Download presentation
Presentation is loading. Please wait.

1
G.Tecuci, Learning Agents Laboratory Learning Agents Laboratory Department of Computer Science George Mason University Gheorghe Tecuci tecuci@cs.gmu.edu http://lalab.gmu.edu/ CS 785, Fall 2001

2
G.Tecuci, Learning Agents Laboratory Overview Evaluation of Disciple Workaround Agent training experiment with Disciple CoG Recommended reading The research goal Evaluation of Disciple COA Knowledge acquisition experiment with Disciple COA

3
G.Tecuci, Learning Agents Laboratory What is the research problem Elaborate a theory, methodology and system for the development of knowledge bases and agents by subject matter experts, with limited assistance from knowledge engineers. Instructable Agent Knowledge Base

4
G.Tecuci, Learning Agents Laboratory This research aims at changing the way future knowledge-based agents will be built, from being programmed by computer scientists and knowledge engineers, to being taught by subject matter experts and typical computer users. Long term research vision Develop a capability that will allow subject matter experts and typical computer users to build and maintain knowledge bases and agents, as easily as they use personal computers for text processing.

5
G.Tecuci, Learning Agents Laboratory Evolution of the software development process Mainframe Computers Software systems developed and used by computer experts Personal Computers Software systems developed by computer experts and used by persons that are not computer experts Learning Agents Software systems developed and used by persons that are not computer experts

6
G.Tecuci, Learning Agents Laboratory High Performance Knowledge Bases Program 97-99 (DARPA, AFOSR) Disciple-Workaround (planning to overcome damage to bridges and roads) Demonstrated that a knowledge engineer can rapidly build a Disciple knowledge base capturing knowledge from military engineering manuals and expert solutions. Disciple-COA (critiquing military courses of action) Demonstrated that a knowledge engineer and a subject matter expert can jointly teach Disciple (using multistrategy rule learning and refinement). Rapid Knowledge Formation Program 00-03 (DARPA, AFOSR, US Army) Disciple-RKF/CoG (identifying center of gravity candidates in theaters of war scenarios) Demonstrated that a subject matter expert can perform more knowledge base development tasks, with limited assistance from a knowledge engineer (scenario elicitation, domain modeling, rule learning, and rule refinement). Recent steps toward agent development by typical users
 Demonstrated that a knowledge engineer and a subject matter expert can jointly teach Disciple (using multistrategy rule learning and refinement). Rapid Knowledge Formation Program (DARPA, AFOSR, US Army) Disciple-RKF/CoG (identifying center of gravity candidates in theaters of war scenarios) Demonstrated that a subject matter expert can perform more knowledge base development tasks, with limited assistance from a knowledge engineer (scenario elicitation, domain modeling, rule learning, and rule refinement). Recent steps toward agent development by typical users.")
7
G.Tecuci, Learning Agents Laboratory Overview Evaluation of Disciple Workaround Agent training experiment with Disciple CoG Recommended reading The research goal Evaluation of Disciple COA Knowledge acquisition experiment with Disciple COA

8
G.Tecuci, Learning Agents Laboratory Estimate the best way of working around damage to a transportation infrastructure, such as a damaged bridge or road. Input problem: Sample solution: description of a military unit (e.g. UNIT201) that needs to work around some damage; description of the damage and of the terrain; description of the resources in the area that could be used to repair the damage. detailed plan of actions (e.g. detail plan for installing AVLB); minimum duration = 15h:6m:15s) expected duration = 18h:47m:55s) resources = BULLDOZER-UNIT201 and AVLB-UNIT204 link capacity after reconstruction: 135.13 vehicles/hr Disciple Workaround (1997-1998)
 that needs to work around some damage; description of the damage and of the terrain; description of the resources in the area that could be used to repair the damage. detailed plan of actions (e.g. detail plan for installing AVLB); minimum duration = 15h:6m:15s) expected duration = 18h:47m:55s) resources = BULLDOZER-UNIT201 and AVLB-UNIT204 link capacity after reconstruction: vehicles/hr Disciple Workaround ( ).")
9
G.Tecuci, Learning Agents Laboratory The High Performance Knowledge Bases Program Rapid development of the workaround agent Experiment Design June 17:receive 20 problems to be solved and returned within 24 hours; June 18: receive solutions provided by the expert; June 18-June 24:improve the workaround agent and return new solutions to the same 20 problems; June 25:receive 5 new problems outside the scope of the initial specification; return whatever solutions can be generated within 24 hours; June 26-June 30:develop the agent to solve the new problems and return a new set of solutions; July 1:test the developed agent with additional 5 problems.

