Download presentation
Presentation is loading. Please wait.

1
Introduction of Regression Discontinuity Design (RDD)
")
2
This Talk Will: Introduce the history and logic of RDD, Consider conditions for its internal validity, Considers its sample size requirements, Consider its dependence on functional form, Illustrate some specification tests for it, Describe an application. Consider limits to its external validity, Consider how to deal with noncompliance,

3
RDD History In the beginning there was Thislethwaite and Campbell (1960) This was followed by a flurry of applications to Title I (Trochim, 1984) Only a few economists were involved initially (Goldberger, 1972) Then RDD went into hibernation It recently experienced a renaissance among economists (e.g. Hahn, Todd and van der Klaauw, 2001; Jacob and Lefgren, 2002) Tom Cook has written about this story
 Tom Cook has written about this story.")
4
RDD Logic Selection on an observable (a rating) A tie-breaking experiment Modeling close to the cut-point Modeling the full distribution of ratings
 A tie-breaking experiment Modeling close to the cut-point Modeling the full distribution of ratings")
11
Many different rules work like this. Examples: Whether you pass a test Whether you are eligible for a program Who wins an election Which school district you reside in Whether some punishment strategy is enacted Birth date for entering kindergarten This last one should look pretty familiar-Angrist and Krueger’s quarter of birth was essentially a regression discontinuity idea

12
The key insight is that right around the cutoff we can think of people slightly above as identical to people slightly below Formally we can write it the model as: if is continuous then the model is identified (actually all you really need is that it is continuous at x = x*)
")
13
To see it is identified not that Thus That it

14
There is nothing special about the fact that Ti was binary as long as there is a jump in the value of Ti at x* This is what is referred to as a “Sharp Regression Discontinuity” There is also something called a “Fuzzy Regression Discontinuity” This occurs when rules are not strictly enforced

20
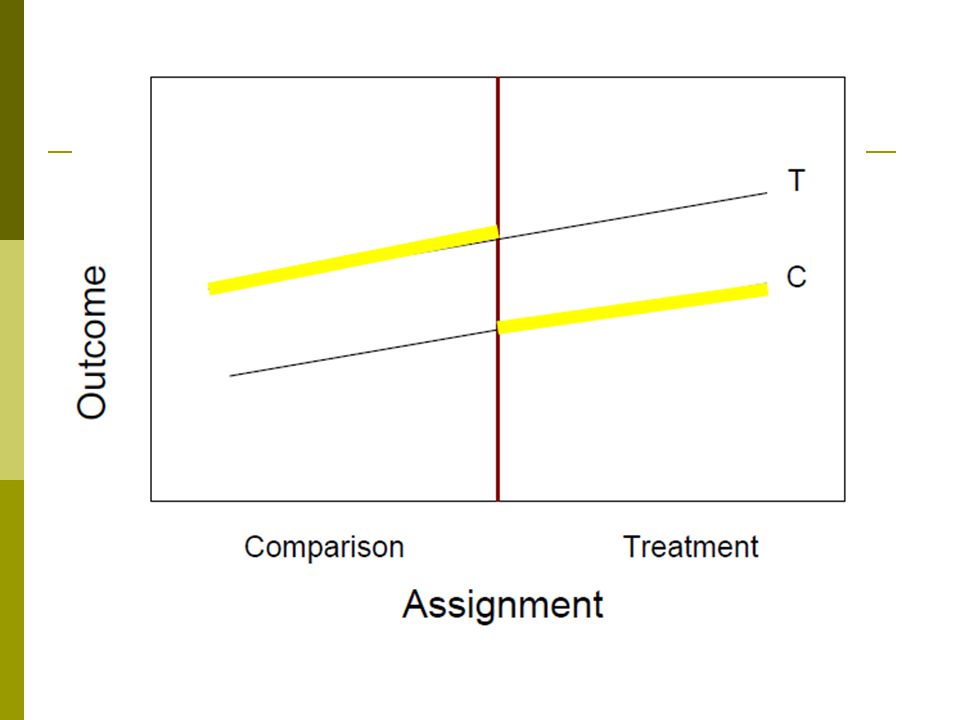
The size of the discontinuity at the cutoff is the size of the effect.

21
Conditions for Internal Validity The outcome-by-rating regression is a continuous function (absent treatment). The cut-point is determined independently of knowledge about ratings. Ratings are determined independently of knowledge about the cut-point. The functional form of the outcome-by-rating regression is specified properly.

