Download presentation
Presentation is loading. Please wait.

1
Building Petabyte Databases SQL+.Net
Jim Gray Microsoft research VSlive! SQL To The Max 15 February San Francisco Objects are closer than they appear in the mirror Objects are closer than they appear in the mirror PhotoServer: Tom Barclay Ya Feng Sung TerraServer USGS SkyServer Alex Szalay Ani Thakar Peter Kunszt Tanu Malik Jordan Raddick Don Slutz Jan vandenBerg Some Slides Robert Brunner

2
SQLserver™: Past and Future History
XML Replication x, y, z,… Auto Admin Data Transformation OLAP Data Mining Text Indexing English Query Partitioning Clusters .Net XML schema support updategrams More xPath support SPs and templates as web services SQL 200x Beta late this year Trustworthy: Availability Privacy Security CLR (objects) XML (xQuery,….) Unify Files & Records Manageability, Scalability WebReference.soap proxy = new WebReference.soap(); object[] results1 = proxy.StoredProcedure (inParam, ref inoutParam, out returnValue); object[] results2 = proxy.Template(inParam);
 XML (xQuery,….) Unify Files & Records. Manageability, Scalability. WebReference.soap proxy = new WebReference.soap(); object[] results1 = proxy.StoredProcedure (inParam, ref inoutParam, out returnValue); object[] results2 = proxy.Template(inParam);")
3
Outline We will be able to store everything,
How do we represent it? (objects) How will we find it (aka: who cares?) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService Why put everything in the database? A prototypical Web Service. SkyServer and the World Wide Telescope Data Mining science data Serving Windows/Macintosh/Unix clients with .Net Federating Archives with .Net
 How will we find it (aka: who cares ) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService. Why put everything in the database A prototypical Web Service. SkyServer and the World Wide Telescope. Data Mining science data. Serving Windows/Macintosh/Unix clients with .Net. Federating Archives with .Net.")
4
Record Everything? What’s that?
Yotta Zetta Exa Peta Tera Giga Mega Kilo Record Everything? What’s that? Everything! Recorded Disks will get 100x to 1,000x more capacity 10x to 30x more bandwidth. Other technologies in the wings: mram,mems, … The 20TB … 200TB disk drive! Library of Congress (books) A billion photos 2…20 years of video (continuous) All Books MultiMedia All LoC books (words) .Movie A Photo See Mike Lesk: How much information is there: See Lyman & Varian: How much information A Book
 A billion photos. 2…20 years of video (continuous) All Books MultiMedia. All LoC books. (words) .Movie. A Photo. See Mike Lesk: How much information is there: See Lyman & Varian: How much information. A Book.")
5
Why Put Everything in Cyberspace?
Low rent min $/byte Shrinks time now or later Shrinks space here or there Automate processing knowbots Point-to-Point OR Broadcast Immediate OR Time Delayed Locate Process Analyze Summarize

6
Most storage is personal
90% of disks are IDE/ATA 85% of bytes are Gordon Bell’s shoebox: Scans 20 k “pages” 300 dpi 1 GB Music: 2 k “tacks” 7 GB Photos: 13 k images 2 GB Video: 10 hrs 3 GB Docs: 3 k ppt, word,.. 2 GB Mail: 50 k messages 2 GB 16 GB

7
How will we find it? Put everything in the DB (and index it)
More than a file system Unifies data and meta-data Simpler to manage Easier to subset and reorganize Set-oriented access Allows online updates Automatic indexing Automatic replication SQL SQL

