Download presentation
Presentation is loading. Please wait.

1
Regression Discontinuity Design

2
Basics Two potential outcomes Yi(0) and Yi(1), causal effect Yi(1) − Yi(0), binary treatment indicator Wi, covariate Xi, and the observed outcome equal to: At Xi = c incentives to participate change. Two cases, Sharp Regression Discontinuity: (SRD) and Fuzzy Regression Discontinuity Design: (FRD)
 and Fuzzy Regression Discontinuity Design: (FRD).")
3
Outline Introduction Basics Graphical Analyses Local Linear Regression Choosing the Bandwidth Variance Estimation Specification Checks

4
RD History In the beginning there was Thislethwaite and Campbell (1960) Only a few economists were involved initially (Goldberger, 1972) Then RDD went into hibernation It recently experienced a renaissance among economists (e.g. Hahn, Todd and van der Klaauw, 2001; Jacob and Lefgren, 2002) Tom Cook has written about this story
 Tom Cook has written about this story.")
5
Recent applications in politics include analyses of the incumbency effect (Lee, 2008), electoral competition on policy (Lee, Moretti, and Butler 2004), the effect of gender on legislator behavior (Rehavi nd), the value of a seat in the legisalture (Eggers and Hainmueller 2009), the effect of mayoral party ID on policy (Ferreria and Gyourko 2009). Recent important theoretical work has dealt with identification issues (Hahn, Todd, and Van Der Klaauw, 2001), optimal estimation (Porter, 2003), tests for validity of the design (McCrary, 2008), bandwidth selection (Imbens andKalyanaraman 2011).
, optimal estimation (Porter, 2003), tests for validity of the design (McCrary, 2008), bandwidth selection (Imbens andKalyanaraman 2011)..")
6
General surveys include Lee and Lemieux (2009), Van Der Klaauw (2008), and Imbens and Lemieux (2008). Angrist & Pischke, “Mostly Harmless Econometrics” Lee and Lemieux, 2010, "Regression Discontinuity Designs in Economics." Journal of Economic Literature, 48(2), 281–355 Imbens and Lemieux (2008). “” Journal of Econometrics, 2008, 142(2)
, 281–355 Imbens and Lemieux (2008). Journal of Econometrics, 2008, 142(2).")
7
Introduction A Regression Discontinuity (RD) Design is a powerful and widely applicable identification strategy. Often access to, or incentives for participation in, a service or program is assigned based on transparent rules with criteria based on clear cutoff values, rather than on discretion of administrators. Comparisons of individuals that are similar but on different sides of the cutoff point can be credible estimates of causal effects for a specific subpopulation.

8
RD Logic

14
Many different rules work like this. Examples: Whether you pass a test Whether you are eligible for a program Who wins an election Which school district you reside in Whether some punishment strategy is enacted Birth date for entering kindergarten The key insight is that right around the cutoff we can think of people slightly above as identical to people slightly below

15
Two cases of RD Sharp Regression Discontinuity (SRD) Fuzzy Regression Discontinuity Design (FRD)
 Fuzzy Regression Discontinuity Design (FRD)")
16
This is what is referred to as a “Sharp Regression Discontinuity” There is also something called a “Fuzzy Regression Discontinuity” This occurs when rules are not strictly enforced

17
SRD Example: Lee (2007) What is effect of incumbency on election outcomes? (More specifically, what is the probability of a Democrat winning the next election given that the last election was won by a Democrat?) This conjecture sounds plausible, but the success of incumbents need not reflect a real electoral advantage. Incumbents - by definition, candidates and parties who have shown they can win - may simply be better at satisfying voters or getting the vote out. Compare election outcomes in cases where previous election was very close.
 This conjecture sounds plausible, but the success of incumbents need not reflect a real electoral advantage. Incumbents - by definition, candidates and parties who have shown they can win - may simply be better at satisfying voters or getting the vote out. Compare election outcomes in cases where previous election was very close..")
19
Fuzzy Regression Discontinuity Examples (VanderKlaauw, 2002) What is effect of financial aid offer on acceptance of college admission. College admissions office puts applicants in a few categories based on numerical score. Financial aid offer is highly correlated with category. Compare individuals close to cutoff score.

