Download presentation
Presentation is loading. Please wait.

1
1 Overview 2 Cache entry structure 3 mapping function 4 Cache hierarchy in a modern processor 5 Advantages and Disadvantages of Larger Caches 6 Implementation

3
A CPU cache is a cache used by the central processing unit (CPU) of a computer to reduce the average time to access data from the main memory The cache is a smaller, faster memory which stores copies of the data from frequently used main memory locations. Most CPUs have different independent caches, including instruction and data caches, where the data cache is usually organized as a hierarchy of more cache levels (L1, L2 etc.)
.")
4
Overview When the processor needs to read from or write to a location in main memory, it first checks whether a copy of that data is in the cache. If so, the processor immediately reads from or writes to the cache, which is much faster than reading from or writing to main memory. Most modern desktop and server CPUs have at least three independent caches: an instruction cache to speed up executable instruction fetch, a data cache to speed up data fetch and store, and a translation lookaside buffer (TLB) used to speed up virtual-to-physical address translation for both executable instructions and data.
 used to speed up virtual-to-physical address translation for both executable instructions and data..")
5
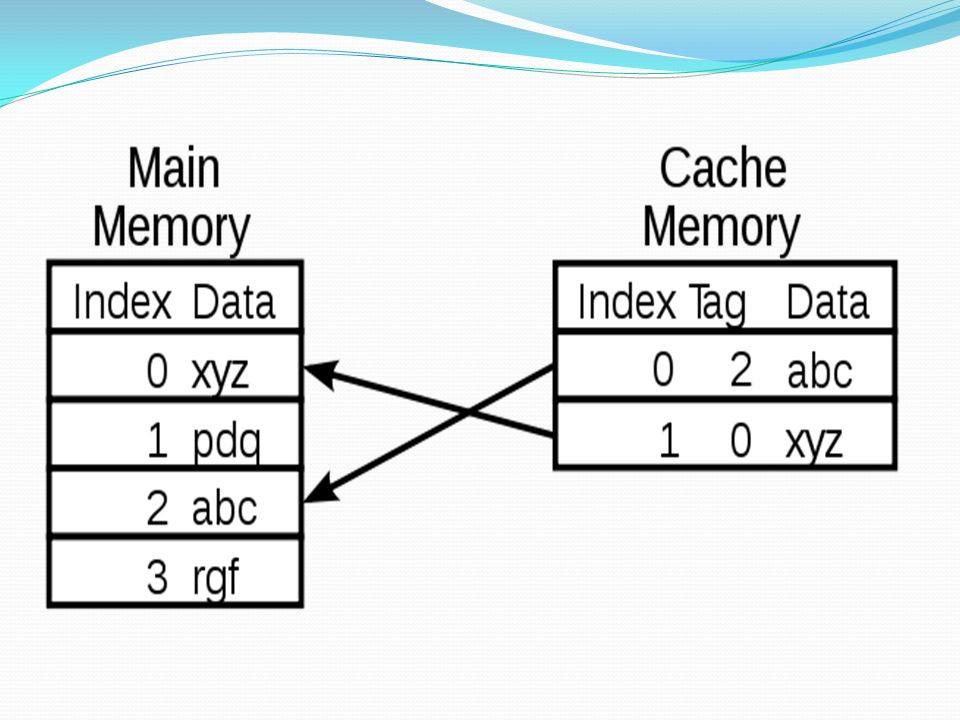
Cache entries Data is transferred between memory and cache in blocks of fixed size, called cache lines. When a cache line is copied from memory into the cache, a cache entry is created. The cache entry will include the copied data as well as the requested memory location (now called a tag). When the processor needs to read or write a location in main memory, it first checks for a corresponding entry in the cache. The cache checks for the contents of the requested memory location in any cache lines that might contain that address. If the processor finds that the memory location is in the cache, a cache hit has occurred. However, if the processor does not find the memory location in the cache, a cache miss has occurred. In the case of: a cache hit, the processor immediately reads or writes the data in the cache line a cache miss, the cache allocates a new entry and copies in data from main memory, then the request is fulfilled from the contents of the cache.
. When the processor needs to read or write a location in main memory, it first checks for a corresponding entry in the cache. The cache checks for the contents of the requested memory location in any cache lines that might contain that address. If the processor finds that the memory location is in the cache, a cache hit has occurred. However, if the processor does not find the memory location in the cache, a cache miss has occurred. In the case of: a cache hit, the processor immediately reads or writes the data in the cache line a cache miss, the cache allocates a new entry and copies in data from main memory, then the request is fulfilled from the contents of the cache..")
6
Cache entry structure Cache row entries usually have the following structure: The data block (cache line) contains the actual data fetched from the main memory. The tag contains (part of) the address of the actual data fetched from the main memory. The flag bits are discussed below. The "size" of the cache is the amount of main memory data it can hold. This size can be calculated as the number of bytes stored in each data block times the number of blocks stored in the cache. tagdata blockflag bits
 the address of the actual data fetched from the main memory. The flag bits are discussed below. The size of the cache is the amount of main memory data it can hold. This size can be calculated as the number of bytes stored in each data block times the number of blocks stored in the cache. tagdata blockflag bits.")
8
Mapping Function Because there are fewer cache lines than main memory blocks, an algorithm is needed for mapping main memory blocks into cache lines. The choice of the mapping function dictates how the cache is organized. Three techniques can be used: 1. Direct. 2. Associative 3. Set associative.

