Download presentation
Presentation is loading. Please wait.

1
Alexander Gelbukh www.Gelbukh.com
Special Topics in Computer Science Advanced Topics in Information Retrieval Lecture 4 (book chapter 8): Indexing and Searching Alexander Gelbukh
: Indexing and Searching. Alexander Gelbukh.")
2
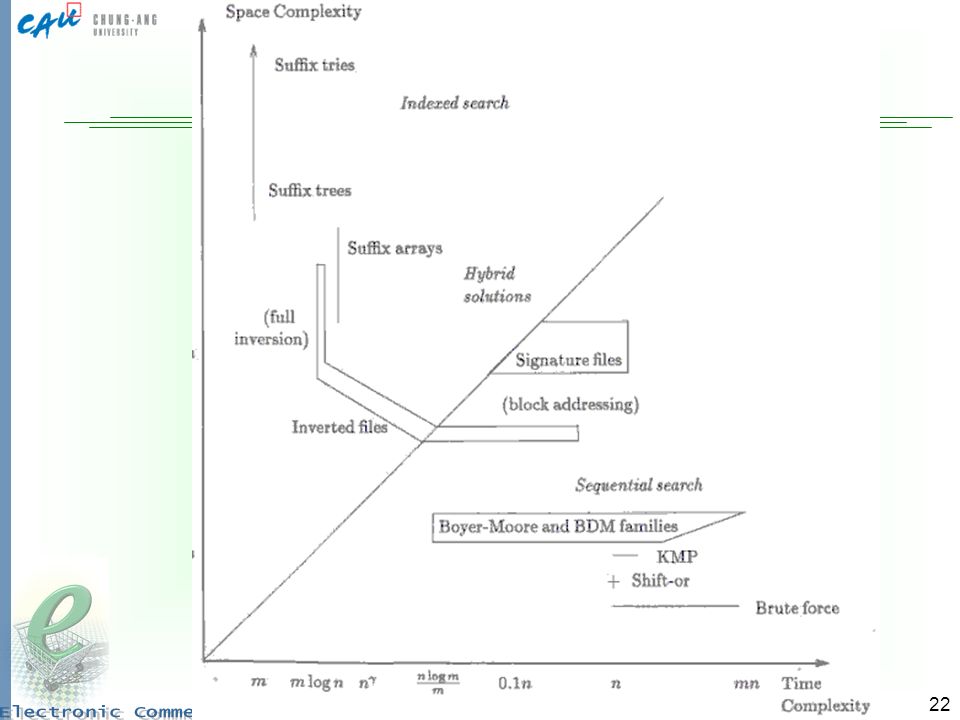
Previous Chapter: Conclusions
Main measures: Precision & Recall. For sets Rankings are evaluated through initial subsets There are measures that combine them into one Involve user-defined preferences Many (other) characteristics An algorithm can be good at some and bad at others Averages are used, but not always are meaningful Reference collection exists with known answers to evaluate new algorithms
 characteristics. An algorithm can be good at some and bad at others. Averages are used, but not always are meaningful. Reference collection exists with known answers to evaluate new algorithms.")
3
Previous Chapter: Research topics
Different types of interfaces Interactive systems: What measures to use? Such as infromativeness

4
Types of searching Indexed Sequential Combined Semi-static
Space overhead Sequential Small texts Volatile, or space limited Combined Index into large portions, then sequential inside portion Best combination of speed / overhead

5
Inverted files Vocabulary: sqrt (n). Heaps’ law. 1GB 5M
Occurrences: n * 40% (stopwords) positions (word, char), files, sections...
 positions (word, char), files, sections...")
6
Compression: Block addressing
Block addressing: 5% overhead 256, 64K, ..., blocks (1, 2, ..., bytes) Equal size (faster search) or logical sections (retrieval units)
 Equal size (faster search) or logical sections (retrieval units)")
7
Searching in inverted files
Vocabulary search Separate file Many searching techniques Lexicographic: log V (voc. size) = ½ log n (Heaps) Hashing is not good for prefix search Retrieval of occurrences Manipulation with occurrences: ~sqrt (n) (Heaps, Zipf) Boolean operations. Context search Merging occurrences For AND: One list is usually shorter (Zipf law) sublinear! Only inverted files allow sublinear both space & time Suffix trees and signature files don’t
 = ½ log n (Heaps) Hashing is not good for prefix search. Retrieval of occurrences. Manipulation with occurrences: ~sqrt (n) (Heaps, Zipf) Boolean operations. Context search. Merging occurrences. For AND: One list is usually shorter (Zipf law) sublinear! Only inverted files allow sublinear both space & time. Suffix trees and signature files don’t.")
8
Building inverted file: 1
Infinite memory? Use trie to store vocabulary. O(n) append positions Finite memory? Build in chunks, merge. Almost O(n) Insertion: index + merge. Deleting: O(n). Very fast.
 append positions. Finite memory Build in chunks, merge. Almost O(n) Insertion: index + merge. Deleting: O(n). Very fast.")
9
Suffix trees Text as one long string. No words.
Genetic databases Complex queries Compacted trie structure Problem: space For text retrieval, inverted files are better

