Download presentation
Presentation is loading. Please wait.

1
Sampling online communities: using triplets as basis for a (semi-) automated hyperlink web crawler. Yoann VENY Université Libre de Bruxelles (ULB) - GERME yoann.veny@ulb.ac.be This research is funded by the FRS-FNRS Paper presented at the 15th General Online Reasearch Conference, 4-6 march, Mannheim
 - GERME This research is funded by the FRS-FNRS Paper presented at the 15th General Online Reasearch Conference, 4-6 march, Mannheim.")
2
Online communities – a theoretical definitions What is an online community? “social aggregations that emerge from the Net when enough people carry on those public discussions long enough, with sufficient human feeling, to form webs of personal relationship in cyberspace” » (Rheingold 2000) long term involvement (Jones 2006) sense of community (Blanchard 2008) temporal perspective (Lin et al 2006) Probably important … but the first operation should be to take into account the ‘hyperlink environment’ Graph analysis issue / SNA issue
 long term involvement (Jones 2006) sense of community (Blanchard 2008) temporal perspective (Lin et al 2006) Probably important … but the first operation should be to take into account the ‘hyperlink environment’ Graph analysis issue / SNA issue.")
3
Online Communities – A graphical definition (1) Community = more ties among members than with non-members three general classes of ‘community’ in graph partitioning algorithm (Fortunato 2010) : – a local definition: focus on the sub-graphs (i.e.: cliques, n-cliques (Luce, 1950), k-plex (Seidman & Foster, 1978), lambda sets (Borgatti et al, 1990), … ) – a global definition: focus on the graph as a whole (observed graph significantly different from a random graph (i.e.: Erdös-Rényi graph)?) – vertex similarity: focus on actors (i.e.: euclidian distance & hierarchical clustering, max-flow/min-cut (Elias et al, 1956; Flake et al, 2000)
 Community = more ties among members than with non-members three general classes of ‘community’ in graph partitioning algorithm (Fortunato 2010) : – a local definition: focus on the sub-graphs (i.e.: cliques, n-cliques (Luce, 1950), k-plex (Seidman & Foster, 1978), lambda sets (Borgatti et al, 1990), … ) – a global definition: focus on the graph as a whole (observed graph significantly different from a random graph (i.e.: Erdös-Rényi graph) ) – vertex similarity: focus on actors (i.e.: euclidian distance & hierarchical clustering, max-flow/min-cut (Elias et al, 1956; Flake et al, 2000)")
4
Online communities – graphical definition (2) 2 main problems of graph partitionning in a hyperlink environment: 1) network size / and form (i.e. tree structure) 2) edges direction better discover communities with a efficient web crawler
 2) edges direction better discover communities with a efficient web crawler.")
5
Web crawling - Generalities The general idea for a web crawling process: Source: Jacomi & Ghitalla (2007) - We have a number of starting blogs (seeds) - All hyperlink are retrieved from these seeds blogs - For each new website discovered, decide wether this new site is accepted or refused - If the site is accepted, it become a seed and the process is reiterated on this site.
 - We have a number of starting blogs (seeds) - All hyperlink are retrieved from these seeds blogs - For each new website discovered, decide wether this new site is accepted or refused - If the site is accepted, it become a seed and the process is reiterated on this site.")
6
Web crawling – constrain-based web crawler (1) Two problems of a manual crawler : Number and quality of decision Closure? A solution: taking advantage of local structural properties of a network: Assume that a network is an outcome of the agregation of local social processes: – Examples in SNA: General philosphy of ERG Models (see f.e. : Robins et al 2007) Local clustering coefficient (see f.e. : Watts & Strogatz, 1998) Constrain the crawler to identify local social structures (ie: triangles, mutual dyads, transitive triads,…
 Local clustering coefficient (see f.e. : Watts & Strogatz, 1998) Constrain the crawler to identify local social structures (ie: triangles, mutual dyads, transitive triads,….")
7
Web crawling – constrain-based web crawler (2) An example of a constrained web crawler based on identification of triangles Generalisation
 An example of a constrained web crawler based on identification of triangles Generalisation")
8
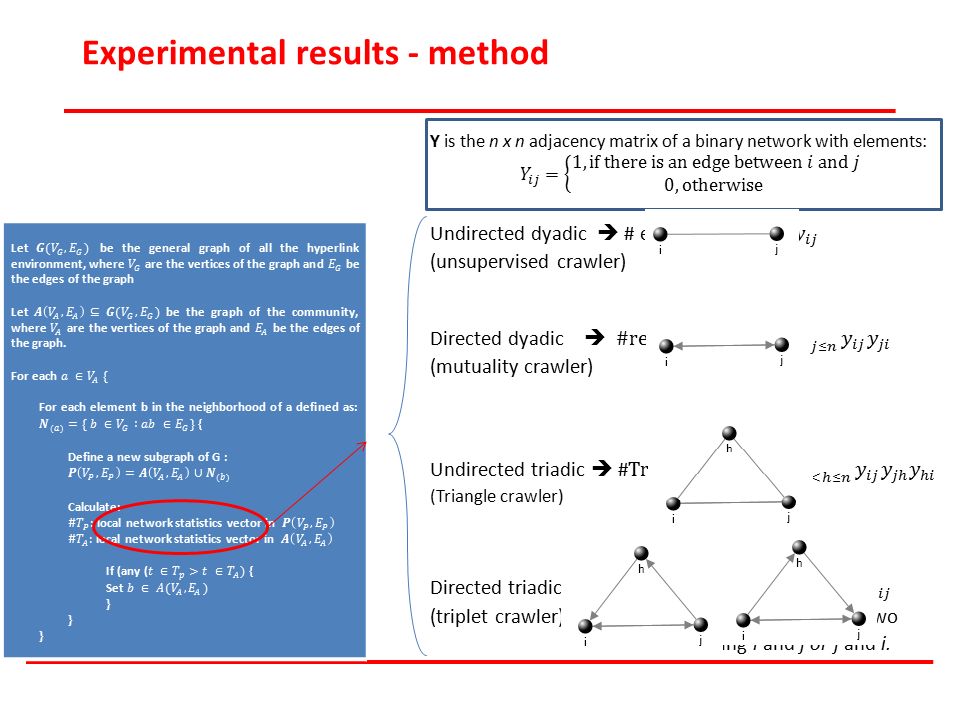
Experimental results - method

