Download presentation
Presentation is loading. Please wait.

1
©2003 Dror Feitelson Parallel Computing Systems Part I: Introduction Dror Feitelson Hebrew University

2
©2003 Dror Feitelson Topics Overview of the field Architectures: vectors, MPPs, SMPs, and clusters Networks and routing Scheduling parallel jobs Grid computing Evaluating performance

3
©2003 Dror Feitelson Today (and next week?) What is parallel computing Some history The Top500 list The fastest machines in the world Trends and predictions
 What is parallel computing Some history The Top500 list The fastest machines in the world Trends and predictions")
4
©2003 Dror Feitelson What is a Parallel System? In particular, what is the difference between parallel and distributed computing?

5
©2003 Dror Feitelson What is a Parallel System? Chandy: it is related to concurrency. In distributed computing, concurrency is part of the problem. In parallel computing, concurrency is part of the solution.

6
©2003 Dror Feitelson Distributed Systems Concurrency because of physical distribution –Desktops of different users –Servers across the Internet –Branches of a firm –Central bank computer and ATMs Need to coordinate among autonomous systems Need to tolerate failures and disconnections

7
©2003 Dror Feitelson Parallel Systems High-performance computing: solve problems that are to big for a single machine –Get the solution faster (weather forecast) –Get a better solution (physical simulation) Need to parallelize algorithm Need to control overhead Can assume friendly system?
 –Get a better solution (physical simulation) Need to parallelize algorithm Need to control overhead Can assume friendly system")
8
©2003 Dror Feitelson The Convergence Use distributed resources for parallel processing Networks of workstations – use available desktop machines within organization Grids – use available resources (servers?) across organizations Internet computing – use personal PCs across the globe (SETI@home)
 across organizations Internet computing – use personal PCs across the globe")
9
©2003 Dror Feitelson Some History

10
©2003 Dror Feitelson Early HPC Parallel systems in academia/research –1974: C.mmp –1974: Illiac IV –1978: Cm* –1983: Goodyear MPP

11
©2003 Dror Feitelson Illiac IV 1974 SIMD: all processors do the same Numerical calculations at NASA Now in Boston computer museum

12
©2003 Dror Feitelson The Illiac IV in Numbers 64 processors arranged as 8 8 grid Each processor has 10 4 ECL transistors Each processor has 2K 64-bit words (total is 8 Mbit) Arranged in 210 boards Packed in 16 cabinets 500 Mflops peak performance Cost: $31 million
 Arranged in 210 boards Packed in 16 cabinets 500 Mflops peak performance Cost: $31 million")
13
©2003 Dror Feitelson Sustained vs. Peak Peak performance: product of clock rate and number of functional units Sustained rate: what you actually achieve on a real application Sustained is typically much lower than peak –Application does not require all functional units –Need to wait for data to arrive from memory –Need to synchronize –Best for dense matrix operations (Linpack) A rate that the vendor guarantees will not be exceeded
 A rate that the vendor guarantees will not be exceeded.")
14
©2003 Dror Feitelson Early HPC Parallel systems in academia/research –1974: C.mmp –1974: Illiac IV –1978: Cm* –1983: Goodyear MPP Vector systems by Cray and Japanese firms –1976: Cray 1 rated at 160 Mflops peak –1982: Cray X-MP, later Y-MP, C90, … –1985: Cray 2, NEC SX-2

15
©2003 Dror Feitelson Cray’s Achievements Architectural innovations –Vector operations on vector registers –All memory is equally close: no cache –Trade off accuracy and speed Packaging –Short and equally long wires –Liquid cooling systems Style

16
©2003 Dror Feitelson Vector Supercomputers Vector registers store vectors of fast access Vector instructions operate on whole vectors of values –Overhead of instruction decode only once per vector –Pipelined execution of instruction on vector elements: one result per clock tick (at least after pipeline is full) –Possible to chain vector operations: start feeding second functional unit before finishing first one
 –Possible to chain vector operations: start feeding second functional unit before finishing first one")
17
©2003 Dror Feitelson Cray 1 1975 80 MHz clock 160 Mflops peak Liquid cooling World’s most expensive love seat Power supply and cooling under the seat Available in red, blue, black… No operating system