10
G.Tecuci, Learning Agents Laboratory HPKB First Year Evaluation: GMU Results Extension of the scope of the GMU system during the evaluation several resources ribbon bridges ribbon rafts mines craters* TMM slope reduction fording fixed bridges * Included craters during the day of the evaluation

11
G.Tecuci, Learning Agents Laboratory Evaluation Measures

12
G.Tecuci, Learning Agents Laboratory Interesting solutions found by the GMU system June 25 (initial modification phase) Problem 3: Found solutions involving the emplacement of fixed bridges over craters by simply applying the rules for emplacing such bridges over the river gaps. These kinds of solutions were accepted by the experts and were added to the model solutions. Problem 5: Found solutions involving various combinations of using filling for some craters and emplacing fixed bridges over the others. These kinds of solutions were accepted by the experts and were added to the model solutions.

13
G.Tecuci, Learning Agents Laboratory Interesting solutions found by the GMU system June 30 (retest of the modification phase) Problem 2: Realized that the ribbon raft solutions involve slope reduction to reduce the height above the water from 2m to 1.5 m. The expert’s solution did not specify these operations.

14
G.Tecuci, Learning Agents Laboratory Interesting solutions found by the GMU system July 1 (final modification phase) Problems 5 and 10: Found solutions involving the parallel filling of several craters. Problem 7: Found a ribbon raft solution that involves opening the first centerline after 14h:21min and the second one after 24h:25min. Also, it acquired a bulldozer through operational control from division rather than waiting an additional two hours to get the bulldozer of the ribbon bridge company.

15
G.Tecuci, Learning Agents Laboratory Evolution of the KB during Evaluation: Ontology

16
G.Tecuci, Learning Agents Laboratory Evolution of the KB during Evaluation: Tasks

17
G.Tecuci, Learning Agents Laboratory Evolution of the KB during Evaluation: Rules

18
G.Tecuci, Learning Agents Laboratory Knowledge Base Rules Ontology Tasks Evolution of the KB during Evaluation

19
G.Tecuci, Learning Agents Laboratory Days KB Size - Predicates Test Sets % Correct KA approach: SME teaches an agent how to solve problems through examples and explanations, in a way that resembles the teaching of an apprentice. Claim: this approach enables rapid acquisition of relevant problem solving knowledge from the SME. Y1 results: 787 predicates/day over 17 days. Problem Solving approach: task reduction with rules learned from the SME. Claim: the knowledge acquired from the SME assures good correctness of solutions and high performance of Pb.Solver. Y1 results: expert level performance for problems within system's scope. Speed: 3 solutions/second on a PC. KB Development TimeCP Test Performance Average time to generate a solution: 0.3 seconds

20
G.Tecuci, Learning Agents Laboratory

21
Demonstrated that a knowledge engineer can use Disciple to rapidly build and update a knowledge base capturing knowledge from military engineering manuals and a set of sample solutions provided by a subject matter expert. KB Disciple Workaround KE version Evolution of KB coverage and performance from the pre-repair phase to the post-repair phase. KB development during evaluation. 72% increase of KB size in 17 days High knowledge acquisition rate during evaluation; High problem solving performance (accurate solutions, new model solutions). Further extended and demonstrated at EFX’98 as part of an integrated application coordinated by Alphatech. Summary of evaluation results
. Further extended and demonstrated at EFX’98 as part of an integrated application coordinated by Alphatech. Summary of evaluation results.")
22
G.Tecuci, Learning Agents Laboratory Overview Evaluation of Disciple Workaround Agent training experiment with Disciple CoG Recommended reading The research goal Evaluation of Disciple COA Knowledge acquisition experiment with Disciple COA

23
G.Tecuci, Learning Agents Laboratory Identify strengths and weaknesses in a military Course of Action, based on the principles of war and the tenets of army operations. Disciple-COA (1998-1999)
.")
24
G.Tecuci, Learning Agents Laboratory May 10-15: Dry run to debug mechanics July 6-16: Two-week final evaluation Each week: –Release evaluation materials (Alphatech) –Debug shared input representations (Teknowledge, AIAI-Edinburgh, Alphatech) –Generate initial system responses (Teknowledge/Cyc, ISI-Expect, ISI-Loom, GMU) –Issue model answers (Alphatech) –Repair phase (All teams) –Generate revised system responses (All critiquing teams)
 –Debug shared input representations (Teknowledge, AIAI-Edinburgh, Alphatech) –Generate initial system responses (Teknowledge/Cyc, ISI-Expect, ISI-Loom, GMU) –Issue model answers (Alphatech) –Repair phase (All teams) –Generate revised system responses (All critiquing teams)")
25
G.Tecuci, Learning Agents Laboratory Baseline: PMA and COAs from sample scenarios Baseline with new test questions New friendly COA and questions Minor variant scenario New scenario Week 1 Week 2 Increasing difficulty

26
G.Tecuci, Learning Agents Laboratory Score for All Correct or Partly Correct Answers Number of Original Model Answers Score for Correct or Partly Correct Answers to Critiquing Questions Number of Original Model Answers Score for All Answers to Critiquing Questions Number of System Answers Provided Overall % = Recall = Precision =