10
Experimental results – results(1) Starting set: 6 « polititical ecological » blogs Remarks: dyad sampler and triplets samplers closure Unsupervised and triangles samplers manually stopped
 Starting set: 6 « polititical ecological » blogs Remarks: dyad sampler and triplets samplers closure Unsupervised and triangles samplers manually stopped")
11
Experimental results – results (2) Triangles Dyads Triplets
 Triangles Dyads Triplets")
12
Unsupervised crawler is not manageable (+20000 actors after 4 iterations!!) Dyads: did not selected ‘authoritative’ sources + sensitive to the number of seeds ? Triplets seems to be the best solution: take ties direction into account + take profit of authoritative sources + conservative Triangles: problem of network size … but sampled network can have interesting properties.

13
Conclusion and further researches Pitfalls to avoid: Not necessary all relevant information in the core: there is a lot of information in the periphery of this core. Based on human behaviour patterns: not adapted at all for other kind of networks (words occurencies, proteïns chains,…) Do not throw away more classical graph partitionning methods Always question your results. How to assess efficiency of a crawler? Should communities in web graph always be topic-centered Further researches: Analysis and detection of ‘multi-core’ networks ‘Random walks’ in complete networks to find recursive patterns using T.C. assumptions Code of the samplers in ‘R’
 Do not throw away more classical graph partitionning methods Always question your results. How to assess efficiency of a crawler. Should communities in web graph always be topic-centered Further researches: Analysis and detection of ‘multi-core’ networks ‘Random walks’ in complete networks to find recursive patterns using T.C. assumptions Code of the samplers in ‘R’.")
Similar presentations









>")