8
How do we represent it to the outside world?
<?xml version="1.0" encoding="utf-8" ?> - <DataSet xmlns=" - <xs:schema id="radec" xmlns="" xmlns:xs=" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"> <xs:element name="radec" msdata:IsDataSet="true"> <xs:element name="Table"> <xs:element name="ra" type="xs:double" minOccurs="0" /> <xs:element name="dec" type="xs:double" minOccurs="0" /> … - <diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1"> - <radec xmlns=""> - <Table diffgr:id="Table1" msdata:rowOrder="0"> <ra> </ra> <dec> </dec> </Table> - <Table diffgr:id="Table10" msdata:rowOrder="9"> <ra> </ra> <dec> </dec> </Table> </radec> </diffgr:diffgram> </DataSet> File metaphor too primitive: just a blob Table metaphor too primitive: just records Need Metadata describing data context Format Providence (author/publisher/ citations/…) Rights History Related documents In a standard format XML and XML schema DataSet is great example of this World is now defining standard schemas schema Data or difgram
 Rights. History. Related documents. In a standard format. XML and XML schema. DataSet is great example of this. World is now defining standard schemas. schema. Data or. difgram.")
9
There is a problem: Need Standard Data AND Methods
Niklaus Wirth: Algorithms + Data Structures = Programs XML data is GREAT!!!! XML documents are portable objects XML documents are complex objects WSDL defines the methods on objects (the class) But will all the implementations match? Think of UNIX or SQL or C or… We need conformance tests. That’s why Web Services Interoperability is so important.
 But will all the implementations match Think of UNIX or SQL or C or… We need conformance tests. That’s why Web Services Interoperability is so important.")
10
Outline We will be able to store everything,
How do we represent it? (objects) How will we find it (aka: who cares?) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService Why put everything in the database? A prototypical Web Service. SkyServer and the World Wide Telescope Data Mining science data Serving Windows/Macintosh/Unix clients with .Net Federating Archives with .Net
 How will we find it (aka: who cares ) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService. Why put everything in the database A prototypical Web Service. SkyServer and the World Wide Telescope. Data Mining science data. Serving Windows/Macintosh/Unix clients with .Net. Federating Archives with .Net.")
11
PhotoServer: Managing Photos
Load all photos into the database Annotate the photos View by various attributes Do similarity Search Use XML for interchange Use dbObject, Template for access SQL, Templates, XML data IIS jScript XML datasets & mime data Templates Schema DOM SQL (for xml)
")
12
How Similarity Search Works
For each picture Loader Inserts thumbnails Extracts 270 Features into a blob When looking for similar picture Scan all photos comparing features (dot product of vectors) Sort by similarity Feature blob is an array Today I fake the array with functions and cast cast(substring(feature,72,8) as float) When SQL Server gets C#, we won’t have to fake it. And… it will run 100x faster (compiled managed code). Idea pioneered by IBM Research, we use a variant by MS Beijing Research. many black squares 10% orange …etc No black squares 20% orange …etc 72% match 27% match
 Sort by similarity. Feature blob is an array. Today I fake the array with functions and cast cast(substring(feature,72,8) as float) When SQL Server gets C#, we won’t have to fake it. And… it will run 100x faster (compiled managed code). Idea pioneered by IBM Research, we use a variant by MS Beijing Research. many black squares. 10% orange. …etc. No black squares. 20% orange. …etc. 72% match. 27% match.")
13
Things I Learned from PhotoServer
Data: XML data sets are a universal way to represent answers XML data sets minimize round trips: 1 request/response Search It is BEST to index You can put objects and attributes in a row (SQL puts big blobs off-page) If you can’t index, You can extract attributes and quickly compare SQL can scan at 2M records/cpu/second Sequential scans are embarrassingly parallel.
 If you can’t index, You can extract attributes and quickly compare. SQL can scan at 2M records/cpu/second. Sequential scans are embarrassingly parallel.")
14
Outline We will be able to store everything,
How do we represent it? (objects) How will we find it (aka: who cares?) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService Why put everything in the database? A prototypical Web Service. SkyServer and the World Wide Telescope Data Mining science data Serving Windows/Macintosh/Unix clients with .Net Federating Archives with .Net
 How will we find it (aka: who cares ) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService. Why put everything in the database A prototypical Web Service. SkyServer and the World Wide Telescope. Data Mining science data. Serving Windows/Macintosh/Unix clients with .Net. Federating Archives with .Net.")
15
Big! Servers ScaleUP: a BIG box ScaleOut: computing by the slice
SMP (32 cpus) 64 bit ScaleOut: computing by the slice 6 years ago: 8ktpmC, today 750ktpmC SQL Server is #1, #2, #3 (Windows is best DB2 platform too) VLDB Management Availability: Clusters, remote logging, replication
 64 bit. ScaleOut: computing by the slice. 6 years ago: 8ktpmC, today 750ktpmC. SQL Server is #1, #2, #3 (Windows is best DB2 platform too) VLDB Management. Availability: Clusters, remote logging, replication.")
16
TPC measures peak performance and Price/Performance
SQL Server always had best price Performance Now best of both (using scaleout) SMP performance also impressive 32x8 900Mhz Xenon 256GB ram 59 TB disk Rank Company System tpmC price/tpmC Database OS TP Mon Date 1 ProLiant DL P 709,220 14.96US$ Microsoft SQL Server 2000 Enterprise Microsoft Windows 2000 Advanced COM+ 09/19/01 2 IBM eSeries370 c/s 688,220 22.58US$ Microsoft SQL Server 2000 Datacenter 04/10/01 3 ProLiant DL P 567,882 14.04US$ Microsoft SQL Server 2000 Enterprise 7 HP HP 9000 Superdome 389,435 21.24US$ Oracle 9i Enterprise HP UX 11.i 64-bit BEA Tuxedo6.4 12/21/01 14 Unisys Enterprise Server ES7000 165,219 21.33US$ Datacenter LE COM+ Source: 32 900Mhz Xeon 64GB ram 15TB disk
 SMP performance also impressive. 32x8 900Mhz Xenon. 256GB ram. 59 TB disk. Rank. Company. System. tpmC. price/tpmC. Database. OS. TP Mon. Date. 1 ProLiant DL P 709, US$ Microsoft SQL Server 2000 Enterprise. Microsoft. Windows Advanced COM+ 09/19/01 2 IBM. eSeries370. c/s 688, US$ Microsoft SQL Server 2000 Datacenter 04/10/01 3 ProLiant DL P 567, US$ Microsoft SQL Server 2000 Enterprise 7. HP. HP 9000 Superdome. 389, US$ Oracle 9i Enterprise. HP UX 11.i 64-bit. BEA Tuxedo /21/ Unisys. Enterprise Server ES , US$ Datacenter LE COM+ Source: Mhz Xeon 64GB ram. 15TB disk.")
17
Scale Out: Buy Computing by the Slice 709,202 tpmC
Scale Out: Buy Computing by the Slice 709,202 tpmC! == 1 Billion transactions/day Slice: 8cpu, 8GB, 100 disks (=1.8TB) 20ktpmC per slice, ~300k$/slice clients and 4 DTC nodes not shown
 20ktpmC per slice, ~300k$/slice. clients and 4 DTC nodes not shown.")
18
ScaleUp: A Very Big System!
UNISYS Windows 2000 Data Center Limited Edition 32 cpus on 32 GB of RAM and 1,061 disks (15.5 TB) Will be helped by 64bit addressing 24 fiber channel
 Will be helped by 64bit addressing. 24. fiber. channel.")
19
Outline We will be able to store everything,
How do we represent it? (objects) How will we find it (aka: who cares?) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService Why put everything in the database? A prototypical Web Service. SkyServer and the World Wide Telescope Data Mining science data Serving Windows/Macintosh/Unix clients with .Net Federating Archives with .Net
 How will we find it (aka: who cares ) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService. Why put everything in the database A prototypical Web Service. SkyServer and the World Wide Telescope. Data Mining science data. Serving Windows/Macintosh/Unix clients with .Net. Federating Archives with .Net.")
20
TerraServer – A SQL poster child http://TerraServer. HomeAdvisor
3 x 2 TB databases 18TB disk tri-plexed (=6TB) 3 + 1 Cluster 99.96% uptime 1B page views 5B DB queries Now a .NET web service
 Cluster % uptime. 1B page views 5B DB queries. Now a .NET web service.")
21
USGS Aerial photos “DOQ”
Image Data 12 TB 95 % U.S. Coverage 1 m resolution 1 TB 100% U.S. Coverage 2 m resolution USGS Topo Maps USGS Aerial photos “DOQ” All in the database 200x200 pixel tiles compressed Spatial access z-Tranform Btree Encarta Virtual Globe 1 Km resolution 100 % World Coverage