9
Direct mapping The simplest technique. maps each block of main memory into only one possible cache line. also be called a "one-way set associative" cache. It does not have a replacement policy.

10
b t b B0 L0 m line B m-1 L m-1 main memory Cache memory b=length of block in bit t= length of tag in bit

11
The direct mapping technique is simple and inexpensive to implement. Its main disadvantage is that there is a fixed cache location for any given block. Thus, if a program happens to reference words repeatedly from two different blocks that map into the same line, then the blocks will be continually swapped in the cache, and the hit ratio will be low

12
ASSOCIATIVE MAPPING Any memory location can be cached in any cache line. This is the most complex technique and requires sophisticated search algorithms when checking for a hit. It can lead to the whole cache being slowed down because of this, but it offers the best theoretical hit ratio since there are so many options for caching any memory address. It overcomes the disadvantage of direct mapping.

13
t b L 0 b one block of Memory L m-1 Cache memory

14
the cache control logic interprets a memory address simply as a Tag and a Word field. The Tag field uniquely identifies a block of main memory. To determine whether a block is in the cache, the cache control logic must simultaneously examine every line’s tag for a match. With associative mapping, there is flexibility as to which block to replace when a new block is read into the cache. The principal disadvantage of associative mapping is the complex circuitry required to examine the tags of all cache lines in parallel.

15
SET-ASSOCIATIVE MAPPING A compromise that exhibits the strengths of both the direct and associative approaches while reducing their disadvantages. The cache is broken into sets of "N" lines each, and any memory address can be cached in any of those "N" lines. This improves hit ratios over the direct mapped cache, but without incurring a severe search penalty

16
Set-Associative Caches Characterized by more than one line per set validtag set 0: N=2 lines per set set 1: set N-1: cache block validtagcache block validtagcache block validtagcache block validtagcache block validtagcache block

17
B0 k lines cache memory_set 0 Bv-1 first N block cache memory _set N-1 of main memory

18
Cache hierarchy in a modern processor The operation of a particular cache can be completely specified by: the cache size the cache block size the number of blocks in a set the cache set replacement policy the cache write policy (write-through or write-back)
")
19
While all of the cache blocks in a particular cache are the same size and have the same associativity, typically: 1. "lower-level" caches (such as the L1 cache) have a smaller size have smaller blocks have fewer blocks in a set, 2. "higher-level" caches (such as the L3 cache) have larger size larger blocks have more blocks in a set.
 have a smaller size have smaller blocks have fewer blocks in a set, 2. higher-level caches (such as the L3 cache) have larger size larger blocks have more blocks in a set..")
20
Specialized caches: Pipelined CPUs access memory from multiple points in the pipeline:pipeline instruction fetch virtual-to-physical address translationvirtual-to-physical data fetch Thus the pipeline naturally ends up with at least three separate caches: Instruction I TLB Data Each specialized to its particular role.

21
1. Victim cache A victim cache is a cache used to hold blocks evicted from a CPU cache upon replacement. The victim cache lies between the main cache and its refill path, and only holds blocks that were evicted from the main cache. The victim cache is usually fully associative, and is intended to reduce the number of conflict misses. Many commonly used programs do not require an associative mapping for all the accesses. It was introduced by Norman Jouppi from DEC in 1990.

