Download presentation
Presentation is loading. Please wait.

1
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Principles and Applications of Probabilistic Learning Padhraic Smyth Department of Computer Science University of California, Irvine www.ics.uci.edu/~smyth

2
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 New Slides Original slides created in mid-July for ACM –Some new slides have been added “new” logo in upper left NEW

3
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 New Slides Original slides created in mid-July for ACM –Some new slides have been added “new” logo in upper left –A few slides have been updated “updated” logo in upper left Current slides (including new and updated) at: www.ics.uci.edu/~smyth/talks UPDATED
 at: UPDATED.")
4
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 From the tutorial Web page: “The intent of this tutorial is to provide a starting point for students and researchers……” NEW

5
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Modeling vs. Function Approximation Two major themes in machine learning: 1. Function approximation/”black box” methods e.g., for classification and regression Learn a flexible function y = f(x) e.g., SVMs, decision trees, boosting, etc 2. Probabilistic learning e.g., for regression, model p(y|x) or p(y,x) e.g, graphical models, mixture models, hidden Markov models, etc Both approaches are useful in general –In this tutorial we will focus only on the 2 nd approach, probabilistic modeling
 e.g., SVMs, decision trees, boosting, etc 2. Probabilistic learning e.g., for regression, model p(y|x) or p(y,x) e.g, graphical models, mixture models, hidden Markov models, etc Both approaches are useful in general –In this tutorial we will focus only on the 2 nd approach, probabilistic modeling.")
6
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Motivations for Probabilistic Modeling leverage prior knowledge generalize beyond data analysis in vector-spaces handle missing data combine multiple types of information into an analysis generate calibrated probability outputs quantify uncertainty about parameters, models, and predictions in a statistical manner

7
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning object models in vision Weber, Welling, Perona, 2000 NEW

8
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning object models in vision Weber, Welling, Perona, 2000 NEW

9
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning to Extract Information from Documents e.g., Seymore, McCallum, Rosenfeld, 1999 NEW

10
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 NEW

11
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 NEW Segal, Friedman, Koller, et al, Nature Genetics, 2005

12
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Model Real World Data P(Data | Parameters)
.")
13
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Model Real World Data P(Data | Parameters) P(Parameters | Data)
 P(Parameters | Data).")
14
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Model Real World Data P(Data | Parameters) P(Parameters | Data) (Generative Model) (Inference)
 P(Parameters | Data) (Generative Model) (Inference).")
15
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Outline 1.Review of probability 2.Graphical models 3.Connecting probability models to data 4.Models with hidden variables 5.Case studies (i) Simulating and forecasting rainfall data (ii) Curve clustering with cyclone trajectories (iii) Topic modeling from text documents
 Simulating and forecasting rainfall data (ii) Curve clustering with cyclone trajectories (iii) Topic modeling from text documents.")
16
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Part 1: Review of Probability

17
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Notation and Definitions X is a random variable –Lower-case x is some possible value for X –“X = x” is a logical proposition: that X takes value x –There is uncertainty about the value of X e.g., X is the Dow Jones index at 5pm tomorrow p(X = x) is the probability that proposition X=x is true –often shortened to p(x) If the set of possible x’s is finite, we have a probability distribution and p(x) = 1 If the set of possible x’s is infinite, p(x) is a density function, and p(x) integrates to 1 over the range of X
 is the probability that proposition X=x is true –often shortened to p(x) If the set of possible x’s is finite, we have a probability distribution and p(x) = 1 If the set of possible x’s is infinite, p(x) is a density function, and p(x) integrates to 1 over the range of X.")
18
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example Let X be the Dow Jones Index (DJI) at 5pm Monday August 22 nd (tomorrow) X can take real values from 0 to some large number p(x) is a density representing our uncertainty about X –This density could be constructed from historical data, e.g., –After 5pm p(x) becomes infinitely narrow around the true known x (no uncertainty)
 at 5pm Monday August 22 nd (tomorrow) X can take real values from 0 to some large number p(x) is a density representing our uncertainty about X –This density could be constructed from historical data, e.g., –After 5pm p(x) becomes infinitely narrow around the true known x (no uncertainty).")
19
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probability as Degree of Belief Different agents can have different p(x)’s –Your p(x) and the p(x) of a Wall Street expert might be quite different –OR: if we were on vacation we might not have access to stock market information we would still be uncertain about p(x) after 5pm So we should really think of p(x) as p(x | B I ) –Where B I is background information available to agent I –(will drop explicit conditioning on B I in notation) Thus, p(x) represents the degree of belief that agent I has in proposition x, conditioned on available background information
’s –Your p(x) and the p(x) of a Wall Street expert might be quite different –OR: if we were on vacation we might not have access to stock market information we would still be uncertain about p(x) after 5pm So we should really think of p(x) as p(x | B I ) –Where B I is background information available to agent I –(will drop explicit conditioning on B I in notation) Thus, p(x) represents the degree of belief that agent I has in proposition x, conditioned on available background information.")
20
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Comments on Degree of Belief Different agents can have different probability models –There is no necessarily “correct” p(x) –Why? Because p(x) is a model built on whatever assumptions or background information we use –Naturally leads to the notion of updating p(x | B I ) -> p(x | B I, C I ) This is the subjective Bayesian interpretation of probability –Generalizes other interpretations (such as frequentist) –Can be used in cases where frequentist reasoning is not applicable –We will use “degree of belief” as our interpretation of p(x) in this tutorial Note! –Degree of belief is just our semantic interpretation of p(x) –The mathematics of probability (e.g., Bayes rule) remain the same regardless of our semantic interpretation
 –Why. Because p(x) is a model built on whatever assumptions or background information we use –Naturally leads to the notion of updating p(x | B I ) -> p(x | B I, C I ) This is the subjective Bayesian interpretation of probability –Generalizes other interpretations (such as frequentist) –Can be used in cases where frequentist reasoning is not applicable –We will use degree of belief as our interpretation of p(x) in this tutorial Note. –Degree of belief is just our semantic interpretation of p(x) –The mathematics of probability (e.g., Bayes rule) remain the same regardless of our semantic interpretation.")
21
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Multiple Variables p(x, y, z) –Probability that X=x AND Y=y AND Z =z –Possible values: cross-product of X Y Z –e.g., X, Y, Z each take 10 possible values x,y,z can take 10 3 possible values p(x,y,z) is a 3-dimensional array/table –Defines 10 3 probabilities Note the exponential increase as we add more variables –e.g., X, Y, Z are all real-valued x,y,z live in a 3-dimensional vector space p(x,y,z) is a positive function defined over this space, integrates to 1
 –Probability that X=x AND Y=y AND Z =z –Possible values: cross-product of X Y Z –e.g., X, Y, Z each take 10 possible values x,y,z can take 10 3 possible values p(x,y,z) is a 3-dimensional array/table –Defines 10 3 probabilities Note the exponential increase as we add more variables –e.g., X, Y, Z are all real-valued x,y,z live in a 3-dimensional vector space p(x,y,z) is a positive function defined over this space, integrates to 1.")
22
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Conditional Probability p(x | y, z) –Probability of x given that Y=y and Z = z –Could be hypothetical, e.g., “if Y=y and if Z = z” observational, e.g., we observed values y and z –can also have p(x, y | z), etc –“all probabilities are conditional probabilities” Computing conditional probabilities is the basis of many prediction and learning problems, e.g., –p(DJI tomorrow | DJI index last week) –expected value of [DJI tomorrow | DJI index next week) –most likely value of parameter given observed data
 –Probability of x given that Y=y and Z = z –Could be hypothetical, e.g., if Y=y and if Z = z observational, e.g., we observed values y and z –can also have p(x, y | z), etc – all probabilities are conditional probabilities Computing conditional probabilities is the basis of many prediction and learning problems, e.g., –p(DJI tomorrow | DJI index last week) –expected value of [DJI tomorrow | DJI index next week) –most likely value of parameter given observed data.")
23
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Computing Conditional Probabilities Variables A, B, C, D –All distributions of interest related to A,B,C,D can be computed from the full joint distribution p(a,b,c,d) Examples, using the Law of Total Probability –p(a) = {b,c,d} p(a, b, c, d) –p(c,d) = {a,b} p(a, b, c, d) –p(a,c | d) = {b} p(a, b, c | d) where p(a, b, c | d) = p(a,b,c,d)/p(d) These are standard probability manipulations: however, we will see how to use these to make inferences about parameters and unobserved variables, given data
 Examples, using the Law of Total Probability –p(a) = {b,c,d} p(a, b, c, d) –p(c,d) = {a,b} p(a, b, c, d) –p(a,c | d) = {b} p(a, b, c | d) where p(a, b, c | d) = p(a,b,c,d)/p(d) These are standard probability manipulations: however, we will see how to use these to make inferences about parameters and unobserved variables, given data.")
24
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Conditional Independence A is conditionally independent of B given C iff p(a | b, c) = p(a | c) (also implies that B is conditionally independent of A given C) In words, B provides no information about A, if value of C is known Example: –a = “patient has upset stomach” –b = “patient has headache” –c = “patient has flu” Note that conditional independence does not imply marginal independence
 = p(a | c) (also implies that B is conditionally independent of A given C) In words, B provides no information about A, if value of C is known Example: –a = patient has upset stomach –b = patient has headache –c = patient has flu Note that conditional independence does not imply marginal independence.")
25
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Two Practical Problems (Assume for simplicity each variable takes K values) Problem 1: Computational Complexity –Conditional probability computations scale as O(K N ) where N is the number of variables being summed over Problem 2: Model Specification –To specify a joint distribution we need a table of O(K N ) numbers –Where do these numbers come from?
 Problem 1: Computational Complexity –Conditional probability computations scale as O(K N ) where N is the number of variables being summed over Problem 2: Model Specification –To specify a joint distribution we need a table of O(K N ) numbers –Where do these numbers come from .")
26
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Two Key Ideas Problem 1: Computational Complexity –Idea: Graphical models Structured probability models lead to tractable inference Problem 2: Model Specification –Idea: Probabilistic learning General principles for learning from data

27
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Part 2: Graphical Models

28
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 “…probability theory is more fundamentally concerned with the structure of reasoning and causation than with numbers.” Glenn Shafer and Judea Pearl Introduction to Readings in Uncertain Reasoning, Morgan Kaufmann, 1990

29
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Models Represent dependency structure with a directed graph –Node random variable –Edges encode dependencies Absence of edge -> conditional independence –Directed and undirected versions Why is this useful? –A language for communication –A language for computation Origins: –Wright 1920’s –Independently developed by Spiegelhalter and Lauritzen in statistics and Pearl in computer science in the late 1980’s