22
RDD Statistical Model where: Y i = outcome for subject i, T i = one for subjects in the treatment group and zero otherwise, R i = rating for subject i, e i = random error term for subject i, which is independently and identically distributed

23
Sample Size Implications Because of the substantial multi-collinearity that exists between its rating variable and treatment indicator, an RDD requires 3 to 4 times as many sample members as a corresponding randomized experiment

24
Specification Tests Using the RDD to compare baseline characteristics of the treatment and comparison groups Re-estimating impacts and sequentially deleting subjects with the highest and lowest ratings Re-estimating impacts and adding: a treatment status/rating interaction a quadratic rating term interacting the quadratic with treatment status Using non-parametric estimation

25
Here we see a discontinuity between the regression lines at the cutoff, which would lead us to conclude that the treatment worked. But this conclusion would be wrong because we modeled these data with a linear model when the underlying relationship was nonlinear

27
Here we see a discontinuity that suggests a treatment effect. However, these data are again modeled incorrectly, with a linear model that contains no interaction terms, producing an artifactualdiscontinuity at the cutoff…

31
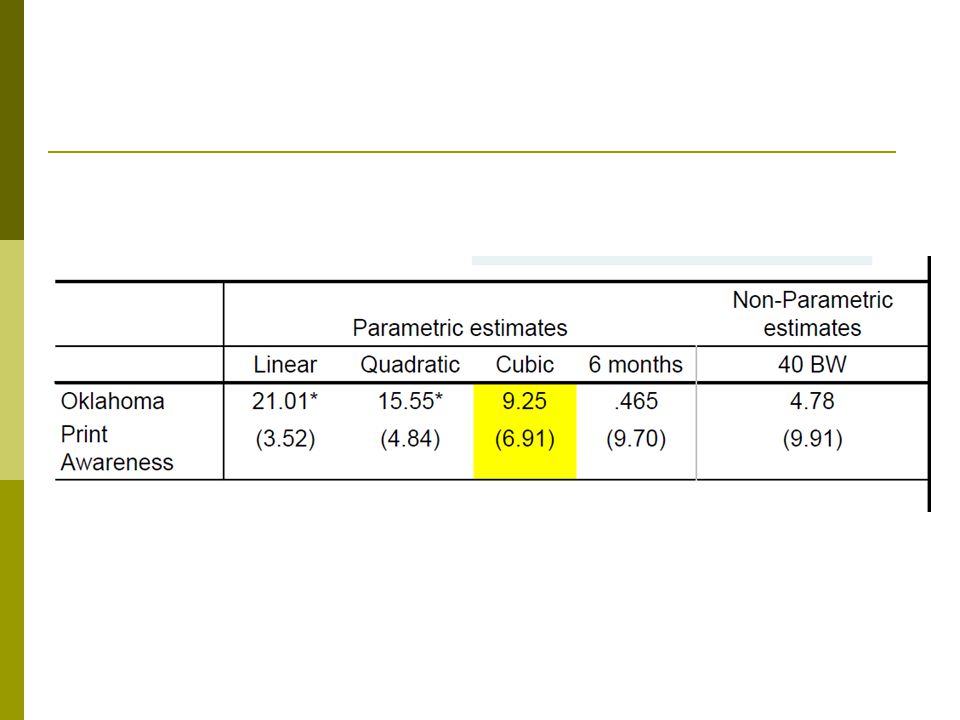
Example: State Pre-K Pre-K available by birth date cutoff in 38 states, here scaled as 0 (zero) 5 chosen for study and summed here How does pre-K affect PPVT (vocabulary) and print awareness (pre-reading)
 5 chosen for study and summed here How does pre-K affect PPVT (vocabulary) and print awareness (pre-reading)")
32
Correct specification of the regression line of assignment on outcome variable

33
Best case scenario –regression line is linear and parallel (NJ Math)
")
34
Sometimes, form is less clear

36
So, what to do?

37
Graphical approaches

40
Parametric approaches Alternate specifications and samples Include interactions and higher order terms Linear, quadratic, & cubic models Look for statistical significance for higher order terms When functional form is ambiguous, overfit the model (Sween1971; Trochim1980) Truncate sample to observations closer to cutoff Bias versus efficiency tradeoff
 Truncate sample to observations closer to cutoff Bias versus efficiency tradeoff")
41
Non-parametric approaches Eliminates functional form assumptions Performs a series of regressions within an interval, weighing observations closer to the boundary Use local linear regression because it performs better at the boundaries What depends on selecting correct bandwidth? Key tradeoff in NP estimates: bias vs precision–How do you select appropriate bandwidth?–Ocular/sensitivity tests Cross-validation methods “Leave-one-out” method

