Download presentation
Presentation is loading. Please wait.

1
Hashing and Packet Level Algorithms
Michael Mitzenmacher

2
Goals of the Talk Consider algorithms/data structures for measurement/monitoring schemes at the router level. Focus on packets, flows. Emphasis on my recent work, future plans. “Applied theory”. Less on experiments, more on design/analysis of data structures for applications. Hash-based schemes Bloom filters and variants.

3
Vision Three-pronged research data.
Low: Efficient hardware implementations of relevant algorithms and data structures. Medium: New, improved data structures and algorithms for old and new applications. High: Distributed infrastructure supporting monitoring and measurement schemes.

4
Background / Building Blocks
Multiple-choice hashing Bloom filters

5
Multiple Choices: d-left Hashing
Split hash table into d equal subtables. To insert, choose a bucket uniformly for each subtable. Place item in a cell in the least loaded bucket, breaking ties to the left.

6
Properties of d-left Hashing
Analyzable using both combinatorial methods and differential equations. Maximum load very small: O(log log n). Differential equations give very, very accurate performance estimates. Maximum load is extremely close to average load for small values of d.
. Differential equations give very, very accurate performance estimates. Maximum load is extremely close to average load for small values of d.")
7
Example of d-left hashing
Consider 3-left performance. Average load 6.4 Average load 4 Load 0 1.7e-08 Load 1 5.6e-07 Load 2 1.2e-05 Load 3 2.1e-04 Load 4 3.5e-03 Load 5 5.6e-02 Load 6 4.8e-01 Load 7 4.5e-01 Load 8 6.2e-03 Load 9 4.8e-15 Load 0 2.3e-05 Load 1 6.0e-04 Load 2 1.1e-02 Load 3 1.5e-01 Load 4 6.6e-01 Load 5 1.8e-01 Load 6 Load 7 5.6e-31

8
Example of d-left hashing
Consider 4-left performance with average load of 6, using differential equations. Alternating insertions/deletions Steady state Insertions only Load > 1 1.0000 Load > 2 Load > 3 Load > 4 0.9999 Load > 5 0.9971 Load > 6 0.8747 Load > 7 0.1283 Load > 8 1.273e-10 Load > 9 2.460e-138 Load > 1 1.0000 Load > 2 0.9999 Load > 3 0.9990 Load > 4 0.9920 Load > 5 0.9505 Load > 6 0.7669 Load > 7 0.2894 Load > 8 0.0023 Load > 9 1.681e-27

9
Review: Bloom Filters Given a set S = {x1,x2,x3,…xn} on a universe U, want to answer queries of the form: Bloom filter provides an answer in “Constant” time (time to hash). Small amount of space. But with some probability of being wrong. Alternative to hashing with interesting tradeoffs.
. Small amount of space. But with some probability of being wrong. Alternative to hashing with interesting tradeoffs.")
10
Bloom Filters B B B B Start with an m bit array, filled with 0s.
B Hash each item xj in S k times. If Hi(xj) = a, set B[a] = 1. 1 B To check if y is in S, check B at Hi(y). All k values must be 1. 1 B Possible to have a false positive; all k values are 1, but y is not in S. 1 B n items m = cn bits k hash functions
 = a, set B[a] = B. To check if y is in S, check B at Hi(y). All k values must be B. Possible to have a false positive; all k values are 1, but y is not in S. 1. B. n items m = cn bits k hash functions.")
11
False Positive Probability
Pr(specific bit of filter is 0) is If r is fraction of 0 bits in the filter then false positive probability is Approximations valid as r is concentrated around E[r]. Martingale argument suffices. Find optimal at k = (ln 2)m/n by calculus. So optimal fpp is about (0.6185)m/n n items m = cn bits k hash functions
 is. If r is fraction of 0 bits in the filter then false positive probability is. Approximations valid as r is concentrated around E[r]. Martingale argument suffices. Find optimal at k = (ln 2)m/n by calculus. So optimal fpp is about (0.6185)m/n. n items m = cn bits k hash functions.")
12
Example m/n = 8 Opt k = 8 ln 2 = n items m = cn bits k hash functions

13
Handling Deletions Bloom filters can handle insertions, but not deletions. If deleting xi means resetting 1s to 0s, then deleting xi will “delete” xj. xi xj B 1 1 1 1 1 1 1 1