27
G.Tecuci, Learning Agents Laboratory Correctness (50%) – Matches model answer or is otherwise judged to be correct. Justification (30%) – Scored on presence, soundness, and level of detail. Lay Intelligibility (10%) – Degree to which a lay observer can understand the answer and the justification. Sources (10%) – Degree to which appropriate sources are noted. Proactivity (10% extra credit) – Appropriate corrective actions or other information suggested to address the critique.
 – Scored on presence, soundness, and level of detail. Lay Intelligibility (10%) – Degree to which a lay observer can understand the answer and the justification. Sources (10%) – Degree to which appropriate sources are noted. Proactivity (10% extra credit) – Appropriate corrective actions or other information suggested to address the critique..")
28
G.Tecuci, Learning Agents Laboratory 53.83% 63.71% 114.69% 70.20% 78.92% 0.00% 20.00% 40.00% 60.00% 80.00% 100.00% 120.00% Tek/CycISI-ExpectGMUISI-LoomALL

29
G.Tecuci, Learning Agents Laboratory 56.81% 63.71% 114.69% 70.20% 84.20% 0.00% 20.00% 40.00% 60.00% 80.00% 100.00% 120.00% Tek/CycISI-ExpectGMUISI-LoomALL

30
G.Tecuci, Learning Agents Laboratory 62.61% 76.01% 81.99% 57.48% 75.01% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00% Tek/CycISI-ExpectGMUISI-LoomALL

31
G.Tecuci, Learning Agents Laboratory 0.00% 20.00% 40.00% 60.00% 80.00% 100.00% 120.00% 140.00% CorrectnessProactivityJustificationIntelligibilitySourceTotal Tek/Cyc ISI-Expect GMU ISI-Loom

32
G.Tecuci, Learning Agents Laboratory 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00% CorrectnessJustificationIntelligibilitySourcesProactivityTotal Tek/Cyc ISI-Expect GMU ISI-Loom

33
G.Tecuci, Learning Agents Laboratory Coverage Recall 0 20 40 60 80 100 120 140 160 0%50%100% 25%75% 3 5 4 4 5 3 3 4 5 Coverage Tek GMU ISI (Expect) (Evaluation Items 3, 4, and 5)
 (Evaluation Items 3, 4, and 5)")
34
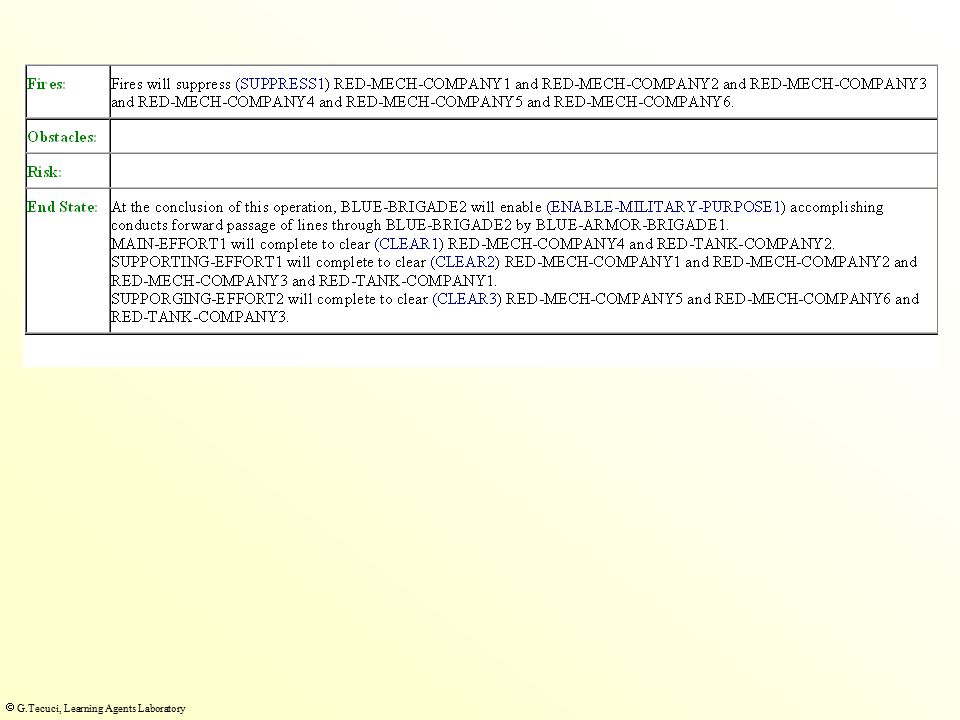
G.Tecuci, Learning Agents Laboratory To what extent does this course of action conform to the Principle of Objective? There is a weakness in COA BLUE-BRIGADE-COA4-2-1-MT with respect to objective because BLUE-TASK-FORCE1 is the MAIN-EFFORT1 of the COA and its assigned action is of a different type and has a significantly different focus than the main action of the COA BLUE-BRIGADE-TASK. The main effort is meant to accomplish the purpose of the COA and this may not be supported by the main effort having a different type of task and objective than the COA. Reference: FM 100-5 pg 2-4, KF 111.1, KF 111.5 - Direct every military operation toward a clearly defined, decisive, and attainable objective. A course of action which does not have a clearly defined purpose, which the main effort accomplishes and all other efforts support, is not following the principle of objective. Suggested corrective action: Redefine the actions assigned to the main effort of COA BLUE-BRIGADE-COA4-2-1-MT so that the main effort can accomplish the purpose of the COA, or designate a different unit as the main effort. Item 5 Total Score 105% GMU New Model Answers Original Model Answers 2536 AT