21
RD Compared to an Experiment RD is often described as a “close cousin” of a randomized experiment or as a “local randomized experiment.” Consider an experiment in which each participant is assigned a randomly generated number, v, from a uniform distribution over the range [0,1]. Units with v ≥ 2 assigned to treatment; units with v < 2 assigned to control. This randomized experiment can be thought of as an RD where the assignment variable X = v and the cutoff is at 2. Because the assignment variable is random, the curves [Y(0)|X] and E[Y(1)|X] are flat. The ATE can be computed as the difference in the mean value of Y on either side of the cutoff. Good for internal validity, not much external validity.
![RD Compared to an Experiment RD is often described as a close cousin of a randomized experiment or as a local randomized experiment. Consider an experiment in which each participant is assigned a randomly generated number, v, from a uniform distribution over the range [0,1].](http://images.slideplayer.com/22/6431133/slides/slide_21.jpg " Units with v ≥ 2 assigned to treatment; units with v < 2 assigned to control. This randomized experiment can be thought of as an RD where the assignment variable X = v and the cutoff is at 2. Because the assignment variable is random, the curves [Y(0)|X] and E[Y(1)|X] are flat. The ATE can be computed as the difference in the mean value of Y on either side of the cutoff. Good for internal validity, not much external validity..")
22
Figure 3. Randomized Experiment as a RD Design

23
SRD Key assumption: E[Y (0)|X = x] and E[Y (1)|X = x] are continuous in x. Under this assumption, The estimand is the difference of two regression functions at a point. Extrapolation is unavoidable.
![SRD Key assumption: E[Y (0)|X = x] and E[Y (1)|X = x] are continuous in x.](http://images.slideplayer.com/22/6431133/slides/slide_23.jpg " Under this assumption, The estimand is the difference of two regression functions at a point. Extrapolation is unavoidable..")
24
FRD What do we look at in the FRD case: ratio of discontinuities in regression function of outcome and treatment: (FRD)
")
25
RD Compared to an Experiment Note that there are several ways in which an RD differs from a randomized experiment in actuality First, it may be possible for units to alter their assignment to treatment by manipulating the forcing variable in a way that is not possible when it is assigned at random by the investigator Second, the functional form need not be flat (or linear or monotonic) and may not even be known. not possible when it is assigned at random by the investigator. Third, only the sample near to the cutoff points are useful.

26
Manipulation If individuals have control over the assignment variable, then we should expect them to sort into (out of) treatment if treatment is desirable (undesirable) Think of a means ‐ tested income support program, or an election Those just above the threshold will be a mixture of those who would passed and those who barely failed without manipulation.
 treatment if treatment is desirable (undesirable) Think of a means ‐ tested income support program, or an election Those just above the threshold will be a mixture of those who would passed and those who barely failed without manipulation.")
27
If individuals have precise control over the assignment variable, we would expect the density of X to be zero just below the threshold but positive just above the threshold (assuming the treatment is desirable). McCrary (2008) provides a formal test for maniupulaiton of the assignment variable in an RD. The idea is that the marginal density of X should be continuous without manipulation and hence we look for discontinuities in the density around the threshold. How precise must the manipulation must be in order to threaten the RD design? See Lee and Lemieux (2010). This means that when you run an RD you must know something about the mechanism generating the assignment variable and how susceptible it could be to manipulation.
 provides a formal test for maniupulaiton of the assignment variable in an RD. The idea is that the marginal density of X should be continuous without manipulation and hence we look for discontinuities in the density around the threshold. How precise must the manipulation must be in order to threaten the RD design. See Lee and Lemieux (2010). This means that when you run an RD you must know something about the mechanism generating the assignment variable and how susceptible it could be to manipulation..")
28
Example: Hysterectomy cases in Taiwan Each year about 25000 women have hysterectomy in Taiwan. NHI records show that one out of five women have hysterectomy in her life in Taiwan. Each year about 6-7000 labor enrollees have hysterectomy, with NT130-140k per case. In total, LI paid NT 1 billion for disability benefits each year. There is no clear associations between the number of hysterectomy and the economic conditions 28