18
©2003 Dror Feitelson Cray 1 Wiring Round configuration for small and uniform distances Longest wire: 4 feet Wires connected manually by extra- small engineers

19
©2003 Dror Feitelson Cray X-MP 1982 1 Gflop Multiprocessor with 2 or 4 Cray1-like processors Shard memory

20
©2003 Dror Feitelson Cray X-MP

21
©2003 Dror Feitelson Cray 2 1985 Smaller and more compact than Cray 1 4 (or 8) processors Total immersion liquid cooling
 processors Total immersion liquid cooling")
22
©2003 Dror Feitelson Cray Y-MP 1988 8 proc’s Achieved 1 Gflop

23
©2003 Dror Feitelson Cray Y-MP – Opened

24
©2003 Dror Feitelson Cray Y-MP – From Back Power supply and cooling

25
©2003 Dror Feitelson Cray C90 1992 1 Gflop per processor 8 or more processors

26
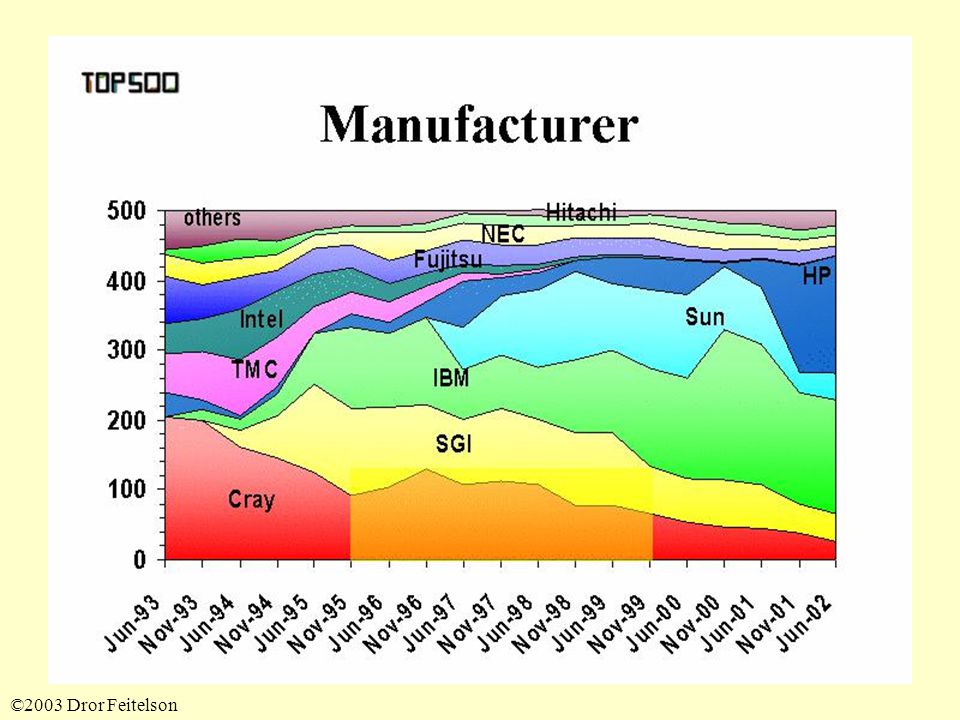
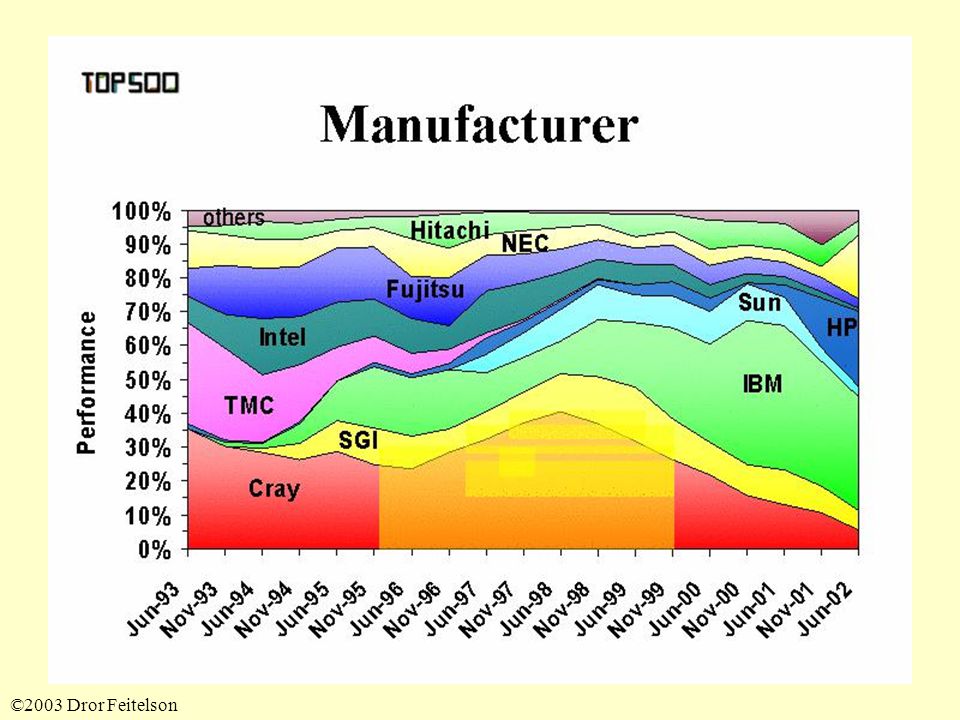
©2003 Dror Feitelson The MPP Boom 1985: Thinking Machines introduces the Connection Machine CM-1 –16K single-bit processors, SIMD –Followed by CM-2, CM-200 –Similar machines by MasPar mid ’80s: hypercubes become successful Also: Transputers used as building blocks Early ’90s: big companies join –IBM, Cray

