Download presentation
Presentation is loading. Please wait.

1
DIFFERENTIAL ITEM FUNCTIONING AND COGNITIVE ASSESSMENT USING IRT-BASED METHODS Jeanne Teresi, Ed.D., Ph.D. Katja Ocepek-Welikson, M.Phil.

2
PART I: OVERVIEW Jeanne Teresi, Ed.D., Ph.D.

3
A recent report on national healthcare disparities (DHHS, Agency for Healthcare Research and Quality, National Healthcare Disparities Report, 2003) concluded that: “Disparities in the health care system are pervasive” “Racial, ethnic and socioeconomic disparities are national problems that affect health care…” Differential item functioning analyses are important in health disparities research
 concluded that: Disparities in the health care system are pervasive Racial, ethnic and socioeconomic disparities are national problems that affect health care… Differential item functioning analyses are important in health disparities research")
4
USES OF DIF ANALYSES: EVALUATE EXISTING MEASURES DEVELOP NEW MEASURES THAT ARE AIMED TO BE : – Culture Fair – Gender Equivalent – Age invariant

5
DIF METHODS There are numerous review articles and books related to DIF. A few are: Camilli and Shepard, 1994 Holland and Wainer; 1993 Millsap and Everson, 1993 Potenza and Dorans, 1995 Thissen, Steinberg and Wainer, 1993

6
DEFINITIONS DIF INVOLVES THREE FACTORS : –Response to an item –Conditioning/matching cognitive status variable –Background (grouping) variable(s) DIF can be defined as conditional probabilities or conditional expected item scores that vary across groups.
 variable(s) DIF can be defined as conditional probabilities or conditional expected item scores that vary across groups.")
7
A randomly-selected person of average cognitive function interviewed in Spanish should have the same chance of responding in the unimpaired direction to a cognitive status item as would a randomly selected person of average function interviewed in English CONTROLLING FOR LEVEL OF COGNITIVE STATUS, IS RESPONSE TO AN ITEM RELATED TO GROUP MEMBERSHIP?

8
EXAMPLE Contingency table that examines the cross- tabulation of item response by group membership for every level (or grouped levels) of the attribute estimate
 of the attribute estimate")
9
Two by two contingency table for item ‘Does not State Correct State’ by language groups, conditioning on the MMSE summary score (score levels 8 to 12) Item Score Group No Error (0) Incorrect (1) Total Focal (English interview) 221 (90.2%) 24 (9.8%) 245 (100%) Reference group (Spanish interview) 113 (62.1%) 69 (37.9%) 182 (100%) Total 334 (78.2%) 93 (21.8%) 427
 Item Score Group No Error (0) Incorrect (1) Total Focal (English interview) 221 (90.2%) 24 (9.8%) 245 (100%) Reference group (Spanish interview) 113 (62.1%) 69 (37.9%) 182 (100%) Total 334 (78.2%) 93 (21.8%) 427")
10
UNIFORM DIF DEFINITIONS DIF is in the same direction across the entire spectrum of disability (item response curves for two groups do not cross) DIF involves the location (b) parameters DIF is a significant main (group) effect in regression analyses predicting item response
 DIF involves the location (b) parameters DIF is a significant main (group) effect in regression analyses predicting item response")
12
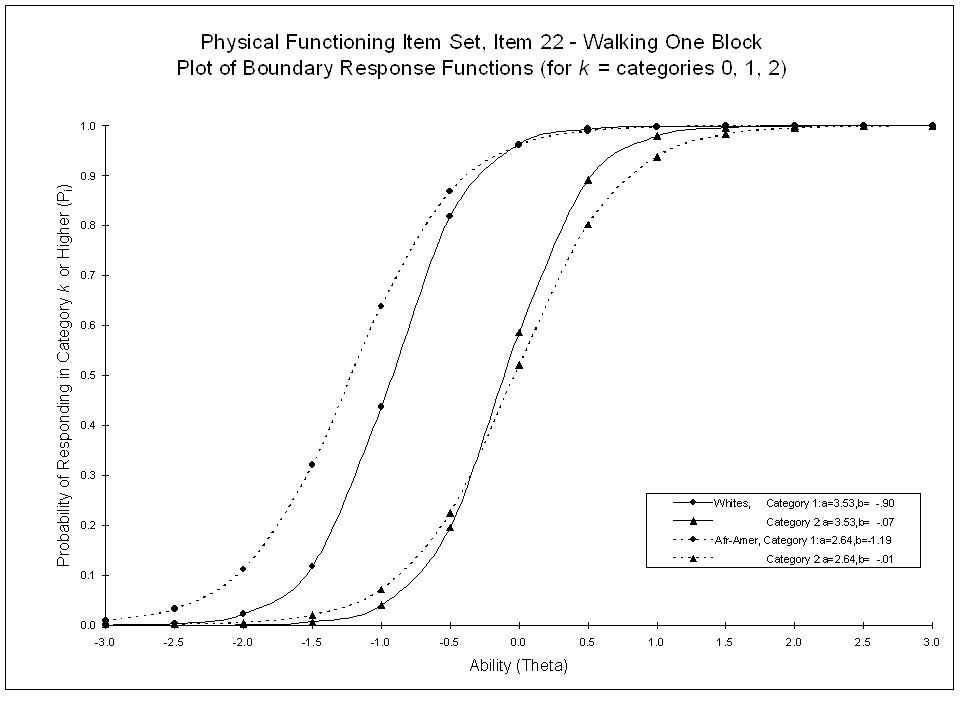
The probability of a randomly selected Spanish speaking person of mild cognitive dysfunction (theta = 0) responding incorrectly to the item “Does not State Correct State” is higher (.45) than for a randomly selected English speaking person (.09) at the same cognitive dysfunction level. (Given equal cognitive dysfunction, Spanish speaking respondents are more likely than English speaking respondents to make an error.)
.")
13
NON-UNIFORM DIF An item favors one group at certain disability levels, and other groups at other levels (or the probability of item endorsement is higher for group 1 at lower ability and higher for group 2 at higher ability) DIF involves the discrimination (a) parameters DIF is a significant group by ability interaction in regressions predicting item response DIF is assessed by examination of nested models comparing differences in log-likelihoods
 DIF involves the discrimination (a) parameters DIF is a significant group by ability interaction in regressions predicting item response DIF is assessed by examination of nested models comparing differences in log-likelihoods")
16
MAGNITUDE Magnitude of DIF Item level characteristic, e.g., odds ratio, area statistic, beta coefficient or R square increment, expected item scores