14
Counting Bloom Filters
Start with an m bit array, filled with 0s. B Hash each item xj in S k times. If Hi(xj) = a, add 1 to B[a]. 3 1 2 B To delete xj decrement the corresponding counters. 2 3 1 B Can obtain a corresponding Bloom filter by reducing to 0/1. 1 B
 = a, add 1 to B[a] B. To delete xj decrement the corresponding counters B. Can obtain a corresponding Bloom filter by reducing to 0/1. 1. B.")
15
Counting Bloom Filters: Overflow
Must choose counters large enough to avoid overflow. Poisson approximation suggests 4 bits/counter. Average load using k = (ln 2)m/n counters is ln 2. Probability a counter has load at least 16: Failsafes possible. We assume 4 bits/counter for comparisons.
m/n counters is ln 2. Probability a counter has load at least 16: Failsafes possible. We assume 4 bits/counter for comparisons.")
16
Bloomier Filters Instead of set membership, keep an r-bit function value for each set element. Correct value should be given for each set element. Non-set elements should return NULL with high probability. Mutable version: function values can change. But underlying set can not. First suggested in paper by Chazelle, Kilian, Rubenfeld, Tal.

17
From Low to High Low Medium High Hash Tables for Hardware
New Bloom Filter/Counting Bloom Filter Constructions (Hardware Friendly) Medium Approximate Concurrent State Machines High A Distributed Hashing Infrastructure Why do Weak Hash Functions Work So Well?
 Medium. Approximate Concurrent State Machines. High. A Distributed Hashing Infrastructure. Why do Weak Hash Functions Work So Well")
18
Low Level : Better Hash Tables for Hardware
Joint work with Adam Kirsch. Simple Summaries for Hashing with Choices. The Power of One Move: Hashing Schemes for Hardware.

19
Perfect Hashing Approach
Element 1 Element 2 Element 3 Element 4 Element 5 Fingerprint(4) Fingerprint(5) Fingerprint(2) Fingerprint(1) Fingerprint(3)
 Fingerprint(5) Fingerprint(2) Fingerprint(1) Fingerprint(3)")
20
Near-Perfect Hash Functions
Perfect hash functions are challenging. Require all the data up front – no insertions or deletions. Hard to find efficiently in hardware. In [BM96], we note that d-left hashing can give near-perfect hash functions. Useful even with insertions, deletions. Some loss in space efficiency.

21
Near-Perfect Hash Functions via d-left Hashing
Maximum load equals 1 Requires significant space to avoid all collisions, or some small fraction of spillovers. Maximum load greater than 1 Multiple buckets must be checked, and multiple cells in a bucket must be checked. Not perfect in space usage. In practice, 75% space usage is very easy. In theory, can do even better.

22
Hash Table Design : Example
Desired goals: At most 1 item per bucket. Minimize space. And minimize number of hash functions. Small amount of spillover possible. We model as a constant fraction, e.g. 0.2%. Can be placed in a content-addressable memory (CAM) if small enough.
 if small enough.")
23
Basic d-left Scheme For hash table holding up to n elements, with max load 1 per bucket, use 4 choices and 2n cells. Spillover of approximately 0.002n elements into CAM.

24
Improvements from Skew
For hash table holding up to n elements, with max load 1 per bucket, use 4 choices and 1.8n cells. Subtable sizes 0.79n, 0.51n, 0.32n, 0.18n. Spillover still approximately 0.002n elements into CAM. Subtable sizes optimized using differential equations, black-box optimization. xk

25
Summaries to Avoid Lookups
In hardware, d choices of location can be done by parallelization. Look at d memory banks in parallel. But there’s still a cost: pin count. Can we keep track of which hash function to use for each item, using a small summary? Yes: use a Bloom-filter like structure to track. Skew impacts summary performance; more skew better. Uses small amount of on-chip memory. Avoids multiple look-ups. Special case of a Bloomier filter.

26
Hash Tables with Moves Cuckoo Hashing (Pagh, Rodler)
Hashed items need not stay in their initial place. With multiple choices, can move item to another choice, without affecting lookups. As long as hash values can be recomputed. When inserting, if all spots are filled, new item kicks out an old item, which looks for another spot, and might kick out another item, and so on.