27
©2003 Dror Feitelson SIMD Array Processors ’80 favorites –Connection machine –Maspar Very many single-bit processors with attached memory – proprietary hardware Single control unit: everything is totally synchronized (SIMD = single instruction multiple data) Massive parallelism even with “correct counting” (i.e. divide by 32)
.")
28
©2003 Dror Feitelson Connection Machine CM-2 Cube of 64K proc’s Acts as backend Hyper- cube topology Data vault for parallel I/O

29
©2003 Dror Feitelson Hypercubes Early ’80s: Caltech 64-node Cosmic Cube Mid to late ’80s: Commercialized by several companies –Intel iPSC, iPSC/2, iPSC/860 –nCUBE, nCUBE 2 (later turned into a VoD server…) Early ’90s: replaced by mesh/torus –Intel Paragon – i860 processors –Cray T3D, T3E – Alpha processors
 Early ’90s: replaced by mesh/torus –Intel Paragon – i860 processors –Cray T3D, T3E – Alpha processors")
30
©2003 Dror Feitelson Transputers A microprocessor with built-in support for communication Programmed using Occam Used in Meiko and other systems PAR SEQ x := 13; c ! x; SEQ c ? y; z := y; -- z is 13 Synchronous communication: an assignment across processes

31
©2003 Dror Feitelson Attack of the Killer Micros Commodity microprocessors advance at a faster rate than vector processors Takeover point was around year 2000 Even before that, using many together could provide lots of power –1992: TMC uses SPARC in CM-5 –1992: Intel uses i860 in Paragon –1993: IBM SP uses RS/6000, later PowerPC –1993: Cray uses Alpha in T3D –Berkeley NoW project

32
©2003 Dror Feitelson Connection Machine CM-5 1992 SPARC-based Fat-tree network Dominant in early ’90s Featured in Jurassic Park Support for gang scheduling!

