Download presentation
Presentation is loading. Please wait.

1
Personalized Predictive Medicine and Genomic Clinical Trials Richard Simon, D.Sc. Chief, Biometric Research Branch National Cancer Institute http://brb.nci.nih.gov

2
Biometric Research Branch Website brb.nci.nih.gov Powerpoint presentations Powerpoint presentations Reprints Reprints BRB-ArrayTools software BRB-ArrayTools software Web based Sample Size Planning Web based Sample Size Planning

3
Personalized Oncology is Here Today and Rapidly Advancing Key information is in tumor genome, not in inherited genetics Key information is in tumor genome, not in inherited genetics Personalization is based on limited stratification of traditional diagnostic categories, not on individual genomes Personalization is based on limited stratification of traditional diagnostic categories, not on individual genomes

4
Personalized Oncology is Here Today Estrogen receptor over-expression in breast cancer Estrogen receptor over-expression in breast cancer Anti-estrogens, aromatase inhibitors Anti-estrogens, aromatase inhibitors HER2 amplification in breast cancer HER2 amplification in breast cancer Trastuzumab, Lapatinib Trastuzumab, Lapatinib OncotypeDx in breast cancer OncotypeDx in breast cancer Low score for ER+ node - = hormonal rx Low score for ER+ node - = hormonal rx KRAS in colorectal cancer KRAS in colorectal cancer WT KRAS = cetuximab or panitumumab WT KRAS = cetuximab or panitumumab EGFR mutation or amplification in NSCLC EGFR mutation or amplification in NSCLC EGFR inhibitor EGFR inhibitor

5
These Diagnostics Have Medical Utility They inform therapeutic decision-making leading to improved patient outcome They inform therapeutic decision-making leading to improved patient outcome Tests with medical utility help patients and may reduce medical costs Tests with medical utility help patients and may reduce medical costs Tests correlated with outcome that are not actionable may increase medical costs without helping patients Tests correlated with outcome that are not actionable may increase medical costs without helping patients

6
Developing a test and demonstrating medical utility for it is a complex multi-step process that generally requires prospective randomized clinical trials Developing a test and demonstrating medical utility for it is a complex multi-step process that generally requires prospective randomized clinical trials

7
Although the randomized clinical trial remains of fundamental importance for predictive genomic medicine, some of the conventional wisdom of how to design and analyze rct’s requires re-examination Although the randomized clinical trial remains of fundamental importance for predictive genomic medicine, some of the conventional wisdom of how to design and analyze rct’s requires re-examination E.g. The concept of doing a rct of thousands of patients to answer a single question about average treatment effect for a heterogeneous target population no longer has an adequate scientific basis in oncology E.g. The concept of doing a rct of thousands of patients to answer a single question about average treatment effect for a heterogeneous target population no longer has an adequate scientific basis in oncology

8
Standard Approach is Based on Assumptions Qualitative treatment by subset interactions are unlikely Qualitative treatment by subset interactions are unlikely i.e. if new treatment T is better than control C on average, it is better for all subsets of patients i.e. if new treatment T is better than control C on average, it is better for all subsets of patients “Costs” of over-treatment are less than “costs” of under-treatment “Costs” of over-treatment are less than “costs” of under-treatment

9
Cancers of a primary site often represent a heterogeneous group of diverse molecular diseases which vary fundamentally with regard to Cancers of a primary site often represent a heterogeneous group of diverse molecular diseases which vary fundamentally with regard to the oncogenic mutations that cause them, the oncogenic mutations that cause them, their responsiveness to specific drugs their responsiveness to specific drugs

10
How Can We Develop New Drugs in a Manner More Consistent With Modern Tumor Biology and Obtain Reliable Information About What Regimens Work for What Kinds of Patients?