30
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of 3-way Graphical Models ACB Marginal Independence: p(A,B,C) = p(A) p(B) p(C)
 = p(A) p(B) p(C).")
31
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of 3-way Graphical Models A CB Conditionally independent effects: p(A,B,C) = p(B|A)p(C|A)p(A) B and C are conditionally independent Given A e.g., A is a disease, and we model B and C as conditionally independent symptoms given A
 = p(B|A)p(C|A)p(A) B and C are conditionally independent Given A e.g., A is a disease, and we model B and C as conditionally independent symptoms given A.")
32
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of 3-way Graphical Models A B C Independent Causes: p(A,B,C) = p(C|A,B)p(A)p(B)
 = p(C|A,B)p(A)p(B).")
33
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of 3-way Graphical Models ACB Markov dependence: p(A,B,C) = p(C|B) p(B|A)p(A)
 = p(C|B) p(B|A)p(A).")
34
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Real-World Example Monitoring Intensive-Care Patients 37 variables 509 parameters …instead of 2 37 (figure courtesy of Kevin Murphy/Nir Friedman) PCWP CO HRBP HREKG HRSAT ERRCAUTER HR HISTORY CATECHOL SAO2 EXPCO2 ARTCO2 VENTALV VENTLUNG VENITUBE DISCONNECT MINVOLSET VENTMACH KINKEDTUBE INTUBATIONPULMEMBOLUS PAPSHUNT ANAPHYLAXIS MINOVL PVSAT FIO2 PRESS INSUFFANESTHTPR LVFAILURE ERRBLOWOUTPUT STROEVOLUMELVEDVOLUME HYPOVOLEMIA CVP BP
 PCWP CO HRBP HREKG HRSAT ERRCAUTER HR HISTORY CATECHOL SAO2 EXPCO2 ARTCO2 VENTALV VENTLUNG VENITUBE DISCONNECT MINVOLSET VENTMACH KINKEDTUBE INTUBATIONPULMEMBOLUS PAPSHUNT ANAPHYLAXIS MINOVL PVSAT FIO2 PRESS INSUFFANESTHTPR LVFAILURE ERRBLOWOUTPUT STROEVOLUMELVEDVOLUME HYPOVOLEMIA CVP BP.")
35
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Directed Graphical Models A B C p(A,B,C) = p(C|A,B)p(A)p(B)
 = p(C|A,B)p(A)p(B).")
36
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Directed Graphical Models A B C In general, p(X 1, X 2,....X N ) = p(X i | parents(X i ) ) p(A,B,C) = p(C|A,B)p(A)p(B)
 = p(X i | parents(X i ) ) p(A,B,C) = p(C|A,B)p(A)p(B).")
37
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Directed Graphical Models A B C Probability model has simple factored form Directed edges => direct dependence Absence of an edge => conditional independence Also known as belief networks, Bayesian networks, causal networks In general, p(X 1, X 2,....X N ) = p(X i | parents(X i ) ) p(A,B,C) = p(C|A,B)p(A)p(B)
 = p(X i | parents(X i ) ) p(A,B,C) = p(C|A,B)p(A)p(B).")
38
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B C F E G

39
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B C F E G p(A, B, C, D, E, F, G) = p( variable | parents ) = p(A|B)p(C|B)p(B|D)p(F|E)p(G|E)p(E|D) p(D)
 = p( variable | parents ) = p(A|B)p(C|B)p(B|D)p(F|E)p(G|E)p(E|D) p(D).")
40
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Say we want to compute p(a | c, g)
.")
41
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Direct calculation: p(a|c,g) = bdef p(a,b,d,e,f | c,g) Complexity of the sum is O(K 4 )
 = bdef p(a,b,d,e,f | c,g) Complexity of the sum is O(K 4 ).")
42
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Reordering (using factorization): b p(a|b) d p(b|d,c) e p(d|e) f p(e,f |g)
: b p(a|b) d p(b|d,c) e p(d|e) f p(e,f |g).")
43
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Reordering: b p(a|b) d p(b|d,c) e p(d|e) f p(e,f |g) p(e|g)
 d p(b|d,c) e p(d|e) f p(e,f |g) p(e|g).")
44
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Reordering: b p(a|b) d p(b|d,c) e p(d|e) p(e|g) p(d|g)
 d p(b|d,c) e p(d|e) p(e|g) p(d|g).")
45
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Reordering: b p(a|b) d p(b|d,c) p(d|g) p(b|c,g)
 d p(b|d,c) p(d|g) p(b|c,g).")
46
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example D A B c F E g Reordering: b p(a|b) p(b|c,g) p(a|c,g) Complexity is O(K), compared to O(K 4 )
 p(b|c,g) p(a|c,g) Complexity is O(K), compared to O(K 4 ).")
47
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 A More General Algorithm Message Passing (MP) Algorithm –Pearl, 1988; Lauritzen and Spiegelhalter, 1988 –Declare 1 node (any node) to be a root –Schedule two phases of message-passing nodes pass messages up to the root messages are distributed back to the leaves –In time O(N), we can compute P(….)
 Algorithm –Pearl, 1988; Lauritzen and Spiegelhalter, 1988 –Declare 1 node (any node) to be a root –Schedule two phases of message-passing nodes pass messages up to the root messages are distributed back to the leaves –In time O(N), we can compute P(….).")
48
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Sketch of the MP algorithm in action

49
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Sketch of the MP algorithm in action 1

50
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Sketch of the MP algorithm in action 1 2

51
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Sketch of the MP algorithm in action 1 2 3

52
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Sketch of the MP algorithm in action 1 2 3 4

53
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Complexity of the MP Algorithm Efficient –Complexity scales as O(N K m ) N = number of variables K = arity of variables m = maximum number of parents for any node –Compare to O(K N ) for brute-force method
 N = number of variables K = arity of variables m = maximum number of parents for any node –Compare to O(K N ) for brute-force method.")
54
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphs with “loops” D A B C F E G Message passing algorithm does not work when there are multiple paths between 2 nodes

55
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphs with “loops” D A B C F E G General approach: “cluster” variables together to convert graph to a tree

56
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Reduce to a Tree D A B, E C F G

57
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Reduce to a Tree D A B, E C F G Good news: can perform MP algorithm on this tree Bad news: complexity is now O(K 2 )
.")
58
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probability Calculations on Graphs Structure of the graph reveals –Computational strategy –Dependency relations Complexity is typically O(K max(number of parents) ) –If single parents (e.g., tree), -> O(K) –The sparser the graph the lower the complexity Technique can be “automated” –i.e., a fully general algorithm for arbitrary graphs –For continuous variables: replace sum with integral –For identification of most likely values Replace sum with max operator
 ) –If single parents (e.g., tree), -> O(K) –The sparser the graph the lower the complexity Technique can be automated –i.e., a fully general algorithm for arbitrary graphs –For continuous variables: replace sum with integral –For identification of most likely values Replace sum with max operator.")
59
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Hidden Markov Model (HMM) Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn - - - - - - - - - - - - - - - - - - - - - - - - - - Observed Hidden Two key assumptions: 1. hidden state sequence is Markov 2. observation Y t is CI of all other variables given S t Widely used in speech recognition, protein sequence models Motivation: switching dynamics, low-d representation of Y’s, etc
 Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn Observed Hidden Two key assumptions: 1. hidden state sequence is Markov 2. observation Y t is CI of all other variables given S t Widely used in speech recognition, protein sequence models Motivation: switching dynamics, low-d representation of Y’s, etc.")
60
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 HMMs as graphical models… Computations of interest p( Y ) = p(Y, S = s) -> “forward-backward” algorithm arg max s p(S = s | Y) -> Viterbi algorithm Both algorithms…. –computation time linear in T –special cases of MP algorithm Many generalizations and extensions…. –Make state S continuous -> Kalman filters –Add inputs -> convolutional decoding –Add additional dependencies in the model Generalized HMMs
 = p(Y, S = s) -> forward-backward algorithm arg max s p(S = s | Y) -> Viterbi algorithm Both algorithms…. –computation time linear in T –special cases of MP algorithm Many generalizations and extensions…. –Make state S continuous -> Kalman filters –Add inputs -> convolutional decoding –Add additional dependencies in the model Generalized HMMs.")
61
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Part 3: Connecting Probability Models to Data Recommended References for this Section: All of Statistics, L. Wasserman, Chapman and Hall, 2004 (Chapters 6,9,11) Pattern Classification and Scene Analysis, 1 st ed, R. Duda and P. Hart, Wiley, 1973, Chapter 3.
 Pattern Classification and Scene Analysis, 1 st ed, R. Duda and P. Hart, Wiley, 1973, Chapter 3..")
62
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Model Real World Data P(Data | Parameters) P(Parameters | Data) (Generative Model) (Inference)
 P(Parameters | Data) (Generative Model) (Inference).")
63
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Conditionally Independent Observations y1y1 Data Model parameters y2y2 y n-1 ynyn NEW

64
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 “Plate” Notation yiyi i=1:n Data = {y 1,…y n } Model parameters Plate = rectangle in graphical model variables within a plate are replicated in a conditionally independent manner

65
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example: Gaussian Model yiyi i=1:n Generative model: p(y 1,…y n | ) = p(y i | ) = p(data | parameters) = p(D | ) where = { }
 = p(y i | ) = p(data | parameters) = p(D | ) where = { } .")
66
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The Likelihood Function Likelihood = p(data | parameters) = p( D | ) = L ( ) Likelihood tells us how likely the observed data are conditioned on a particular setting of the parameters Details –Constants that do not involve can be dropped in defining L ( ) –Often easier to work with log L ( )
 = p( D | ) = L ( ) Likelihood tells us how likely the observed data are conditioned on a particular setting of the parameters Details –Constants that do not involve can be dropped in defining L ( ) –Often easier to work with log L ( ).")
67
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Comments on the Likelihood Function Constructing a likelihood function L ( ) is the first step in probabilistic modeling The likelihood function implicitly assumes an underlying probabilistic model M with parameters L ( ) connects the model to the observed data Graphical models provide a useful language for constructing likelihoods
 is the first step in probabilistic modeling The likelihood function implicitly assumes an underlying probabilistic model M with parameters L ( ) connects the model to the observed data Graphical models provide a useful language for constructing likelihoods.")
68
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Binomial Likelihood Binomial model –N memoryless trials –probability of success at each trial Observed data –r successes in n trials –Defines a likelihood: L( ) = p(D | ) = p(succeses) p(non-successes) = r (1- ) n-r NEW yiyi i=1:n
 = p(D | ) = p(succeses) p(non-successes) = r (1- ) n-r NEW yiyi i=1:n .")
69
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Binomial Likelihood Examples NEW

70
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Gaussian Model and Likelihood Model assumptions: 1. y’s are conditionally independent given model 2. each y comes from a Gaussian (Normal) density
 density.")
71
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

72
Conditional Independence (CI) CI in a likelihood model means that we are assuming data points provide no information about each other, if the model parameters are assumed known. p( D | ) = p(y 1,… y N | ) = p(y i | ) Works well for (e.g.) –Patients randomly arriving at a clinic –Web surfers randomly arriving at a Web site Does not work well for –Time-dependent data (e.g., stock market) –Spatial data (e.g., pixel correlations) CI assumption
 = p(y 1,… y N | ) = p(y i | ) Works well for (e.g.) –Patients randomly arriving at a clinic –Web surfers randomly arriving at a Web site Does not work well for –Time-dependent data (e.g., stock market) –Spatial data (e.g., pixel correlations) CI assumption.")
73
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example: Markov Likelihood Motivation: wish to model data in a sequence where there is sequential dependence, –e.g., a first-order Markov chain for a DNA sequence –Markov modeling assumption: p(y t | y t-1, y t-2, …y t ) = p(y t | y t-1 ) – = matrix of K x K transition matrix probabilities L( ) = p( D | ) = p(y 1,… y N | ) = p(y t | y t-1, )
 = p(y t | y t-1 ) – = matrix of K x K transition matrix probabilities L( ) = p( D | ) = p(y 1,… y N | ) = p(y t | y t-1, ).")
74
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Maximum Likelihood (ML) Principle (R. Fisher ~ 1922) yiyi i=1:n L () = p(Data | ) = p(y i | ) Maximum Likelihood: ML = arg max{ Likelihood() } Select the parameters that make the observed data most likely Data = {y 1,…y n } Model parameters
 Principle (R. Fisher ~ 1922) yiyi i=1:n L () = p(Data | ) = p(y i | ) Maximum Likelihood: ML = arg max{ Likelihood() } Select the parameters that make the observed data most likely Data = {y 1,…y n } Model parameters.")
75
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example: ML for Gaussian Model Maximum Likelhood Estimate ML