22
TerraServer Traffic & Database Growth
Sessions Page Views Image Tiles Db Queries Bytes Xfered Average Day 44,320 879,720 3,786,551 4,566,024 59 GB Peak Day 277,292 12,388,104 10,475,674 163 GB 2,401,209 44,851,547 890,277087 3,831,989,887 4,620,815,913 59 TB Jan 2002 900 m Rows SQL TB Db 678 m Rows SQL TB Db SQL TB Db SQL Server 1.5 TB Db SQL Server .8 TB Db 298 m Rows SQL TB Db 231 m Rows SQL TB Db SQL TB Db 217 m Rows SQL TB Db SQL TB Db 173 m Rows SQL TB Db SQL TB Db 1 Server / Win NT 4.0 EE 2nd Server / Win 2k DataCenter 4 Node / Win2k Datacenter Failover Cluster

23
8 Compaq DL360 “Photon” Web Servers 4 Compaq ProLiant 8500 Db Servers
Hardware 8 Compaq DL360 “Photon” Web Servers One SQL database per rack Each rack contains 4.5 tb 261 total drives / 13.7 TB total 2200 Fiber SAN Switches E J O Meta Data Stored on 101 GB “Fast, Small Disks” (18 x 18.2 GB) SQL\Inst1 F G L K P Q Imagery Data Stored on GB “Slow, Big Disks” (15 x 73.8 GB) SQL\Inst2 I H M N R S SQL\Inst3 To Add GB Disks in Feb 2001 to create 18 TB SAN Spare 4 Compaq ProLiant 8500 Db Servers
 SQL\Inst1. F. G. L. K. P. Q. Imagery Data. Stored on GB. Slow, Big Disks (15 x 73.8 GB) SQL\Inst2. I. H. M. N. R. S. SQL\Inst3. To Add GB. Disks in Feb to create 18 TB SAN. Spare. 4 Compaq ProLiant 8500 Db Servers.")
24
TerraServer Lessons Learned
Hardware is 5 9’s (with clustering) Software is 5 9’s (with clustering) Admin is 4 9’s (offline maintenance) Network is 3 9’s (mistakes, environment) Simple designs are best 10 TB DB is management limit 1 PB = 100 x 10 TB DB this is 100x better than 5 years ago. Minimize use of tape Backup to disk (snapshots) Portable disk TBs 9 9 9 9
 Software is 5 9’s (with clustering) Admin is 4 9’s (offline maintenance) Network is 3 9’s (mistakes, environment) Simple designs are best. 10 TB DB is management limit 1 PB = 100 x 10 TB DB this is 100x better than 5 years ago. Minimize use of tape. Backup to disk (snapshots) Portable disk TBs")
25
TerraService http://TerraService.Net/
Added .NET web services to TerraServer A great way to learn what Web Services are And what .Net is. Image server Gives arbitrary rectangle/zoom of US Overlays features (hospitals, schools,..) Census service You can use it in your app. USDA is using it today. Demo Tour API Demo map maker Mention location and census services
 Census service. You can use it in your app. USDA is using it today. Demo. Tour API. Demo map maker. Mention location and census services.")
26
Outline We will be able to store everything,
How do we represent it? (objects) How will we find it (aka: who cares?) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService Why put everything in the database? A prototypical Web Service. SkyServer and the World Wide Telescope Data Mining science data Serving Windows/Macintosh/Unix clients with .Net Federating Archives with .Net
 How will we find it (aka: who cares ) PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService. Why put everything in the database A prototypical Web Service. SkyServer and the World Wide Telescope. Data Mining science data. Serving Windows/Macintosh/Unix clients with .Net. Federating Archives with .Net.")
27
Computational Science The Third Science Branch is Evolving
In the beginning science was empirical. Then theoretical branches evolved. Now, we have computational branches. Has primarily been simulation Growth area data analysis/visualization of peta-scale instrument data. Computational Science Data captured by instruments Or data generated by simulator Processed by software Placed in a database / files Scientist analyzes database / files