11
Predictive biomarkers Predictive biomarkers Measured before treatment to identify who will benefit from a particular treatment Measured before treatment to identify who will benefit from a particular treatment Prognostic biomarkers Prognostic biomarkers Measured before treatment to indicate long-term outcome for patients untreated or receiving standard treatment Measured before treatment to indicate long-term outcome for patients untreated or receiving standard treatment

12
Prognostic and Predictive Biomarkers in Oncology Single gene or protein measurement Single gene or protein measurement ER protein expression ER protein expression HER2 amplification HER2 amplification KRAS mutation KRAS mutation Scalar index or classifier that summarizes expression levels of multiple genes Scalar index or classifier that summarizes expression levels of multiple genes

16
Prospective Co-Development of Drugs and Companion Diagnostics 1. Develop a completely specified genomic classifier of the patients likely to benefit from a new drug 2. Establish analytical validity of the classifier 3. Use the completely specified classifier to design and analyze a focused clinical trial to evaluate effectiveness of the new treatment and how it relates to the candidate biomarker

17
Targeted (Enrichment) Design Restrict entry to the phase III trial based on the binary predictive classifier Restrict entry to the phase III trial based on the binary predictive classifier
 Design Restrict entry to the phase III trial based on the binary predictive classifier Restrict entry to the phase III trial based on the binary predictive classifier")
18
Using phase II data, develop predictor of response to new drug Develop Predictor of Response to New Drug Patient Predicted Responsive New Drug Control Patient Predicted Non-Responsive Off Study

19
Applicability of Targeted Design Primarily for settings where the classifier is based on a single gene whose protein product is the target of the drug Primarily for settings where the classifier is based on a single gene whose protein product is the target of the drug eg trastuzumab eg trastuzumab

20
Evaluating the Efficiency of Targeted Design Simon R and Maitnourim A. Evaluating the efficiency of targeted designs for randomized clinical trials. Clinical Cancer Research 10:6759-63, 2004; Correction and supplement 12:3229, 2006 Simon R and Maitnourim A. Evaluating the efficiency of targeted designs for randomized clinical trials. Clinical Cancer Research 10:6759-63, 2004; Correction and supplement 12:3229, 2006 Maitnourim A and Simon R. On the efficiency of targeted clinical trials. Statistics in Medicine 24:329-339, 2005. Maitnourim A and Simon R. On the efficiency of targeted clinical trials. Statistics in Medicine 24:329-339, 2005. reprints and interactive sample size calculations at http://linus.nci.nih.gov reprints and interactive sample size calculations at http://linus.nci.nih.gov

21
Relative efficiency of targeted design depends on Relative efficiency of targeted design depends on proportion of patients test positive proportion of patients test positive effectiveness of new drug (compared to control) for test negative patients effectiveness of new drug (compared to control) for test negative patients Specificity of treatment Specificity of treatment Sensitivity of test Sensitivity of test When less than half of patients are test positive and the drug has little or no benefit for test negative patients, the targeted design requires dramatically fewer randomized patients When less than half of patients are test positive and the drug has little or no benefit for test negative patients, the targeted design requires dramatically fewer randomized patients
 for test negative patients effectiveness of new drug (compared to control) for test negative patients Specificity of treatment Specificity of treatment Sensitivity of test Sensitivity of test When less than half of patients are test positive and the drug has little or no benefit for test negative patients, the targeted design requires dramatically fewer randomized patients When less than half of patients are test positive and the drug has little or no benefit for test negative patients, the targeted design requires dramatically fewer randomized patients")
22
Stratification Design Develop Predictor of Response to New Rx Predicted Non- responsive to New Rx Predicted Responsive To New Rx Control New RXControl New RX