27
Benefits and Problems of Moves
Benefit: much better space utilization. Multiple choices, multiple items per bucket, can achieve 90+% with no spillover. Drawback: complexity. Moves required can grow like log n. Constant on average. Bounded maximum time per operation important in many settings. Moves expensive. Table usually in slow memory.

28
Question : Power of One Move
How much leverage do we get by just allowing one move? One move likely to be possible in practice. Simple for hardware. Analysis possible via differential equations. Cuckoo hard to analyze. Downside : some spillover into CAM.

29
Comparison, Insertions Only
4 schemes No moves Conservative : Place item if possible. If not, try to move earliest item that has not already replaced another item to make room. Otherwise spill over. Second chance : Read all possible locations, and for each location with an item, check it it can be placed in the next subtable. Place new item as early as possible, moving up to 1 item left 1 level. Second chance, with 2 per bucket. Target of 0.2% spillover. Balanced (all subtables the same) and skewed compared. All done by differential equation analysis (and simulations match).
 and skewed compared. All done by differential equation analysis (and simulations match).")
30
Results of Moves : Insertions Only
Space overhead, balanced Space overhead, skewed Fraction moved, skewed No moves 2.00 1.79 0% Conservative 1.46 1.39 1.6% Standard 1.41 1.29 12.0% Standard, 2 1.14 1.06 14.9%

31
Conclusions, Moves Even one move saves significant space.
More aggressive schemes, considering all possible single moves, save even more. (Harder to analyze, more hardware resources.) Importance of allowing small amounts of spillover in practical settings.
 Importance of allowing small amounts of spillover in practical settings.")
32
Future Work This analysis was for insertions only.
Lots more space required in case of deletions. Different behavior in steady state. More moves may be required. Examining possible implementations. With Adam Kirsch, to appear in Allerton.

33
From Low to High Low Medium High Hash Tables for Hardware
New Bloom Filter/Counting Bloom Filter Constructions (Hardware Friendly) Medium Approximate Concurrent State Machines High A Distributed Hashing Infrastructure Why do Weak Hash Functions Work So Well?
 Medium. Approximate Concurrent State Machines. High. A Distributed Hashing Infrastructure. Why do Weak Hash Functions Work So Well")
34
Low- Medium: New Bloom Filters / Counting Bloom Filters
Joint work with Flavio Bonomi, Rina Panigrahy, Sushil Singh, George Varghese.

35
A New Approach to Bloom Filters
Folklore Bloom filter construction. Recall: Given a set S = {x1,x2,x3,…xn} on a universe U, want to answer membership queries. Method: Find an n-cell perfect hash function for S. Maps set of n elements to n cells in a 1-1 manner. Then keep bit fingerprint of item in each cell. Lookups have false positive < e. Advantage: each bit/item reduces false positives by a factor of 1/2, vs ln 2 for a standard Bloom filter. Negatives: Perfect hash functions non-trivial to find. Cannot handle on-line insertions.

36
Near-Perfect Hash Functions
In [BM96], we note that d-left hashing can give near-perfect hash functions. Useful even with deletions. Main differences Multiple buckets must be checked, and multiple cells in a bucket must be checked. Not perfect in space usage. In practice, 75% space usage is very easy. In theory, can do even better.

37
First Design : Just d-left Hashing
For a Bloom filter with n elements, use a 3-left hash table with average load 4, 60 bits per bucket divided into 6 fixed-size fingerprints of 10 bits. Overflow rare, can be ignored. False positive rate of Vs for a standard Bloom filter. Problem: Too much empty, wasted space. Other parametrizations similarly impractical. Need to avoid wasting space.