18
IMPACT Impact in the context of cognitive measures: Differences in the cognitive status distributions and summary statistics between or among studied groups Group differences in the total (test) response function Group differences in relationship of demographic variables to cognitive status variables with and without adjustment for DIF
 response function Group differences in relationship of demographic variables to cognitive status variables with and without adjustment for DIF")
20
IRT-BASED METHODS Likelihood ratio test based on IRT (Thissen, 1991, 2001) –Based on examination of differences in fit between compact and augmented models that include additional free parameters representing non-uniform and uniform DIF –Latent conditioning variable
 –Based on examination of differences in fit between compact and augmented models that include additional free parameters representing non-uniform and uniform DIF –Latent conditioning variable")
21
SOME ADVANTAGES OF IRTLR Well-developed theoretical models Can examine uniform and non-uniform DIF No equating required because of simultaneous estimation of group parameters Can model missing data Simulations show superior performance (in terms of power, particularly with small sample sizes) in comparison with non-parametric methods (Bolt, 2002)
 in comparison with non-parametric methods (Bolt, 2002)")
22
Model must fit the data; misfit results in Type I error Inflation (Bolt, 2002) Requires categorical group variable Assumptions must be met Magnitude measures not as well-integrated No formal magnitude summary measure or guidelines POSSIBLE DISADVANTAGES OF IRTLR
 Requires categorical group variable Assumptions must be met Magnitude measures not as well-integrated No formal magnitude summary measure or guidelines POSSIBLE DISADVANTAGES OF IRTLR")
23
AREA AND DFIT METHODS Area and DFIT methods based on IRT model with latent conditioning variable (Raju and colleagues, 1995; Flowers and colleagues, 1999) Non-compensatory DIF (NCDIF) indices: average squared differences in item “true” or expected raw scores for individuals as members of the focal group and as members of the reference group (expected score is the sum of the (weighted) probabilities of category endorsement, conditional on disability). Differential test functioning (DTF) : based on the compensatory DIF (CDIF) index and reflects group differences summed across items
 : based on the compensatory DIF (CDIF) index and reflects group differences summed across items.")
24
SOME ADVANTAGES OF DFIT Can detect both uniform and non-uniform DIF, and shares the advantages of IRT models upon which it is based Magnitude measures used for DIF detection Impact of item DIF on the total score is examined One simulation study (in comparison with IRTLR) showed favorable performance in terms of false DIF detection (Bolt, 2002)
 showed favorable performance in terms of false DIF detection (Bolt, 2002)")
25
SOME DISADVANTAGES OF DFIT Requires parameter equating Many programs required for DIF testing Model misfit will result in false DIF detection χ 2 statistical tests affected by sample size, and identification of optimal cut-points for DIF detection requires further simulation

26
DIFFERENCES AMONG DIF METHODS CAN BE CHARACTERIZED ACCORDING TO WHETHER THEY: Are parametric or non-parametric Are based on latent or observed variables Treat the disability dimension as continuous Can model multiple traits Can detect both uniform and non-uniform DIF Can examine polytomous responses Can include covariates in the model Must use a categorical studied (group variable)
")
27
CONCLUSIONS DIF cancellation at the aggregate level may still have an impact on an individual DIF assessment of measures remains a critical component of health disparities research, and of efforts to achieve cultural equivalence in an increasingly, culturally diverse society

28
PART II: STEPS IN IRTLRDIF ANALYSIS Katja Ocepek-Welikson, M.Phil.

29
IRTLRDIF ANALYSIS The underlying procedure of IRTLRDIF is a series of comparisons of compact and augmented models. Likelihood ratio tests are used for comparison resulting in goodness of fit statistic G 2 distributed as a χ 2