23
Do not use the test to restrict eligibility, but to structure a prospective analysis plan Do not use the test to restrict eligibility, but to structure a prospective analysis plan Having a prospective analysis plan is essential Having a prospective analysis plan is essential “Stratifying” (balancing) the randomization is useful to ensure that all randomized patients have tissue available but is not a substitute for a prospective analysis plan “Stratifying” (balancing) the randomization is useful to ensure that all randomized patients have tissue available but is not a substitute for a prospective analysis plan Size the study for adequate evaluation of T vs C separately by marker status Size the study for adequate evaluation of T vs C separately by marker status The purpose of the study is to evaluate the new treatment overall and for the pre-defined subsets; not to modify or refine the classifier The purpose of the study is to evaluate the new treatment overall and for the pre-defined subsets; not to modify or refine the classifier The purpose is not to demonstrate that repeating the classifier development process on independent data results in the same classifier The purpose is not to demonstrate that repeating the classifier development process on independent data results in the same classifier
 the randomization is useful to ensure that all randomized patients have tissue available but is not a substitute for a prospective analysis plan Stratifying (balancing) the randomization is useful to ensure that all randomized patients have tissue available but is not a substitute for a prospective analysis plan Size the study for adequate evaluation of T vs C separately by marker status Size the study for adequate evaluation of T vs C separately by marker status The purpose of the study is to evaluate the new treatment overall and for the pre-defined subsets; not to modify or refine the classifier The purpose of the study is to evaluate the new treatment overall and for the pre-defined subsets; not to modify or refine the classifier The purpose is not to demonstrate that repeating the classifier development process on independent data results in the same classifier The purpose is not to demonstrate that repeating the classifier development process on independent data results in the same classifier")
24
R Simon. Using genomics in clinical trial design, Clinical Cancer Research 14:5984-93, 2008 R Simon. Using genomics in clinical trial design, Clinical Cancer Research 14:5984-93, 2008 R Simon. Designs and adaptive analysis plans for pivotal clinical trials of therapeutics and companion diagnostics, Expert Opinion in Medical Diagnostics 2:721-29, 2008 R Simon. Designs and adaptive analysis plans for pivotal clinical trials of therapeutics and companion diagnostics, Expert Opinion in Medical Diagnostics 2:721-29, 2008

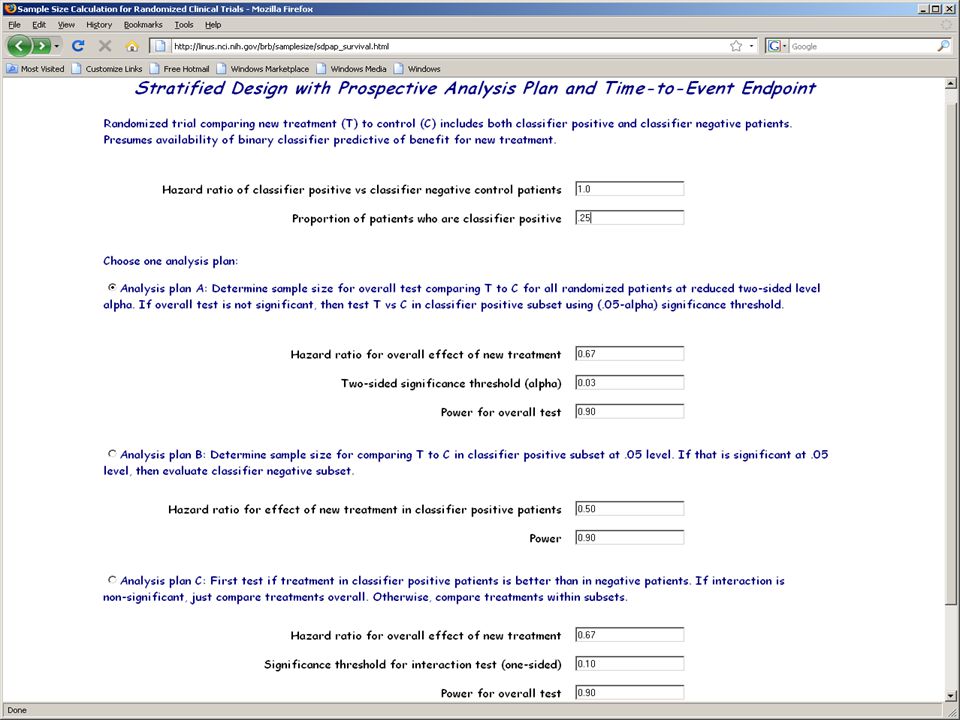
25
Analysis Plan B (Limited confidence in test) Compare the new drug to the control overall for all patients ignoring the classifier. Compare the new drug to the control overall for all patients ignoring the classifier. If p overall ≤ 0.03 claim effectiveness for the eligible population as a whole If p overall ≤ 0.03 claim effectiveness for the eligible population as a whole Otherwise perform a single subset analysis evaluating the new drug in the classifier + patients Otherwise perform a single subset analysis evaluating the new drug in the classifier + patients If p subset ≤ 0.02 claim effectiveness for the classifier + patients. If p subset ≤ 0.02 claim effectiveness for the classifier + patients.

