently long and are highly similar to the genomic sequence. Reads from NG sequencing techniques do not have either of 2 properties..")
18
Motivation Objective to be able to accurately align the sequence reads over intron boundaries. QPALMA takes the read’s quality information as well as computational splice site predictions to compute accurate spliced alignments.

19
Principles Learn, in a supervised manner, how to score quality information, splice site predictions and sequence identity based on a representative set of sequence reads with known alignments. Extended Smith-Waterman algorithm: Extension 1 : Quality Scores Extension 2 : Splice Sites Extension 3 : Non-affine Intron Length Model

20
1)Splice site prediction Need to know acceptor and donor splice sites as well as suitable decoy sequences. Extension 1 : Quality Scores Extension 2 : Splice Sites Extension 3 : Non-affine Intron Length Model

21
Extension 1 : Quality Scores same computational complexity as the original Smith–Waterman algorithm ( O (mn)). However, it uses a more complex scoring that may depend on the sequencing technology used. Constant

22
Extension 2 : Splice Sites ( O (mnL)) operations, where L is the maximal length of the intron. The idea is to maintain an additional recurrence matrix W used to keep track of the intron boundaries.

23
Extension 2 : Splice Sites, cont g o and g e are the intron opening and extension scores The g don (i) and g acc (i) gacc(i) are scoring functions for splice sites at position i in the sequence ˆ f acc (i) := f acc ( g acc (i) ) and ˆ f don (i) := f don ( g don (i) ).
 and g acc (i) gacc(i) are scoring functions for splice sites at position i in the sequence ˆ f acc (i) := f acc ( g acc (i) ) and ˆ f don (i) := f don ( g don (i) ).")
24
Extension 3 : Non-affine Intron Length Model Here is scoring the intron length with an arbitrary function

25
Recurrence can be implemented as follows Extension 3 : Non-affine Intron Length Model For long introns this approach seem computationally infeasible.

28
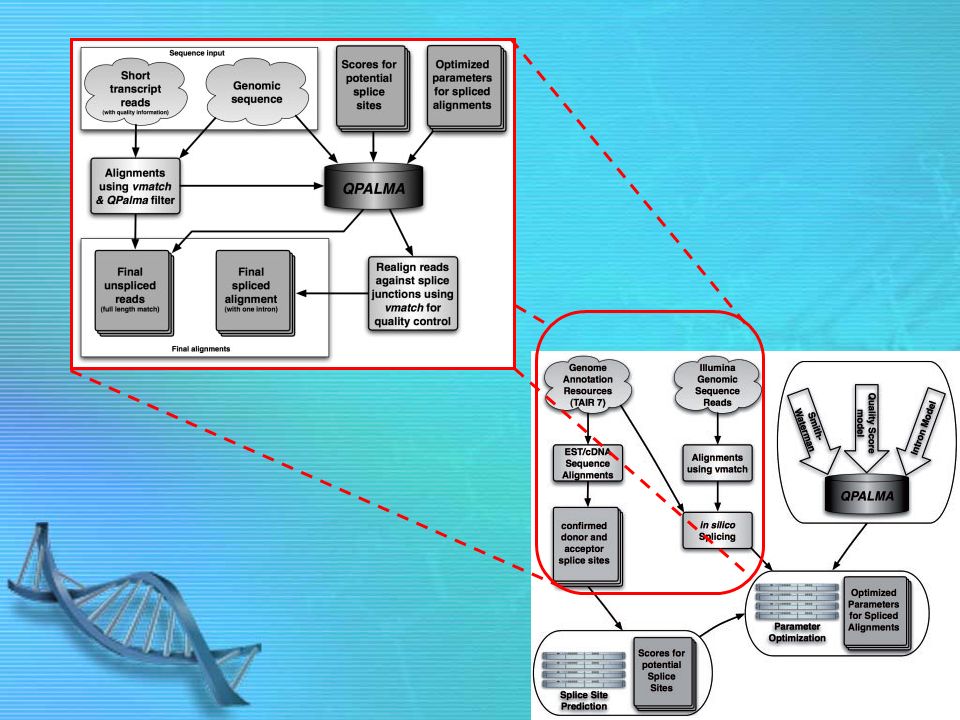
An alignment pipeline against whole genomes !!! optimal alignments is time consuming => use vmatch(multi-step approach on enhanced suffix arrays) + high quality splice site detection
 + high quality splice site detection.")
29
vmatch (1 st round) finds global alignments of all short reads (max 2 mismatches) against the genome to identify large fraction of unspliced reads. –If there are reads that cannot be aligned (leftover reads) – spliced or low quality reads Yet, there is possibility that the boundary of the reads are the spliced sites –Check with QPALMA scoring function as a filter to quickly decide whether the read is spliced or not. – all combinations of putative donor splice sites within the read and acceptor splice sites ≤2000 nt downstream of the read, and – all combinations of putative acceptor splice sites within the read and donor splice sites ≤2000 nt upstream of the read. [Optional] An alignment pipeline against whole genomes
 – spliced or low quality reads Yet, there is possibility that the boundary of the reads are the spliced sites –Check with QPALMA scoring function as a filter to quickly decide whether the read is spliced or not. – all combinations of putative donor splice sites within the read and acceptor splice sites ≤2000 nt downstream of the read, and – all combinations of putative acceptor splice sites within the read and donor splice sites ≤2000 nt upstream of the read. [Optional] An alignment pipeline against whole genomes.")
30
leftover reads + spliced (predicted to be by QPALMA) used as seeds for vmatch (2 nd round) and localize the splice sites with a ‘window’
 used as seeds for vmatch (2 nd round) and localize the splice sites with a ‘window’")
31
Results

32
Conclusion –Motivation: NGS is inaccurate. –Principles 3 extentions to PALMA Vmatch pipelining, for boundary precision. –Results: lower error QPALMA + vmatch pipelining = PALMA + 3extentions – {SVM, large marigin}

33
References A Tutorial on Support Vector Machines for Pattern Recognition NCBI National Center for Biotechnology Information http://www.ncbi.nlm.nih.gov/About/primer/genetics_ genome.htmlNCBI http://www.ncbi.nlm.nih.gov/About/primer/genetics_ genome.html BioInfoBank Library http://lib.bioinfo.pl/BioInfoBank Libraryhttp://lib.bioinfo.pl/ High Throughput Short Read Alignment via Bi- directional BWT

34
Mich_a___el__chan Badil_el ha dy

Similar presentations













 Weijia Wang, Huanren Zhang, Vijendra Purohit, Aditi Gupta.>")