76
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Maximizing the Likelihood More generally, we analytically solve for the value that maximizes the function L () –With p parameters, L () is a scalar function defined over a p-dimensional space –2 situations: We can analytically solve for the maxima of L () –This is rare We have to resort to iterative techniques to find ML –More common General approach –Define a generative probabilistic model –Define an associated likelihood (connect model to data) –Solve an optimization problem to find ML
 –With p parameters, L () is a scalar function defined over a p-dimensional space –2 situations: We can analytically solve for the maxima of L () –This is rare We have to resort to iterative techniques to find ML –More common General approach –Define a generative probabilistic model –Define an associated likelihood (connect model to data) –Solve an optimization problem to find ML.")
77
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Analytical Solution for Gaussian Likelihood

78
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Model for Regression yiyi i=1:n xixi

79
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example x y

80
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example f(x ; ) this is unknown x y
 this is unknown x y.")
81
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example: ML for Linear Regression Generative model: y = ax + b + Gaussian noise p(y) = N(ax + b, ) Conditional Likelihood L() = p(y 1,… y N | x 1,… x N, ) = p(y i | x i, ), {a, b} Can show (homework problem!) that log L() = - [y i - (a x i – b) ] 2 i.e., finding a,b to maximize log- likelihood is the same as finding a,b that minimizes least squares
 = N(ax + b, ) Conditional Likelihood L() = p(y 1,… y N | x 1,… x N, ) = p(y i | x i, ), {a, b} Can show (homework problem!) that log L() = - [y i - (a x i – b) ] 2 i.e., finding a,b to maximize log- likelihood is the same as finding a,b that minimizes least squares.")
82
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 ML and Regression Multivariate case –multiple x’s, multiple regression coefficients –with Gaussian noise, the ML solution is again equivalent to least- squares (solutions to a set of linear equations) Non-linear multivariate model –With Gaussian noise we get log L() = - [y i - f (x i ; ) ] 2 –Conditions for the q that maximizes L() leads to a set of p non- linear equations in p variables –e.g., f (x i ; ) = a multilayer neural network with 1000 weights Optimization = finding the maximum of a non-convex function in 1000 dimensional space! Typically use iterative local search based on gradient (many possible variations)
 Non-linear multivariate model –With Gaussian noise we get log L() = - [y i - f (x i ; ) ] 2 –Conditions for the q that maximizes L() leads to a set of p non- linear equations in p variables –e.g., f (x i ; ) = a multilayer neural network with 1000 weights Optimization = finding the maximum of a non-convex function in 1000 dimensional space. Typically use iterative local search based on gradient (many possible variations).")
83
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Learning and Classification 2 main approaches: 1. p(c | x) = p(x|c) p(c) / p(x) ~ p(x|c) p(c) -> learn a model for p(x|c) for each class, use Bayes rule to classify - example: naïve Bayes - advantage: theoretically optimal if p(x|c) is “correct” - disadvantage: not directly optimizing predictive accuracy 2.Learn p(c|x) directly, e.g., –logistic regression (see tutorial notes from D. Lewis) –other regression methods such as neural networks, etc. –Often quite effective in practice: very useful for ranking, scoring, etc –Contrast with purely discriminative methods such as SVMs, trees NEW
 = p(x|c) p(c) / p(x) ~ p(x|c) p(c) -> learn a model for p(x|c) for each class, use Bayes rule to classify - example: naïve Bayes - advantage: theoretically optimal if p(x|c) is correct - disadvantage: not directly optimizing predictive accuracy 2.Learn p(c|x) directly, e.g., –logistic regression (see tutorial notes from D. Lewis) –other regression methods such as neural networks, etc. –Often quite effective in practice: very useful for ranking, scoring, etc –Contrast with purely discriminative methods such as SVMs, trees NEW.")
84
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The Bayesian Approach to Learning yiyi i=1:n Maximum A Posteriori: MAP = arg max{ Likelihood() x Prior() } Fully Bayesian: p( | Data) = p(Data | ) p() / p(Data) Prior() = p( )
 x Prior() } Fully Bayesian: p( | Data) = p(Data | ) p() / p(Data) Prior() = p( ).")
85
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The Bayesian Approach yiyi i=1:n Fully Bayesian: p( | Data) = p(Data | ) p() / p(Data) = Likelihood x Prior / Normalization term Estimating p( | Data) can be viewed as inference in a graphical model ML is a special case = MAP with a “flat” prior
 = p(Data | ) p() / p(Data) = Likelihood x Prior / Normalization term Estimating p( | Data) can be viewed as inference in a graphical model ML is a special case = MAP with a flat prior .")
86
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 More Comments on Bayesian Learning “fully” Bayesian: report full posterior density p( |D) –For simple models, we can calculate p( |D) analytically –Otherwise we empirically estimate p( |D) Monte Carlo sampling methods are very useful Bayesian prediction (e.g., for regression): p(y | x, D ) = integral p(y, | x, D) d = integral p(y | , x) p( |D) d -> prediction at each is weighted by p(|D) [theoretically preferable to picking a single (as in ML)]
 –For simple models, we can calculate p( |D) analytically –Otherwise we empirically estimate p( |D) Monte Carlo sampling methods are very useful Bayesian prediction (e.g., for regression): p(y | x, D ) = integral p(y, | x, D) d = integral p(y | , x) p( |D) d -> prediction at each is weighted by p(|D) [theoretically preferable to picking a single (as in ML)].")
87
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 More Comments on Bayesian Learning In practice… –Fully Bayesian is theoretically optimal but not always the most practical approach E.g., computational limitations with large numbers of parameters assessing priors can be tricky Bayesian approach particularly useful for small data sets For large data sets, Bayesian, MAP, ML tend to agree –ML/MAP are much simpler => often used in practice

88
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example of Bayesian Estimation Definition of Beta prior Definition of Binomial likelihood Form of Beta posterior Examples of plots with prior+likelihood -> posterior

89
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Beta Density as a Prior Let be a proportion, –e.g., fraction of customers that respond to an email ad –p( ) is a prior for –e.g. p( ) = Beta density with parameters and p( ) ~ -1 (1- ) -1 /( + ) influences the location + controls the width NEW
 is a prior for –e.g. p( ) = Beta density with parameters and p( ) ~ -1 (1- ) -1 /( + ) influences the location + controls the width NEW .")
90
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of Beta Density Priors NEW

91
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Binomial Likelihood Binomial model –N memoryless trials –probability of success at each trial Observed data –r successes in n trials –Defines a likelihood: p(D | ) = p(succeses) p(non-successes) = r (1- ) n-r NEW
 = p(succeses) p(non-successes) = r (1- ) n-r NEW.")
92
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Beta + Binomial -> Beta p( | D) = Posterior ~ Likelihood x Prior = Binomial x Beta ~ r (1- ) n-r x -1 (1- ) -1 = Beta( + r, + n – r) Prior is “updated” using data: Parameters : -> +r, -> + n – r Sample size: + -> + + n Mean: /( + ) -> ( + r)/( + + n) NEW
 = Posterior ~ Likelihood x Prior = Binomial x Beta ~ r (1- ) n-r x -1 (1- ) -1 = Beta( + r, + n – r) Prior is updated using data: Parameters : -> +r, -> + n – r Sample size: + -> + + n Mean: /( + ) -> ( + r)/( + + n) NEW.")
93
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 NEW

94
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 NEW

95
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 NEW

96
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Extensions K categories with K probabilities that sum to 1 –Dirichlet prior + Multinomial likelihood -> Dirichlet posterior –Used in text modeling, protein alignment algorithms, etc E.g. Biological Sequence Analysis, R. Durbin et al., Cambridge University Press, 1998. Hierarchical modeling –Multiple trials for different individuals –Each individual has their own –The ’s ~ common population distribution –For applications in marketing see Market Segmentation: Conceptual and Methodological Foundations, M. Wedel and W. A. Kamakura, Kluwer, 1998 NEW

97
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example: Bayesian Gaussian Model yiyi i=1:n Note: priors and parameters are assumed independent here

98
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example: Bayesian Regression yiyi i=1:n Model: y i = f [x i ;] + e, e ~ N(0, ) p(y i | x i ) ~ N ( f[x i ;], ) xixi
 p(y i | x i ) ~ N ( f[x i ;], ) xixi.")
99
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Other Examples Bayesian examples –Bayesian neural networks Richer probabilistic models –Random effects models –E.g., Learning to align curves Learning model structure –Chow-Liu trees –General graphical model structures e.g. gene regulation networks Comprehensive reference: Bayesian Data Analysis, A. Gelman, J. B. Carlin. H. S. Stern, and D. B. Rubin, Chapman and Hall, 2 nd edition, 2003. UPDATED

100
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning Shapes and Shifts Original data Data after Learning Data = smoothed growth acceleration data from teenagers EM used to learn a spline model + time-shift for each curve

101
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning to Track People Sidenbladh, Black, Fleet, 2000

102
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Model Uncertainty How do we know what model M to select for our likelihood function? –In general, we don’t! –However, we can use the data to help us infer which model from a set of possible models is best

103
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Method 1: Bayesian Approach Can evaluate the evidence for each model, p(M |D) = p(D|M) p(M)/ p(D) –Can get p(D|M) by integrating p(D, | M) over parameter space (this is the “marginal likelihood”) –in theory p(M |D) is how much evidence exists in the data for model M More complex models are automatically penalized because of the integration over higher-dimensional parameter spaces –in practice p(M|D) can rarely be computed directly Monte Carlo schemes are popular Also: approximations such as BIC, Laplace, etc
 = p(D|M) p(M)/ p(D) –Can get p(D|M) by integrating p(D, | M) over parameter space (this is the marginal likelihood ) –in theory p(M |D) is how much evidence exists in the data for model M More complex models are automatically penalized because of the integration over higher-dimensional parameter spaces –in practice p(M|D) can rarely be computed directly Monte Carlo schemes are popular Also: approximations such as BIC, Laplace, etc.")
104
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Comments on Bayesian Approach Bayesian Model Averaging (BMA): –Instead of selecting the single best model, for prediction average over all available models (theoretically the correct thing to do) –Weights used for averaging are p(M|D) Empirical alternatives –e.g., Stacking, Bagging –Idea is to learn a set of unconstrained combining weights from the data, weights that optimize predictive accuracy “emulate” BMA approach may be more effective in practice
: –Instead of selecting the single best model, for prediction average over all available models (theoretically the correct thing to do) –Weights used for averaging are p(M|D) Empirical alternatives –e.g., Stacking, Bagging –Idea is to learn a set of unconstrained combining weights from the data, weights that optimize predictive accuracy emulate BMA approach may be more effective in practice.")
105
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Method 2: Predictive Validation Instead of the Bayesian approach, we could use the probability of new unseen test data as our metric for selecting models E.g., 2 models –If p(D | M1) > p(D | M2) then M1 is assigning higher probability to new data than M2 –This will (with enough data) select the model that predicts the best, in a probabilistic sense –Useful for problems where we have very large amounts of data and it is easy to create a large validation data set D
 > p(D | M2) then M1 is assigning higher probability to new data than M2 –This will (with enough data) select the model that predicts the best, in a probabilistic sense –Useful for problems where we have very large amounts of data and it is easy to create a large validation data set D.")
106
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The Prediction Game NEW 0 10 Observed Data What is a good guess at p(x)? x 0 10 Model A for p(x) 0 10 Model B for p(x)
. x 0 10 Model A for p(x) 0 10 Model B for p(x).")
107
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Which of Model A or B is better? NEW Test data generated from the true underlying q(x) Model A Model B We can score each model in terms of p(new data | model) Asymptotically, this is a fair unbiased score (irrespective of the complexities of the models) Note: empirical average of log p(data) scores ~ negative entropy
 Model A Model B We can score each model in terms of p(new data | model) Asymptotically, this is a fair unbiased score (irrespective of the complexities of the models) Note: empirical average of log p(data) scores ~ negative entropy.")
108
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 NEW Model-based clustering and visualization of navigation patterns on a Web site Cadez et al, Journal of Data Mining and Knowledge Discovery, 2003