28
Exploring Parameter Space Manual or Automatic Data Mining
There is LOTS of data people cannot examine most of it. Need computers to do analysis. Manual or Automatic Exploration Manual: person suggests hypothesis, computer checks hypothesis Automatic: Computer suggests hypothesis person evaluates significance Given an arbitrary parameter space: Data Clusters Points between Data Clusters Isolated Data Clusters Isolated Data Groups Holes in Data Clusters Isolated Points Nichol et al. 2001 Slide courtesy of and adapted from Robert CalTech.

29
What’s needed? (not drawn to scale)
Scientists Miners Data Mining Algorithms Science Data & Questions Plumbers Tools Databases to Store Data And Execute Queries Question & Answer Visualization

30
Some science is hitting a wall FTP and GREP are not adequate
You can GREP 1 MB in a second You can GREP 1 GB in a minute You can GREP 1 TB in 2 days You can GREP 1 PB in 3 years. Oh!, and 1PB ~10,000 disks At some point you need indices to limit search parallel data search and analysis This is where databases can help Goal Make it easy to Publish: Record structured data Find: Find data anywhere in the network Get the subset you need Explore datasets interactively You can FTP 1 MB in 1 sec You can FTP 1 GB / min (= 1 $/GB) … days and 1K$ … 3 years and 1M$
 … 2 days and 1K$ … 3 years and 1M$")
31
Web Services are The Key
Your program Web Server Web SERVER: Given a url + parameters Returns a web page (often dynamic) Web SERVICE: Given a XML document (soap msg) Returns an XML document Tools make this look like an RPC. F(x,y,z) returns (u, v, w) Distributed objects for the web. + naming, discovery, security,.. Internet-scale distributed computing http Web page Your program Web Service soap Data In your address space object in xml
 Web SERVICE: Given a XML document (soap msg) Returns an XML document. Tools make this look like an RPC. F(x,y,z) returns (u, v, w) Distributed objects for the web. + naming, discovery, security,.. Internet-scale distributed computing. http. Web page. Your. program. Web. Service. soap. Data. In your address space. object in xml.")
32
Data Federations of Web Services
Massive datasets live near their owners: Near the instrument’s software pipeline Near the applications Near data knowledge and curation Super Computer centers become Super Data Centers Each Archive publishes a web service Schema: documents the data Methods on objects (queries) Scientists get “personalized” extracts Uniform access to multiple Archives A common global schema Federation
 Scientists get personalized extracts. Uniform access to multiple Archives. A common global schema. Federation.")
33
Why Astronomy Data? It has no commercial value
IRAS 25m 2MASS 2m It has no commercial value No privacy concerns Can freely share results with others Great for experimenting with algorithms It is real and well documented High-dimensional data (with confidence intervals) Spatial data Temporal data Many different instruments from Many different places and Many different times Federation is a goal The questions are interesting How did the universe form? There is a lot of it (petabytes) DSS Optical IRAS 100m WENSS 92cm NVSS 20cm GB 6cm ROSAT ~keV
 Spatial data. Temporal data. Many different instruments from Many different places and Many different times. Federation is a goal. The questions are interesting. How did the universe form There is a lot of it (petabytes) DSS Optical. IRAS 100m. WENSS 92cm. NVSS 20cm. GB 6cm. ROSAT ~keV.")
34
The Internet will be the world’s best telescope:
Web Services & Grid Enable Virtual Observatory The Internet will be the world’s best telescope: It has data on every part of the sky In every measured spectral band: optical, x-ray, radio.. As deep as the best instruments (2 years ago). It is up when you are up. The “seeing” is always great (no working at night, no clouds no moons no..). It’s a smart telescope: links objects and data to literature on them. W3C & IETF standards Provide Naming Authorization / Security / Privacy Distributed Objects Discovery, Definition, Invocation, Object Model Higher level services: workflow, transactions, DB,..
. It is up when you are up. The seeing is always great (no working at night, no clouds no moons no..). It’s a smart telescope: links objects and data to literature on them. W3C & IETF standards Provide. Naming. Authorization / Security / Privacy. Distributed Objects. Discovery, Definition, Invocation, Object Model. Higher level services: workflow, transactions, DB,..")
35
Steps to Virtual Observatory Prototype
Define a set of Astronomy Objects and methods. Based on UDDI, WSDL, XSL, SOAP, dataSet Use them locally to debug ideas Schema, Units,… Dataset problems Typical use scenarios. Federate different archives Each archive is a web service Global query tool accesses them Working on this plan with Sloan Digital Sky Survey and CalTech/Palomar. Especially Alex Szalay et. al. at JHU