38
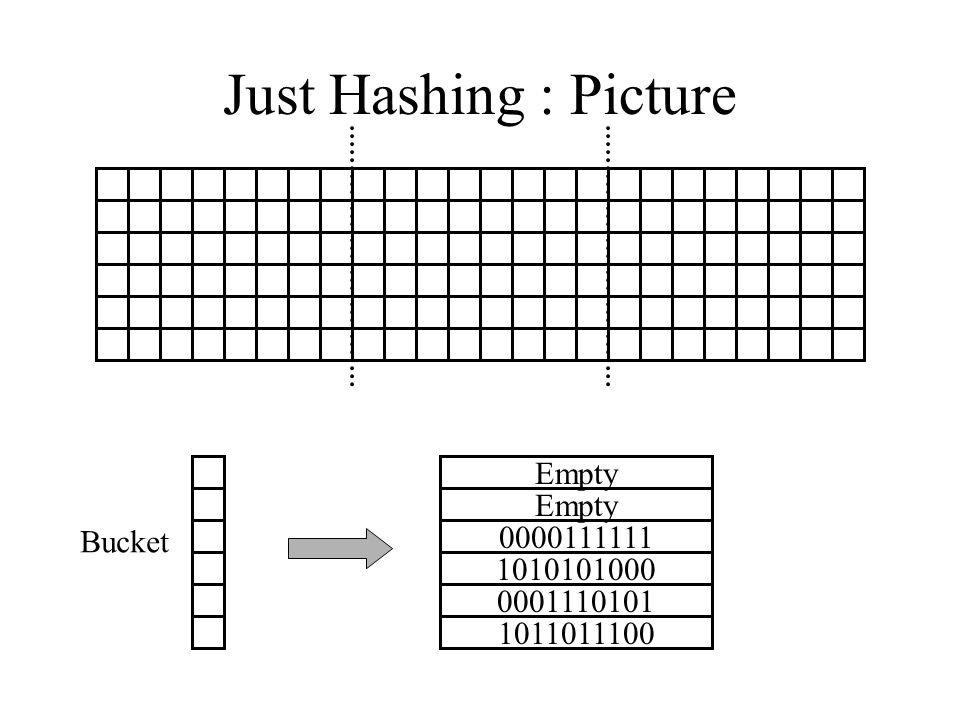
Just Hashing : Picture Empty Empty Bucket 0000111111 1010101000
39
Key: Dynamic Bit Reassignment
Use 64-bit buckets: 4 bit counter, 60 bits divided equally among actual fingerprints. Fingerprint size depends on bucket load. False positive rate of Vs for a standard Bloom filter. DBR: Within a factor of 2. And would be better for larger buckets. But 64 bits is a nice bucket size for hardware. Can we remove the cost of the counter?

40
DBR : Picture Bucket Count : 4 000110110101 111010100001 101010101000
Bucket Count : 4

41
Semi-Sorting Fingerprints in bucket can be in any order.
Semi-sorting: keep sorted by first bit. Use counter to track #fingerprints and #fingerprints starting with 0. First bit can then be erased, implicitly given by counter info. Can extend to first two bits (or more) but added complexity.
 but added complexity.")
42
DBR + Semi-sorting : Picture
Bucket Count : 4,2

43
DBR + Semi-Sorting Results
Using 64-bit buckets, 4 bit counter. Semi-sorting on loads 4 and 5. Counter only handles up to load 6. False positive rate of Vs for a standard Bloom filter. This is the tradeoff point. Using 128-bit buckets, 8 bit counter, 3-left hash table with average load 6.4. Semi-sorting all loads: fpr of 2 bit semi-sorting for loads 6/7: fpr of Vs for a standard Bloom filter.

44
Additional Issues Futher possible improvements
Group buckets to form super-buckets that share bits. Conjecture: Most further improvements are not worth it in terms of implementation cost. Moving items for better balance? Underloaded case. New structure maintains good performance.

45
Improvements to Counting Bloom Filter
Similar ideas can be used to develop an improved Counting Bloom Filter structure. Same idea: use fingerprints and a d-left hash table. Counting Bloom Filters waste lots of space. Lots of bits to record counts of 0. Our structure beats standard CBFs easily, by factors of 2 or more in space. Even without dynamic bit reassignment.

46
From Low to High Low Medium High Hash Tables for Hardware
New Bloom Filter/Counting Bloom Filter Constructions (Hardware Friendly) Medium Approximate Concurrent State Machines High A Distributed Hashing Infrastructure Why do Weak Hash Functions Work So Well?
 Medium. Approximate Concurrent State Machines. High. A Distributed Hashing Infrastructure. Why do Weak Hash Functions Work So Well")
47
Approximate Concurrent State Machines
Joint work with Flavio Bonomi, Rina Panigrahy, Sushil Singh, George Varghese. Extending the Bloomier filter idea to handle dynamic sets, dynamic function values, in practical setting.

48
Approximate Concurrent State Machines
Model for ACSMs We have underlying state machine, states 1…X. Lots of concurrent flows. Want to track state per flow. Dynamic: Need to insert new flows and delete terminating flows. Can allow some errors. Space, hardware-level simplicity are key.