26
Sample size for Analysis Plan B To have 90% power for detecting uniform 33% reduction in overall hazard at 3% two-sided level requires 297 events (instead of 263 for similar power at 5% level) To have 90% power for detecting uniform 33% reduction in overall hazard at 3% two-sided level requires 297 events (instead of 263 for similar power at 5% level) If 25% of patients are positive, then when there are 297 total events there will be approximately 75 events in positive patients If 25% of patients are positive, then when there are 297 total events there will be approximately 75 events in positive patients 75 events provides 75% power for detecting 50% reduction in hazard at 2% two-sided significance level 75 events provides 75% power for detecting 50% reduction in hazard at 2% two-sided significance level By delaying evaluation in test positive patients, 80% power is achieved with 84 events and 90% power with 109 events By delaying evaluation in test positive patients, 80% power is achieved with 84 events and 90% power with 109 events
 To have 90% power for detecting uniform 33% reduction in overall hazard at 3% two-sided level requires 297 events (instead of 263 for similar power at 5% level) If 25% of patients are positive, then when there are 297 total events there will be approximately 75 events in positive patients If 25% of patients are positive, then when there are 297 total events there will be approximately 75 events in positive patients 75 events provides 75% power for detecting 50% reduction in hazard at 2% two-sided significance level 75 events provides 75% power for detecting 50% reduction in hazard at 2% two-sided significance level By delaying evaluation in test positive patients, 80% power is achieved with 84 events and 90% power with 109 events By delaying evaluation in test positive patients, 80% power is achieved with 84 events and 90% power with 109 events")
27
Analysis Plan C Test for difference (interaction) between treatment effect in test positive patients and treatment effect in test negative patients at an elevated level (e.g..10) Test for difference (interaction) between treatment effect in test positive patients and treatment effect in test negative patients at an elevated level (e.g..10) If interaction is significant at that level then compare treatments separately for test positive patients and test negative patients If interaction is significant at that level then compare treatments separately for test positive patients and test negative patients Otherwise, compare treatments overall Otherwise, compare treatments overall
 between treatment effect in test positive patients and treatment effect in test negative patients at an elevated level (e.g..10) Test for difference (interaction) between treatment effect in test positive patients and treatment effect in test negative patients at an elevated level (e.g..10) If interaction is significant at that level then compare treatments separately for test positive patients and test negative patients If interaction is significant at that level then compare treatments separately for test positive patients and test negative patients Otherwise, compare treatments overall Otherwise, compare treatments overall")
28
Sample Size Planning for Analysis Plan C 88 events in test + patients needed to detect 50% reduction in hazard at 5% two-sided significance level with 90% power 88 events in test + patients needed to detect 50% reduction in hazard at 5% two-sided significance level with 90% power If 25% of patients are positive, when there are 88 events in positive patients there will be about 264 events in negative patients If 25% of patients are positive, when there are 88 events in positive patients there will be about 264 events in negative patients 264 events provides 90% power for detecting 33% reduction in hazard at 5% two-sided significance level 264 events provides 90% power for detecting 33% reduction in hazard at 5% two-sided significance level

29
Does the RCT Need to Be Significant Overall for the T vs C Treatment Comparison? No No That requirement has been traditionally used to protect against data dredging. It is inappropriate for focused trials of a treatment with a companion test. That requirement has been traditionally used to protect against data dredging. It is inappropriate for focused trials of a treatment with a companion test.

