Download presentation
Presentation is loading. Please wait.

1
University of Alberta Letter-to-phoneme conversion Sittichai Jiampojamarn sj@cs.ualberta.ca CMPUT 500 / HUCO 612 September 26, 2007

2
University of Alberta Outline Part I –Introduction to letter-phoneme conversion Part II –Many-to-Many alignments and Hidden Markov Models to Letter- to-phoneme conversion., NAACL 2007 Part III –On-going work: discriminative approaches for letter-to-phoneme conversion Part IV –Possible term projects for CMPUT 500 / HUGO 612

3
University of Alberta The task Converting words to their pronunciations –study -> [ s t ʌ d I ] –band-> [b æ n d ] –phoenix-> [ f i n I k s ] –king -> [ k I ŋ ] Words sequences of letters. Pronunciations sequence of phonemes. –Ignoring syllabifications, and stresses.
![University of Alberta The task Converting words to their pronunciations –study -> [ s t ʌ d I ] –band-> [b æ n d ] –phoenix-> [ f i n I k s ] –king -> [ k I ŋ ] Words sequences of letters.](http://images.slideplayer.com/16/5054963/slides/slide_3.jpg "Pronunciations sequence of phonemes. –Ignoring syllabifications, and stresses..")
4
University of Alberta Why is it important? Major component in speech synthesis systems Word similarity based on pronunciation –Spelling correction. (Toutanova and Moore, 2001) Linguistic interest of relationships between letters and phonemes. Not a trivial task, but tractable.
 Linguistic interest of relationships between letters and phonemes. Not a trivial task, but tractable..")
5
University of Alberta Trivial solutions ? Dictionary – searching answers on database –Great effort to construct such large lexicon database. –Can’t handle new words and misspellings. Rule-based approaches –Work well on non-complex languages –Fail on complex languages Each word creates its own rules. --- end up with remembering word-phoneme pairs.

6
University of Alberta John Kominek and Alan W. Black, “Learning Pronunciation Dictionaries: Language Complexity and Word Selection Strategies”, In proceeding of HLT-NAACL 2006, June 4-9, pp.232-239

7
University of Alberta Learning-based approaches Training data –Examples of words and their phonemes. Hidden structure –band [b æ n d ] b [b], a [æ], n [n], d [d] –abode [ə b o d] a [ ə ], b [b], o [o], d [d], e [ _ ]

8
University of Alberta Alignments To train L2P, we need alignments between letters and phonemes a ->[ə] b ->[b] o ->[o] d ->[d] e ->[_]
![University of Alberta Alignments To train L2P, we need alignments between letters and phonemes a ->[ə] b ->[b] o ->[o] d ->[d] e ->[_]](http://images.slideplayer.com/16/5054963/slides/slide_8.jpg "University of Alberta Alignments To train L2P, we need alignments between letters and phonemes a ->[ə] b ->[b] o ->[o] d ->[d] e ->[_]")
9
University of Alberta Overview standard process

10
University of Alberta Letter-to-phoneme alignments Previous work assumed one-to-one alignment for simplicity (Daelemans and Bosch, 1997; Black et al., 1998; Damper et al., 2005). Expectation-Maximization (EM) algorithms are used to optimize the alignment parameters. Matching all possible letters and phonemes iteratively until the parameters converge.
 algorithms are used to optimize the alignment parameters. Matching all possible letters and phonemes iteratively until the parameters converge..")
11
University of Alberta 1-to-1 alignments Initially, alignments parameters can start from uniform distribution, or counting all possible letter-phoneme mapping. Ex. abode [ə b o d] P(a, ə) = 4/5 P(b,b) = 3/5 …
 = 4/5 P(b,b) = 3/5 ….")
12
University of Alberta 1-to-1 alignments Find the best possible alignments based on current alignment parameters. Based on the alignments found, update the parameters.

13
University of Alberta Finding the best possible alignments Dynamic programming: –Standard weighted minimum edit distance algorithm style. –Consider the alignment parameter P(l,p) is a mapping score component. –Try to find alignments which give the maximum score. –Allow to have null phonemes but not null letters It is hard to incorporate null letters in the testing data
 is a mapping score component. –Try to find alignments which give the maximum score. –Allow to have null phonemes but not null letters It is hard to incorporate null letters in the testing data.")
14
University of Alberta Visualization

15
University of Alberta Visualization

16
University of Alberta Visualization

17
University of Alberta Visualization

18
University of Alberta Visualization

19
University of Alberta Visualization

20
University of Alberta Visualization

21
University of Alberta Visualization

22
University of Alberta Visualization

23
University of Alberta Visualization

24
University of Alberta Problems with 1-to-1 alignments Double letters: two letters map to one phoneme. (e.g. ng [ŋ], sh [ ʃ ], ph [f])
.")
25
University of Alberta Problem with 1-to-1 alignments Double phonemes: one letter maps to two phonemes. (e.g. x [k s], u [j u])
.")
26
University of Alberta Previous solutions for double phonemes Preprocess using a fix list of phonemes. –[k s] -> [X] –[j u] -> [U]