109
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Simple Model Class

110
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Data-generating process (“truth”) Simple Model Class
 Simple Model Class.")
111
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Data-generating process (“truth”) Best model is relatively far from Truth => High Bias Simple Model Class “Closest” model in terms of KL distance
 Best model is relatively far from Truth => High Bias Simple Model Class Closest model in terms of KL distance.")
112
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Data-generating process (“truth”) Simple Model Class Complex Model Class
 Simple Model Class Complex Model Class.")
113
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Data-generating process (“truth”) Simple Model Class Complex Model Class Best model is closer to Truth => Low Bias
 Simple Model Class Complex Model Class Best model is closer to Truth => Low Bias.")
114
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Data-generating process (“truth”) Simple Model Class Complex Model Class However,…. this could be the model that best fits the observed data => High Variance
 Simple Model Class Complex Model Class However,…. this could be the model that best fits the observed data => High Variance.")
115
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Part 4: Models with Hidden Variables

116
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Hidden or Latent Variables In many applications there are 2 sets of variables: –Variables whose values we can directly measure –Variables that are “hidden”, cannot be measured Examples: –Speech recognition: Observed: acoustic voice signal Hidden: label of the word spoken –Face tracking in images Observed: pixel intensities Hidden: position of the face in the image –Text modeling Observed: counts of words in a document Hidden: topics that the document is about

117
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixture Models S Y p(Y) = k p(Y | S=k) p(S=k) Hidden discrete variable Observed variable(s) Motivation: 1. models a true process (e.g., fish example) 2. approximation for a complex process Pearson, 1894, Phil. Trans. Roy. Soc. A.
 = k p(Y | S=k) p(S=k) Hidden discrete variable Observed variable(s) Motivation: 1. models a true process (e.g., fish example) 2. approximation for a complex process Pearson, 1894, Phil. Trans. Roy. Soc. A..")
118
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

121
A Graphical Model for Clustering S YjYj Hidden discrete (cluster) variable Observed variable(s) (assumed conditionally independent given S) YdYd Y1Y1 Clusters = p(Y 1,…Y d | S = s) Probabilistic Clustering = learning these probability distributions from data
 variable Observed variable(s) (assumed conditionally independent given S) YdYd Y1Y1 Clusters = p(Y 1,…Y d | S = s) Probabilistic Clustering = learning these probability distributions from data")
122
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Hidden Markov Model (HMM) Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn - - - - - - - - - - - - - - - - - - - - - - - - - - Observed Hidden Two key assumptions: 1. hidden state sequence is Markov 2. observation Y t is CI of all other variables given S t Widely used in speech recognition, protein sequence models Motivation? - S can provide non-linear switching - S can encode low-dim time-dependence for high-dim Y
 Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn Observed Hidden Two key assumptions: 1. hidden state sequence is Markov 2. observation Y t is CI of all other variables given S t Widely used in speech recognition, protein sequence models Motivation. - S can provide non-linear switching - S can encode low-dim time-dependence for high-dim Y.")
123
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Generalizing HMMs Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn T1T1 T2T2 T3T3 TnTn Two independent state variables, e.g., two processes evolving at different time-scales

124
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Generalizing HMMs Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn I1I1 I2I2 I3I3 InIn Inputs I provide context to influence switching, e.g., external forcing variables Model is still a tree -> inference is still linear

125
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Generalizing HMMs Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YnYn SnSn I1I1 I2I2 I3I3 InIn Add direct dependence between Y’s to better model persistence Can merge each S t and Y t to construct a tree-structured model

126
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixture Model SiSi yiyi i=1:n Likelihood() = p(Data | ) = i p(y i | ) = i [ k p(y i |s i = k, ) p(s i = k) ]
 = p(Data | ) = i p(y i | ) = i [ k p(y i |s i = k, ) p(s i = k) ].")
127
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning with Missing Data Guess at some initial parameters E-step (Inference) –For each case, and each unknown variable compute p(S | known data, ) M-step (Optimization) –Maximize L() using p(S | …..) –This yields new parameter estimates This is the EM algorithm: –Guaranteed to converge to a (local) maximum of L() –Dempster, Laird, Rubin, 1977
 –For each case, and each unknown variable compute p(S | known data, ) M-step (Optimization) –Maximize L() using p(S | …..) –This yields new parameter estimates This is the EM algorithm: –Guaranteed to converge to a (local) maximum of L() –Dempster, Laird, Rubin,")
128
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 E-Step SiSi yiyi i=1:n

129
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 M-Step SiSi yiyi i=1:n

130
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 E-Step SiSi yiyi i=1:n

131
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The E (Expectation) Step Current K components and parameters n objects E step: Compute p(object i is in group k)
 Step Current K components and parameters n objects E step: Compute p(object i is in group k).")
132
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The M (Maximization) Step New parameters for the K components n objects M step: Compute , given n objects and memberships
 Step New parameters for the K components n objects M step: Compute , given n objects and memberships.")
133
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Complexity of EM for mixtures K models n objects Complexity per iteration scales as O( n K f(d) )
 ).")
134
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Data from Prof. Christine McLaren, Dept of Epidemiology, UC Irvine

135
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

141
Anemia Group Control Group

142
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

143
Example of a Log-Likelihood Surface Log Scale for Sigma 2 Mean 2

144
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

145
Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YNYN SNSN HMMs

146
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YNYN SNSN

147
Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YNYN SNSN

148
Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YNYN SNSN E-Step (linear inference)
")
149
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YNYN SNSN M-Step (closed form)
.")
150
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Alternatives to EM Method of Moments –EM is more efficient Direct optimization –e.g., gradient descent, Newton methods –EM is usually simpler to implement Sampling (e.g., MCMC) Minimum distance, e.g.,
 Minimum distance, e.g.,.")
151
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixtures as “Data Simulators” For i = 1 to N class k ~ p(class1, class2, …., class K) x i ~ p(x | class k ) end
 x i ~ p(x | class k ) end.")
152
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixtures with Markov Dependence For i = 1 to N class k ~ p(class1, class2, …., class K | class[x i-1 ] ) x i ~ p(x | class k ) end Current class depends on previous class (Markov dependence) This is a hidden Markov model
 x i ~ p(x | class k ) end Current class depends on previous class (Markov dependence) This is a hidden Markov model.")
153
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixtures of Sequences For i = 1 to N class k ~ p(class1, class2, …., class K) while non-end state x ij ~ p(x j | x j-1, class k ) end Markov sequence model Produces a variable length sequence
 while non-end state x ij ~ p(x j | x j-1, class k ) end Markov sequence model Produces a variable length sequence.")
154
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixtures of Curves For i = 1 to N class k ~ p(class1, class2, …., class K) L i ~ p(L i | class k ) for i = 1 to L i y ij ~ f(y | x j, class k ) + e k end Class-dependent curve model Length of curve Independent variable x
 L i ~ p(L i | class k ) for i = 1 to L i y ij ~ f(y | x j, class k ) + e k end Class-dependent curve model Length of curve Independent variable x.")
155
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Mixtures of Image Models For i = 1 to N class k ~ p(class1, class2, …., class K) size i ~ p(size|class k ) for i = 1 to V i-1 intensity i ~ p(intensity | class k ) end Pixel generation model Number of vertices Global scale
 size i ~ p(size|class k ) for i = 1 to V i-1 intensity i ~ p(intensity | class k ) end Pixel generation model Number of vertices Global scale.")
156
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 More generally….. Generative Model - select a component c k for individual i - generate data according to p(D i | c k ) - p(D i | c k ) can be very general - e.g., sets of sequences, spatial patterns, etc [Note: given p(D i | c k ), we can define an EM algorithm]
 - p(D i | c k ) can be very general - e.g., sets of sequences, spatial patterns, etc [Note: given p(D i | c k ), we can define an EM algorithm].")
157
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 References The EM Algorithm and Mixture Models –The EM Algorithm and Extensions G. McLachlan and T. Krishnan. John Wiley and Sons, New York, 1997. Mixture models –Statistical analysis of finite mixture distributions. D. M. Titterington, A. F. M. Smith & U. E. Makov. Wiley & Sons, Inc., New York, 1985. –Finite Mixture Models G.J. McLachlan and D. Peel, New York: Wiley (2000) –Model-based clustering, discriminant analysis, and density estimation, C. Fraley and A. E. Raftery, Journal of the American Statistical Association 97:611-631 (2002). NEW
 –Model-based clustering, discriminant analysis, and density estimation, C. Fraley and A. E. Raftery, Journal of the American Statistical Association 97: (2002). NEW.")
158
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 References Hidden Markov Models –A tutorial on hidden Markov models and selected applications in speech recognition, L. R. Rabiner, Proceedings of the IEEE, vol. 77, no.2, 257-287, 1989. –Probabilistic independence networks for hidden Markov models P. Smyth, D. Heckerman, and M. Jordan, Neural Computation, vol.9, no. 2, 227-269, 1997. –Hidden Markov models, A. Moore, online tutorial slides, http://www.autonlab.org/tutorials/hmm12.pdf NEW

159
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Part 5: Case Studies (i) Simulating and forecasting rainfall data (ii) Curve clustering with cyclones (iii) Topic modeling from text documents and if time permits….. (iv) Sequence clustering for Web data (v) Analysis of time-course gene expression data
 Simulating and forecasting rainfall data (ii) Curve clustering with cyclones (iii) Topic modeling from text documents and if time permits….. (iv) Sequence clustering for Web data (v) Analysis of time-course gene expression data.")
160
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Case Study 1: Simulating and Predicting Rainfall Patterns Joint work with: Andy Robertson, International Research Institute for Climate Prediction Sergey Kirshner, Department of Computer Science, UC Irvine

161
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Spatio-Temporal Rainfall Data Northeast Brazil 1975-2002 90-day time series 24 years 10 stations

162
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

163
Modeling Goals “Downscaling” –Modeling interannual variability –coupling rainfall to large-scale effects like El Nino Prediction –e.g., “hindcasting” of missing data Seasonal Forecasts –E.g. on Dec 1 produce simulations of likely 90-day winters

164
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Y1Y1 S1S1 Y2Y2 S2S2 Y3Y3 S3S3 YNYN SNSN I1I1 I2I2 I3I3 ININ S = unobserved weather state Y = spatial rainfall pattern (“outputs”) I = atmospheric variables (“inputs”) HMMs for Rainfall Modeling
 I = atmospheric variables ( inputs ) HMMs for Rainfall Modeling.")
165
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learned Weather States States provide an interpretable “view” of spatio-temporal relationships in the data

166
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

167
Weather States for Kenya

168
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

170
Spatial Chow-Liu Trees -Spatial distribution given a state is a tree structure (a graphical model) -Useful intermediate between full pair-wise model and conditional independence -Optimal topology learned from data using minimum spanning tree algorithm -Can use priors based on distance, topography -Tree-structure over time also
 -Useful intermediate between full pair-wise model and conditional independence -Optimal topology learned from data using minimum spanning tree algorithm -Can use priors based on distance, topography -Tree-structure over time also")
171
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Missing Data