42
State-of-art is imperfect So we test for robustness and present multiple estimates

43
Example I

45
Example II

47
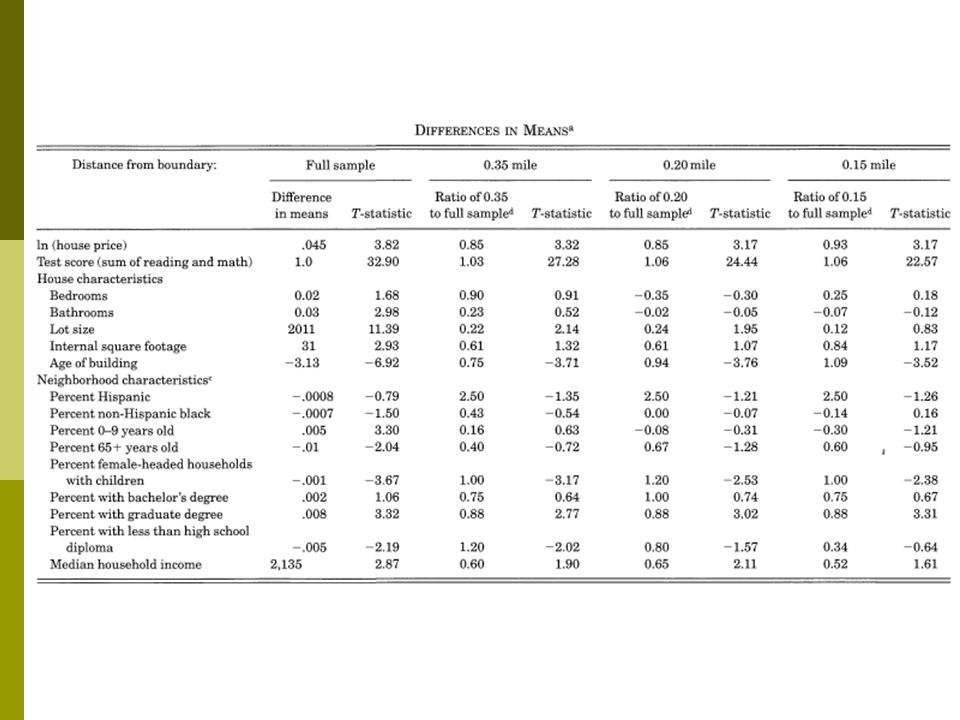
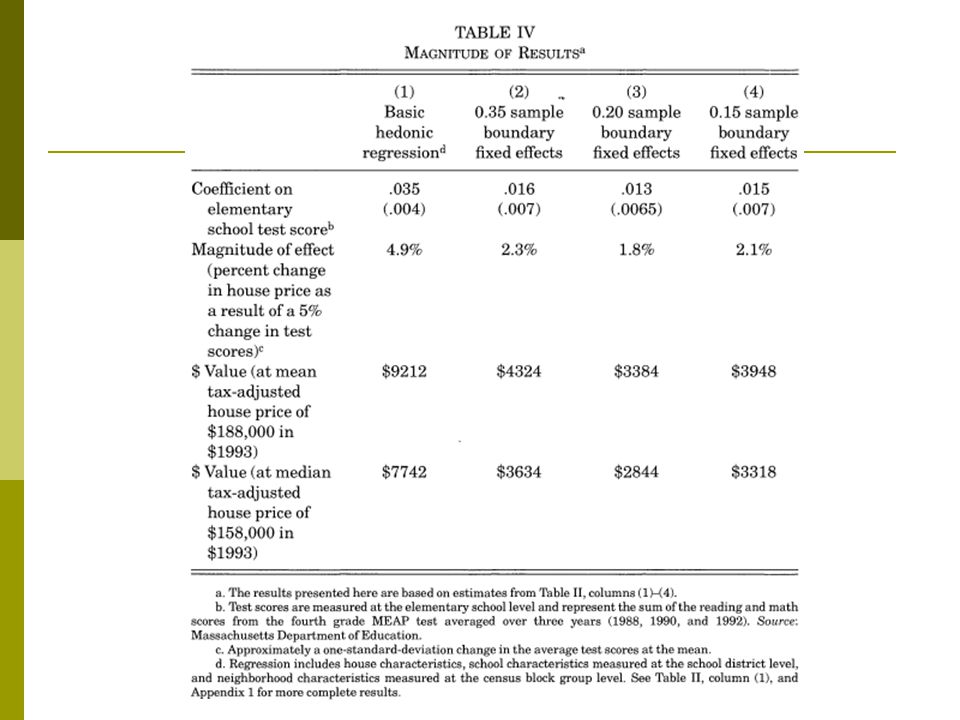
Do Better Schools Matter? Parental Valuation of Elementary Education Sandra Black, QJE, 1999 In the Tiebout model parents can “buy” better schools for their children by living in a neighborhood with better public schools How do we measure the willingness to pay? Just looking in a cross section is difficult: Richer parents probably live in nicer houses in areas that are better for many reasons