29
Disability insurance Three social programs: Government Employees Insurance (GEI): workers in public sector, school teachers Labor Insurance (LI): workers in the private sector Farmers’ Insurance (FI): farmers Women under age 45, undergoing a hysterectomy (surgical removal of uterus ,子宮切除術 ) or an oophorectomy (surgical removal of both ovaries ,卵巢切除術 ) Disability benefit = 6 months of insured salary for GEI, 5.5 months for LI and FI 29
: workers in public sector, school teachers Labor Insurance (LI): workers in the private sector Farmers’ Insurance (FI): farmers Women under age 45, undergoing a hysterectomy (surgical removal of uterus ,子宮切除術 ) or an oophorectomy (surgical removal of both ovaries ,卵巢切除術 ) Disability benefit = 6 months of insured salary for GEI, 5.5 months for LI and FI 29")
30
Hazard by quarter Total and partial hysterectomies 30

31
Hazard by quarter Total and partial hysterectomies 31

32
Hazard by quarter Partial oophorectomies 32

38
The size of the discontinuity at the cutoff is the size of the effect.

39
Here we see a discontinuity between the regression lines at the cutoff, which would lead us to conclude that the treatment worked. But this conclusion would be wrong because we modeled these data with a linear model when the underlying relationship was nonlinear

41
Here we see a discontinuity that suggests a treatment effect. However, these data are again modeled incorrectly, with a linear model that contains no interaction terms, producing an artifactualdiscontinuity at the cutoff…

45
Sample Size Implications Because of the substantial multi-collinearity that exists between its forcing variable and treatment indicator, an RDD requires 3 to 4 times as many sample members as a corresponding randomized experiment

46
External Validity The estimatand has little external validity. It is at best valid for a population defined by the cutoff value c, and by the subpopulation that is affected at that value.

47
Figure 2. Nonlinear RD

48
Because the assignment variable is random, the curves [Y(0)|X] and E[Y(1)|X] are flat. The ATE can be computed as the difference in the mean value of Y on either side of the cutoff. Because the functions are flat everywhere, the “optimal bandwidth” is to use all the data
![ Because the assignment variable is random, the curves [Y(0)|X] and E[Y(1)|X] are flat.](http://images.slideplayer.com/22/6431133/slides/slide_48.jpg "The ATE can be computed as the difference in the mean value of Y on either side of the cutoff. Because the functions are flat everywhere, the optimal bandwidth is to use all the data.")
49
How to Estimate SRD Model Compare means

50
Approach #1: Compare means In the data, we never observe E[Y(0)|X=c], that is there are no units at the cutoff that don’t get the treatment, but in principle it can be approximated arbitrarily well by E[Y(0)|X=c ‐ ε]. Therefore we estimate: E[Y|X=c+ε]-E[Y|X=c ‐ ε] This is the difference in means for those just above and below the cutoff. This is a nonparametric approach. A great virtue is that it does not depend on correct specification of functional forms.
![Approach #1: Compare means In the data, we never observe E[Y(0)|X=c], that is there are no units at the cutoff that don’t get the treatment, but in principle it can be approximated arbitrarily well by E[Y(0)|X=c ‐ ε].](http://images.slideplayer.com/22/6431133/slides/slide_50.jpg " Therefore we estimate: E[Y|X=c+ε]-E[Y|X=c ‐ ε] This is the difference in means for those just above and below the cutoff. This is a nonparametric approach. A great virtue is that it does not depend on correct specification of functional forms..")
51
Figure 2. Nonlinear RD

52
OLS (with Polynomials) The original RD design (Thistlewaite and Campbell 1960) was implemented by OLS. where τ is the causal effect of interest and η is an error term. This regression distinguishes the nonlinear and discontinuous jump from the smooth linear function. OLS with one linear term in X is seldom used anymore because the functional form assumptions are very strong.