27
University of Alberta Applying many-to-many alignments and Hidden Markov Models to Letter-to-Phoneme conversion Sittichai Jiampojamarn, Grzegorz Kondrak and Tarek Sherif Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL- HLT 2007), Rochester, NY, April 2007, pp.372-379.
, Rochester, NY, April 2007, pp")
28
University of Alberta Overview system Prediction process Alignment process

29
University of Alberta Many-to-many alignments EM-based method. Extended from the forward-backward training of a one-to-one stochastic transducer (Ristad and Yianilos, 1998). Allow one or two letters to map to null, one, or two phonemes.
. Allow one or two letters to map to null, one, or two phonemes..")
30
University of Alberta Many-to-many alignments

31
University of Alberta Many-to-many alignments

32
University of Alberta Many-to-many alignments

33
University of Alberta Prediction problem Should the prediction model generate phonemes from one or two letters ? –gash [g æ ʃ ] gasholder [g æ s h o l d ə r]

34
University of Alberta Letter chunking A bigram letter chunking prediction automatic discovers double letters. Ex. longs

35
University of Alberta Overview system Prediction process Alignment process

36
University of Alberta Phoneme prediction Once the training examples are aligned, we need a phoneme prediction model. “Classification task” or “sequence prediction”?

37
University of Alberta Instance based learning Store the training examples. The predicted class is assigned by searching the “most similar” training instance. The similarity functions: –Hamming distance, Euclidean distance, etc.

38
University of Alberta Basic HMMs A basic sequence-based prediction method. In L2P, –letters are observations –phonemes are states Output phoneme sequences depend on both emission and transition probabilities.