49
Motivation: Router State Problem
Suppose each flow has a state to be tracked. Applications: Intrusion detection Quality of service Distinguishing P2P traffic Video congestion control Potentially, lots of others! Want to track state for each flow. But compactly; routers have small space. Flow IDs can be ~100 bits. Can’t keep a big lookup table for hundreds of thousands or millions of flows!

50
Problems to Be Dealt With
Keeping state values with small space, small probability of errors. Handling deletions. Graceful reaction to adversarial/erroneous behavior. Invalid transitions. Non-terminating flows. Could fill structure if not eventually removed. Useful to consider data structures in well-behaved systems and ill-behaved systems.

51
Summary We have an ACSM design. ACSM performance seems reasonable:
Similar to new Bloom filter design. ACSM design came first! ACSM performance seems reasonable: Sub 1% error rates with reasonable size.

52
From Low to High Low Medium High Hash Tables for Hardware
New Bloom Filter/Counting Bloom Filter Constructions (Hardware Friendly) Medium Approximate Concurrent State Machines High A Distributed Hashing Infrastructure Why do Weak Hash Functions Work So Well?
 Medium. Approximate Concurrent State Machines. High. A Distributed Hashing Infrastructure. Why do Weak Hash Functions Work So Well")
53
A Distributed Router Infrastructure
Recently funded FIND proposal. Looking for ideas/collaborators.

54
The High-Level Pitch Lots of hash-based schemes being designed for approximate measurement/monitoring tasks. But not built into the system to begin with. Want a flexible router architecture that allows: New methods to be easily added. Distributed cooperation using such schemes.

55
What We Need Off-Chip Memory On-Chip Memory CAM(s) Memory Hashing
Computation Unit Unit for Other Computation Programming Language Computation Control System Communication Architecture Communication + Control

56
Lots of Design Questions
How much space for various memory levels? How can we dynamically divide memory among multiple competing applications? What hash functions should be included? How open should system be to new hash functions? What programming functionality should be included? What programming language to use? What communication is necessary to achieve distributed monitoring tasks given the architecture? Should security be a consideration? What security approaches are possible? And so on…

57
Which Hash Functions? Theorists: Practitioners:
Want hash functions with analyzable properties. Dislike assuming fully random hash functions. Which we have done! But often what you can prove doesn’t match actual performance. Practitioners: Want easily implementable, fast hash functions. Space and speed important! Want simple analysis. Generally accept simulated behavior. But possible danger!!!

58
Why Do Weak Hash Functions Work So Well?
In reality, assuming perfectly random hash functions seems to be the right thing to do. Easier to analyze. Real systems almost always work that way, even with weak hash functions! Can Theory explain strong performance of weak hash functions?

59
Recent Work A new explanation:
Joint work with Salil Vadhan. Choosing a hash function from a pairwise independent family is enough – if data has sufficient entropy. Randomness of hash function and data “combine”. Behavior matches truly random hash function with high probability. Techniques based on theory of randomness extraction. Leftover Hash Lemma, extensions.

60
Sample Results and Implications
Consider input data of n items as a stream, {X1,X2,…,Xn} of random variables. Let collision probability Suppose , is close to that of a uniform distribution. Then hashed data is close to uniform. Implications: for d-left hashing, Bloom filters, linear hashing, etc. choosing a hash function from a pairwise independent family should behave like the perfect analysis, if the data has enough entropy.

61
Conclusions and Future Work
Low: Mapping current hashing techniques to hardware is fruitful for practice. Medium: Big boom in hashing-based algorithms/data structures. Trend is likely to continue. Approximate concurrent state machines: Natural progression from set membership to functions (Bloomier filter) to state machines. What is next? Power of d-left hashing variants for near-perfect matchings. High: Wide open. Need to systematize our knowledge for next generation systems. Measurement and monitoring infrastructure built into the system.
 to state machines. What is next Power of d-left hashing variants for near-perfect matchings. High: Wide open. Need to systematize our knowledge for next generation systems. Measurement and monitoring infrastructure built into the system.")
Similar presentations










 Yonsei University 2 nd Semester, 2013 Sanghyun Park.>")
 Hash-Based Indexes Xuemin COMP9315: Database Systems Implementation.>")



 Joint work with Isaac Keslassy (Technion, Israel) and David Hay (Hebrew Univ., Israel)>")