172
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Error rate v. fraction of missing data

173
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 References Trees and Hidden Markov Models –Conditional Chow-Liu tree structures for modeling discrete- valued vector time series S. Kirshner, P. Smyth, and A. Robertson in Proceedings of the 20th International Conference on Uncertainty in AI, 2004. Applications to rainfall modeling –Hidden Markov models for modeling daily rainfall occurrence over Brazil A. Robertson, S. Kirshner, and P. Smyth Journal of Climate, November 2005. NEW

174
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Summary Simple “empirical” probabilistic models can be very helpful in interpreting large scientific data sets –e.g., HMM states provide scientists with a basic but useful classification of historical spatial rainfall patterns Graphical models provide “glue” to link together different information –Spatial –Temporal –Hidden states, etc “Generative” aspect of probabilistic models can be quite useful, e.g., for simulation Missing data is handled naturally in a probabilistic framework

175
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Case Study 2: Clustering Cyclone Trajectories Joint work with: Suzana Camargo, Andy Robertson, International Research Institute for Climate Prediction Scott Gaffney, Department of Computer Science, UC Irvine

176
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Storm Trajectories

177
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Microarray Gene Expression Data

178
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Clustering “non-vector” data Challenges with the data…. –May be of different “lengths”, “sizes”, etc –Not easily representable in vector spaces –Distance is not naturally defined a priori Possible approaches –“convert” into a fixed-dimensional vector space Apply standard vector clustering – but loses information –use hierarchical clustering But O(N 2 ) and requires a distance measure –probabilistic clustering with mixtures Define a generative mixture model for the data Learn distance and clustering simultaneously
 and requires a distance measure –probabilistic clustering with mixtures Define a generative mixture model for the data Learn distance and clustering simultaneously.")
179
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Models for Curves y T t y = f(t ; ) e.g., y = at 2 + bt + c, = {a, b, c} Data = { (y 1,t 1 ),……. y T, t T ) }
 e.g., y = at 2 + bt + c, = {a, b, c} Data = { (y 1,t 1 ),……. y T, t T ) }.")
180
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Models for Curves y T t y ~ Gaussian density with mean = f(t ; ), variance = 2
, variance = 2 .")
181
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example t y

182
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Example f(t ; ) <- this is hidden t y
 <- this is hidden t y.")
183
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Models for Sets of Curves y T t Each curve: P(y i | t i, ) = product of Gaussians N curves
 = product of Gaussians N curves.")
184
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Curve-Specific Transformations y T t N curves e.g., y i = at 2 + bt + c + i, = {a, b, c, 1,…. N } Note: we can learn function parameters and shifts simultaneously with EM

185
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning Shapes and Shifts Original data Data after Learning Data = smoothed growth acceleration data from teenagers EM used to learn a spline model + time-shift for each curve

186
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Clustering: Mixtures of Curves y T t N curves c Each set of trajectory points comes from 1 of K models Model for group k is a Gaussian curve model Marginal probability for a trajectory = mixture model

187
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 The Learning Problem K cluster models –Each cluster is a shape model E[Y] = f(X;) with its own parameters N observed curves: for each curve we learn –P(cluster k | curve data) –distribution on alignments, shifts, scaling, etc, given data Requires simultaneous learning of –Cluster models –Curve transformation parameters Results in an EM algorithm where E and M step are tractable
 with its own parameters N observed curves: for each curve we learn –P(cluster k | curve data) –distribution on alignments, shifts, scaling, etc, given data Requires simultaneous learning of –Cluster models –Curve transformation parameters Results in an EM algorithm where E and M step are tractable.")
188
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

190
Results on Simulated Data 0.1290.424-0.79K-means 0.0480.0191.340.99EM with Alignment 0.05002.011True Model Within- Cluster Error in Mean LogPClassification Accuracy Method *Averaged over 50 train/test sets Standard EM 0.89-7.870.1710.105

191
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Clusters of Trajectories

192
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Cluster Shapes for Pacific Cyclones

193
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 TROPICAL CYCLONES Western North Pacific 1983-2002

194
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

195
References on Curve Clustering Functional Data Analysis J. O. Ramsay and B. W. Silverman, Springer, 1997. Probabilistic curve-aligned clustering and prediction with regression mixture models S. J. Gaffney, Phd Thesis, Department of Computer Science, University of California, Irvine, March 2004. Joint probabilistic curve clustering and alignment S. Gaffney and P. Smyth Advances in Neural Information Processing 17, in press, 2005. Probabilistic clustering of extratropical cyclones using regression mixture models S. Gaffney, A. Robertson, P. Smyth, S. Camargo, M. Ghil preprint, online at www.datalab.uci.edu. NEW

196
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Summary Graphical models provide a flexible representational language for modeling complex scientific data –can build complex models from simpler building blocks Systematic variability in the data can be handled in a principled way –Variable length time-series –Misalignments in trajectories Generative probabilistic models are interpretable and understandable by scientists

197
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Case Study 3: Topic Modeling from Text Documents Joint work with: Mark Steyvers, Dave Newman, Chaitanya Chemudugunta, UC Irvine Michal Rosen-Zvi, Hebrew University, Jerusalem Tom Griffiths, Brown University

198
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Enron email data 250,000 emails 5000 authors 1999-2002

199
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Questions of Interest –What topics do these documents “span”? –Which documents are about a particular topic? –How have topics changed over time? –What does author X write about? –Who is likely to write about topic Y? –Who wrote this specific document? –and so on…..

200
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Model for Clustering z w Cluster for document Word Cluster-Word distributions D n

201
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Graphical Model for Topics z w Topic Word Document-Topic distributions Topic-Word distributions D n

202
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Topic = probability distribution over words

203
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Key Features of Topic Models Generative model for documents in form of bags of words Allows a document to be composed of multiple topics –Much more powerful than 1 doc -> 1 cluster Completely unsupervised –Topics learned directly from data –Leverages strong dependencies at word level AND large data sets Learning algorithm –Gibbs sampling is the method of choice Scalable –Linear in number of word tokens –Can be run on millions of documents NEW

204
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Topics vs. Other Approaches Clustering documents –Computationally simpler… –But a less accurate and less flexible model LSI/LSA –Projects words into a K-dimensional hidden space –Less interpretable –Not generalizable E.g., authors or other side-information –Not as accurate E.g., precision-recall: Hoffman, Blei et al, Buntine, etc Topic Models (aka LDA model) –“next-generation” text modeling, after LSI –More flexible and more accurate (in prediction) –Linear time complexity in fitting the model
 – next-generation text modeling, after LSI –More flexible and more accurate (in prediction) –Linear time complexity in fitting the model.")
205
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of Topics learned from Proceedings of the National Academy of Sciences Griffiths and Steyvers, 2004 NEW FORCE SURFACE MOLECULES SOLUTION SURFACES MICROSCOPY WATER FORCES PARTICLES STRENGTH POLYMER IONIC ATOMIC AQUEOUS MOLECULAR PROPERTIES LIQUID SOLUTIONS BEADS MECHANICAL HIV VIRUS INFECTED IMMUNODEFICIENCY CD4 INFECTION HUMAN VIRAL TAT GP120 REPLICATION TYPE ENVELOPE AIDS REV BLOOD CCR5 INDIVIDUALS ENV PERIPHERAL MUSCLE CARDIAC HEART SKELETAL MYOCYTES VENTRICULAR MUSCLES SMOOTH HYPERTROPHY DYSTROPHIN HEARTS CONTRACTION FIBERS FUNCTION TISSUE RAT MYOCARDIAL ISOLATED MYOD FAILURE STRUCTURE ANGSTROM CRYSTAL RESIDUES STRUCTURES STRUCTURAL RESOLUTION HELIX THREE HELICES DETERMINED RAY CONFORMATION HELICAL HYDROPHOBIC SIDE DIMENSIONAL INTERACTIONS MOLECULE SURFACE NEURONS BRAIN CORTEX CORTICAL OLFACTORY NUCLEUS NEURONAL LAYER RAT NUCLEI CEREBELLUM CEREBELLAR LATERAL CEREBRAL LAYERS GRANULE LABELED HIPPOCAMPUS AREAS THALAMIC TUMOR CANCER TUMORS HUMAN CELLS BREAST MELANOMA GROWTH CARCINOMA PROSTATE NORMAL CELL METASTATIC MALIGNANT LUNG CANCERS MICE NUDE PRIMARY OVARIAN

206
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 What can Topic Models be used for? –Queries Who writes on this topic? –e.g., finding experts or reviewers in a particular area What topics does this person do research on? –Comparing groups of authors or documents –Discovering trends over time –Detecting unusual papers and authors –Interactive browsing of a digital library via topics –Parsing documents (and parts of documents) by topic –and more…..
 by topic –and more…...")
207
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 What is this paper about? Empirical Bayes screening for multi-item associations Bill DuMouchel and Daryl Pregibon, ACM SIGKDD 2001 Most likely topics according to the model are… 1.data, mining, discovery, association, attribute.. 2.set, subset, maximal, minimal, complete,… 3.measurements, correlation, statistical, variation, 4.Bayesian, model, prior, data, mixture,….. NEW

208
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

210
Pennsylvania Gazette 1728-1800 1728-1800 80,000 articles (courtesy of David Newman & Sharon Block, UC Irvine) NEW
 NEW")
211
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Historical Trends in Pennsylvania Gazette STATE GOVERNMENT CONSTITUTION LAW UNITED POWER CITIZEN PEOPLE PUBLIC CONGRESS SILK COTTON DITTO WHITE BLACK LINEN CLOTH WOMEN BLUE WORSTED (courtesy of David Newman & Sharon Block, UC Irvine) NEW
 NEW.")
212
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Enron email data 250,000 emails 5000 authors 1999-2002

213
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Enron email topics

214
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Non-work Topics…

215
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Topical Topics

216
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Using Topic Models for Information Retrieval UPDATED

217
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Author-Topic Models The author-topic model –a probabilistic model linking authors and topics authors -> topics -> words –Topic = distribution over words –Author = distribution over topics –Document = generated from a mixture of author distributions –Learns about entities based on associated text Can be generalized –Replace author with any categorical doc information –e.g., publication type, source, year, country of origin, etc

218
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Author-Topic Graphical Model x z w a Author Topic Word Author-Topic distributions Topic-Word distributions D n

219
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Learning Author-Topic Models from Text Full probabilistic model –Power of statistical learning can be leveraged –Learning algorithm is linear in number of word occurrences Scalable to very large data sets Completely automated (no tweaking required) –completely unsupervised, no labels Query answering –A wide variety of queries can be answered: Which authors write on topic X? What are the spatial patterns in usage of topic Y? How have authors A, B and C changed over time? –Queries answered using probabilistic inference Query time is real-time (learning is offline)
 –completely unsupervised, no labels Query answering –A wide variety of queries can be answered: Which authors write on topic X. What are the spatial patterns in usage of topic Y. How have authors A, B and C changed over time. –Queries answered using probabilistic inference Query time is real-time (learning is offline).")
220
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Author-Topic Models for CiteSeer

221
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Author-Profiles Author = Andrew McCallum, U Mass: –Topic 1: classification, training, generalization, decision, data,… –Topic 2: learning, machine, examples, reinforcement, inductive,….. –Topic 3: retrieval, text, document, information, content,… Author = Hector Garcia-Molina, Stanford: - Topic 1: query, index, data, join, processing, aggregate…. - Topic 2: transaction, concurrency, copy, permission, distributed…. - Topic 3: source, separation, paper, heterogeneous, merging….. Author = Jerry Friedman, Stanford: –Topic 1: regression, estimate, variance, data, series,… –Topic 2: classification, training, accuracy, decision, data,… –Topic 3: distance, metric, similarity, measure, nearest,…