35
G.Tecuci, Learning Agents Laboratory Item 5Item 3 & 4

36
G.Tecuci, Learning Agents Laboratory 46% KB size increase in 8 days

37
G.Tecuci, Learning Agents Laboratory Overview Evaluation of Disciple Workaround Agent training experiment with Disciple CoG Recommended reading The research goal Evaluation of Disciple COA Knowledge acquisition experiment with Disciple COA

38
G.Tecuci, Learning Agents Laboratory

39
Organizers of the Experiment MAJ Eugene F. Stockel Battle Command Battle Lab. CPT Robert A. Rasch, Jr. Battle Command Battle Lab. Eric Jones Alphatech LTC John N. Duquette Battle Command Battle Lab. LTC Jay E. Farwell Battle Command Battle Lab. MAJ Michael P. Bowman Battle Command Training Prog. MAJ Dwayne E. Ptaschek Battle Command Battle Lab. Participants in the KA Experiment

40
G.Tecuci, Learning Agents Laboratory Demonstrate that it is possible for a military expert to teach Disciple how to critique a COA with respect to several principles of war. Measure the knowledge acquisition rate and the quality of the knowledge learned by Disciple. Create a useful professional development experience for the participating military experts.

41
G.Tecuci, Learning Agents Laboratory Critique of a COA by each military expert and by Disciple, and discussion of the generated critiques. Detailed presentation of Disciple's knowledge representation, problem solving and learning methods and tools, including the process of teaching Disciple to critique a COA with respect to the Tenet of Initiative and the Principle of Surprise.

42
G.Tecuci, Learning Agents Laboratory Discussion of the experiment and of Disciple. Each military expert taught Disciple to critique a COA with respect to the Principle of Offensive and the Principle of Security, starting from a conceptual modeling of the critiquing process.

43
G.Tecuci, Learning Agents Laboratory BLUE-TASK-FORCE1 MECHANIZED-INFANTRY-UNIT--MILITARY-SPECIALTY BLUE-ARMOR-BRIGADE2 MANEUVER-UNIT-MILITARY-SPECIALTYAVIATION-UNIT--MILITARY-SPECIALTY ARMORED-UNIT--MILITARY-SPECIALTYINFANTRY-UNIT--MILITARY-SPECIALTY MODERN-MILITARY-UNIT--DEPLOYABLE MODERN-MILITARY-ORGANIZATION ORGANIZATION BLUE-MECH-BRIGADE1 BLUE-TASK-FORCE2 BLUE-TASK-FORCE3

44
G.Tecuci, Learning Agents Laboratory

47
Assess security wrt countering enemy reconnaissance for-coa coa421 Assess security when enemy recon is present for-coa coa421 for-unit red-csop1 for-recon-action screen1 Yes, the enemy unit RED-CSOP1 is performing the action SCREEN1 which a reconnaissance action. No,... Assess COA wrt Principle of Security for-coacoa421 Is an enemy reconnaissance unit present? Is the enemy reconnaissance unit destroyed? I consider enemy reconnaissance coa421-security Does the COA include security and counter-recon actions, a security element, a rear element, and identify risks? No Report weakness in security because enemy recon is not countered for-coa coa421 for-unit red-csop1 for-recon-action screen1 with-importance... Yes ….