30
Web Based Software for Planning Clinical Trials of Treatments with a Candidate Predictive Biomarker http://brb.nci.nih.gov http://brb.nci.nih.gov

33
It is difficult to have the right single completely defined predictive biomarker identified and analytically validated by the time the pivotal trial of a new drug is ready to start accrual It is difficult to have the right single completely defined predictive biomarker identified and analytically validated by the time the pivotal trial of a new drug is ready to start accrual Changes in the way we do phase II trials Changes in the way we do phase II trials Adaptive methods for the refinement and evaluation of predictive biomarkers in the pivotal trials in a non- exploratory manner Adaptive methods for the refinement and evaluation of predictive biomarkers in the pivotal trials in a non- exploratory manner Use of archived tissues in focused “prospective- retrospective” designs based on randomized pivotal trials Use of archived tissues in focused “prospective- retrospective” designs based on randomized pivotal trials

34
Multiple Biomarker Design Have identified K candidate binary classifiers B 1, …, B K thought to be predictive of patients likely to benefit from T relative to C Have identified K candidate binary classifiers B 1, …, B K thought to be predictive of patients likely to benefit from T relative to C Eligibility not restricted by candidate classifiers Eligibility not restricted by candidate classifiers For notation let B 0 denote the classifier with all patients positive For notation let B 0 denote the classifier with all patients positive

35
Test T vs C restricted to patients positive for B k for k=0,1,…,K Test T vs C restricted to patients positive for B k for k=0,1,…,K Let S(B k ) be log partial likelihood ratio statistic for treatment effect in patients positive for B k (k=1,…,K) Let S(B k ) be log partial likelihood ratio statistic for treatment effect in patients positive for B k (k=1,…,K) Let S* = max{S(B k )}, k* = argmax{S(B k )} Let S* = max{S(B k )}, k* = argmax{S(B k )} For a global test of significance For a global test of significance Compute null distribution of S* by permuting treatment labels Compute null distribution of S* by permuting treatment labels If the data value of S* is significant at 0.05 level, then claim effectiveness of T for patients positive for B k* If the data value of S* is significant at 0.05 level, then claim effectiveness of T for patients positive for B k*
 be log partial likelihood ratio statistic for treatment effect in patients positive for B k (k=1,…,K) Let S(B k ) be log partial likelihood ratio statistic for treatment effect in patients positive for B k (k=1,…,K) Let S* = max{S(B k )}, k* = argmax{S(B k )} Let S* = max{S(B k )}, k* = argmax{S(B k )} For a global test of significance For a global test of significance Compute null distribution of S* by permuting treatment labels Compute null distribution of S* by permuting treatment labels If the data value of S* is significant at 0.05 level, then claim effectiveness of T for patients positive for B k* If the data value of S* is significant at 0.05 level, then claim effectiveness of T for patients positive for B k*")
36
Let S* = max{S(B k )}, k* = argmax{S(B k )} in actual data Let S* = max{S(B k )}, k* = argmax{S(B k )} in actual data The new treatment is superior to control for the population defined by k* The new treatment is superior to control for the population defined by k* Repeating the analysis for bootstrap samples of cases provides Repeating the analysis for bootstrap samples of cases provides an estimate of the stability of k* (the indication) an estimate of the stability of k* (the indication) an interval estimate of S* (the size of treatment effect for the size of treatment effect in the target population) an interval estimate of S* (the size of treatment effect for the size of treatment effect in the target population)
}, k* = argmax{S(B k )} in actual data Let S* = max{S(B k )}, k* = argmax{S(B k )} in actual data The new treatment is superior to control for the population defined by k* The new treatment is superior to control for the population defined by k* Repeating the analysis for bootstrap samples of cases provides Repeating the analysis for bootstrap samples of cases provides an estimate of the stability of k* (the indication) an estimate of the stability of k* (the indication) an interval estimate of S* (the size of treatment effect for the size of treatment effect in the target population) an interval estimate of S* (the size of treatment effect for the size of treatment effect in the target population)")
38
Adaptive Signature Design Adaptive Signature Design Boris Freidlin and Richard Simon Clinical Cancer Research 11:7872-8, 2005