222
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005

223
PubMed-Query Topics

224
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 PubMed-Query Topics

225
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 PubMed: Topics by Country

226
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 PubMed-Query: Topics by Country

227
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Extended Models Conditioning on non-authors –“side-information” other than authors –e.g., date, publication venue, country, etc –can use citations as authors Fictitious authors and common author –Allow 1 unique fictitious author per document Captures document specific effects –Assign 1 common fictitious author to each document Captures broad topics that are used in many documents Semantics and syntax model –Semantic topics = topics that are specific to certain documents –Syntactic topics = broad, across many documents –Probabilistic model that learns each type automatically

228
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Scientific syntax and semantics (Griffiths et al., NIPS 2004 – slides courtesy of Mark Steyvers and Tom Griffiths, PNAS Symposium presentation, 2003) z w z z ww x x x semantics: probabilistic topics syntax: probabilistic regular grammar Factorization of language based on statistical dependency patterns: long-range, document specific dependencies short-range dependencies constant across all documents
 z w z z ww x x x semantics: probabilistic topics syntax: probabilistic regular grammar Factorization of language based on statistical dependency patterns: long-range, document specific dependencies short-range dependencies constant across all documents.")
229
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 HEART 0.2 LOVE 0.2 SOUL 0.2 TEARS 0.2 JOY 0.2 z = 1 0.4 SCIENTIFIC 0.2 KNOWLEDGE 0.2 WORK 0.2 RESEARCH 0.2 MATHEMATICS 0.2 z = 2 0.6 x = 1 THE 0.6 A 0.3 MANY 0.1 x = 3 OF 0.6 FOR 0.3 BETWEEN 0.1 x = 2 0.9 0.1 0.2 0.8 0.7 0.3

230
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 HEART 0.2 LOVE 0.2 SOUL 0.2 TEARS 0.2 JOY 0.2 SCIENTIFIC 0.2 KNOWLEDGE 0.2 WORK 0.2 RESEARCH 0.2 MATHEMATICS 0.2 THE 0.6 A 0.3 MANY 0.1 OF 0.6 FOR 0.3 BETWEEN 0.1 0.9 0.1 0.2 0.8 0.7 0.3 THE ……………………………… z = 1 0.4 z = 2 0.6 x = 1 x = 3 x = 2

231
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 HEART 0.2 LOVE 0.2 SOUL 0.2 TEARS 0.2 JOY 0.2 SCIENTIFIC 0.2 KNOWLEDGE 0.2 WORK 0.2 RESEARCH 0.2 MATHEMATICS 0.2 THE 0.6 A 0.3 MANY 0.1 OF 0.6 FOR 0.3 BETWEEN 0.1 0.9 0.1 0.2 0.8 0.7 0.3 THE LOVE…………………… z = 1 0.4 z = 2 0.6 x = 1 x = 3 x = 2

232
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 HEART 0.2 LOVE 0.2 SOUL 0.2 TEARS 0.2 JOY 0.2 SCIENTIFIC 0.2 KNOWLEDGE 0.2 WORK 0.2 RESEARCH 0.2 MATHEMATICS 0.2 THE 0.6 A 0.3 MANY 0.1 OF 0.6 FOR 0.3 BETWEEN 0.1 0.9 0.1 0.2 0.8 0.7 0.3 THE LOVE OF……………… z = 1 0.4 z = 2 0.6 x = 1 x = 3 x = 2

233
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 HEART 0.2 LOVE 0.2 SOUL 0.2 TEARS 0.2 JOY 0.2 SCIENTIFIC 0.2 KNOWLEDGE 0.2 WORK 0.2 RESEARCH 0.2 MATHEMATICS 0.2 THE 0.6 A 0.3 MANY 0.1 OF 0.6 FOR 0.3 BETWEEN 0.1 0.9 0.1 0.2 0.8 0.7 0.3 THE LOVE OF RESEARCH …… z = 1 0.4 z = 2 0.6 x = 1 x = 3 x = 2

234
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Semantic topics

235
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Syntactic classes REMAINED 581425263033 INARETHESUGGESTLEVELSRESULTSBEEN FORWERETHISINDICATENUMBERANALYSISMAY ONWASITSSUGGESTINGLEVELDATACAN BETWEENISTHEIRSUGGESTSRATESTUDIESCOULD DURINGWHENANSHOWEDTIMESTUDYWELL AMONGREMAINEACHREVEALEDCONCENTRATIONSFINDINGSDID FROMREMAINSONESHOWVARIETYEXPERIMENTSDOES UNDERREMAINEDANYDEMONSTRATERANGEOBSERVATIONSDO WITHINPREVIOUSLYINCREASEDINDICATINGCONCENTRATIONHYPOTHESISMIGHT THROUGHOUTBECOMEEXOGENOUSPROVIDEDOSEANALYSESSHOULD THROUGHBECAMEOURSUPPORTFAMILYASSAYSWILL TOWARDBEINGRECOMBINANTINDICATESSETPOSSIBILITYWOULD INTOBUTENDOGENOUSPROVIDESFREQUENCYMICROSCOPYMUST ATGIVETOTALINDICATEDSERIESPAPERCANNOT INVOLVINGMEREPURIFIEDDEMONSTRATEDAMOUNTSWORK THEY AFTERAPPEAREDTILESHOWSRATESEVIDENCEALSO ACROSSAPPEARFULLSOCLASSFINDING AGAINSTALLOWEDCHRONICREVEALVALUESMUTAGENESISBECOME WHENNORMALLYANOTHERDEMONSTRATESAMOUNTOBSERVATIONMAG ALONGEACHEXCESSSUGGESTEDSITESMEASUREMENTSLIKELY

236
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 (PNAS, 1991, vol. 88, 4874-4876) A 23 generalized 49 fundamental 11 theorem 20 of 4 natural 46 selection 46 is 32 derived 17 for 5 populations 46 incorporating 22 both 39 genetic 46 and 37 cultural 46 transmission 46. The 14 phenotype 15 is 32 determined 17 by 42 an 23 arbitrary 49 number 26 of 4 multiallelic 52 loci 40 with 22 two 39 -factor 148 epistasis 46 and 37 an 23 arbitrary 49 linkage 11 map 20, as 43 well 33 as 43 by 42 cultural 46 transmission 46 from 22 the 14 parents 46. Generations 46 are 8 discrete 49 but 37 partially 19 overlapping 24, and 37 mating 46 may 33 be 44 nonrandom 17 at 9 either 39 the 14 genotypic 46 or 37 the 14 phenotypic 46 level 46 (or 37 both 39 ). I 12 show 34 that 47 cultural 46 transmission 46 has 18 several 39 important 49 implications 6 for 5 the 14 evolution 46 of 4 population 46 fitness 46, most 36 notably 4 that 47 there 41 is 32 a 23 time 26 lag 7 in 22 the 14 response 28 to 31 selection 46 such 9 that 47 the 14 future 137 evolution 46 depends 29 on 21 the 14 past 24 selection 46 history 46 of 4 the 14 population 46. (graylevel = “semanticity”, the probability of using LDA over HMM)
 A 23 generalized 49 fundamental 11 theorem 20 of 4 natural 46 selection 46 is 32 derived 17 for 5 populations 46 incorporating 22 both 39 genetic 46 and 37 cultural 46 transmission 46. The 14 phenotype 15 is 32 determined 17 by 42 an 23 arbitrary 49 number 26 of 4 multiallelic 52 loci 40 with 22 two 39 -factor 148 epistasis 46 and 37 an 23 arbitrary 49 linkage 11 map 20, as 43 well 33 as 43 by 42 cultural 46 transmission 46 from 22 the 14 parents 46. Generations 46 are 8 discrete 49 but 37 partially 19 overlapping 24, and 37 mating 46 may 33 be 44 nonrandom 17 at 9 either 39 the 14 genotypic 46 or 37 the 14 phenotypic 46 level 46 (or 37 both 39 ). I 12 show 34 that 47 cultural 46 transmission 46 has 18 several 39 important 49 implications 6 for 5 the 14 evolution 46 of 4 population 46 fitness 46, most 36 notably 4 that 47 there 41 is 32 a 23 time 26 lag 7 in 22 the 14 response 28 to 31 selection 46 such 9 that 47 the 14 future 137 evolution 46 depends 29 on 21 the 14 past 24 selection 46 history 46 of 4 the 14 population 46. (graylevel = semanticity , the probability of using LDA over HMM).")
237
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 (PNAS, 1996, vol. 93, 14628-14631) The 14 ''shape 7 '' of 4 a 23 female 115 mating 115 preference 125 is 32 the 14 relationship 7 between 4 a 23 male 115 trait 15 and 37 the 14 probability 7 of 4 acceptance 21 as 43 a 23 mating 115 partner 20, The 14 shape 7 of 4 preferences 115 is 32 important 49 in 5 many 39 models 6 of 4 sexual 115 selection 46, mate 115 recognition 125, communication 9, and 37 speciation 46, yet 50 it 41 has 18 rarely 19 been 33 measured 17 precisely 19, Here 12 I 9 examine 34 preference 7 shape 7 for 5 male 115 calling 115 song 125 in 22 a 23 bushcricket *13 (katydid *48 ). Preferences 115 change 46 dramatically 19 between 22 races 46 of 4 a 23 species 15, from 22 strongly 19 directional 11 to 31 broadly 19 stabilizing 45 (but 50 with 21 a 23 net 49 directional 46 effect 46 ), Preference 115 shape 46 generally 19 matches 10 the 14 distribution 16 of 4 the 14 male 115 trait 15, This 41 is 32 compatible 29 with 21 a 23 coevolutionary 46 model 20 of 4 signal 9 -preference 115 evolution 46, although 50 it 41 does 33 nor 37 rule 20 out 17 an 23 alternative 11 model 20, sensory 125 exploitation 150. Preference 46 shapes 40 are 8 shown 35 to 31 be 44 genetic 11 in 5 origin 7.
 The 14 shape 7 of 4 a 23 female 115 mating 115 preference 125 is 32 the 14 relationship 7 between 4 a 23 male 115 trait 15 and 37 the 14 probability 7 of 4 acceptance 21 as 43 a 23 mating 115 partner 20, The 14 shape 7 of 4 preferences 115 is 32 important 49 in 5 many 39 models 6 of 4 sexual 115 selection 46, mate 115 recognition 125, communication 9, and 37 speciation 46, yet 50 it 41 has 18 rarely 19 been 33 measured 17 precisely 19, Here 12 I 9 examine 34 preference 7 shape 7 for 5 male 115 calling 115 song 125 in 22 a 23 bushcricket *13 (katydid *48 ). Preferences 115 change 46 dramatically 19 between 22 races 46 of 4 a 23 species 15, from 22 strongly 19 directional 11 to 31 broadly 19 stabilizing 45 (but 50 with 21 a 23 net 49 directional 46 effect 46 ), Preference 115 shape 46 generally 19 matches 10 the 14 distribution 16 of 4 the 14 male 115 trait 15, This 41 is 32 compatible 29 with 21 a 23 coevolutionary 46 model 20 of 4 signal 9 -preference 115 evolution 46, although 50 it 41 does 33 nor 37 rule 20 out 17 an 23 alternative 11 model 20, sensory 125 exploitation 150. Preference 46 shapes 40 are 8 shown 35 to 31 be 44 genetic 11 in 5 origin 7..")
238
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 (PNAS, 1996, vol. 93, 14628-14631) The 14 ''shape 7 '' of 4 a 23 female 115 mating 115 preference 125 is 32 the 14 relationship 7 between 4 a 23 male 115 trait 15 and 37 the 14 probability 7 of 4 acceptance 21 as 43 a 23 mating 115 partner 20, The 14 shape 7 of 4 preferences 115 is 32 important 49 in 5 many 39 models 6 of 4 sexual 115 selection 46, mate 115 recognition 125, communication 9, and 37 speciation 46, yet 50 it 41 has 18 rarely 19 been 33 measured 17 precisely 19, Here 12 I 9 examine 34 preference 7 shape 7 for 5 male 115 calling 115 song 125 in 22 a 23 bushcricket *13 (katydid *48 ). Preferences 115 change 46 dramatically 19 between 22 races 46 of 4 a 23 species 15, from 22 strongly 19 directional 11 to 31 broadly 19 stabilizing 45 (but 50 with 21 a 23 net 49 directional 46 effect 46 ), Preference 115 shape 46 generally 19 matches 10 the 14 distribution 16 of 4 the 14 male 115 trait 15. This 41 is 32 compatible 29 with 21 a 23 coevolutionary 46 model 20 of 4 signal 9 -preference 115 evolution 46, although 50 it 41 does 33 nor 37 rule 20 out 17 an 23 alternative 11 model 20, sensory 125 exploitation 150. Preference 46 shapes 40 are 8 shown 35 to 31 be 44 genetic 11 in 5 origin 7.
 The 14 shape 7 of 4 a 23 female 115 mating 115 preference 125 is 32 the 14 relationship 7 between 4 a 23 male 115 trait 15 and 37 the 14 probability 7 of 4 acceptance 21 as 43 a 23 mating 115 partner 20, The 14 shape 7 of 4 preferences 115 is 32 important 49 in 5 many 39 models 6 of 4 sexual 115 selection 46, mate 115 recognition 125, communication 9, and 37 speciation 46, yet 50 it 41 has 18 rarely 19 been 33 measured 17 precisely 19, Here 12 I 9 examine 34 preference 7 shape 7 for 5 male 115 calling 115 song 125 in 22 a 23 bushcricket *13 (katydid *48 ). Preferences 115 change 46 dramatically 19 between 22 races 46 of 4 a 23 species 15, from 22 strongly 19 directional 11 to 31 broadly 19 stabilizing 45 (but 50 with 21 a 23 net 49 directional 46 effect 46 ), Preference 115 shape 46 generally 19 matches 10 the 14 distribution 16 of 4 the 14 male 115 trait 15. This 41 is 32 compatible 29 with 21 a 23 coevolutionary 46 model 20 of 4 signal 9 -preference 115 evolution 46, although 50 it 41 does 33 nor 37 rule 20 out 17 an 23 alternative 11 model 20, sensory 125 exploitation 150. Preference 46 shapes 40 are 8 shown 35 to 31 be 44 genetic 11 in 5 origin 7..")
239
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 References on Topic Models Latent Dirichlet allocation David Blei, Andrew Y. Ng and Michael Jordan. Journal of Machine Learning Research, 3:993-1022, 2003. Finding scientific topics Griffiths, T., & Steyvers, M. (2004). Proceedings of the National Academy of Sciences, 101 (suppl. 1), 5228-5235 Probabilistic author-topic models for information discovery M. Steyvers, P. Smyth, M. Rosen-Zvi, and T. Griffiths, in Proceedings of the ACM SIGKDD Conference on Data Mining and Knowledge Discovery, August 2004. Integrating topics and syntax. Griffiths, T.L., & Steyvers, M., Blei, D.M., & Tenenbaum, J.B. (in press, 2005). In: Advances in Neural Information Processing Systems, 17. NEW
. Proceedings of the National Academy of Sciences, 101 (suppl. 1), Probabilistic author-topic models for information discovery M. Steyvers, P. Smyth, M. Rosen-Zvi, and T. Griffiths, in Proceedings of the ACM SIGKDD Conference on Data Mining and Knowledge Discovery, August Integrating topics and syntax. Griffiths, T.L., & Steyvers, M., Blei, D.M., & Tenenbaum, J.B. (in press, 2005). In: Advances in Neural Information Processing Systems, 17. NEW.")
240
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Summary State-of-the-art probabilistic text models can be constructed from large text data sets –Can yield better performance than other approaches like clustering, LSI, etc –Advantage of probabilistic approach is that a wide range of queries can be supported by a single model –See also recent work by Buntine and colleagues Learning algorithms are slow but scalable –Linear in the number of word tokens –Applying this type of Monte Carlo statistical learning to millions of words was unheard of a few years ago