48
Black uses the school border as a regression discontinuity We could take two families who live on opposite side of the same street, but are zoned to go to different schools The difference in their house price gives the willingness to pay for school quality.

53
Tie-breaker experiment?

54
Show sample density at the cutoff

55
Summary of To-Do List Graphical analyses Alternative specification and sample choices in parametric models Non-parametric estimates at the cutoff Present multiple estimates to check for robustness Move to tie-breaker experiment around the cutoff Sample densely at the cutoff Use pretest measures

56
Recommendations Pray for parallel and linear relationships

57
External Validity Estimating impacts at the cut-point Extrapolating impacts beyond the cut-point with a simple linear model Estimating varying impacts beyond the cut-point with more complex functional forms

58
References Cook, T. D. (in press) “Waiting for Life to Arrive: A History of the Regression- discontinuity Design in Psychology, Statistics and Economics” Journal of Econometrics. Goldberger, A. S. (1972) “Selection Bias in Evaluating Treatment Effects: Some Formal Illustrations” (Discussion Paper 129-72, Madison WI: University of Wisconsin, Institute for Research on Poverty, June). Hahn, H., P. Todd and W. van der Klaauw (2001) “Identification and Estimation of Treatment Effects with a Regression-Discontinuity Design” Econometrica, 69(3): 201 – 209. Jacob, B. and L. Lefgren (2004) “Remedial Education and Student Achievement: A Regression-Discontinuity Analysis” Review of Economics and Statistics, LXXXVI.1: 226 -244. Thistlethwaite, D. L. and D. T. Campbell (1960) “Regression Discontinuity Analysis: An Alternative to the Ex Post Facto Experiment” Journal of Educational Psychology, 51(6): 309 – 317. Trochim, W. M. K. (1984) Research Designs for Program Evaluation: The Regression-Discontinuity Approach (Newbury Park, CA: Sage Publications).
 Waiting for Life to Arrive: A History of the Regression- discontinuity Design in Psychology, Statistics and Economics Journal of Econometrics. Goldberger, A. S. (1972) Selection Bias in Evaluating Treatment Effects: Some Formal Illustrations (Discussion Paper , Madison WI: University of Wisconsin, Institute for Research on Poverty, June). Hahn, H., P. Todd and W. van der Klaauw (2001) Identification and Estimation of Treatment Effects with a Regression-Discontinuity Design Econometrica, 69(3): 201 – 209. Jacob, B. and L. Lefgren (2004) Remedial Education and Student Achievement: A Regression-Discontinuity Analysis Review of Economics and Statistics, LXXXVI.1: Thistlethwaite, D. L. and D. T. Campbell (1960) Regression Discontinuity Analysis: An Alternative to the Ex Post Facto Experiment Journal of Educational Psychology, 51(6): 309 – 317. Trochim, W. M. K. (1984) Research Designs for Program Evaluation: The Regression-Discontinuity Approach (Newbury Park, CA: Sage Publications)..")
Similar presentations





















>")



. How do we measure program impact when random assignment is not possible ? e.g. universal take-up non-excludable.>")







 R-squared statistic (10.4.1) Residual plots (11.2) Influential observations (11.3, 11.4.3.>")
 Andrej Tusicisny, methodological reading group 2008.>")




