Download presentation
Presentation is loading. Please wait.

1
Combining Lexical Semantic Resources with Question & Answer Archives for Translation-Based Answer Finding Delphine Bernhard and Iryna Gurevvch Ubiquitous Knowledge Processing (UKP) Lab Computer Science Department Technische Universit¨at Darmstadt, Hochschulstraße 10 D-64289 Darmstadt, Germany ACL 2009 Reporter: Kan-Wen Tien Date: 2009.10.22
 Lab Computer Science Department Technische Universit¨at Darmstadt, Hochschulstraße 10 D Darmstadt, Germany ACL 2009 Reporter: Kan-Wen Tien Date:")
2
Outlines Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

3
Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

4
Introduction Lexical gap between queries and documents or questions and answers Several solutions : – Query reformulation, query paraphrasing – Query expansion – Semantic information retrieval

5
Introduction Several solutions : – Integrate monolingual statistical translation models in the retrieval process (1999) Drawback: limited availability of truly parallel monolingual corpora Training data often consist in question-answer pairs and usually extracted from the evaluation corpus itself
 Drawback: limited availability of truly parallel monolingual corpora Training data often consist in question-answer pairs and usually extracted from the evaluation corpus itself")
6
Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

7
Related Work Statistical translation models for retrieval Built synthetic training data Train translation models on Q&A pairs – Answers -> source language – Questions -> target language Select the most important terms to build compact translation models

8
Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

9
Parallel Datasets Different data resources: (1)Manually-tagged question reformulations and question-answer pairs from the WikiAnswers social Q&A site (2) Glosses from WordNet, Wiktionary, Wikipedia and Simple Wikipedia
Manually-tagged question reformulations and question-answer pairs from the WikiAnswers social Q&A site (2) Glosses from WordNet, Wiktionary, Wikipedia and Simple Wikipedia")
11
Parallel Datasets (1) Manually-tagged question reformulations and question-answer pairs From social Q&A sites: WikiAnswers (WA) – Question-Answer Pairs (WAQA) – Question Reformulations (WAQ) [URL]
![Parallel Datasets (1) Manually-tagged question reformulations and question-answer pairs From social Q&A sites: WikiAnswers (WA) – Question-Answer Pairs (WAQA) – Question Reformulations (WAQ) [URL]](http://images.slideplayer.com/24/7340073/slides/slide_11.jpg "Parallel Datasets (1) Manually-tagged question reformulations and question-answer pairs From social Q&A sites: WikiAnswers (WA) – Question-Answer Pairs (WAQA) – Question Reformulations (WAQ) [URL]")
12
Parallel Datasets (2) Glosses from WordNet, Wiktionary, Wikipedia and Simple Wikipedia Lexical Semantic Resources (LSR) – Word sense alignment Example !
 Glosses from WordNet, Wiktionary, Wikipedia and Simple Wikipedia Lexical Semantic Resources (LSR) – Word sense alignment Example !")
13
Parallel Datasets Example: “moon” – Wordnet (sense 1): The natural satellite of the Earth. – English Wiktionary: The Moon, the satellite of planet Earth. – English Wikipedia: The Moon (Latin: Luna) is Earth’s only natural satellite and the fifth largest natural satellite in the Solar System.
 is Earth’s only natural satellite and the fifth largest natural satellite in the Solar System..")
14
Parallel Datasets Three datasets: Question-Answer Pairs (WAQA) 1,227,362 parallel pairs Question Reformulations (WAQ) 4,379,620 parallel pairs Lexical Semantic Resources (LSR) 397,136 pairs
 1,227,362 parallel pairs Question Reformulations (WAQ) 4,379,620 parallel pairs Lexical Semantic Resources (LSR) 397,136 pairs")
15
Parallel Datasets Translation Model Training – Pre-processing steps – GIZA++ SMT Toolkit -> word-to-word translation probabilities – IBM translation model 1

16
Parallel Datasets Combination of the datasets – Lin (combination of models after training) – Pool (concatenating the corpora before training)
 – Pool (concatenating the corpora before training)")
17
Parallel Datasets