241
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Conclusion

242
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Probabilistic Model Real World Data Modeling Learning NEW “All models are wrong, but some are useful” (G.E.P. Box)
.")
243
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Concluding Comments The probabilistic approach is worthy of inclusion in a data miner’s toolbox –Systematic handling of missing information and uncertainty –Ability to incorporate prior knowledge –Integration of different sources of information –However, not always best choice for “black-box” predictive modeling Graphical models in particular provide: –A flexible and modular representational language for modeling –efficient and general computational inference and learning algorithms Many recent advances in theory, algorithms, and applications –Likely to continue to see advances in new powerful models, more efficient scalable learning algorithms, etc

244
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 Examples of New Research Directions Modeling and Learning –Probabilistic Relational Models Work by Koller et al, Russell et al, etc. –Conditional Markov Random Fields information extraction (McCallum et al) –Dirichlet processes Flexible non-parametric models (Jordan et al) –Combining discriminative and generative models e.g., Haussler and Jaakkola Applications –Computer vision: particle filters –Robotics: map learning –Statistical machine translation –Biology: learning gene regulation networks –and many more….
 –Dirichlet processes Flexible non-parametric models (Jordan et al) –Combining discriminative and generative models e.g., Haussler and Jaakkola Applications –Computer vision: particle filters –Robotics: map learning –Statistical machine translation –Biology: learning gene regulation networks –and many more…..")
245
Probabilistic Learning Tutorial: P. Smyth, UC Irvine, August 2005 General References All of Statistics: A Concise Course in Statistical Inference L. Wasserman, Chapman and Hall, 2004 Bayesian Data Analysis A. Gelman, J. B. Carlin. H. S. Stern, and D. B. Rubin, Chapman and Hall, 2 nd edition, 2003. Learning in Graphical Models M. I. Jordan (ed), MIT Press, 1998 Graphical models M. I. Jordan. Statistical Science (Special Issue on Bayesian Statistics), 19, 140- 155, 2004. The Elements of Statistical Learning : Data Mining, Inference, and Prediction T. Hastie, R. Tibshirani, J. H. Friedman, Springer, 2001 Recent Research: –Proceedings of NIPS and UAI conferences, Journal of Machine Learning Research UPDATED
, MIT Press, 1998 Graphical models M. I. Jordan. Statistical Science (Special Issue on Bayesian Statistics), 19, , The Elements of Statistical Learning : Data Mining, Inference, and Prediction T. Hastie, R. Tibshirani, J. H. Friedman, Springer, 2001 Recent Research: –Proceedings of NIPS and UAI conferences, Journal of Machine Learning Research UPDATED.")
Similar presentations
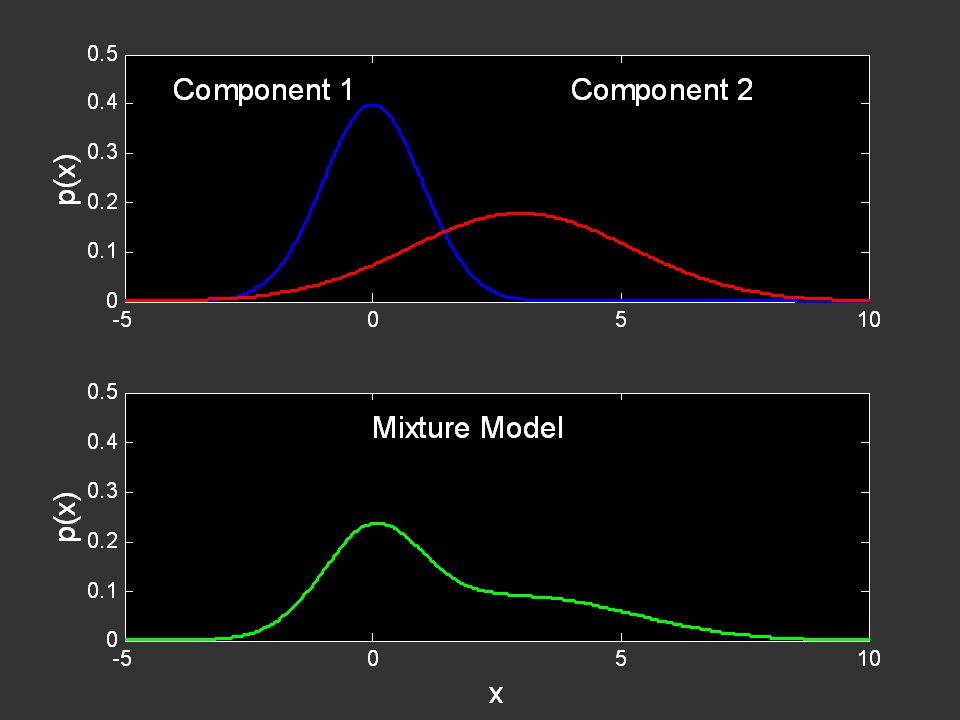
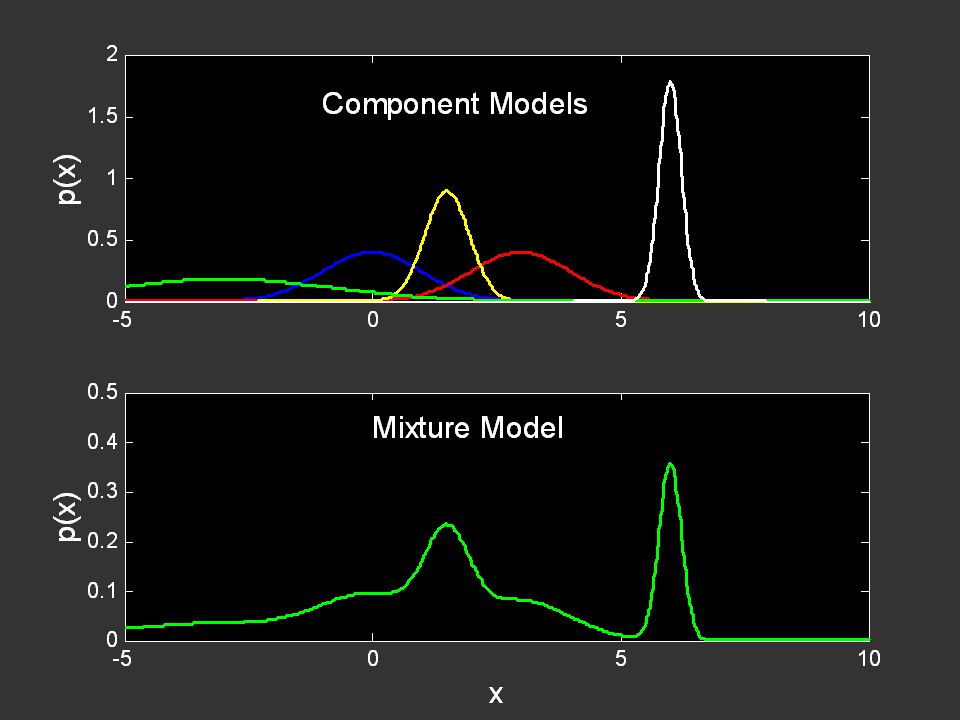
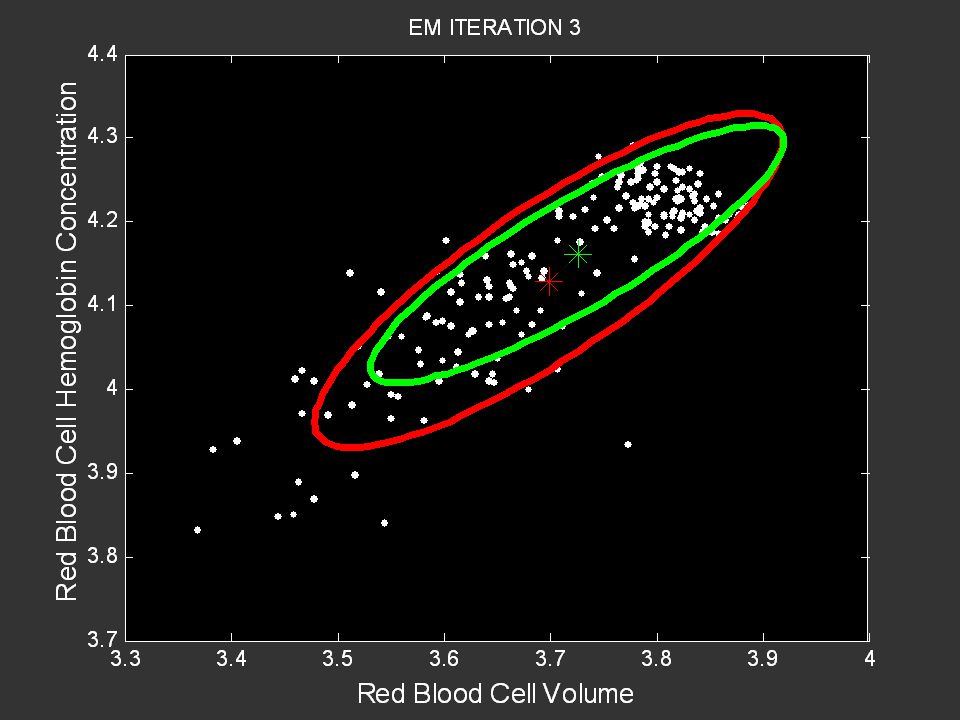