33
©2003 Dror Feitelson Intel Paragon 1992 2 i860 proc’s per node: –Compute –Commun. Mesh interconnect with spiffi display

34
©2003 Dror Feitelson Cray T3D/T3E 1993 – Cray T3D Uses commodity microprocessors (DEC Alpha) 3D Torus interconnect 1995 – Cray T3E
 3D Torus interconnect 1995 – Cray T3E")
35
©2003 Dror Feitelson IBM SP 1993 16 RS/6000 processors per rack Each runs AIX (full Unix) Multistage network Flexible configurations First large IUCC machine
 Multistage network Flexible configurations First large IUCC machine")
36
©2003 Dror Feitelson Berkeley NoW The building is the computer Just need some glue software…

37
©2003 Dror Feitelson Not Everybody is Convinced… Japan’s computer industry continues to build vector machines NEC –SX series of supercomputers Hitachi –SR series of supercomputers Fujitsu –VPP series of supercomputers Albeit with less style

38
©2003 Dror Feitelson Fujitsu VPP700

39
©2003 Dror Feitelson NEC SX-4

40
©2003 Dror Feitelson More Recent History 1994 – 1995 slump –Cold war is over –Thinking machines files for chapter 11 –KSR Research files for chapter 11 Late ’90s much better –IBM, Cray retain parallel machine market –Later also SGI, Sun, especially with SMPs –ASCI program is started 21 st century: clusters take over –Based on SMPs

41
©2003 Dror Feitelson SMPs Machines with several CPUs Initially small scale: 8-16 processors Later achieved large scale of 64-128 processors Global shared memory accessed via a bus Hard to scale further due to shared memory and cache coherence

42
©2003 Dror Feitelson SGI Challenge 1 to 16 processors Bus interconnect Dominated low end of Top500 list in mid ’90s Not only graphics…

43
©2003 Dror Feitelson SGI Origin An Origin 2000 installed at IUCC MIPS processors Remote memory access

44
©2003 Dror Feitelson Architectural Convergence Shared memory used to be uniform (UMA) –Based on bus or crossbar –Conventional load/store operations Distributed memory used message passing Newer machines support remote memory access –Nonuniform (NUMA): access to remote memory costs more –Put/get operations (but handled by NIC) –Cray T3D/T3E, SGI Origin 2000/3000
 –Based on bus or crossbar –Conventional load/store operations Distributed memory used message passing Newer machines support remote memory access –Nonuniform (NUMA): access to remote memory costs more –Put/get operations (but handled by NIC) –Cray T3D/T3E, SGI Origin 2000/3000")
45
©2003 Dror Feitelson The ASCI Program 1996: nuclear test ban leads to need for simulation of nuclear explosions Accelerated Strategic Computing Initiative: Moore’s law not fast enough… Budget of a billion dollars

46
©2003 Dror Feitelson The Vision Market-driven progress ASCI requirements PathForward Technology transfer Time Performance

47
©2003 Dror Feitelson ASCI Milestones

48
©2003 Dror Feitelson The ASCI Red Machine 9260 processors – PentiumPro 200 Arranged as 4-way SMPs in 86 cabinets 573 GB memory total 2.25 TB disk space total 2 miles of cables 850 KW peak power consumption 44 tons (+300 tons air conditioning equipment) Cost: $55 million
 Cost: $55 million")
49
©2003 Dror Feitelson Clusters vs. MPPs Mix and match approach –PCs/SMPs/blades used as processing nodes –Fast switched network for interconnect –Linux on each node –MPI for software development –Something for management Lower cost to set up Non-trivial to operate effectively

50
©2003 Dror Feitelson SMP Nodes PCs, workstations, or servers with several CPUs Small scale (4-8) used as nodes in MPPs or clusters Access to shared memory via shared L2 cache SMP support (cache coherence) built into modern microprocessors
 used as nodes in MPPs or clusters Access to shared memory via shared L2 cache SMP support (cache coherence) built into modern microprocessors")
51
©2003 Dror Feitelson Myrinet 1995 Switched gigabit LAN –As opposed to Ethernet that is a broadcast medium Programmable NIC –Offload communication operations from the CPU Allows clusters to achieve communication rates of MPPs Very expensive Later: gigabit Ethernet

52
©2003 Dror Feitelson

53
Blades PCs/SMPs require resources –Floor space –Cables for interconnect –Power supplies and fans This is meaningful if you have thousands Blades provide dense packaging With vertical mounting get < 1U on average The hot new thing in 2002