36
Sloan Digital Sky Survey http://www.sdss.org/
For the last 12 years astronomers have been building a telescope (with funding from Sloan Foundation, NSF, and a dozen universities). 90M$. Y2000: engineer, calibrate, commission: now public data. 5% of the survey, 600 sq degrees, 15 M objects 60GB, ½ TB raw. This data includes most of the known high z quasars. It has a lot of science left in it but…. New the data is arriving: 250GB/nite (20 nights per year) = 5TB/y. 100 M stars, 100 M galaxies, 1 M spectra.
. 90M$. Y2000: engineer, calibrate, commission: now public data. 5% of the survey, 600 sq degrees, 15 M objects 60GB, ½ TB raw. This data includes most of the known high z quasars. It has a lot of science left in it but…. New the data is arriving: 250GB/nite (20 nights per year) = 5TB/y. 100 M stars, 100 M galaxies, 1 M spectra.")
37
Demo of Sky Server http://skyserver.sdss.org/ Demo sky server
Demo Explorer Explain need for Unix/Mac clients Demo Java SQLQA? Talk about federation plan. Work is product of Alex Johns Hopkins Tanu Malik did SQLQA.

38
Two kinds of SDSS data in an SQL DB (objects and images all in DB)
15M Photo Objects ~ 400 attributes 50K Spectra with ~30 lines/ spectrum

39
Spatial Data Access – SQL extension (Szalay, Kunszt, Brunner) http://www.sdss.jhu.edu/htm
Added Hierarchical Triangular Mesh (HTM) table-valued function for spatial joins. Every object has a 20-deep Mesh ID. Given a spatial definition: Routine returns up to ~10 covering triangles. Spatial query is then up to ~10 range queries. Very fast: 10,000 triangles / second / cpu. Based onSQL Server Extended Stored Procedure 2
 table-valued function for spatial joins. Every object has a 20-deep Mesh ID. Given a spatial definition: Routine returns up to ~10 covering triangles. Spatial query is then up to ~10 range queries. Very fast: 10,000 triangles / second / cpu. Based onSQL Server Extended Stored Procedure")
40
Data Loading JavaScript of DB loader (DTS)
Web ops interface & workflow system Data ingest and scrubbing is major effort Test data quality Chase down bugs / inconsistencies Other major task is data documentation Explain the data Explain the schema and functions. If we supported users, …