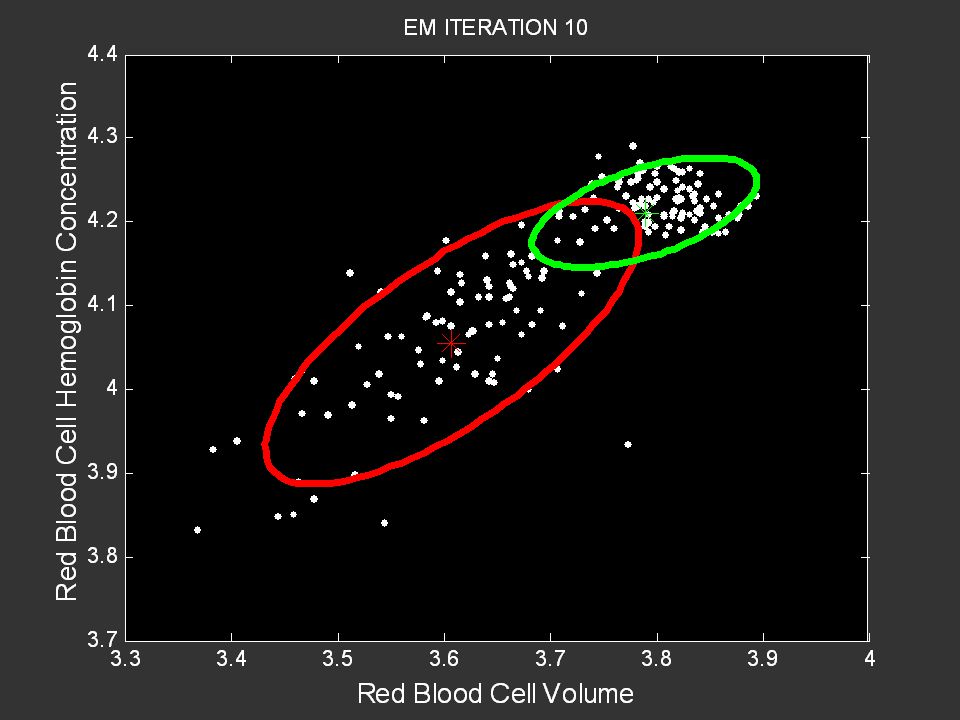
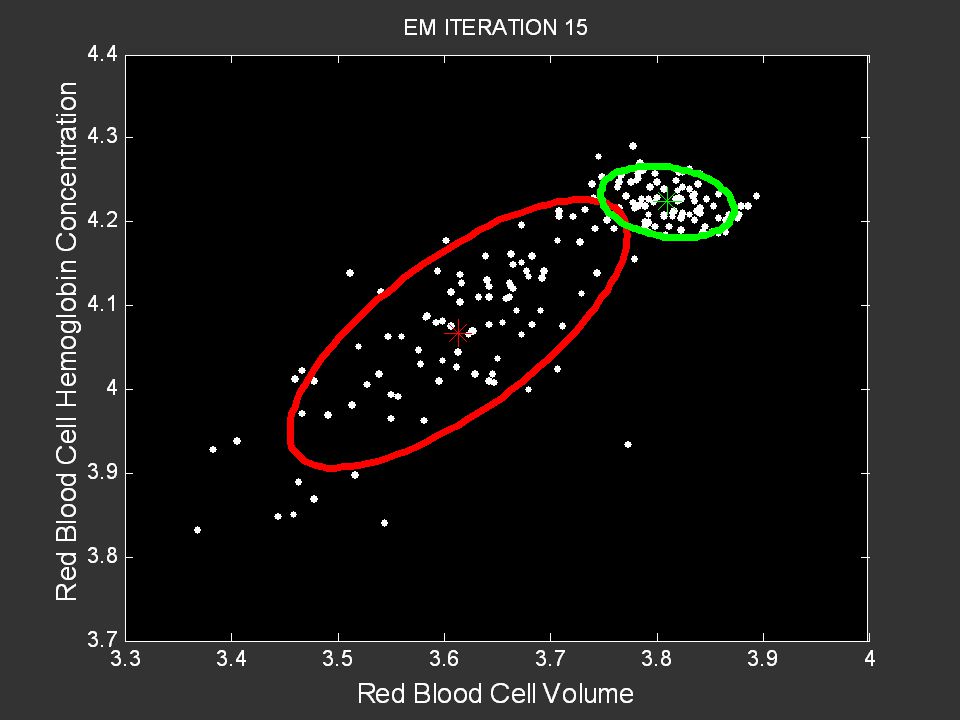
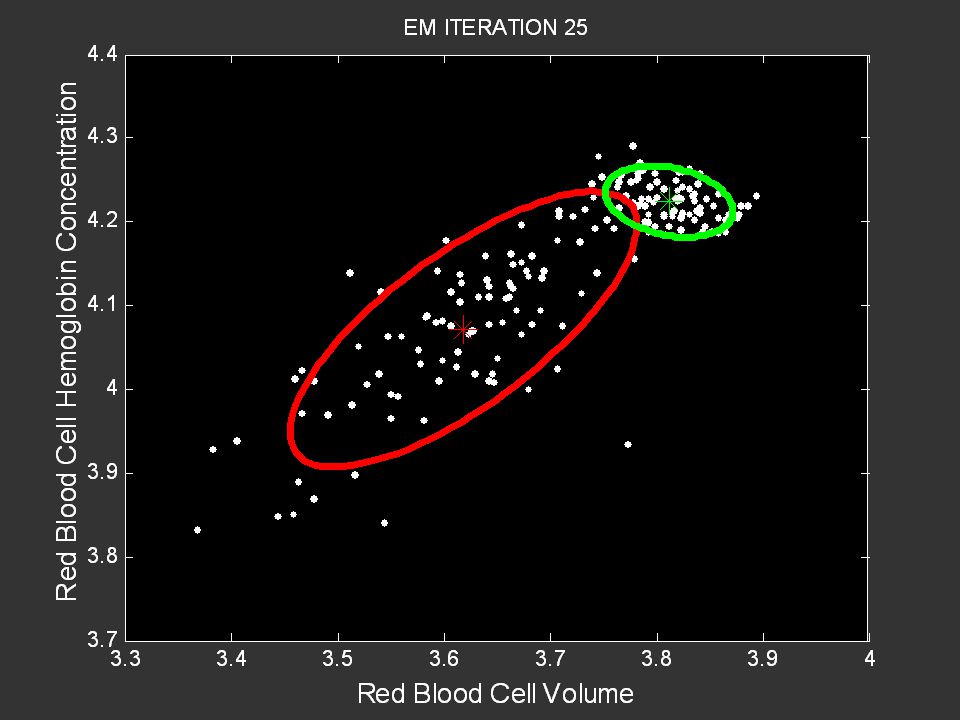


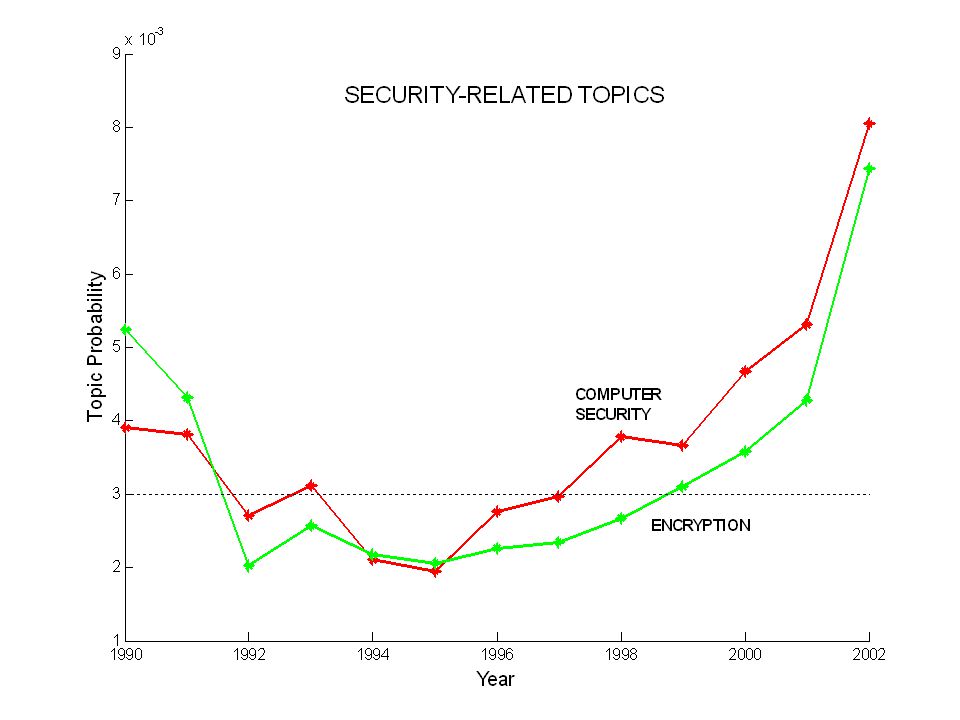



 by R. O. Duda, P. E. Hart and D. G. Stork, John.>")

>")








 – Section 2.11>")


 11/05/07. Methods Linear –PCA (Raychaudhuri et al. 2000) –NIR (Gardner et al. 2003) Nonlinear –Bayesian network (Friedman.>")
 by R. O. Duda, P. E. Hart and D. G. Stork, John.>")