54
©2003 Dror Feitelson SunFire Servers 16 servers in a rack- mounted box Used to be called “single-board computers” in the ’80s (Makbilan)
")
55
©2003 Dror Feitelson The Cray Name 1972: Cray Research founded –Cray 1, X-MP, Cray 2, Y-MP, C90… –From 1993: MPPs T3D, T3E 1989: Cray Computer founded –GaAs efforts, closed 1996: SGI Acquires Cray Research –Attempt to merge T3E and Origin 2000: sold to Tera –Use name to bolster MTA 2002: Cray sells Japanese NEC SX-6 2002: Announces new X1 supercomputer

56
©2003 Dror Feitelson Vectors are not Dead! 1994: Cray T90 –Continues Cray C90 line 1996: Cray J90 –Continues Cray Y-MP line 2000: Cray SV1 2002: Cray X1 –Only “Big-Iron” company left

57
©2003 Dror Feitelson Cray J90 1996 Very popular continuation of Y-MP 8, then 16, then 32 processors One installed at IUCC

58
©2003 Dror Feitelson Cray X1 2002 Up to 1024 nodes 4 custom vector proc’s per node 12.8 GFlops peak each Torus interconnect

59
©2003 Dror Feitelson Confused?

60
©2003 Dror Feitelson The Top500 List List of the 500 most powerful computer installations in the world Separates academic chic from real impact Measured using Linpack –Dense matrix operations –Might not be representative of real applications

61
©2003 Dror Feitelson

65
The Competition How to achieve a rank: Few vector processors –Maximize power per processor –High efficiency Many commodity processors –Ride technology curve –Power in numbers –Low efficiency

66
©2003 Dror Feitelson Vector Programming Conventional Fortran Automatic vectorization of loops by compiler Autotasking uses processors that happen to be available at runtime to execute chunks of loop iterations Easy for application writers Very high efficiency

67
©2003 Dror Feitelson MPP Programming Library added to programming language –MPI for distributed memory –OpenMP for shared memory Applications need to be partitioned manually Many possible efficiency losses –Fragmentation in allocating processors –Stalls waiting for memory and communication –Imbalance among threads Hard for programmers

68
©2003 Dror Feitelson Also National Competition Japan Inc. is “more Cray than Cray” –Computers based on few but powerful proprietary vector processors –Numerical wind tunnel at rank 1 from 1993 to 1995 –CP-PACS at rank 1 in 1996 –Earth simulator at rank 1 in 2003 US industry switched to commodity microprocessors –Even Cray did –ASCI machines at rank 1 in 1997—2002

69
©2003 Dror Feitelson Vectors vs. MPPs – 1994 Feitelson, Int. J. High-Perf. Comput. App., 1999

70
©2003 Dror Feitelson Vectors vs. MPPs – 1997

71
©2003 Dror Feitelson Vectors vs. MPPs – 1997

72
©2003 Dror Feitelson The Current Situation

73
©2003 Dror Feitelson Real Usage Control functions for telecomm companies Reservoir modeling for oil companies Graphic rendering for Hollywood Financial modeling for Wall Street Drug design for pharmaceuticals Weather prediction Airplane design for Boeing and Airbus Hush-hush activities