53
Suppose the underlying functions are nonlinear and maybe unknown. In particular, suppose you want to estimate where f(X) is a smooth nonlinear function of X. Perhaps the simplest f(X) is with in X way to approximate via OLS polynomials X. Common practice is to fit different polynomial functions on each side of the cutoff by including interactions between T and X. Modeling f(X) with a pth ‐ order polynomial in this way leads to
 is a smooth nonlinear function of X. Perhaps the simplest f(X) is with in X way to approximate via OLS polynomials X. Common practice is to fit different polynomial functions on each side of the cutoff by including interactions between T and X. Modeling f(X) with a pth ‐ order polynomial in this way leads to.")
54
Centering X at the cutoff prior to running the regression ensures that the coefficient on T is the treatment effect. Common practice, for whatever reason, seems to use a 4 th order polynomial, though you should be sure that your results are robust to other specifications (more on this below).
..")
55
OLS with polynomials is a particularly simple way of allowing a flexible functional form in X. A drawback is that it provides global estimates of the regression function that use data far from the cutoff. There many are other ways, but the RD setup poses a couple of problems for standard nonparametric smoothers. We are interested in the estimate of a function at a boundary point. (For why this is a problem, see HTV or Imbens and Lemieux.) Standard nonparametric kernel regression does not work well here (converging rate too slow)
 Standard nonparametric kernel regression does not work well here (converging rate too slow).")
56
Local Linear Regression Instead of locally fitting a constant function (e.g., the mean), fit linear regressions to observations within some bandwidth of the cutoff A rectangular kernel seems to work best (see Imbens and Lemieux), but optimal bandwidth selection is an open question A serious discussion of local linear regression is beyond the scope of this lecture. See, for example, Fan and Gijbels (1996) But, really, we’re just talking about running regressions on data near the cutoff.
 But, really, we’re just talking about running regressions on data near the cutoff..")
57
Local Linear Regression We are interested in the value of a regression function at the boundary of the support. Standard kernel regression does not work well for that case (slower convergence rates) Better rates are obtained by using local linear regression. First
 Better rates are obtained by using local linear regression. First.")
58
The value of left hand limit μl(c) is then estimated as Similarly for right hand side. Not much gained by using a nonuniform kernel.

59
Alternatively one can estimate the average effect directly in a single regression, thus solving which will numerically yield the same estimate of τSRD. This interpretation extends easily to the inclusion of covariates.

60
Estimation for the FRD Case Do local linear regression for both the outcome and the treatment indicator, on both sides, and similarly and. Then the FRD estimator is

61
Alternatively, define the vector of covariates Then we can write (TSLS) Then estimating τ based on the regression function (TSLS) by Two- Stage-Least-Squares methods, using Wi as the endogenous regressor, the indicator 1{Xi ≥ c} as the excluded instrument Vi as the set of exogenous variables
 Then estimating τ based on the regression function (TSLS) by Two- Stage-Least-Squares methods, using Wi as the endogenous regressor, the indicator 1{Xi ≥ c} as the excluded instrument Vi as the set of exogenous variables")
62
This is numerically identical to before (because of uniform kernel) Can add other covariates in straightfoward manner.
 Can add other covariates in straightfoward manner.")
63
Choosing the Bandwidth (Ludwig & Miller) We wish to take into account that (i) we are interested in the regression function at the boundary of the support, and (ii) that we are interested in the regression function at x = c. Define and as the solutions to Define

64
Define to be δ quantile of the empirical distribution of X for the subsample with Xi < c, and let be δ quantile of the empirical distribution of X for the subsample with Xi ≥ c. Now we use the cross-validation criterion for, say δ = 1/2, with the corresponding cross-validation choice for the binwidth

65
Bandwidth for FRD Design Calculate optimal bandwidth separately for both regression functions and choose smallest. Calculate optimal bandwidth only for outcome and use that for both regression functions. Typically the regression function for the treatment indicator is flatter than the regression function for the outcome away from the discontinuity point (completely flat in the SRD case). So using same criterion would lead to larger bandwidth for estimation of regression function for treatment indicator. In practice it is easier to use the same bandwidth, and so to avoid bias, use the bandwidth from criterion for SRD design or smallest.
. So using same criterion would lead to larger bandwidth for estimation of regression function for treatment indicator. In practice it is easier to use the same bandwidth, and so to avoid bias, use the bandwidth from criterion for SRD design or smallest..")
66
Variance Estimation The asymptotic covar of and is Finally, the asymptotic distribution has the form

67
This asymptotic distribution is a special case of that in HTV, using the rectangular kernel, and with h = N −δ, for 1/5 < δ <2/5 (so that the asymptotic bias can be ignored). Can use plug in estimators for components of variance.