30
STEP 1: NO ANCHOR ITEMS DEFINED STEP 1a: The first comparison is between a model with all parameters constrained to be equal for the two groups, including the studied item, with a model with separate estimation of all parameters for the studied item. IRTLRDIF is designed using stringent criteria for DIF detection, so that if any model comparison results in a χ 2 value greater than 3.84 (d.f.= 1), indicating that at least one parameter differs between the two groups at the.05 level, the item is assumed to have DIF.
, indicating that at least one parameter differs between the two groups at the.05 level, the item is assumed to have DIF..")
31
STEP 1b: If there is any DIF, further model comparisons are performed STEP 1c: Two-parameter models, test of DIF in the ‘a’ parameter: the model with all parameters constrained is compared to a model in which the ‘a’ parameter (slope or discrimination) is constrained to be equal and the ‘b’ parameter (difficulty or threshold) is estimated freely
 is constrained to be equal and the ‘b’ parameter (difficulty or threshold) is estimated freely")
32
STEP 1d: The same concepts are followed with respect to the ‘b’ parameters test of DIF. The ‘a’ parameters are constrained equal and the ‘b’ parameters are free to be estimated as different. The G 2 for this last model is derived by subtraction of the G 2 for evaluation of the ‘a’ parameters from the overall G 2 value evaluating any difference (G 2 all equal - G 2 a's equal).
..")
33
STEP 2: ANCHOR ITEM SET For all models, all items are constrained to be equal within the anchor set Anchor items are defined as those with the G 2 cutoff value of 3.84 or less for the overall test of all parameters equal versus all parameters free for the studied item (for a dichotomous item under the 2p model the d.f. = 2)
.")
34
This may result in the selection of a very small anchor set for some comparisons. Therefore, these criteria may be relaxed somewhat, and the results of the individual parameter estimates examined rather than the overall result. If significant DIF is observed for the a's or b's using appropriate degrees of freedom, then the item will be excluded from the anchor set. ANCHOR ITEM SET, cont.

35
FINAL ANCHOR ITEM SET Even if anchor items were identified prior to the analyses using IRTLRDIF, additional items with DIF may be identified. All of the items in the anchor test are again evaluated, following the procedures described in step 1, in order to exclude any additional items with DIF, and to finalize the anchor set.

36
STEP 3: FINAL TESTS FOR DIF After the anchor item set is defined, all of the remaining (non-anchor) items are evaluated for DIF against this anchor set. Some items that have been identified as having DIF in earlier stages of the analyses, can convert to non-DIF with the use of a purified anchor set. (It is noted that the studied item is modeled along with the anchor items, so that parameter estimates are based on the anchor item set with inclusion of the studied item.)
.")
37
STEP4: ADJUSTMENT FOR MULTIPLE COMPARISONS Items with values of G 2 indicative of DIF in this last stage are subject to adjustment or p values for multiple comparisons used in order to reduce over-identification of items with DIF. Bonferroni, Benjamini-Hochberg or other comparable method to control for false discovery can be used.

38
STEP 5: MULTILOG RUN TO OBTAIN FINAL PARAMETER ESTIMATES In order to obtain the final item parameter estimates, an additional MULTILOG run has to be performed Parameters are estimated simultaneously for two groups Parameters for anchor items are set to be estimated equal for two groups Parameters for items with DIF are estimated separately (if only ‘b’ parameters show DIF, ‘a’s are set as equal)
")
39
SUMMARY OF STEPS IN DFIT ANALYSIS 1.Perform an assessment of dimensionality 2.Perform IRT analyses to obtain parameters and disability estimates; perform analyses separately for each group (both PARSCALE and MULTILOG can be used) 3.Equate the parameters (Baker’s EQUATE program was used in this step)
 3.Equate the parameters (Baker’s EQUATE program was used in this step)")
40
DFIT STEP, cont. 4.Identify DIF using DFIT (DFIT5P was used) 5.Identify anchor items that are relatively DIF-free, using NCDIF cutoffs rather than χ 2 significance tests that are available 6.Purify the equating constants by re- equating 7.Perform DFIT again
 5.Identify anchor items that are relatively DIF-free, using NCDIF cutoffs rather than χ 2 significance tests that are available 6.Purify the equating constants by re- equating 7.Perform DFIT again.")
41
DFIT STEP, cont. 8.Examine the NCDIF cutoffs to determine items with DIF 9.Examine CDIF and DTF to determine if values exceed the cutoff, indicating differential test (scale) functioning 10.If DTF > the cutoff, examine the removal index to identify items that might be removed
 functioning 10.If DTF > the cutoff, examine the removal index to identify items that might be removed.")
42
DFIT STEP, cont. 11.Calculate expected item scores; sum the expected item scores to obtain an expected test (scale) score for each group, separately 12.Plot the expected scale scores against theta (disability) for each group
 score for each group, separately 12.Plot the expected scale scores against theta (disability) for each group.")
Similar presentations






-the General Linear Model (GLM)>")
