48
G.Tecuci, Learning Agents Laboratory Rule: R$ASWERIP-002 Task: ASSESS-SECURITY-WHEN-ENEMY-RECON-IS-PRESENT FOR-COA ?O1 FOR-UNIT ?O2 FOR-RECON-ACTION ?O3 Question:Is the enemy reconnaissance unit destroyed? Answer: No. Condition: ?O1 (CONCEPT (COA-SPECIFICATION-MICROTHEORY)) ?O2 (CONCEPT (MODERN-MILITARY-UNIT--DEPLOYABLE) (MECHANIZED-INFANTRY-UNIT--MILITARY-SPECIALTY)) ?O3 (CONCEPT (INTELLIGENCE-COLLECTION--MILITARY-TASK) (SCREEN--MILITARY-TASK)) ?S1 (STRING GM-CT (SET High)) Except when: ?O4 (CONCEPT (MILITARY-PURPOSE ACTION)) OBJECT-ACTED-ON ?O2 ?O2 (CONCEPT (MODERN-MILITARY-UNIT--DEPLOYABLE)) Conclusion: ?T1 REPORT-WEAKNESS-IN-SECURITY-BECAUSE-ENEMY-RECON-IS-NOT-COUNTERED FOR-COA ?O1 FOR-UNIT ?O2 FOR-RECON-ACTION ?O3 WITH-IMPORTANCE ?S1 Explanations: Failure explanation: ?O4 OBJECT-ACTED-ON ?O2
) O2 (CONCEPT (MODERN-MILITARY-UNIT--DEPLOYABLE) (MECHANIZED-INFANTRY-UNIT--MILITARY-SPECIALTY)) O3 (CONCEPT (INTELLIGENCE-COLLECTION--MILITARY-TASK) (SCREEN--MILITARY-TASK)) S1 (STRING GM-CT (SET High)) Except when: O4 (CONCEPT (MILITARY-PURPOSE ACTION)) OBJECT-ACTED-ON O2 O2 (CONCEPT (MODERN-MILITARY-UNIT--DEPLOYABLE)) Conclusion: T1 REPORT-WEAKNESS-IN-SECURITY-BECAUSE-ENEMY-RECON-IS-NOT-COUNTERED FOR-COA O1 FOR-UNIT O2 FOR-RECON-ACTION O3 WITH-IMPORTANCE S1 Explanations: Failure explanation: O4 OBJECT-ACTED-ON O2.")
49
G.Tecuci, Learning Agents Laboratory Task: REPORT-WEAKNESS-IN-SECURITY-BECAUSE-ENEMY-RECON-IS-NOT-COUNTERED FOR-COA ?O1 FOR-UNIT ?O2 FOR-RECON-ACTION ?O3 WITH-IMPORTANCE ?S1 NL description: Report disadvantage in security because is not countered. NL improvement: Consider actions to suppress, neutralize or destroy enemy. NL source: FM 71-3

50
G.Tecuci, Learning Agents Laboratory Description: Report disadvantage in security because RED-CSOP1 SCREEN1 is not countered. Suggested corrective action: Consider actions to suppress, neutralize or destroy enemy RED-CSOP1 SCREEN1. Reference: FM 71-3

51
G.Tecuci, Learning Agents Laboratory

52
KB extended with 26 rules and 28 tasks in 3 hours

53
G.Tecuci, Learning Agents Laboratory Degree of agreement with a statement: 1 (not at all) to 5 (very). All comments consider the fact that Disciple is a research prototype. Do you think that Disciple is a useful tool for Knowledge Acquisition? Rating 5. Absolutely! The potential use of this tool by domain experts is only limited by there imagination—not their AI programming skills. 5 4 Yes, it allowed me to be consistent with logical thought.

54
G.Tecuci, Learning Agents Laboratory Do you think that Disciple is a useful tool for Problem Solving? Rating 5. Yes. 5 (absolutely) 4 Yes. As it develops and becomes tailored to the user, it will simplify the tedious tasks.
 4 Yes. As it develops and becomes tailored to the user, it will simplify the tedious tasks..")
55
G.Tecuci, Learning Agents Laboratory Do you think that Disciple has potential to be used in other tasks you do? Rating 5. Again the use of the tool is only limited to one’s imagination but potential applications include knowledge bases built to support distance/individual learning, a multitude of decision support tools (not just COA Analysis), and autonomous and semi-autonomous decision makers—all these designed by the domain expert vs an AI programmer. Absolutely. It can be used to critique any of the BOS's for any mission. 5 Yes 4
, and autonomous and semi-autonomous decision makers—all these designed by the domain expert vs an AI programmer. Absolutely. It can be used to critique any of the BOS s for any mission. 5 Yes 4.")
56
G.Tecuci, Learning Agents Laboratory Were the procedures/processes used in Disciple compatible with Army doctrine and/or decision making processes? Rating 5. As a minimum yes, as a maximum—better! This again was done very well. 4

57
G.Tecuci, Learning Agents Laboratory Could Disciple be used to support operational requirements in your organization? Rating 5. Yes, Absolutely! I’ll take 10 of them! 5 Not at this point of development.

58
G.Tecuci, Learning Agents Laboratory IKB Disciple COA KE version KB development during evaluation. 46% increase of KB size in 8 days Evolution of KB coverage and performance from the pre-repair phase to the post-repair phase for the final 3 evaluation items. Demonstrated the generality of the learning methods that used an Object ontology created by another group (Cycorp and Teknowledge). Demonstrated that a knowledge engineer and a subject matter expert can jointly teach Disciple. High knowledge acquisition rate during evaluation; Better performance than the other systems; Better performance than the evaluating experts (many new model solutions). Summary of evaluation results
. Demonstrated that a knowledge engineer and a subject matter expert can jointly teach Disciple. High knowledge acquisition rate during evaluation; Better performance than the other systems; Better performance than the evaluating experts (many new model solutions). Summary of evaluation results.")
59
G.Tecuci, Learning Agents Laboratory Overview Evaluation of Disciple Workaround Agent training experiment with Disciple CoG Recommended reading The research goal Evaluation of Disciple COA Knowledge acquisition experiment with Disciple COA

60
G.Tecuci, Learning Agents Laboratory Disciple-COG (2000-2003) The center of gravity of an entity (state, alliance, coalition, or group) is the foundation of capability, the hub of all power and movement, upon which everything depends, the point against which all the energies should be directed. Carl Von Clausewitz, “On War,” 1832. If a combatant eliminates or influences the enemy’s strategic center of gravity, then the enemy will lose control of its power and resources and will eventually fall to defeat. If the combatant fails to adequately protect his own strategic center of gravity, he invites disaster. Identify Center of Gravity candidates in strategic theater of war scenarios.

