Download presentation
Presentation is loading. Please wait.

1
CSC 2535: Computation in Neural Networks Lecture 10 Learning Deterministic Energy-Based Models Geoffrey Hinton

2
A different kind of hidden structure Data is often characterized by saying which directions have high variance. But we can also capture structure by finding constraints that are Frequently Approximately Satisfied. If the constrints are linear they represent directions of low variance. Violations of FAS constraints reduce the probability of a data vector. If a constraint already has a big violation, violating it more does not make the data vector much worse (i.e. assume the distribution of violations is heavy-tailed.)
.")
3
Frequently Approximately Satisfied constraints The intensities in a typical image satisfy many different linear constraints very accurately, and violate a few constraints by a lot. The constraint violations fit a heavy-tailed distribution. The negative log probabilities of constraint violations can be used as energies. Violation 0 Gauss Cauchy energyenergy -+ On a smooth intensity patch the sides balance the middle -

4
Energy-Based Models with deterministic hidden units Use multiple layers of deterministic hidden units with non-linear activation functions. Hidden activities contribute additively to the global energy, E. Familiar features help, violated constraints hurt. data j k EkEk EjEj

5
Reminder: Maximum likelihood learning is hard To get high log probability for d we need low energy for d and high energy for its main rivals, c To sample from the model use Markov Chain Monte Carlo. But what kind of chain can we use when the hidden units are deterministic and the visible units are real-valued.

6
Hybrid Monte Carlo We could find good rivals by repeatedly making a random perturbation to the data and accepting the perturbation with a probability that depends on the energy change. –Diffuses very slowly over flat regions –Cannot cross energy barriers easily In high-dimensional spaces, it is much better to use the gradient to choose good directions. HMC adds a random momentum and then simulates a particle moving on an energy surface. –Beats diffusion. Scales well. –Can cross energy barriers. –Back-propagation can give us the gradient of the energy surface.

7
Trajectories with different initial momenta

8
Backpropagation can compute the gradient that Hybrid Monte Carlo needs 1.Do a forward pass computing hidden activities. 2.Do a backward pass all the way to the data to compute the derivative of the global energy w.r.t each component of the data vector. works with any smooth non-linearity data j k EkEk EjEj

9
1.Start at a datavector, d, and use backprop to compute for every parameter 2.Run HMC for many steps with frequent renewal of the momentum to get equilibrium sample, c. Each step involves a forward and backward pass to get the gradient of the energy in dataspace. 3.Use backprop to compute 4.Update the parameters by : The online HMC learning procedure

