Download presentation
Presentation is loading. Please wait.

1
Feature Selection as Relevant Information Encoding Naftali Tishby School of Computer Science and Engineering The Hebrew University, Jerusalem, Israel NIPS 2001

2
Many thanks to: Noam Slonim Amir Globerson Bill Bialek Fernando Pereira Nir Friedman

3
Feature Selection? NOT generative modeling! –no assumptions about the source of the data Extracting relevant structure from data –functions of the data (statistics) that preserve information Information about what? Approximate Sufficient Statistics Need a principle that is both general and precise. –Good Principles survive longer!
 that preserve information Information about what. Approximate Sufficient Statistics Need a principle that is both general and precise. –Good Principles survive longer!.")
4
A Simple Example...

5
Simple Example

6
A new compact representation The document clusters preserve the relevant information between the documents and words

7
DocumentsWords

8
Mutual information How much X is telling about Y? I(X;Y): function of the joint probability distribution p(x,y) - minimal number of yes/no questions (bits) needed to ask about x, in order to learn all we can about Y. Uncertainty removed about X when we know Y: I(X;Y) = H(X) - H( X|Y) = H(Y) - H(Y|X) H(X|Y) H(Y|X) I(X;Y)
: function of the joint probability distribution p(x,y) - minimal number of yes/no questions (bits) needed to ask about x, in order to learn all we can about Y. Uncertainty removed about X when we know Y: I(X;Y) = H(X) - H( X|Y) = H(Y) - H(Y|X) H(X|Y) H(Y|X) I(X;Y).")
9
Relevant Coding What are the questions that we need to ask about X in order to learn about Y? Need to partition X into relevant domains, or clusters, between which we really need to distinguish... XY X|y 1 y2y2 y1y1 P(x|y 1 ) P(x|y 2 ) X|y 2
 P(x|y 2 ) X|y 2.")
10
Bottlenecks and Neural Nets Auto association: forcing compact representations is a relevant code of w.r.t. Input Output Sample 1 Sample 2 PastFuture

11
Q: How many bits are needed to determine the relevant representation? –need to index the max number of non-overlapping green blobs inside the blue blob: (mutual information!)
.")
12
Information Bottleneck The distortion function determines the relevant part of the pattern… but what if we don’t know the distortion function but rather a relevance variable? Examples: Speech vs its transcription Images vs objects-names Faces vs expressions Stimuli vs spike-trains (neural codes) Protein-sequences vs structure/function Documents vs text-categories Input vs responses etc...
 Protein-sequences vs structure/function Documents vs text-categories Input vs responses etc....")
13
The idea: find a compressed signal that needs short encoding ( small ) while preserving as much as possible the information on the relevant signal ( )
 while preserving as much as possible the information on the relevant signal ( )")
14
A Variational Principle We want a short representation of X that keeps the information about another variable, Y, if possible.

15
Self Consistent Equations The Self Consistent Equations Marginal: Markov condition: Bayes’ rule:

16
effective distortion The emerged effective distortion measure: Regular if is absolutely continuous w.r.t. Small if predicts y as well as x:

17
The iterative algorithm: (Generalized Blahut-Arimoto) Generalized BA-algorithm
 Generalized BA-algorithm")
18
Information Bottleneck The Information Bottleneck Algorithm “free energy”

19
The Information - plane, the optimal for a given is a concave function: Possible phase impossible

20
Regression as relevant encoding Extracting relevant information is fundamental for many problems in learning: Regression: Knowing the parametric class we can calculate p(X,Y), without sampling! Gaussian noise

21
Manifold of relevance The self consistent equations: Assuming a continuous manifold for Coupled (local in ) eigenfunction equations, with as an eigenvalue.
 eigenfunction equations, with as an eigenvalue.")
22
Generalization as relevant encoding The two sample problem: the probability that two samples come from one source Knowing the function class we can estimate p(X,Y). Convergence depends on the class complexity.

23
Document classification - information curves

24
Multivariate Information Bottleneck Complex relationship between many variables Multiple unrelated dimensionality reduction schemes Trade between known and desired dependencies Express IB in the language of Graphical Models Multivariate extension of Rate-Distortion Theory

25
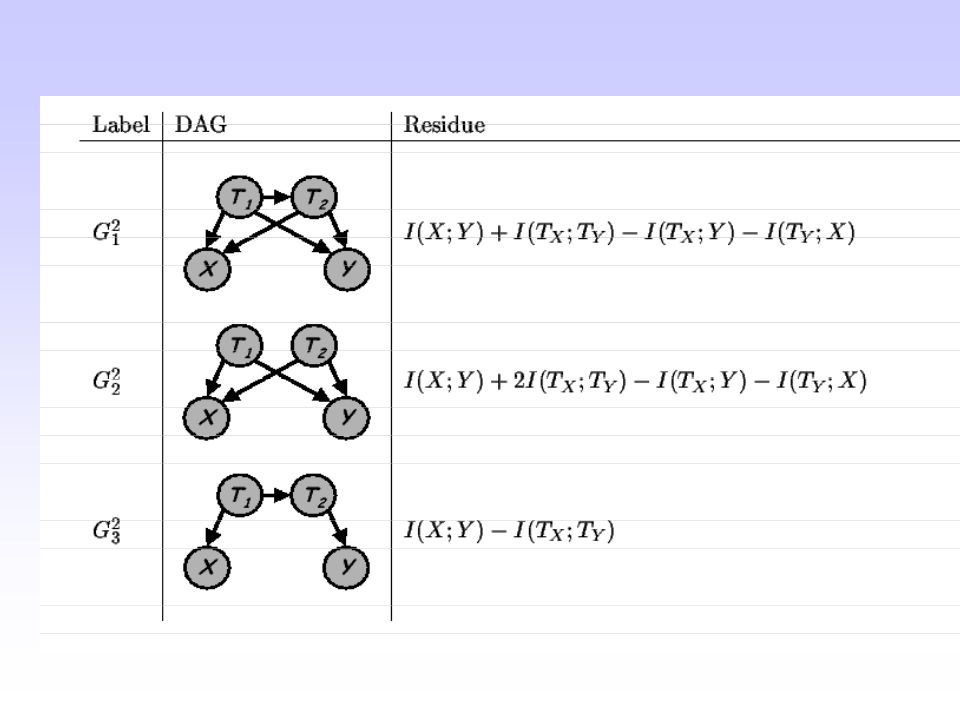
Multivariate Information Bottleneck: Extending the dependency graphs (Multi-information)
")
27
Sufficient Dimensionality Reduction (with Amir Globerson) Exponential families have sufficient statistics Given a joint distribution, find an approximation of the exponential form: This can be done by alternating maximization of Entropy under the constraints: The resulting functions are our relevant features at rank d.
 Exponential families have sufficient statistics Given a joint distribution, find an approximation of the exponential form: This can be done by alternating maximization of Entropy under the constraints: The resulting functions are our relevant features at rank d.")
28
Conclusions There may be a single principle behind... Noise filtering time series prediction categorization and classification feature extraction supervised and unsupervised learning visual and auditory segmentation clustering self organized representation...

29
Summary We present a general information theoretic approach for extracting relevant information. It is a natural generalization of Rate-Distortion theory with similar convergence and optimality proofs. Unifies learning, feature extraction, filtering, and prediction... Applications (so far) include: –Word sense disambiguation –Document classification and categorization –Spectral analysis –Neural codes –Bioinformatics,… –Data clustering based on multi-distance distributions –…
 include: –Word sense disambiguation –Document classification and categorization –Spectral analysis –Neural codes –Bioinformatics,… –Data clustering based on multi-distance distributions –….")
Similar presentations