39
Adaptive Signature Design End of Trial Analysis Compare E to C for all patients at significance level α 0 (eg 0.04) Compare E to C for all patients at significance level α 0 (eg 0.04) If overall H 0 is rejected, then claim effectiveness of E for eligible patients If overall H 0 is rejected, then claim effectiveness of E for eligible patients Otherwise Otherwise
 Compare E to C for all patients at significance level α 0 (eg 0.04) If overall H 0 is rejected, then claim effectiveness of E for eligible patients If overall H 0 is rejected, then claim effectiveness of E for eligible patients Otherwise Otherwise")
40
Otherwise: Otherwise: Using only the first half of patients accrued during the trial, develop a binary classifier that predicts the subset of patients most likely to benefit from the new treatment T compared to control C Using only the first half of patients accrued during the trial, develop a binary classifier that predicts the subset of patients most likely to benefit from the new treatment T compared to control C Compare T to C for patients accrued in second stage who are predicted responsive to T based on classifier Compare T to C for patients accrued in second stage who are predicted responsive to T based on classifier Perform test at significance level 1- α 0 (eg 0.01) Perform test at significance level 1- α 0 (eg 0.01) If H 0 is rejected, claim effectiveness of T for subset defined by classifier If H 0 is rejected, claim effectiveness of T for subset defined by classifier
 Perform test at significance level 1- α 0 (eg 0.01) If H 0 is rejected, claim effectiveness of T for subset defined by classifier If H 0 is rejected, claim effectiveness of T for subset defined by classifier")
41
Treatment effect restricted to subset. 10% of patients sensitive, 10 sensitivity genes, 10,000 genes, 400 patients. TestPower Overall.05 level test 46.7 Overall.04 level test 43.1 Sensitive subset.01 level test (performed only when overall.04 level test is negative) 42.2 Overall adaptive signature design 85.3
 42.2 Overall adaptive signature design")
42
Cross-Validated Adaptive Signature Design Freidlin B, Jiang W, Simon R Freidlin B, Jiang W, Simon R Clinical Cancer Research 16(2) 2010
 2010")
43
Prediction Based Analysis of Clinical Trials Using cross-validation we can evaluate our methods for analysis of clinical trials, including complex subset analysis algorithms, in terms of their effect on improving patient outcome via informing therapeutic decision making Using cross-validation we can evaluate our methods for analysis of clinical trials, including complex subset analysis algorithms, in terms of their effect on improving patient outcome via informing therapeutic decision making This approach can be used with any set of candidate predictor variables This approach can be used with any set of candidate predictor variables

44
Define an algorithm A for developing a classifier of whether patients benefit preferentially from a new treatment T relative to C Define an algorithm A for developing a classifier of whether patients benefit preferentially from a new treatment T relative to C For patients with covariate vector x, the algorithm predicts preferred treatment For patients with covariate vector x, the algorithm predicts preferred treatment Applying A to a training dataset D provides a classifier model M(A, D) Applying A to a training dataset D provides a classifier model M(A, D) R(x |M(A, D) ) = T R(x |M(A, D) ) = T R(x | D ) = C R(x | D ) = C
 Applying A to a training dataset D provides a classifier model M(A, D) R(x |M(A, D) ) = T R(x |M(A, D) ) = T R(x | D ) = C R(x | D ) = C")
45
At the conclusion of the trial randomly partition the patients into K approximately equally sized sets P 1, …, P 10 At the conclusion of the trial randomly partition the patients into K approximately equally sized sets P 1, …, P 10 Let D -i denote the full dataset minus data for patients in P i Let D -i denote the full dataset minus data for patients in P i Using K-fold complete cross-validation, omit patients in P i Using K-fold complete cross-validation, omit patients in P i Apply the defined algorithm to analyze the data in D -i to obtain a classifier M -i Apply the defined algorithm to analyze the data in D -i to obtain a classifier M -i For each patient j in P i record the treatment recommendation i.e. R j =T or R j =C For each patient j in P i record the treatment recommendation i.e. R j =T or R j =C