61
G.Tecuci, Learning Agents Laboratory Students use Disciple to learn about the Center of Gravity concept and to develop a case study in COG analysis. Case Studies in Center of Gravity Analysis Course Students use Disciple to learn about Artificial Intelligence and to develop knowledge-based agents for the identification and testing of strategic COG candidates. Includes a final agent development experiment. Military Applications of Artificial Intelligence Course Students develop inputs Students develop agents Use of Disciple in US Army War College courses

62
G.Tecuci, Learning Agents Laboratory Test the ability of subject matter experts to develop end-to-end agents that can identify center of gravity candidates for a scenario. Measure the effectiveness of the following knowledge base development activities: scenario specification, domain modeling, task formalization, explanation generation, rule learning, and rule refinement. Performed global measurements in a tightly controlled environment: sizes of the KBs developed, KA rates, quality of the developed KBs, help received by the SME. Create a baseline for future evaluations. Goals of the final agent training experiment

63
G.Tecuci, Learning Agents Laboratory Task Develop an end-to-end agent for the identification of strategic COG candidates: 1.based on a previously unseen scenario (the planned 1945 US invasion of the island of Okinawa); 2.starting with a Disciple agent that contains a generic object ontology but no specific knowledge, no tasks, and no rules; 3.preserving the same conditions as during class projects (i.e. 5 teams of two students). The entire experiment was video-taped Experiment Design
. The entire experiment was video-taped Experiment Design.")
64
G.Tecuci, Learning Agents Laboratory 1. Introduction 2. Study scenario description 3. Scenario specification 4. COG candidate identification 5. Modeling for a force 7. Rule learning 8. Modeling for the 2 nd force 10. Rule learning and refining 11. Automatic problem solving Questions/Answers Verification Correction Verification Correction Verification Correction Verification Correction Verification Correction 12. Agent use on a new scenario 9. Formalization for the 2 nd force Verification Correction 6. Formalization for a force Verification Correction Notation: Task performed by SME Task performed by KE Task performed by KE and SME Stages of the Experiment

65
G.Tecuci, Learning Agents Laboratory LTC Dietrick LTC Wiseman LTC Babb COL Matsumura COL Godfrey LTC Velez COL Chimeddorj COL Pike Generic object ontology Okinawa scenario General rules LTC Brooks LTC Alho KBs Developed During the Experiment

66
G.Tecuci, Learning Agents Laboratory LTC Brooks LTC AlhoLTC Dietrick LTC Wiseman LTC Babb COL Matsumura COL Godfrey LTC Velez Generic object ontology Okinawa scenario General rules 19 rules17 rules19 rules22 rules17 rules 78 instances 90 feature val 78 instances 86 feature val 94 instances 103 feature val 105 instances 111 feature val 72 instances 79 feature val 144 concepts 79 features 0.99h 0.91h 1.35h1.38h0.86h 3.77h 4.35h 3.86h3.97h 4.58h COL Chimeddorj COL Pike KBs Developed During the Experiment

67
G.Tecuci, Learning Agents Laboratory Solutions generated by the experiment agents

68
G.Tecuci, Learning Agents Laboratory InstancesFeature valuesFactsTime interval Okinawa - Falklands team 78901700.99h Okinawa - Leyte team 78861660.91h Okinawa - Panama team 941031991.35h Okinawa - Grenada team 1051112181.38h Okinawa - Inchon team 72791530.86h Average85.4093.80181.201.10h Total4274699065.49h Knowledge Base Size Instances acquired during scenario specification

69
G.Tecuci, Learning Agents Laboratory Knowledge Base Size RulesTime interval Okinawa - Falklands team 193.77h Okinawa - Leyte team 224.35h Okinawa - Panama team 173.86h Okinawa - Grenada team 173.97h Okinawa - Inchon team 194.58h Average18.804.11h Total9420.54h Rules learned during experiment

70
G.Tecuci, Learning Agents Laboratory Rate (number / hour) FactsRules Okinawa - Falklands team 171.195.04 Okinawa - Leyte team 182.705.06 Okinawa - Panama team 147.834.40 Okinawa - Grenada team 157.784.28 Okinawa - Inchon team 177.334.15 Average167.374.59 Knowledge Acquisition Rates
 FactsRules Okinawa - Falklands team Okinawa - Leyte team Okinawa - Panama team Okinawa - Grenada team Okinawa - Inchon team Average Knowledge Acquisition Rates")
71
G.Tecuci, Learning Agents Laboratory Project agents Experiment agents Performance of the Agents on a New Scenario Falklands_1982: Falklands war between Argentina and Britain