74
©2003 Dror Feitelson

75
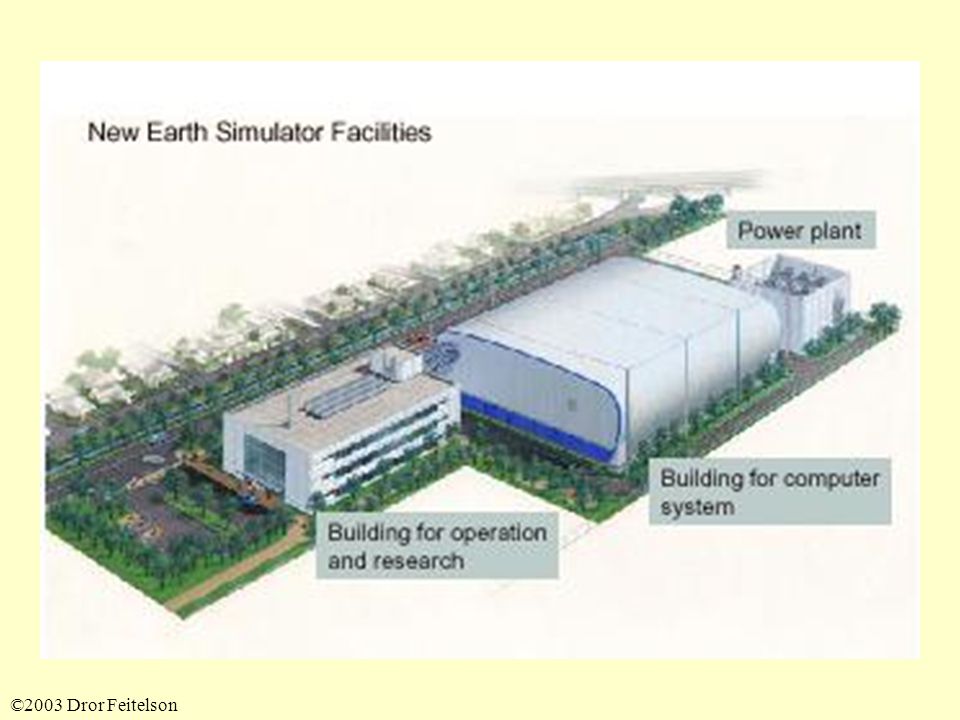
The Earth Simulator Operational in late 2002 Top rank in Top500 list Result of 5-year design and implementation effort Equivalent power to top 15 US machines (including all ASCI machines) Really big
 Really big")
76
©2003 Dror Feitelson

81
The Earth Simulator in Numbers 640 nodes 8 vector processors per node, 5120 total 8 Gflops per processor, 40 Tflops total 16 GB memory per node, 10 TB total 2800 km of cables 320 cabinets (2 nodes each) Cost: $ 350 million
 Cost: $ 350 million")
82
©2003 Dror Feitelson Trends

83
©2003 Dror Feitelson

84
Exercise Look at 10 years of Top500 lists and try to say something non-trivial about trends Are there things that grow? Are there things that stay the same? Can you make predictions?

85
©2003 Dror Feitelson Distribution of Vendors – 1994 Feitelson, Int. J. High-Perf. Comput. App., 1999

86
©2003 Dror Feitelson Distribution of Vendors – 1997

87
©2003 Dror Feitelson IBM in the Lists Arrows are the ANL SP1 with 128 processors Rank doubles each year

88
©2003 Dror Feitelson Minimal Parallelism

89
©2003 Dror Feitelson Min vs. Max

90
©2003 Dror Feitelson Power with Time Rmax of last machine doubles each year This is 8-fold in three years Degree of parallelism doubles every three years So power of each processor increases 4-fold in three years (=doubles in 18 months) Which is Moore’s Law…
 Which is Moore’s Law…")
91
©2003 Dror Feitelson Distribution of Power Rank of machines doubles each year Power of rank 500 machine doubles each year So rank 250 machine this year has double the power of rank 500 machine this year And rank 125 machine has double the power of rank 250 machine In short, power decreases exponentially with rank

92
©2003 Dror Feitelson Power and Rank

93
©2003 Dror Feitelson Power and Rank

94
©2003 Dror Feitelson Power and Rank

95
©2003 Dror Feitelson Power and Rank The slope is becoming flatter 19940.978 19950.865 19960.839 19970.816 19980.777 19990.761 20000.800 20010.753 20020.746

96
©2003 Dror Feitelson Machine Ages in Lists

97
©2003 Dror Feitelson New Machines

98
©2003 Dror Feitelson Industry Share

99
©2003 Dror Feitelson Vector Share

100
©2003 Dror Feitelson Summary Invariants of the last few years: Power grows exponentially with time Parallelism grows exponentially with time But maximal usable parallelism is ~10000 Power drops polynomially with rank Age in the list drops exponentially About 300 new machines each year About 50% of machines in industry About 15% of power due to vector processors

Similar presentations





 Each processor has uniform access time to memory - also known as symmetric multiprocessors (SMPs) (example: SUN ES1000) Non-uniform.>")

