41
Scenario Design Astronomers proposed 20 questions
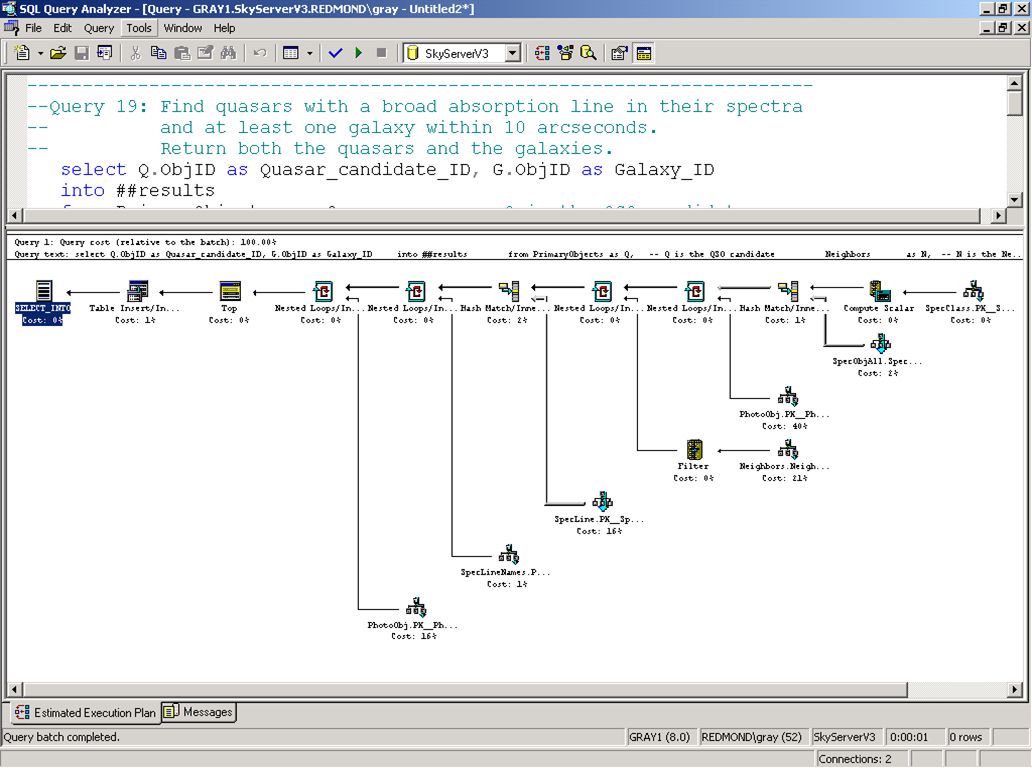
Typical of things they want to do Each would require a week of programming in tcl / C++/ FTP Goal, make it easy to answer questions DB and tools design motivated by this goal Implemented utility procedures JHU Built GUI for Linux clients Q11: Find all elliptical galaxies with spectra that have an anomalous emission line. Q12: Create a grided count of galaxies with u-g>1 and r<21.5 over 60<declination<70, and 200<right ascension<210, on a grid of 2’, and create a map of masks over the same grid. Q13: Create a count of galaxies for each of the HTM triangles which satisfy a certain color cut, like 0.7u-0.5g-0.2i<1.25 && r<21.75, output it in a form adequate for visualization. Q14: Find stars with multiple measurements and have magnitude variations >0.1. Scan for stars that have a secondary object (observed at a different time) and compare their magnitudes. Q15: Provide a list of moving objects consistent with an asteroid. Q16: Find all objects similar to the colors of a quasar at 5.5<redshift<6.5. Q17: Find binary stars where at least one of them has the colors of a white dwarf. Q18: Find all objects within 30 arcseconds of one another that have very similar colors: that is where the color ratios u-g, g-r, r-I are less than 0.05m. Q19: Find quasars with a broad absorption line in their spectra and at least one galaxy within 10 arcseconds. Return both the quasars and the galaxies. Q20: For each galaxy in the BCG data set (brightest color galaxy), in 160<right ascension<170, -25<declination<35 count of galaxies within 30"of it that have a photoz within 0.05 of that galaxy. Q1: Find all galaxies without unsaturated pixels within 1' of a given point of ra=75.327, dec=21.023 Q2: Find all galaxies with blue surface brightness between and 23 and 25 mag per square arcseconds, and -10<super galactic latitude (sgb) <10, and declination less than zero. Q3: Find all galaxies brighter than magnitude 22, where the local extinction is >0.75. Q4: Find galaxies with an isophotal surface brightness (SB) larger than 24 in the red band, with an ellipticity>0.5, and with the major axis of the ellipse having a declination of between 30” and 60”arc seconds. Q5: Find all galaxies with a deVaucouleours profile (r¼ falloff of intensity on disk) and the photometric colors consistent with an elliptical galaxy. The deVaucouleours profile Q6: Find galaxies that are blended with a star, output the deblended galaxy magnitudes. Q7: Provide a list of star-like objects that are 1% rare. Q8: Find all objects with unclassified spectra. Q9: Find quasars with a line width >2000 km/s and 2.5<redshift<2.7. Q10: Find galaxies with spectra that have an equivalent width in Ha >40Å (Ha is the main hydrogen spectral line.)
 and compare their magnitudes. Q15: Provide a list of moving objects consistent with an asteroid. Q16: Find all objects similar to the colors of a quasar at 5.5<redshift<6.5. Q17: Find binary stars where at least one of them has the colors of a white dwarf. Q18: Find all objects within 30 arcseconds of one another that have very similar colors: that is where the color ratios u-g, g-r, r-I are less than 0.05m. Q19: Find quasars with a broad absorption line in their spectra and at least one galaxy within 10 arcseconds. Return both the quasars and the galaxies. Q20: For each galaxy in the BCG data set (brightest color galaxy), in 160<right ascension<170, -25<declination<35 count of galaxies within 30 of it that have a photoz within 0.05 of that galaxy. Q1: Find all galaxies without unsaturated pixels within 1 of a given point of ra=75.327, dec= Q2: Find all galaxies with blue surface brightness between and 23 and 25 mag per square arcseconds, and -10<super galactic latitude (sgb) <10, and declination less than zero. Q3: Find all galaxies brighter than magnitude 22, where the local extinction is >0.75. Q4: Find galaxies with an isophotal surface brightness (SB) larger than 24 in the red band, with an ellipticity>0.5, and with the major axis of the ellipse having a declination of between 30 and 60 arc seconds. Q5: Find all galaxies with a deVaucouleours profile (r¼ falloff of intensity on disk) and the photometric colors consistent with an elliptical galaxy. The deVaucouleours profile. Q6: Find galaxies that are blended with a star, output the deblended galaxy magnitudes. Q7: Provide a list of star-like objects that are 1% rare. Q8: Find all objects with unclassified spectra. Q9: Find quasars with a line width >2000 km/s and 2.5<redshift<2.7. Q10: Find galaxies with spectra that have an equivalent width in Ha >40Å (Ha is the main hydrogen spectral line.)")