72
G.Tecuci, Learning Agents Laboratory Project agents Experiment agents Panama_1989: US invasion of Panama in December 1989 Performance of the Agents on a New Scenario

73
G.Tecuci, Learning Agents Laboratory Project agentsExperiment agents Leyte_1944: Capture of Leyte Island Performance of the Agents on a New Scenario

74
G.Tecuci, Learning Agents Laboratory Project agents Experiment agents Malaya_1941: The Japanese invasion of British Malaya Performance of the Agents on a New Scenario

75
G.Tecuci, Learning Agents Laboratory Performance of the Agents on Several Scenarios

76
G.Tecuci, Learning Agents Laboratory Scenario specification SME assessments of individual steps Domain modeling Task formalization Rule learning Rule refinement Problem solving Agent development requires completion of all these phases by the subject matter experts

77
G.Tecuci, Learning Agents Laboratory Scenario Elicitation: SME Assessments It is easy to learn to use the Scenario Elicitation tool Median: Agree Mode: Agree (60%)
")
78
G.Tecuci, Learning Agents Laboratory Scenario Elicitation: SME Assessments Scenario Elicitation tool is easy to use Median: Agree Mode: Agree (60%)
")
79
G.Tecuci, Learning Agents Laboratory Scenario Elicitation: SME Assessments The user does not need to understand the generated object ontology to use this tool Median: Agree Mode: Agree (50%)
")
80
G.Tecuci, Learning Agents Laboratory Lessons Learned The scenario elicitation module allows the experts to specify the scenario with no assistance from a knowledge engineer. The scenario elicitation module cannot anticipate all the required knowledge. The scenario description needs to be updated after learning has started and the scenario elicitation module needs to reflect all the changes in the object ontology. The current version allows the expert to easily define specific instances in the ontology, but it has only limited capabilities for defining new object concepts in the generic ontology

81
G.Tecuci, Learning Agents Laboratory Future Developments Redesign the scenario elicitation module such that any knowledge engineer may dynamically define or update the elicitation scripts. Enhance this module to facilitate the definition and updating of new concepts and features. Develop and integrate KB management assistants. Develop finding and browsing capabilities.

82
G.Tecuci, Learning Agents Laboratory Scenario specification Steps in Agent Development Domain modeling Task formalization Rule learning Rule refinement Problem solving Domain Modeling by SME is the most uncertain R&D issue.

83
G.Tecuci, Learning Agents Laboratory Domain Modeling: SME Assessments SMEs who are not computer scientists can learn to express their reasoning process using the task reduction paradigm, with a reasonable amount of effort Median: Agree Mode: Agree (80%)
")
84
G.Tecuci, Learning Agents Laboratory Domain Modeling: SME Assessments It is easy to learn to use the Domain Modeling tool Median: Between Neutral and Agree

85
G.Tecuci, Learning Agents Laboratory Domain Modeling: SME Assessments Domain Modeling tool is easy to use Median: Neutral Mode: Neutral (40%)
")
86
G.Tecuci, Learning Agents Laboratory Domain Modeling: SME Assessments I can easily enter the information this tool requests Median: Agree Mode: Agree (70%)
")
87
G.Tecuci, Learning Agents Laboratory Domain Modeling: SME Assessments I can easily update the information entered previously Median: Agree Mode: Agree (70%)
")
88
G.Tecuci, Learning Agents Laboratory Lessons Learned The task reduction paradigm is appropriate to express the reasoning processes of the SMEs. The domain modeling methodology based on task reduction needs to be made more natural. The intermediate tasks seem redundant to the experts. They might be automatically generated by the agent and may even be hidden from the expert. The SME should receive more guidance from the agent during domain modeling. The domain modeling interface needs to be simplified.

89
G.Tecuci, Learning Agents Laboratory Future Developments Improve the domain modeling methodology. Redesign the interface to simplify the interactions with the SME. Develop modeling assistants that can help the expert in domain modeling (by using analogical reasoning with previously done modeling) and by suggesting the next modeling operation.
 and by suggesting the next modeling operation..")
90
G.Tecuci, Learning Agents Laboratory Scenario specification Steps in Agent Development Domain modeling Task formalization Rule learning Rule refinement Problem solving

91
G.Tecuci, Learning Agents Laboratory Task Formalization: SME Assessments It is easy to learn to perform task formalization Median: Agree Mode: Agree (70%)
")
92
G.Tecuci, Learning Agents Laboratory Task Formalization: SME Assessments Task formalization is easy to do Median: Agree Mode: Agree (60%)
")
93
G.Tecuci, Learning Agents Laboratory Task Formalization: SME Assessments Disciple helps me to formalize the task Median: Agree Mode: Agree (70%)
")
94
G.Tecuci, Learning Agents Laboratory Lessons Learned and Future Developments The task formalization process should be further simplified. Develop a more powerful task formalization method by: - better use of the context information; - natural language processing of the task; - analogy with previously formalized tasks.