68
TSLS Variance for FRD Design The second estimator for the asymptotic variance of exploits the interpretation of the as a TSLS estimator. The variance estimator is equal to the robust variance for TSLS based on the subsample of observations with c−h ≤ Xi ≤ c+h, using the indicator 1{Xi ≥ c} as the excluded instrument, the treatment Wi as the endogenous regressor and the Vi as the exogenous covariates.

69
Concerns about Validity Two main conceptual concerns in the application of RD designs, sharp or fuzzy. Other Changes Possibility of other changes at the same cutoff value of the covariate. Such changes may affect the outcome, and these effects may be attributed erroneously to the treatment of interest. Manipulation of Forcing Variable The second concern is that of manipulation of the covariate value.

70
Specification Checks Discontinuities in average Covariates Discontinuity in the Distribution of the Forcing Variable Discontinuities in Average Outcomes at Other Values Sensitivity to Bandwidth Choice RD Designs with Misspecification

71
Discontinuities in Average Covariates Test the null hypothesis of a zero average effect on pseudo outcomes known not to be affected by the treatment. Such variables includes covariates that are by definition not affected by the treatment. Such tests are familiar from settings with identification based on unconfoundedness assumptions. Although not required for the validity of the design, in most cases, the reason for the discontinuity in the probability of the treatment does not suggest a discontinuity in the average value of covariates. If we find such a discontinuity, it typically casts doubt on the assumptions underlying the RD design.

73
A Discontinuity in the Distribution of the Forcing Variable McCrary (2007) suggests testing the null hypothesis of continuity of the density of the covariate that underlies the assignment at the discontinuity point, against the alternative of a jump in the density function at that point. Again, in principle, the design does not require continuity of the density of X at c, but a discontinuity is suggestive of violations of the no-manipulation assumption. If in fact individuals partly manage to manipulate the value of X in order to be on one side of the boundary rather than the other, one might expect to see a discontinuity in this density at the discontinuity point.

74
Discontinuities in Average Outcomes at Other Values Taking the subsample with Xi < c we can test for a jump in the conditional mean of the outcome at the median of the forcing variable. To implement the test, use the same method for selecting the binwidth as before. Also estimate the standard errors of the jump and use this to test the hypothesis of a zero jump. Repeat this using the subsample to the right of the cutoff point with Xi ≥ c. Now estimate the jump in the regression function and at and test whether it is equal to zero.

75
Sensitivity to Bandwidth Choice One should investigate the sensitivity of the inferences to this choice, for example, by including results for bandwidths twice (or four times) and half (or a quarter of) the size of the originally chosen bandwidth. Obviously, such bandwidth choices affect both estimates and standard errors, but if the results are critically dependent on a particular bandwidth choice, they are clearly less credible than if they are robust to such variation in bandwidths.

76
RD Designs with Misspecification Lee and Card (2007) study the case where the forcing variable variable X is discrete. In practice this is of course always true. This implies that ultimately one relies for identification on functional form assumptions for the regression function μ(x). They consider a parametric specification for the regression function that does not fully saturate the model and interpret the deviation between the true conditional expectation and the estimated regression function as random specification error that introduces a group structure on the standard errors.
. They consider a parametric specification for the regression function that does not fully saturate the model and interpret the deviation between the true conditional expectation and the estimated regression function as random specification error that introduces a group structure on the standard errors..")
77
Lee and Card then show how to incorporate this group structure into the standard errors for the estimated treatment effect. Within the local linear regression framework discussed in the current paper one can calculate the Lee-Card standard errors and compare them to the conventional ones.