42
An easy one Q7: Provide a list of rare star-like objects.
Found 14,681 buckets, first 140 buckets have 99% time 62 seconds CPU bound 226 k records/second (2 cpu) KB/s. Select cast((u-g) as int) as ug, cast((g-r) as int) as gr, cast((r-i) as int) as ri, cast((i-z) as int) as iz, count(*) as Population from stars group by cast((u-g) as int), cast((g-r) as int), cast((r-i) as int), cast((i-z) as int) order by count(*)
 250 KB/s. Select cast((u-g) as int) as ug, cast((g-r) as int) as gr, cast((r-i) as int) as ri, cast((i-z) as int) as iz, count(*) as Population. from stars. group by cast((u-g) as int), cast((g-r) as int), cast((r-i) as int), cast((i-z) as int) order by count(*)")
43
An Easy One Q15: Find asteroids
Sounds hard but there are 5 pictures of the object at 5 different times (color filters) and so can “see” velocity. Image pipeline computes velocity. Computing it from the 5 color x,y would also be fast Finds 1,303 objects in 3 minutes, 140MBps. (could go 2x faster with more disks) select objId, dbo.fGetUrlEq(ra,dec) as url --return object ID & url sqrt(power(rowv,2)+power(colv,2)) as velocity from photoObj check each object. where (power(rowv,2) + power(colv, 2)) square of velocity between 50 and huge values =error
 and so can see velocity. Image pipeline computes velocity. Computing it from the 5 color x,y would also be fast. Finds 1,303 objects in 3 minutes, 140MBps. (could go 2x faster with more disks) select objId, dbo.fGetUrlEq(ra,dec) as url --return object ID & url. sqrt(power(rowv,2)+power(colv,2)) as velocity. from photoObj -- check each object. where (power(rowv,2) + power(colv, 2)) -- square of velocity. between 50 and huge values =error.")
44
Q15: Fast Moving Objects Find near earth asteroids:
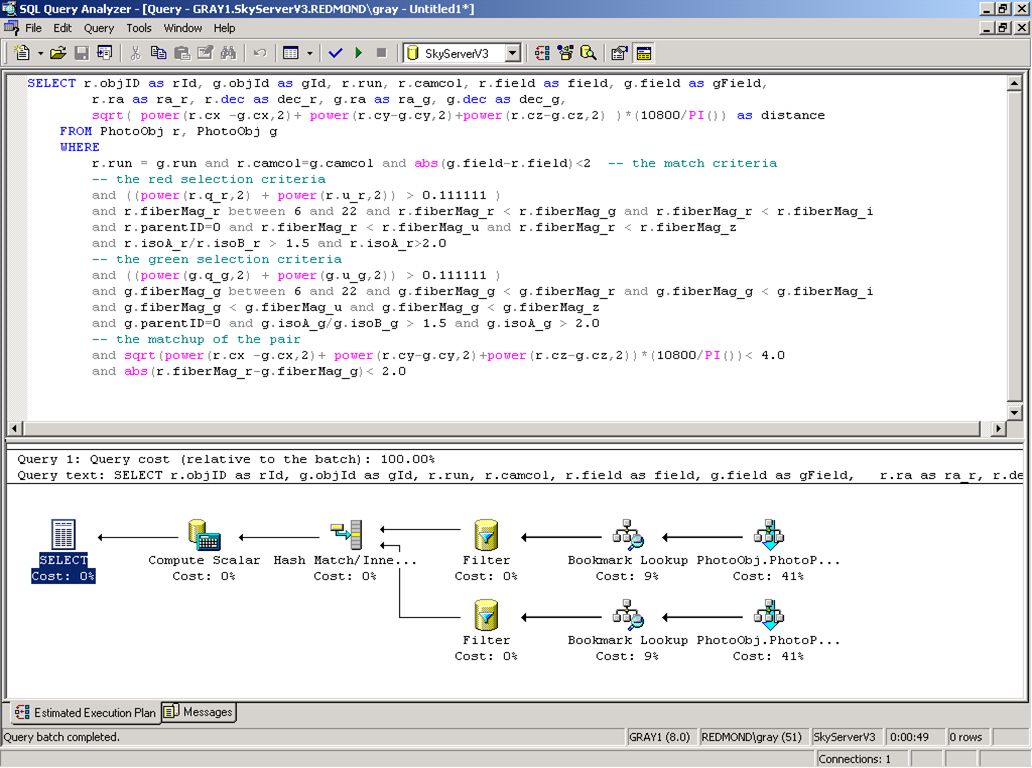
Finds 3 objects in 11 minutes (or 52 seconds with an index) Ugly, but consider the alternatives (c programs an files and…) SELECT r.objID as rId, g.objId as gId, dbo.fGetUrlEq(g.ra, g.dec) as url FROM PhotoObj r, PhotoObj g WHERE r.run = g.run and r.camcol=g.camcol and abs(g.field-r.field)<2 -- nearby -- the red selection criteria and ((power(r.q_r,2) + power(r.u_r,2)) > ) and r.fiberMag_r between 6 and 22 and r.fiberMag_r < r.fiberMag_g and r.fiberMag_r < r.fiberMag_i and r.parentID=0 and r.fiberMag_r < r.fiberMag_u and r.fiberMag_r < r.fiberMag_z and r.isoA_r/r.isoB_r > 1.5 and r.isoA_r>2.0 -- the green selection criteria and ((power(g.q_g,2) + power(g.u_g,2)) > ) and g.fiberMag_g between 6 and 22 and g.fiberMag_g < g.fiberMag_r and g.fiberMag_g < g.fiberMag_i and g.fiberMag_g < g.fiberMag_u and g.fiberMag_g < g.fiberMag_z and g.parentID=0 and g.isoA_g/g.isoB_g > 1.5 and g.isoA_g > 2.0 -- the matchup of the pair and sqrt(power(r.cx -g.cx,2)+ power(r.cy-g.cy,2)+power(r.cz-g.cz,2))*(10800/PI())< 4.0 and abs(r.fiberMag_r-g.fiberMag_g)< 2.0
 Ugly, but consider the alternatives (c programs an files and…) SELECT r.objID as rId, g.objId as gId, dbo.fGetUrlEq(g.ra, g.dec) as url. FROM PhotoObj r, PhotoObj g. WHERE r.run = g.run and r.camcol=g.camcol and abs(g.field-r.field)<2 -- nearby. -- the red selection criteria. and ((power(r.q_r,2) + power(r.u_r,2)) > ) and r.fiberMag_r between 6 and 22 and r.fiberMag_r < r.fiberMag_g and r.fiberMag_r < r.fiberMag_i. and r.parentID=0 and r.fiberMag_r < r.fiberMag_u and r.fiberMag_r < r.fiberMag_z. and r.isoA_r/r.isoB_r > 1.5 and r.isoA_r> the green selection criteria. and ((power(g.q_g,2) + power(g.u_g,2)) > ) and g.fiberMag_g between 6 and 22 and g.fiberMag_g < g.fiberMag_r and g.fiberMag_g < g.fiberMag_i. and g.fiberMag_g < g.fiberMag_u and g.fiberMag_g < g.fiberMag_z. and g.parentID=0 and g.isoA_g/g.isoB_g > 1.5 and g.isoA_g > the matchup of the pair. and sqrt(power(r.cx -g.cx,2)+ power(r.cy-g.cy,2)+power(r.cz-g.cz,2))*(10800/PI())< 4.0. and abs(r.fiberMag_r-g.fiberMag_g)<")
45
http://gray. microsoft. com/~gray/talks/PetabyteDatabasesSql+. Net1
46
http://gray. microsoft. com/~gray/talks/PetabyteDatabasesSql+. Net1