10
The shortcut Instead of taking the negative samples from the equilibrium distribution, use slight corruptions of the datavectors. Only add random momentum once, and only follow the dynamics for a few steps. –Much less variance because a datavector and its confabulation form a matched pair. –Gives a very biased estimate of the gradient of the log likelihood. –Gives a good estimate of the gradient of the contrastive divergence (i.e. the amount by which F falls during the brief HMC.) Its very hard to say anything about what this method does to the log likelihood because it only looks at rivals in the vicinity of the data. Its hard to say exactly what this method does to the contrastive divergence because the Markov chain defines what we mean by “vicinity”, and the chain keeps changing as the parameters change. –But its works well empirically, and it can be proved to work well in some very simple cases.
 Its very hard to say anything about what this method does to the log likelihood because it only looks at rivals in the vicinity of the data. Its hard to say exactly what this method does to the contrastive divergence because the Markov chain defines what we mean by vicinity , and the chain keeps changing as the parameters change. –But its works well empirically, and it can be proved to work well in some very simple cases..")
11
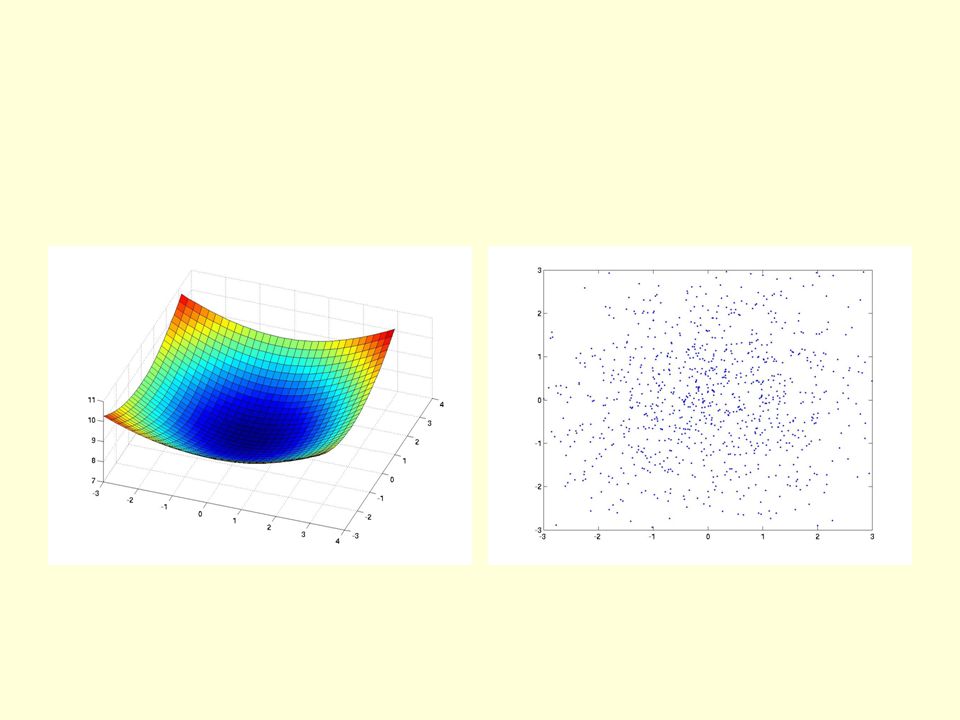
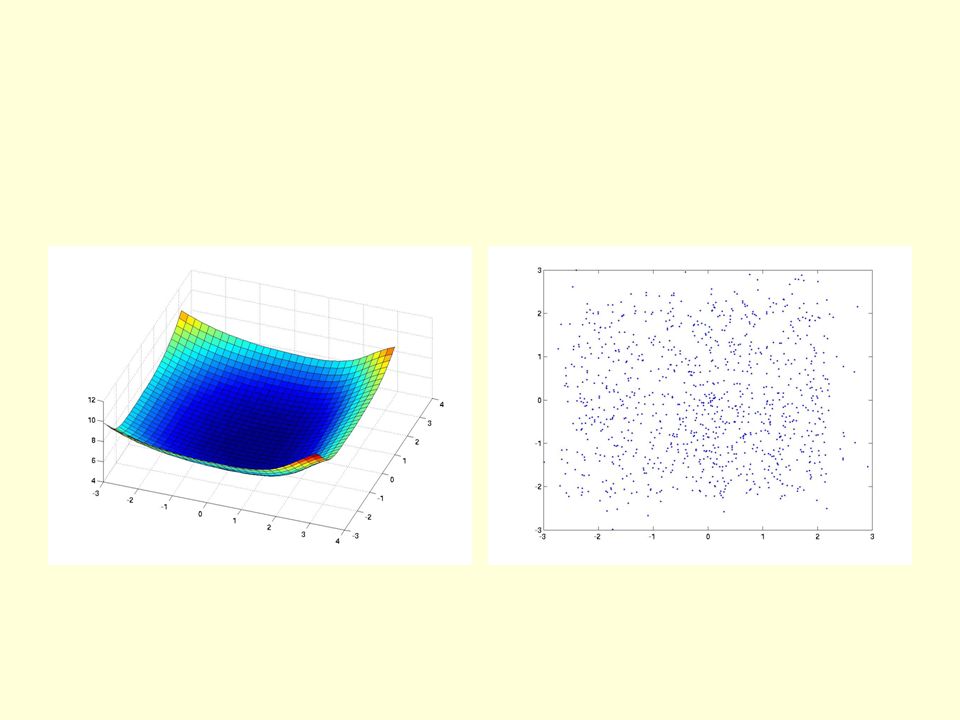
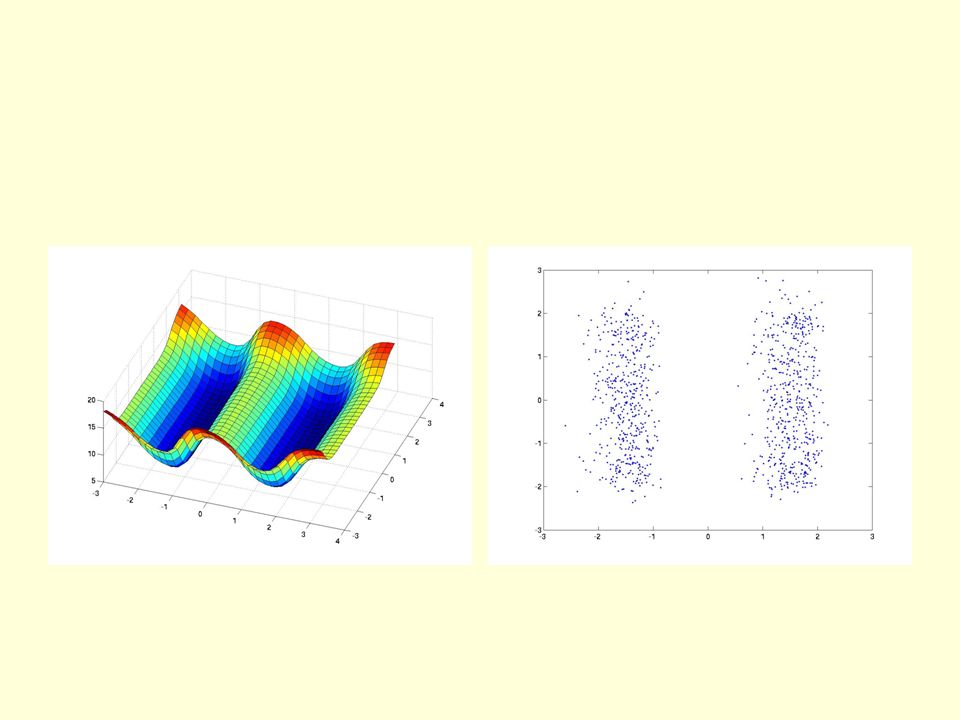
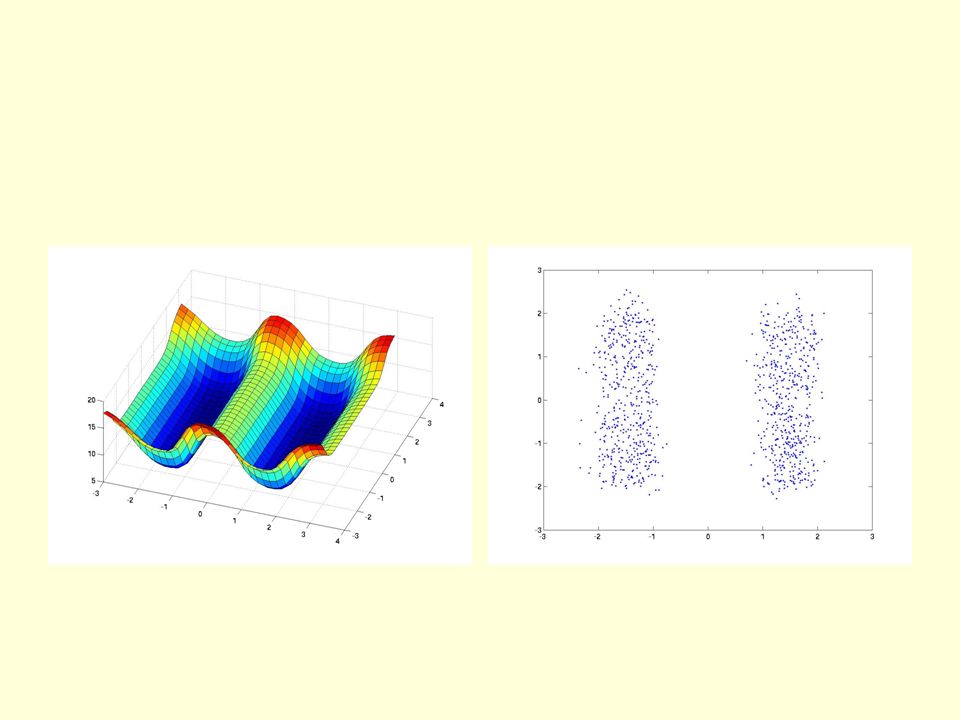
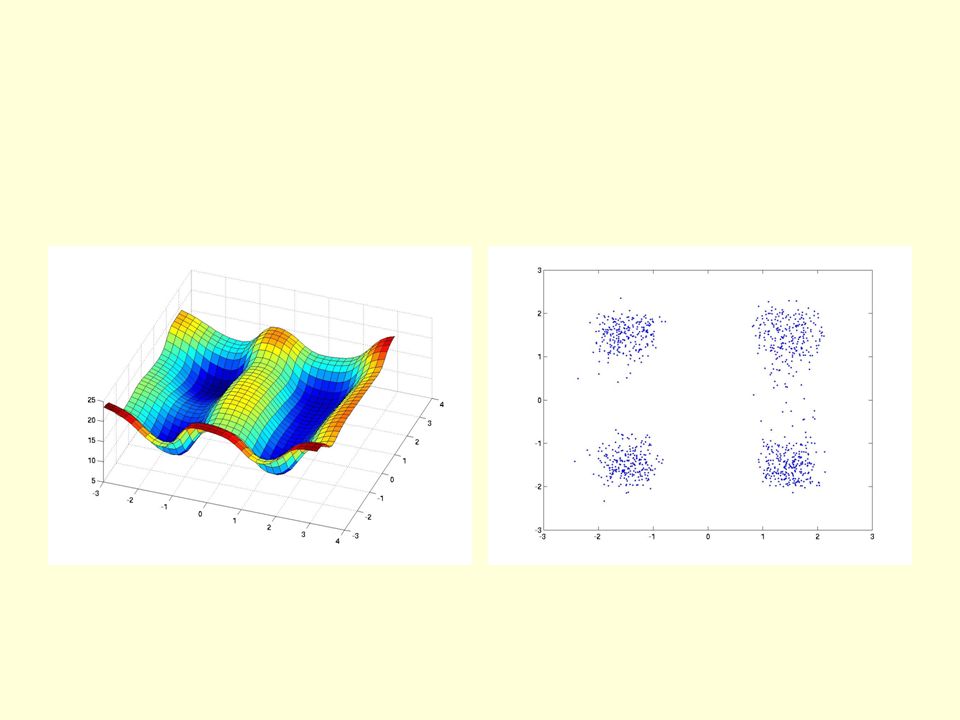
A simple 2-D dataset The true data is uniformly distributed within the 4 squares. The blue dots are samples from the model.