78
Figure 4. Density of Assignment Variable Conditional on W = w, U = u

79
Figure 5. Treatment, Observables, and Unobservables in Four Research Designs

83
Figure 9. Winning the Next Election, Bandwidth of 0.02 (50 bins)
")
84
Figure 10. Winning the Next Election, Bandwidth of 0.01 (100 bins)
")
85
Figure 11. Winning the Next Election, Bandwidth of 0.005 (200 bins)
")
87
Figure 12. Cross-Validation Function for Choosing the Bandwidth in a RD Graph: Winning the Next Election

88
Figure 13. Cross-Validation Function for Choosing Bandwidth in a RD Graph: Share of Vote at Next Election

92
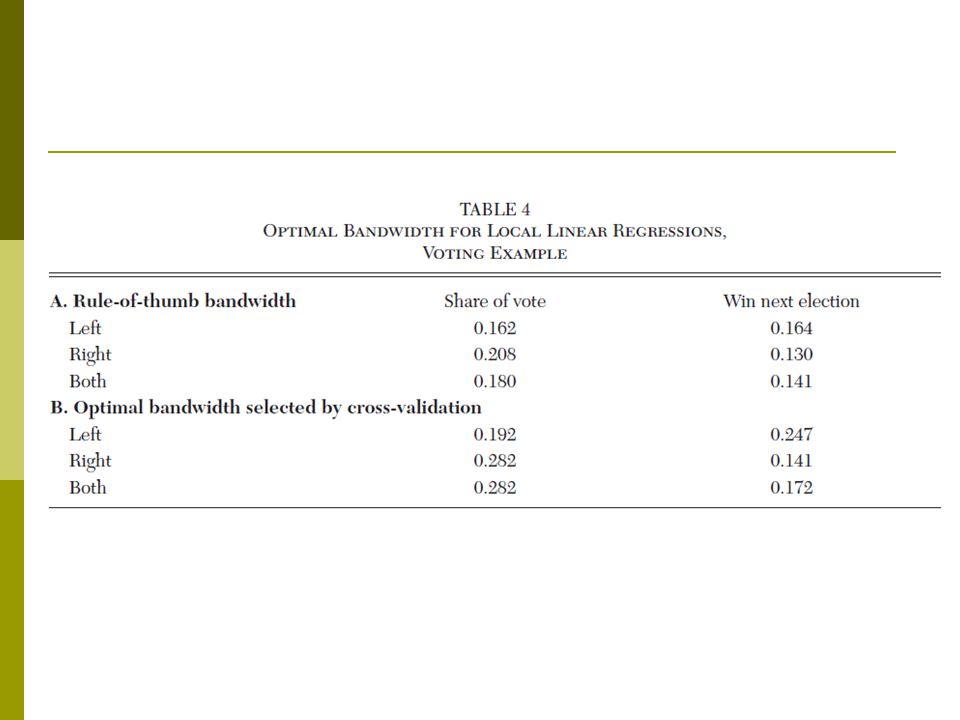
Figure 14. Cross-Validation Function for Local Linear Regression: Share of Vote at Next Election

93
Figure 15. Cross-Validation Function for Local Linear Regression: Winning the Next Election

94
Figure 16. Density of the Forcing Variable (Vote Share in Previous Election)
")
95
Figure 17. Discontinuity in Baseline Covariate (Share of Vote in Prior Election)
")
96
Figure 18. Local Linear Regression with Varying Bandwidth: Share of Vote at Next Election

97
Estimation Basics 1 Approach #1: Compare means In the data, we never observe E[Y(0)|X=c], that is there are no units at the cutoff that don’t get the treatment, but in principle it can be approximated arbitrarily well by E[Y(0)|X=c ‐ ε]. Therefore we estimate: E[Y|X=c+ε]-E[Y|X=c ‐ ε] This is the difference in means for those just above and below the cutoff. This is a nonparametric approach. A great virtue is that it does not depend on correct specification of functional forms.
![Estimation Basics 1 Approach #1: Compare means In the data, we never observe E[Y(0)|X=c], that is there are no units at the cutoff that don’t get the treatment, but in principle it can be approximated arbitrarily well by E[Y(0)|X=c ‐ ε].](http://images.slideplayer.com/22/6431133/slides/slide_97.jpg "Therefore we estimate: E[Y|X=c+ε]-E[Y|X=c ‐ ε] This is the difference in means for those just above and below the cutoff. This is a nonparametric approach. A great virtue is that it does not depend on correct specification of functional forms..")
98
Estimation Basics 2 Approach #2: OLS (with Polynomials) The original RD design (Thistlewaite and Campbell 1960) was implemented by OLS. where τ is the causal effect of interest and η is an error term. This regression distinguishes the nonlinear and discontinuous jump from the smooth linear function. OLS with one linear term in X is seldom used anymore because the functional form assumptions are very strong. What are they?