46
Repeat the above for all K loops of the cross- validation Repeat the above for all K loops of the cross- validation All patients have been classified as what their optimal treatment is predicted to be All patients have been classified as what their optimal treatment is predicted to be

47
Let S T denote the set of patients for whom treatment T is predicted optimal i.e. S T = {i : R j =T} Let S T denote the set of patients for whom treatment T is predicted optimal i.e. S T = {i : R j =T} Compare outcomes for patients in S who actually received T to those in S who actually received C Compare outcomes for patients in S who actually received T to those in S who actually received C Let z T = standardized log-rank statistic Let z T = standardized log-rank statistic Let S C denote the set of patients for whom treatment C is predicted optimal i.e. S C = {i : R j =C} Let S C denote the set of patients for whom treatment C is predicted optimal i.e. S C = {i : R j =C} Compare outcomes for patients in S C who actually received T to those in S who actually received C Compare outcomes for patients in S C who actually received T to those in S who actually received C Let z C = standardized log-rank statistic Let z C = standardized log-rank statistic

48
Test of Significance for Effectiveness of T vs C Compute statistical significance of z T and z C by randomly permuting treatment labels and repeating the entire procedure Compute statistical significance of z T and z C by randomly permuting treatment labels and repeating the entire procedure Do this 1000 or more times to generate the permutation null distribution of treatment effect for the patients in each subset Do this 1000 or more times to generate the permutation null distribution of treatment effect for the patients in each subset

49
The significance test based on comparing T vs C for the adaptively defined subset is the basis for demonstrating that T is more effective than C for some patients. The significance test based on comparing T vs C for the adaptively defined subset is the basis for demonstrating that T is more effective than C for some patients. Although there is less certainty about which patients actually benefit, classification may be substantially greater than for the standard clinical trial in which all patients are classified based on results of testing the single overall null hypothesis Although there is less certainty about which patients actually benefit, classification may be substantially greater than for the standard clinical trial in which all patients are classified based on results of testing the single overall null hypothesis

50
70% Response to T in Sensitive Patients 25% Response to T Otherwise 25% Response to C 20% Patients Sensitive ASDCV-ASD Overall 0.05 Test 0.4860.503 Overall 0.04 Test 0.4520.471 Sensitive Subset 0.01 Test 0.2070.588 Overall Power 0.5250.731

52
Expected 5-Year DFS Using New Algorithm Let S(T) = observed 5-year DFS for patients in S T who received treatment T Let S(T) = observed 5-year DFS for patients in S T who received treatment T m T such patients m T such patients Let S(C) = observed K-year DFS for patients in S C who received treatment C Let S(C) = observed K-year DFS for patients in S C who received treatment C m C such patients m C such patients Expected K-Year DFS using new algorithm Expected K-Year DFS using new algorithm {m T S(T) + m C S(C)}/{m T + m C } {m T S(T) + m C S(C)}/{m T + m C } Confidence limits for this estimate can be obtained by bootstrapping the complete cross-validation procedure Confidence limits for this estimate can be obtained by bootstrapping the complete cross-validation procedure
 = observed 5-year DFS for patients in S T who received treatment T Let S(T) = observed 5-year DFS for patients in S T who received treatment T m T such patients m T such patients Let S(C) = observed K-year DFS for patients in S C who received treatment C Let S(C) = observed K-year DFS for patients in S C who received treatment C m C such patients m C such patients Expected K-Year DFS using new algorithm Expected K-Year DFS using new algorithm {m T S(T) + m C S(C)}/{m T + m C } {m T S(T) + m C S(C)}/{m T + m C } Confidence limits for this estimate can be obtained by bootstrapping the complete cross-validation procedure Confidence limits for this estimate can be obtained by bootstrapping the complete cross-validation procedure")
53
Expected 5-Year DFS Using Standard Analysis If the overall null hypothesis is not rejected If the overall null hypothesis is not rejected Expected 5-Year DFS is the observed 5-year DFS in the control group Expected 5-Year DFS is the observed 5-year DFS in the control group If the overall null hypothesis is rejected If the overall null hypothesis is rejected Expected 5-Year DFS is the observed 5-year DFS in T group Expected 5-Year DFS is the observed 5-year DFS in T group