47
http://gray. microsoft. com/~gray/talks/PetabyteDatabasesSql+. Net1
48
Performance (on current SDSS data)
Run times: on 15k$ COMPAQ Server (2 cpu, 1 GB , 8 disk) Some take 10 minutes Some take 1 minute Median ~ 22 sec. Ghz processors are fast! (10 mips/IO, 200 ins/byte) 2.5 m rec/s/cpu ~1,000 IO/cpu sec ~ 64 MB IO/cpu sec
 Some take 10 minutes. Some take 1 minute. Median ~ 22 sec. Ghz processors are fast! (10 mips/IO, 200 ins/byte) 2.5 m rec/s/cpu. ~1,000 IO/cpu sec ~ 64 MB IO/cpu sec.")
49
Sequential Scan Speed is Important
In high-dimension data, best way is to search. Sequential scan covering index is 10x faster Seconds vs minutes SQL scans at 2M records/s/cpu (!)
")
50
What we learned from the 20 Queries
All have fairly short SQL programs -- a substantial advance over (tcl, C++) Many are sequential one-pass and two-pass over data Covering indices make scans run fast Table valued functions are wonderful but limitations are painful. Counting, Binning, Histograms VERY common Spatial indices helpful, Materialized view (Neighbors) helpful.
 Many are sequential one-pass and two-pass over data. Covering indices make scans run fast. Table valued functions are wonderful but limitations are painful. Counting, Binning, Histograms VERY common. Spatial indices helpful, Materialized view (Neighbors) helpful.")
51
Cosmo: Computing the Cosmological Constant
Compares simulated galaxy distribution to observed distribution Measure distance between each pair of galaxies A lot of work (108 x 108 = 1016 steps) Good algorithms make this ~Nlog2N Needs LARGE main memory Using Itanium donated by Compaq and SQL server for data store (this is Alex Szalay, Adrian Pope,… of JHU). decade year month week day
 Good algorithms make this ~Nlog2N. Needs LARGE main memory. Using Itanium donated by Compaq and SQL server for data store. (this is Alex Szalay, Adrian Pope,… of JHU). decade. year. month. week. day.")
52
Summary We will be able to store everything,
The challenge is organizing and finding answers. PhotoServer: Objects vs records vs files, XML++ gives us portable objects. Similarity search: better than nothing! Scalability: a solved problem, but… Trustworthy & Manageable is not. TerraServer and TerraService Why put everything in the database? A prototypical Web Service. SkyServer and the World Wide Telescope Data Mining science data Serving Windows/Macintosh/Unix clients with .Net Federating Archives with .Net

53
References These Slides http://research.Microsoft.com/~Gray/talks/
TerraServer & TerraService Virtual Observatory (aka World Wide Telescope) SkyServer See documents at Download “personal SkyServer” (1GB)
 SkyServer. See documents at Download personal SkyServer (1GB)")
Similar presentations




 Ltd>")