12
The network for the 4 squares task Each hidden unit contributes an energy equal to its activity times a learned scale. 2 input units 20 logistic units 3 logistic units E

25
Frequently Approximately Satisfied constraints Violation 0 Gauss Cauchy energyenergy The energy contributed by a violation is the negative log probability of the violation what is the best line? Gauss Cauchy

26
Learning the constraints on an arm 3-D arm with 4 links and 5 joints linear squared outputs Energy for non- zero outputs For each link: + _

27
4.19 4.66 -7.12 13.94 -5.03 -4.24 -4.61 7.27 -13.97 5.01 Biases of top-level units Mean total input from layer below Coordinates of joint 5 Coordinates of joint 4 Negative weight Positive weight Weights of a top-level unit Weights of a hidden unit

28
Superimposing constraints A unit in the second layer could represent a single constraint. But it can model the data just as well by representing a linear combination of constraints.

29
Dealing with missing inputs The network learns the constraints even if 10% of the inputs are missing. –First fill in the missing inputs randomly –Then use the back-propagated energy derivatives to slowly change the filled-in values until they fit in with the learned constraints. Why don’t the corrupted inputs interfere with the learning of the constraints? –The energy function has a small slope when the constraint is violated by a lot. –So when a constraint is violated by a lot it does not adapt. Don’t learn when things don’t make sense.

30
Learning constraints from natural images (Yee-Whye Teh) We used 16x16 image patches and a single layer of 768 hidden units (3 x over-complete). Confabulations are produced from data by adding random momentum once and simulating dynamics for 30 steps. Weights are updated every 100 examples. A small amount of weight decay helps.

31
A random subset of 768 basis functions

32
The distribution of all 768 learned basis functions

33
How to learn a topographic map image Linear filters Global connectivity Local connectivity The outputs of the linear filters are squared and locally pooled. This makes it cheaper to put filters that are violated at the same time next to each other. Cost of first violation Cost of second violation Pooled squared filters

35
Faster mixing chains Hybrid Monte Carlo can only take small steps because the energy surface is curved. With a single layer of hidden units, it is possible to use alternating parallel Gibbs sampling. –Step 1: each student-t hidden unit picks a variance from the posterior distribution over variances given the violation produced by the current datavector. If the violation is big, it picks a big variance This is equivalent to picking a Gaussian from an infinite mixture of Gaussians (because that’s what a student-t is). –With the variances fixed, each hidden unit defines a one-dimensional Gaussians in the dataspace. –Step 2: pick a visible vector from the product of all the one-dimensional Gaussians.
. –With the variances fixed, each hidden unit defines a one-dimensional Gaussians in the dataspace. –Step 2: pick a visible vector from the product of all the one-dimensional Gaussians..")
36
Pro’s and Con’s of Gibbs sampling Advantages of Gibbs sampling –Much faster mixing –Can be extended to use pooled second layer (Max Welling) Disadvantages of Gibbs sampling –Can only be used in deep networks by learning hidden layers (or pairs of layers) greedily. –But maybe this is OK. Its scales better than contrastive backpropagation.