39
University of Alberta Applying HMM Use an instance based learning to produce a list of candidate phones with confidence values “ conf(phone i ) ” for each letter i. (emission probability). Use a language model of phoneme sequence in the training data to obtain transition probability P(phone i | phone i-1, … phone i-n ).
. Use a language model of phoneme sequence in the training data to obtain transition probability P(phone i | phone i-1, … phone i-n )..")
40
University of Alberta Visualization Buried -> [ b E r aI d ] = 2.38 x 10 -8 Buried -> [ b E r I d ] = 2.23 x 10 -6
![University of Alberta Visualization Buried -> [ b E r aI d ] = 2.38 x Buried -> [ b E r I d ] = 2.23 x 10 -6](http://images.slideplayer.com/16/5054963/slides/slide_40.jpg "University of Alberta Visualization Buried -> [ b E r aI d ] = 2.38 x Buried -> [ b E r I d ] = 2.23 x 10 -6")
41
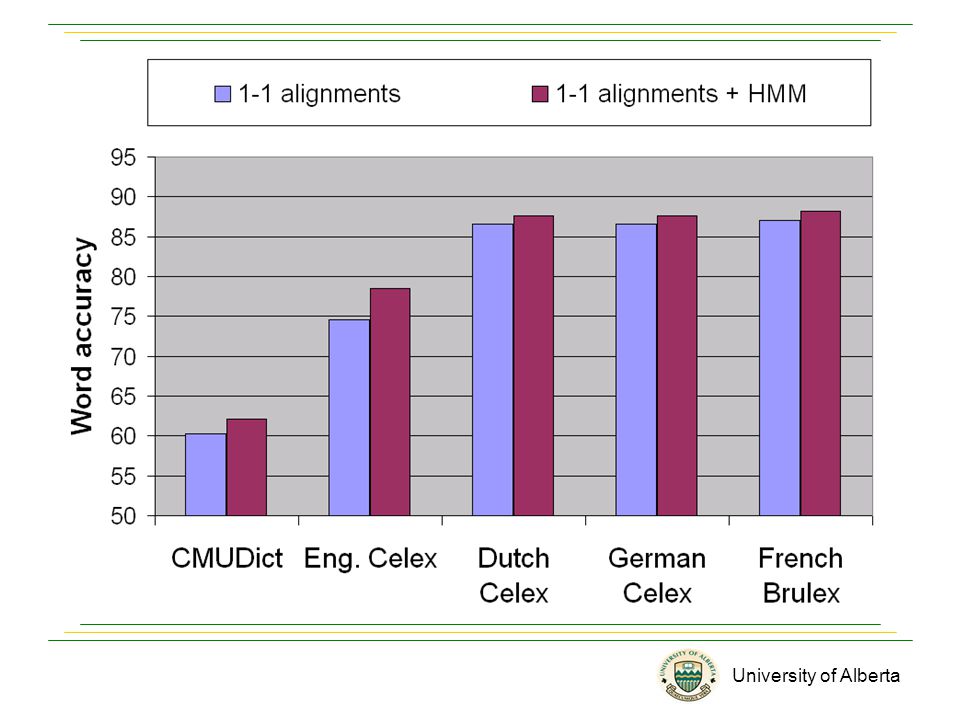
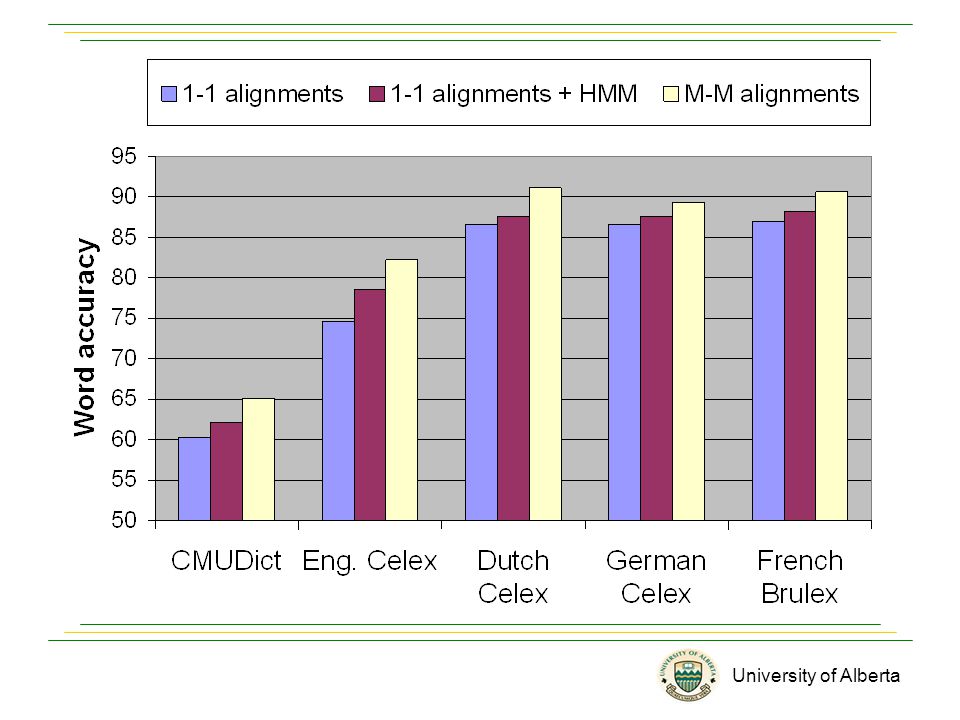
University of Alberta Evaluation Data sets –English: CMUDict (112K), Celex (65K). –Dutch: Celex (116K). –German: Celex (49K). –French: Brulex (27K). IB1 algorithm implemented in TiMBL package as the classifier. (W. Daelemans et al., 2004.) Results are reported in word accuracy rate based on 10- fold cross validation.
. –German: Celex (49K). –French: Brulex (27K). IB1 algorithm implemented in TiMBL package as the classifier. (W. Daelemans et al., 2004.) Results are reported in word accuracy rate based on 10- fold cross validation..")
42
University of Alberta

46
Messages Many-to-many alignments show significant improvements over one-to-one traditional alignments. HMM-like approach helps when a local classify has difficulty to predict phonemes.

47
University of Alberta Criticism Joint models –Alignments, chunking, prediction, and HMM. Error propagation –Errors from one model to other models which are unlikely to re-correct. Can we combine and optimize at once ? Or at least allow the system to re-correct past errors ?

48
University of Alberta On-going work Discriminative approach for letter-to-phoneme conversion

49
University of Alberta Online discriminative learning Let x is an input word and y is an output phonemes. represents features describing x and y. is a weight vector for

50
University of Alberta Online training algorithm 1.Initially, 2.For k iterations 1.For all letter-phoneme sequence pairs (x,y) 1. 2. update weights according to and

51
University of Alberta Perceptron update (Collins, 2002) Simple update training method. Try to move the weights to the direction of correct answers when predicting wrong answers.

52
University of Alberta Examples Separable case Adapted from Dan Klein’s tutorial slides at NAACL 2007.

53
University of Alberta Examples Non-separable case Adapted from Dan Klein’s tutorial slides at NAACL 2007.

54
University of Alberta Issues with Perceptron Overtraining: test / held-out accuracy usually rises, then falls. Regularization: –if the data isn’t separable, weights often thrash around. –Finds a “barely” separating solution Taken from Dan Klein’s tutorial slides at NAACL 2007.

55
University of Alberta Margin Infused Relaxed Algorithm (MIRA) (Crammer and Singer, 2003) Use n-best list to update weights. separate by a margin at least as large as a loss function and keep the weight changes as small as possible.