99
Estimation Basics 3 Suppose the underlying functions are nonlinear and maybe unknown. In particular, suppose you want to estimate where f(X) is a smooth nonlinear function of X. Perhaps the simplest f(X) is with in X way to approximate via OLS polynomials X. Common practice is to fit different polynomial functions on each side of the cutoff by including interactions between T and X. Modeling f(X) with a pth ‐ order polynomial in this way leads to
 is a smooth nonlinear function of X. Perhaps the simplest f(X) is with in X way to approximate via OLS polynomials X. Common practice is to fit different polynomial functions on each side of the cutoff by including interactions between T and X. Modeling f(X) with a pth ‐ order polynomial in this way leads to.")
100
Centering X at the cutoff prior to running the regression ensures that the coefficient on T is the treatment effect. Common practice, for whatever reason, seems to use a 4 th order polynomial, though you should be sure that your results are robust to other specifications (more on this below).
..")
101
Estimation Basics 4 OLS with polynomials is a particularly simple way of allowing a flexible functional form in X. A drawback is that it provides global estimates of the regression function that use data far from the cutoff. There many are other ways, but the RD setup poses a couple of problems for standard nonparametric smoothers. We are interested in the estimate of a function at a boundary point. (For why this is a problem, see HTV or Imbens and Lemieux.) Standard nonparametric kernel regression does not work well here
 Standard nonparametric kernel regression does not work well here.")
102
This leads to Approach #3: Local Linear Regression Instead of locally fitting a constant function (e.g., the mean), fit linear regressions to observations within some bandwidth of the cutoff A rectangular kernel seems to work best (see Imbens and Lemieux), but optimal bandwidth selection is an open question A serious discussion of local linear regression is beyond the scope of this lecture. See, for example, Fan and Gijbels (1996) But, really, we’re just talking about running regressions on data near the cutoff.
 But, really, we’re just talking about running regressions on data near the cutoff..")
103
Manipulation If individuals have control over the assignment variable, then we should expect them to sort into (out of) treatment if treatment is desirable (undesirable) Think of a means ‐ tested income support program, or an election Those just above the threshold will be a mixture of those who would passed and those who barely failed without manipulation.
 treatment if treatment is desirable (undesirable) Think of a means ‐ tested income support program, or an election Those just above the threshold will be a mixture of those who would passed and those who barely failed without manipulation.")
104
If individuals have precise control over the assignment variable, we would expect the density of X to be zero just below the threshold but positive just above the threshold (assuming the treatment is desirable). McCrary (2008) provides a formal test for maniupulaiton of the assignment variable in an RD. The idea is that the marginal density of X should be continuous without manipulation and hence we look for discontinuities in the density around the threshold. How precise must the manipulation must be in order to threaten the RD design? See Lee and Lemieux (2010). This means that when you run an RD you must know something about the mechanism generating the assignment variable and how susceptible it could be to manipulation.
 provides a formal test for maniupulaiton of the assignment variable in an RD. The idea is that the marginal density of X should be continuous without manipulation and hence we look for discontinuities in the density around the threshold. How precise must the manipulation must be in order to threaten the RD design. See Lee and Lemieux (2010). This means that when you run an RD you must know something about the mechanism generating the assignment variable and how susceptible it could be to manipulation..")
105
Example of Manipulation An income support program in which those earning under $14,000 qualify for support Simulated data from McCrary 2008

Similar presentations




























. How do we measure program impact when random assignment is not possible ? e.g. universal take-up non-excludable.>")

>")