20
Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

21
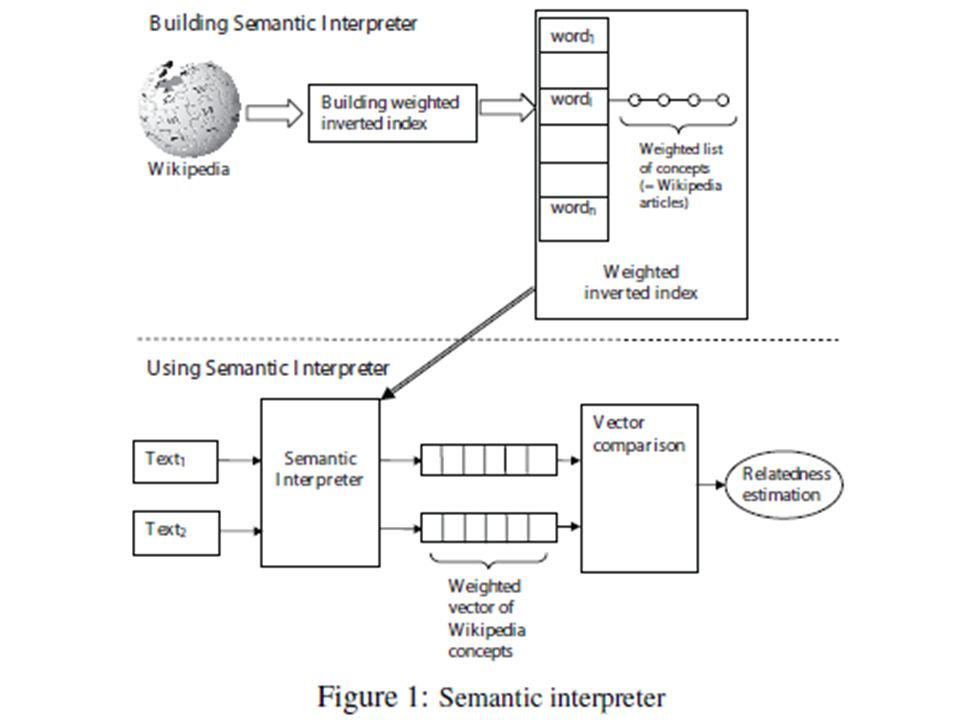
Semantic Relatedness Experiments Goal: Word translation probabilities vs. Concept vector based measure Concept vector based measure relying on Explicit Semantic Analysis (Gabrilovich and Markovitch, 2007) Compare with traditional semantic relatedness measures
 Compare with traditional semantic relatedness measures.")
23
Semantic Relatedness Experiments

24
Testing data set: 353 word-to-word pairs – Created by Finkelstein et al. (2002) – Fin1-153: 153 pairs – Fin2-200: 200 pairs
 – Fin1-153: 153 pairs – Fin2-200: 200 pairs.")
25
Semantic Relatedness Experiments Testing data set: 353 word-to-word pairs – Created by Finkelstein et al. (2002) – Fin1-153: 153 pairs – Fin2-200: 200 pairs
 – Fin1-153: 153 pairs – Fin2-200: 200 pairs.")
26
Semantic Relatedness Experiments Use Spearman’s Rank Correlation Coefficients (-1, 0, +1) [URL]
![Semantic Relatedness Experiments Use Spearman’s Rank Correlation Coefficients (-1, 0, +1) [URL]](http://images.slideplayer.com/24/7340073/slides/slide_26.jpg "Semantic Relatedness Experiments Use Spearman’s Rank Correlation Coefficients (-1, 0, +1) [URL]")
27
Semantic Relatedness Experiments Use Spearman’s Rank Correlation Coefficients (-1, 0, +1) [URL]
![Semantic Relatedness Experiments Use Spearman’s Rank Correlation Coefficients (-1, 0, +1) [URL]](http://images.slideplayer.com/24/7340073/slides/slide_27.jpg "Semantic Relatedness Experiments Use Spearman’s Rank Correlation Coefficients (-1, 0, +1) [URL]")
28
Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

29
Answer Finding Experiments Goal: provide an extrinsic evaluation of the translation probabilities by employing them in an answer finding task. Using a ranking function to perform retrieval