56
University of Alberta Loss function in letter-to-phoneme Describe the loss of an incorrect prediction compared to the correct one. Word error (0/1), phoneme error, or combination.
, phoneme error, or combination..")
57
University of Alberta Results Incomplete !!! –MIRA outperforms Perceptron. –Using 0/1 loss and combination loss are better than the phoneme loss function alone. –Overall, results show better performance than previous work.

58
University of Alberta Possible term projects

59
University of Alberta Possible term projects 1.Explore more linguistic features. 2.Explore machine translation systems for letter-to- phoneme conversion. 3.Unsupervised approaches for letter-to-phoneme conversion. 4.Other cool ideas to improve on a partial system –Data for evaluation are provided –Alignments are provided. –L2P model are provided.

60
University of Alberta Linguistic features Looking for linguistic features to help L2P –Most systems incorporate letter feature (n-gram) type in some ways. The new features (must) be obtained by using (only) word information. Works been already done –Syllabification : Susan’s thesis Find syllabification break on letters using SVM approach.
 be obtained by using (only) word information. Works been already done –Syllabification : Susan’s thesis Find syllabification break on letters using SVM approach..")
61
University of Alberta Machine translation approach L2P problem can be seen as a (simple) machine translation problem. Where, we’d like to translate letters to phonemes. –Consider: L2P MT Letters words Words sentences Phonemes target sentences Moses -- a baseline SMT system, ACL 2007 –http://www.statmt.org/wmt07/baseline.htmlhttp://www.statmt.org/wmt07/baseline.html –May need to also look at GIZA++, Pharaoh, Carmel, etc.

62
University of Alberta Unsupervised approaches Assuming, we don’t have examples of word-phoneme pairs to train a model. We can start from a list of possible letter-phoneme mappings Or assuming, we have a small set of example pairs (~100 pairs). Don’t expect to outperform the supervised approach but take advantage of being unsupervised methods
. Don’t expect to outperform the supervised approach but take advantage of being unsupervised methods.")
63
University of Alberta References Collins, M. 2002. Discriminative training methods for hidden Markov models: theory and experiments with perceptron algorithms. In Proceedings of the Acl-02 Conference on Empirical Methods in Natural Language Processing - Volume 10 Annual Meeting of the ACL. Association for Computational Linguistics, Morristown, NJ, 1-8 Crammer, K. and Singer, Y. 2003. Ultraconservative online algorithms for multiclass problems. J. Mach. Learn. Res. 3 (Mar. 2003), 951-991. Kristina Toutanova and Robert C. Moore. 2001. “Pronunciation modeling for improved spelling correction”. In ACL’02: pp144-151, 2001. John Kominek and Alan W Black, “Learning Pronunciation Dictionaries Language Complexity and Word Selection Strategies”, NAACL06, pp. 232-239, 2006. Walter M. P. Daelemans and Antal P. J. van den Bosch. 1997. “Language-independent data- oriented grapheme-to-phoneme conversion.” In Progress in Speech Synthesis, pages 77.89. Springer, New York. Alan W Black, Kevin Lenzo, and Vincent Pagel. 1998. “Issues in building general letter to sound rules”. In The Third ESCA Workshop in Speech Synthesis, pages 77-80.
, Kristina Toutanova and Robert C. Moore Pronunciation modeling for improved spelling correction . In ACL’02: pp , John Kominek and Alan W Black, Learning Pronunciation Dictionaries Language Complexity and Word Selection Strategies , NAACL06, pp , Walter M. P. Daelemans and Antal P. J. van den Bosch Language-independent data- oriented grapheme-to-phoneme conversion. In Progress in Speech Synthesis, pages Springer, New York. Alan W Black, Kevin Lenzo, and Vincent Pagel Issues in building general letter to sound rules . In The Third ESCA Workshop in Speech Synthesis, pages")
64
University of Alberta References Robert I. Damper, Yannick Marchand, John DS. Marsters, and Alexander I. Bazin. 2005. “Aligning text and phonemes for speech technology applications using an EM-like algorithm”, International Journal of Speech Technology, 8(2):147-160, June 2005. Eric Sven Ristad and Peter N. Yianilos. 1998. “Learning string-edit distance.” IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(5):522.532. Walter Daelemans, Jakub Zavrel, Ko Van Der Sloot, and Antal Van Den Bosch. 2004. “TiMBL: Tilburg Memory Based Leaner, version 5.1, reference guide.” In ILK Technical Report Series 04- 02., 2004.
: , June Eric Sven Ristad and Peter N. Yianilos Learning string-edit distance. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(5): Walter Daelemans, Jakub Zavrel, Ko Van Der Sloot, and Antal Van Den Bosch TiMBL: Tilburg Memory Based Leaner, version 5.1, reference guide. In ILK Technical Report Series ,")
Similar presentations




>")







>")
>")


>")