11
Info for tree comes from the text itself

12
Suffix array All suffixes (by position) in lexicographic order
Allows binary search Much less space: 40% n Supra-index: sampling, for better disk access

13
Suffix tree and suffix array: Searching. Construction
Patterns, prefixes, phrases. Not only words Suffix tree: O(m), but: space (m = query size) Suffix array: O(log n) (n = database size) Construction of arrays: sorting Large text: n2 log (M)/M, more than for inverted files Skip details Addition: n n' log (M)/M. (n' is the size of new portion) Deletion: n
, but: space (m = query size) Suffix array: O(log n) (n = database size) Construction of arrays: sorting. Large text: n2 log (M)/M, more than for inverted files. Skip details. Addition: n n log (M)/M. (n is the size of new portion) Deletion: n.")
14
Signature files Usually worse than inverted files
Words are mapped to bit patterns Blocks are mapped to ORs of their word patterns If a block contains a word, all bits of its pattern are set Sequential search for blocks False drops! Design of the hash function Have to traverse the block Good to search ANDs or proximity queries bit patterns are ORed

15
False drop: letters in 2nd block

16
Boolean operations Merging file (occurrences) lists
AND: to find repetitions According to query syntax tree Complexity linear in intermediate results Can be slow if they are huge There are optimization techniques E.g.: merge small list with a big one by searching This is a usual case (Zipf)
")
17
Sequential search Necessary part of many algorithms (e.g., block addr)
Brute force: O(nm) worst-case, O(n) on average MANY faster algorithms, but more complicated See the book
 worst-case, O(n) on average. MANY faster algorithms, but more complicated. See the book.")
18
Approximate string matching
Match with k errors, select the one with min k Levenshtein distance between strings s1 and s2 The minimum number of editing operations to make one from another Symmetric for standard sets of operations Operations: deletion, addition, change Sometimes weighted Solution: dynamic programming. O(mn), O(kn) m, n are lengths of the two strings
, O(kn) m, n are lengths of the two strings.")
19
Regular expressions Regular expressions
Automation: O (m 2m) + O (n) – bad for long patterns There are better methods, see book Using indices to search for words with errors Inverted files: search in vocabulary Suffix trees and Suffix arrays: the same algorithms as for search without errors! Just allow deviations from the path
 + O (n) – bad for long patterns. There are better methods, see book. Using indices to search for words with errors. Inverted files: search in vocabulary. Suffix trees and Suffix arrays: the same algorithms as for search without errors! Just allow deviations from the path.")
20
Search over compression
Improves both space AND time (less disk operations) Compress query and search Huffman compression, words as symbols, bytes (frequencies: most frequent shorter) Search each word in the vocabulary its code More sophisticated algorithms Compressed inverted files: less disk less time Text and index compression can be combined
 Compress query and search. Huffman compression, words as symbols, bytes. (frequencies: most frequent shorter) Search each word in the vocabulary its code. More sophisticated algorithms. Compressed inverted files: less disk less time. Text and index compression can be combined.")
21
...compression Suffix trees can be compressed almost to size of suffix arrays Suffix arrays can’t be compressed (almost random), but can be constructed over compressed text instead of Huffman, use a code that respects alphabetic order almost the same compression Signature files are sparse, so can be compressed ratios up to 70%
, but can be constructed over compressed text. instead of Huffman, use a code that respects alphabetic order. almost the same compression. Signature files are sparse, so can be compressed. ratios up to 70%")
23
Research topics Perhaps, new details in integration of compression and search “Linguistic” indexing: allowing linguistic variations Search in plural or only singular Search with or without synonyms

24
Conclusions Inverted files seem to be the best option
Other structures are good for specific cases Genetic databases Sequential searching is an integral part of many indexing-based search techniques Many methods to improve sequential searching Compression can be integrated with search

25
Thank you! Till April 26, 6 pm

Similar presentations







: Multimedia.>")


, Mexico.>")





 Fang Wei-Kleiner.>")