38
Density models Causal models Energy-Based Models Tractable posterior mixture models, sparse bayes nets factor analysis Compute exact posterior Intractable posterior Densely connected DAG’s Markov Chain Monte Carlo or Minimize variational free energy Stochastic hidden units Full Boltzmann Machine Full MCMC Restricted Boltzmann Machine Minimize contrastive divergence Deterministic hidden units Markov Chain Monte Carlo Fix the features (“maxent”) Minimize contrastive divergence or
 Minimize contrastive divergence or")
39
Three ways to understand Independent Components Analysis Suppose we have 3 independent sound sources and 3 microphones. Assume each microphone senses a different linear combination of the three sources. Can we figure out the coefficients in each linear combination in an unsupervised way? –Not if the sources are i.i.d. and Gaussian. –Its easy if the sources are non- Gaussian, even if they are i.i.d. independent sources linear combinations

40
Using a non-Gaussian prior If the prior distributions on the factors are not Gaussian, some orientations will be better than others –It is better to generate the data from factor values that have high probability under the prior. – one big value and one small value is more likely than two medium values that have the same sum of squares. If the prior for each hidden activity is the iso-probability contours are straight lines at 45 degrees.

41
Empirical data on image filter responses (from David Mumford) Negative log probability distributions of filter outputs, when filters are applied to natural image data. a) Top plot is for values of horizontal first difference of pixel values; middle plot is for random 0-mean 8x8 filters. b) Bottom plot shows level curves of Joint prob.density of vert.differences at two horizontally adjacent pixels. All are highly non-Gaussian: Gaussian would give parabolas with elliptical level curves.
 Top plot is for values of horizontal first difference of pixel values; middle plot is for random 0-mean 8x8 filters. b) Bottom plot shows level curves of Joint prob.density of vert.differences at two horizontally adjacent pixels. All are highly non-Gaussian: Gaussian would give parabolas with elliptical level curves..")
42
The energy-based view of ICA Each data-vector gets an energy that is the sum of three contributions. The energy function can be viewed as the negative log probability of the output of a linear filter under a heavy-tailed model. We just maximize the log prob of the data given by additive contributions to global energy data-vector

43
Stochastic Causal Generative models The posterior distribution is intractable. Deterministic Energy-Based Models Partition function I is intractable ICA Two views of Independent Components Analysis Z becomes determinant Posterior collapses When the number of linear hidden units equals the dimensionality of the data, the model has both marginal and conditional independence.

44
Independence relationships of hidden variables in three types of model that have one hidden layer Causal Product Square model of experts ICA Hidden states unconditional on data Hidden states conditional on data independent (generation is easy) independent (inference is easy) dependent (rejecting away) dependent (explaining away) independent (by definition) independent (the posterior collapses to a single point) We can use an almost complementary prior to reduce this dependency so that variational inference works
 independent (inference is easy) dependent (rejecting away) dependent (explaining away) independent (by definition) independent (the posterior collapses to a single point) We can use an almost complementary prior to reduce this dependency so that variational inference works")
45
Over-complete ICA using a causal model What if we have more independent sources than data components? (independent \= orthogonal) –The data no longer specifies a unique vector of source activities. It specifies a distribution. This also happens if we have sensor noise in square case. –The posterior over sources is non-Gaussian because the prior is non-Gaussian. So we need to approximate the posterior: –MCMC samples –MAP (plus Gaussian around MAP?) –Variational
 –The data no longer specifies a unique vector of source activities. It specifies a distribution. This also happens if we have sensor noise in square case. –The posterior over sources is non-Gaussian because the prior is non-Gaussian. So we need to approximate the posterior: –MCMC samples –MAP (plus Gaussian around MAP ) –Variational.")
46
Over-complete ICA using an energy-based model Causal over-complete models preserve the unconditional independence of the sources and abandon the conditional independence. Energy-based overcomplete models preserve the conditional independence (which makes perception fast) and abandon the unconditional independence. –Over-complete EBM’s are easy if we use contrastive divergence to deal with the intractable partition function.
 and abandon the unconditional independence. –Over-complete EBM’s are easy if we use contrastive divergence to deal with the intractable partition function..")
Similar presentations












>")