54
By applying the analysis algorithm to the full RCT dataset D, recommendations are developed for how future patients should be treated By applying the analysis algorithm to the full RCT dataset D, recommendations are developed for how future patients should be treated R(x|D) for all x vectors. R(x|D) for all x vectors. The stability of the recommendations can be evaluated based on the distribution of R(x|D(b)) for non-parametric bootstrap samples D(b) from the full dataset D. The stability of the recommendations can be evaluated based on the distribution of R(x|D(b)) for non-parametric bootstrap samples D(b) from the full dataset D.
 for all x vectors. The stability of the recommendations can be evaluated based on the distribution of R(x|D(b)) for non-parametric bootstrap samples D(b) from the full dataset D. The stability of the recommendations can be evaluated based on the distribution of R(x|D(b)) for non-parametric bootstrap samples D(b) from the full dataset D..")
55
With Binary Outcome f j (x) = probability of response for patient with covariate vector x who receives rx j f j (x) = probability of response for patient with covariate vector x who receives rx j Fit separately to data for patients in each treatment group in the training set Fit separately to data for patients in each treatment group in the training set Logistic regression, stepwise logistic regression, L1 penalized logistic regression, CART, random forest, etc Logistic regression, stepwise logistic regression, L1 penalized logistic regression, CART, random forest, etc Fit jointly for patients in both treatment groups combined in the training set Fit jointly for patients in both treatment groups combined in the training set Logistic model including treatment, selected main effects, and covariates with large interactions Logistic model including treatment, selected main effects, and covariates with large interactions
 = probability of response for patient with covariate vector x who receives rx j f j (x) = probability of response for patient with covariate vector x who receives rx j Fit separately to data for patients in each treatment group in the training set Fit separately to data for patients in each treatment group in the training set Logistic regression, stepwise logistic regression, L1 penalized logistic regression, CART, random forest, etc Logistic regression, stepwise logistic regression, L1 penalized logistic regression, CART, random forest, etc Fit jointly for patients in both treatment groups combined in the training set Fit jointly for patients in both treatment groups combined in the training set Logistic model including treatment, selected main effects, and covariates with large interactions Logistic model including treatment, selected main effects, and covariates with large interactions")
57
Biotechnology Has Forced Biostatistics to Focus on Prediction This has led to many exciting methodological developments This has led to many exciting methodological developments p>>n problems in which number of genes is much greater than the number of cases p>>n problems in which number of genes is much greater than the number of cases Statistics has over-focused on inference. Many of the methods and much of the conventional wisdom of statistics are based on inference problems and are not applicable to prediction problems Statistics has over-focused on inference. Many of the methods and much of the conventional wisdom of statistics are based on inference problems and are not applicable to prediction problems

58
Prediction Based Clinical Trials New methods for determining from RCTs which patients, if any, benefit from new treatments can be evaluated directly using the actual RCT data in a manner that separates model development from model evaluation, rather than basing treatment recommendations on the results of a single hypothesis test. New methods for determining from RCTs which patients, if any, benefit from new treatments can be evaluated directly using the actual RCT data in a manner that separates model development from model evaluation, rather than basing treatment recommendations on the results of a single hypothesis test.

59
Prediction Based Clinical Trials Using cross-validation we can evaluate new methods for analysis of clinical trials in terms of their intended use which is informing therapeutic decision making Using cross-validation we can evaluate new methods for analysis of clinical trials in terms of their intended use which is informing therapeutic decision making

60
Acknowledgements Boris Freidlin Boris Freidlin Yingdong Zhao Yingdong Zhao Wenyu Jiang Wenyu Jiang Aboubakar Maitournam Aboubakar Maitournam

Similar presentations











 How.>")




 Design. Prospective Co-Development of Drugs and Companion Diagnostics 1. Develop a completely specified genomic classifier of the.>")





 Hajime Uno (Kitasato University) Tianxi Cai, Els Goetghebeur,>")