22
2. Trace cache: One of the more extreme examples of cache specialization is the trace cache found in the Intel Pentium 4 microprocessors.IntelPentium 4 A trace cache is a mechanism for increasing the instruction fetch bandwidth and decreasing power consumptionby storing traces of instructions that have already been fetched and decoded.instructions

23
A trace cache stores instructions either after they have been decoded, or as they are retired. Generally, instructions are added to trace caches in groups representing either individual basic blocks or dynamic instruction traces.basic blocks Trace lines are stored in the trace cache based on the program counter of the first instruction in the trace and a set of branch predictions. This allows for storing different trace paths that start on the same address, each representing different branch outcomes.program counter

24
3. Micro-operation (uop) cache A micro-operation cache (Uop Cache, UC) is a specialized cache that stores micro-operations of decoded instructions, as received directly from the instruction decoders or from the instruction cache.micro-operationsinstruction decoders When an instruction needs to be decoded, the uop cache is checked for its decoded form which is re-used if cached; if it is not available, the instruction is decoded and then cached.
 cache A micro-operation cache (Uop Cache, UC) is a specialized cache that stores micro-operations of decoded instructions, as received directly from the instruction decoders or from the instruction cache.micro-operationsinstruction decoders When an instruction needs to be decoded, the uop cache is checked for its decoded form which is re-used if cached; if it is not available, the instruction is decoded and then cached..")
25
A uop cache has many similarities with a trace cache, although a uop cache is much simpler thus providing better power efficiency; this makes it better suited for implementations on battery-powered devices. The main disadvantage of the trace cache, leading to its power inefficiency, is the hardware complexity required for its heuristic deciding on caching and reusing dynamically created instruction traces.heuristic

26
Disadvantages of Larger Caches Cache is a kind of memory very expensive and it is usually made of SRAM (static RAM), and it is different from the regular main memory designated by SDRAM, etc. The cache memory uses a lot more transistors for a single bit of information Advantages of Larger Caches: it is large enough, then it can easily contain the information within a large cache-line. in larger cache memories the hit rate increases 100%

27
Cache hierarchy in a modern processor The number of levels in the memory hierarchy and the performance at each level has increased over time Multi Level Caches Another issue is the fundamental tradeoff between cache latency and hit rate. Larger caches have better hit rates but longer latency. To address this tradeoff, many computers use multiple levels of cache,

28
The evolution of several cache layers started to be a reality, it is good for performance. Despite the cache speed difference between L1 and system memory still meant every time the CPU needed to access system memory it had to request the data, and then wait for it A small L1 cache was nice, but it wasn't enough.

29
A level-2 (L2) cache is usually fast (faster) RAM. Cache size can range from 8KB to 1 MB. There is no hard and fast rule about cache size but the general rule is the faster the CPU relative to system memory, the larger your L2 cache should be. And then why not have a third level of cache (L3) with a bigger size then L2
 with a bigger size then L2.")
30
Level4 cache the addition of a fourth level of cache memory is more beneficial than increasing the L3 cache and evaluate the performance gain that is achieved by interlacing the hierarchy of cache memories. To examine the difference in performance with a large L3 cache, compared to the addition of an L4cache memory module

31
an architecture with four cache levels (L1, L2, L3 and L4) where each module has only one lower level cache module in the memory hierarchy. another architecture, in which each L2 cache module can be linked to one or two memories in the L3 level of the hierarchy

32
a large L3 memory (with 32 megabytes of space), shared among all eight cores; but the 32 megabytes of L3 memory were divided into: two 8 megabytes L3 memory modules, each shared by half of the cores, and a 16 megabytes L4 memory, shared by all cores;
, shared among all eight cores; but the 32 megabytes of L3 memory were divided into: two 8 megabytes L3 memory modules, each shared by half of the cores, and a 16 megabytes L4 memory, shared by all cores;")
33
cache level 4 :

34
IMPLEMENTATION Cache reads are the most common CPU operation that takes more than a single cycle. Program execution time tends to be very sensitive to the latency of a level-1 data cache hit. A great deal of design effort, and often power and silicon area are expended making the caches as fast as possible.

35
The simplest cache is a virtually indexed direct-mapped cache. The virtual address is calculated with an adder, the relevant portion of the address extracted and used to index an SRAM, which returns the loaded data. The data is byte aligned in a byte shifter, and from there is bypassed to the next operation.

36
An associative cache is more complicated, because some form of tag must be read to determine which entry of the cache to select. An N-way set-associative level-1 cache usually reads all N possible tags and N data in parallel, and then chooses the data associated with the matching tag. Level-2 caches sometimes save power by reading the tags first, so that only one data element is read from the data SRAM.

Similar presentations







 Cache memories.>")

 Tag.>")


It is less expensive 2)It is usually faster 3)Its average CPI is smaller 4)It allows a faster clock rate 5)It has a simpler.>")

>")

>")