30
Answer Finding Experiments Ranking function (β = 0.8, λ = 0.5)
")
31
Answer Finding Experiments Ranking function (β = 0.8, λ = 0.5)
")
32
Answer Finding Experiments Ranking function (β = 0.8, λ = 0.5) Query likelihood model Translation model
 Query likelihood model Translation model")
33
Answer Finding Experiments Testing data: Microsoft Research QA Corpus 1,364 questions, 9,780 answers 5 levels of relevance judgements: 0: No Judgement Made 1: Extract Answers 3: Off Topic 4: On Topic, Off Target 5: Partial Answer

34
Answer Finding Experiments Testing data: Microsoft Research QA Corpus 1,364 questions, 9,780 answers 5 levels of relevance judgements: 0: No Judgement Made 1: Extract Answers 3: Off Topic 4: On Topic, Off Target 5: Partial Answer

35
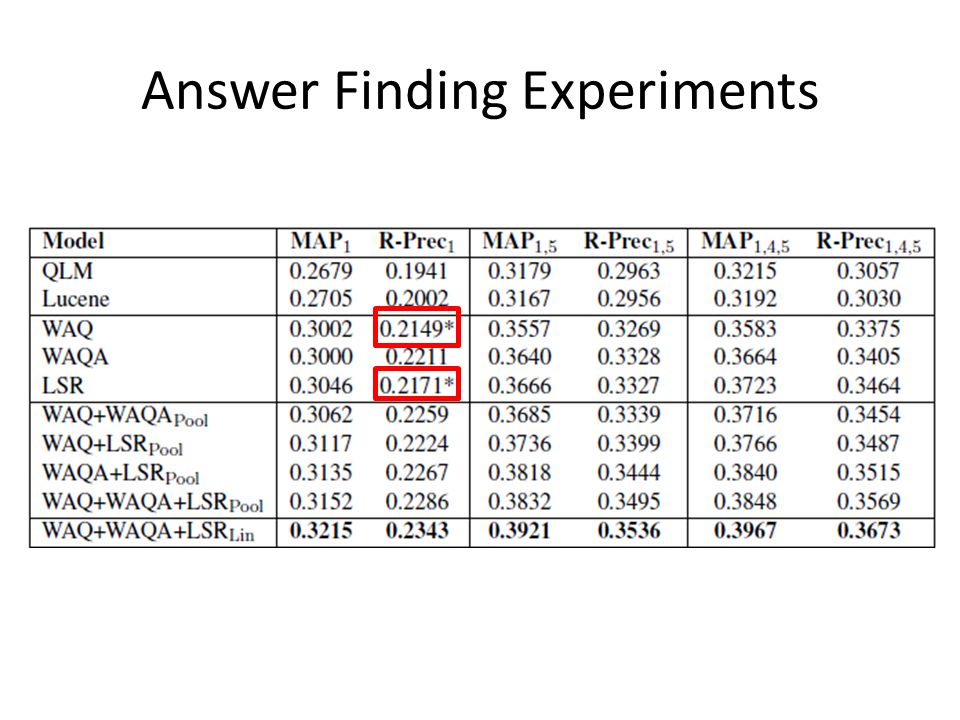
Answer Finding Experiments

36
Mean Average Precision (MAP) Mean R-Precision (R-prec) Baselines: – Query likelihood model (QLM) ---> β = 0 – Lucene Query likelihood model Translation model
 Mean R-Precision (R-prec) Baselines: – Query likelihood model (QLM) ---> β = 0 – Lucene Query likelihood model Translation model")
37
Answer Finding Experiments

45
Introduction Related Work Parallel Datasets Semantic Relatedness Experiments Answer Finding Experiments Conclusion

46
Propose new kinds of datasets for training Provide the first intrinsic evaluation of word translation probabilities with respect to human relatedness rankings for reference word pairs Models based on translation probabilities for answer finding

47
Thank you !

Similar presentations











 José Manuel Perea Ortega CLEF 2008, 18 September, Aarhus (Denmark) Computer.>")


 Learning for Semantic Parsing Advisor: Hsin-His.>")










 Bridging Languages for Question Answering: DIOGENE at CLEF-2003.>")