95
G.Tecuci, Learning Agents Laboratory Scenario specification Steps in Agent Development Domain modeling Task formalization Rule learning Rule refinement Problem solving Rule learning is a very difficult barrier in agent development by an SME.

96
G.Tecuci, Learning Agents Laboratory Explanation Generation: SME Assessments Explanation generation module is easy to use Median: Between Neutral and Agree Mode: Neutral (40%) and Agree (40%)
 and Agree (40%)")
97
G.Tecuci, Learning Agents Laboratory Explanation Generation: SME Assessments Disciple helps in finding the explanation pieces Median: Agree Mode: Agree (50%)
")
98
G.Tecuci, Learning Agents Laboratory Rule Learning: SME Assessments It is easy to learn to use Rule Learning Median: Between Neutral and Agree Mode: Neutral (40%) and Agree (40%)
 and Agree (40%)")
99
G.Tecuci, Learning Agents Laboratory Lessons Learned The generated rule must be analyzed before finishing learning in order to avoid incompletely learned rules that generate too many solutions. More flexible mechanisms for adding and removing explanations are needed. The example needs to be analyzed in order to avoid rule duplications. The explanations must be displayed in a more natural way. Default explanations should always be generated.

100
G.Tecuci, Learning Agents Laboratory Future Developments Facilitate the process of explanation definition by the expert and integrate knowledge elicitation in this process. Develop more powerful analogical methods for explanation generation. Develop natural language processing methods for extracting better hints from the question and the answer. Develop methods for example and rule analysis, to improve the rule learning process. Develop better interface for explanations.

101
G.Tecuci, Learning Agents Laboratory Scenario specification Steps in Agent Development Domain modeling Task formalization Rule learning Rule refinement Problem solving Rule refinement is another very difficult barrier in agent development by an SME.

102
G.Tecuci, Learning Agents Laboratory Rule Refinement: SME Assessments It is easy to learn how to use Rule Refinement Median: Agree Mode: Agree (60%)
")
103
G.Tecuci, Learning Agents Laboratory Lessons Learned The need for the rule refinement operation is not easy to identify. The agent should direct the attention of the SME toward the steps that are plausible and need to be analyzed. There is a need to perform global refinement for an entire reasoning path which is correct. The explanations given for the negative examples are not very intuitive.

104
G.Tecuci, Learning Agents Laboratory Future Developments Develop more powerful capabilities for generating failure explanations. Develop methods for rule refinement based on failure explanations. Automatically refine all the rules that generated a correct line of reasoning. Develop better controls for the rule refinement operation.

105
G.Tecuci, Learning Agents Laboratory Disciple: SME Assessments I think that a subject matter expert can use Disciple to build an agent, with limited assistance from a knowledge engineer Median: Agree Mode: Agree (70%)
")
106
G.Tecuci, Learning Agents Laboratory Overview Evaluation of Disciple Workaround Agent training experiment with Disciple CoG Recommended reading The research goal Evaluation of Disciple COA Knowledge acquisition experiment with Disciple COA

107
G.Tecuci, Learning Agents Laboratory Recommended reading Tecuci G., Boicu M., Wright K., Lee S.W., Marcu D. and Bowman M., "A Tutoring Based Approach to the Development of Intelligent Agents," in Teodorescu, H.N., Mlynek, D., Kandel, A. and Zimmermann, H.J. (editors). Intelligent Systems and Interfaces, Kluwer Academic Press. 2000. http://lalab.gmu.edu/publications/data/2001/Chapter-1-book-2000.doc Tecuci G., Boicu M., Bowman M., and Dorin Marcu, with a commentary by Murray Burke, “An Innovative Application from the DARPA Knowledge Bases Programs: Rapid Development of a High Performance Knowledge Base for Course of Action Critiquing,” invited paper for the special IAAI issue of the AI Magazine, Volume 22, No, 2, Summer 2001, pp. 43-61. http://lalab.gmu.edu/publications/data/2001/COA-critiquer.pdf Boicu M., Tecuci G., Stanescu B., Marcu D. and Cascaval C., "Automatic Knowledge Acquisition from Subject Matter Experts," in Proceedings of the IEEE International Conference on Tools with Artificial Intelligence, Dallas, Texas, November 2001. http://lalab.gmu.edu/publications/data/2001/ICTAI.doc The following papers contain descriptions of the experiments presented in the previous slides.
. Intelligent Systems and Interfaces, Kluwer Academic Press Tecuci G., Boicu M., Bowman M., and Dorin Marcu, with a commentary by Murray Burke, An Innovative Application from the DARPA Knowledge Bases Programs: Rapid Development of a High Performance Knowledge Base for Course of Action Critiquing, invited paper for the special IAAI issue of the AI Magazine, Volume 22, No, 2, Summer 2001, pp Boicu M., Tecuci G., Stanescu B., Marcu D. and Cascaval C., Automatic Knowledge Acquisition from Subject Matter Experts, in Proceedings of the IEEE International Conference on Tools with Artificial Intelligence, Dallas, Texas, November The following papers contain descriptions of the experiments presented in the previous slides..")
Similar presentations