Download presentation
Presentation is loading. Please wait.

1
Speech Recognition Part 3 Back end processing

2
Speech recognition simplified block diagram Speech Capture Speech Capture Feature Extraction Feature Extraction Training Models Pattern Matching Pattern Matching Process Results Process Results Text

3
Building a phone model Annotate the speech input Split and create feature vectors for each

4
Praat Semi automatic anotation –http://www.fon.hum.uva.nl/praat/

5
Probability based state machine Hidden Markov Models Transition probability and output probability

6
One HMM per phone (monophone) th r iy h# 45 phones in British English + silence ($)
 th r iy h# 45 phones in British English + silence ($)")
7
One HMM per two phones (biphone) $ - th or th + r th - r or r + iy r - iy or iy + h# iy - h# or h# + $ Associate with left or right phone Up to 45 x 46 + $ = 2,071 models
 $ - th or th + r th - r or r + iy r - iy or iy + h# iy - h# or h# + $ Associate with left or right phone Up to 45 x 46 + $ = 2,071 models")
8
One HMM per three phones (triphone) $ - th + r th - r + iy r - iy + h# iy - h# + $ Associate with left and right phone Up to 45x46x46+$ = 95,220 models
 $ - th + r th - r + iy r - iy + h# iy - h# + $ Associate with left and right phone Up to 45x46x46+$ = 95,220 models")
9
HMMs are presented with FV sequence of each triphone and “learn” the sound to be recognised using the Baum – Welch algorithm Training HMMs Feature vectors stepped passed and presented to the model

10
Millions of utterances from different people used to train the models Feature vectors from each phoneme are presented to the HMM in training mode HMM states model temporal variability. Eg, one feature vector “sound” may last longer than another so the HMM may stay in that state for longer What is the probability of the current FV being in state T? What is the probability of the transition from state T to state T, T+1, T+2? After many samples, state and transition probabilities stop improving Not all models need to be created as not all triphone combinations are sensible for a particular language

12
Language Model Determines the likelihood of word sequences by analysing lots of text from newspapers and other popular textual sources Typically use trigrams – the frequency of a word which follows one word and precedes another Trigrams for the whole ASR vocabulary (if enough training data is available) are stored for look-up to determine probabilities
 are stored for look-up to determine probabilities")
13
Trigram Probability

14
Recognition problem With the phone based HMMs trained, consider the recognition problem: An utterance consists of a sequence of words, W=w 1,w 2,… w n and the Large Vocabulary Recognition system (LVR) needs to find the most probable word sequence W max given the observed acoustic signal Y. In other words:

15
Bayes’ rule Need to maximise the probability of W given utterance Y - too complex Rewrite using Bayes’ rule to create two more solvable problems

16
Maximise the probability of can ignore P(y) as it is independent of W P(W) is independent of Y so can be found using written text to form a language model P(Y|W): for a given word(s) what is the probability that the current series of speech vectors are that word. This comes from the acoustic models of phonemes concatenated into words

17
Recognition goal

18
Typical recogniser

19
Dictionary Often called a lexicon. Contains the pronunciations of the vocabulary at a phonetic level There may be more than one pronunciation stored for the same word if it is said differently in different contexts “The end” “Thee end” or dialects “Man- chest-er” or “Mon-chest-oh” There may be one entry for more than one word e.g. Red and Read (need language model to sort this out)
.")
20
Decoding Complex, processor intensive, memory intensive Consider simplest method (but most costly): –Find start (after a quiet bit) and hypothesise all possible start words based on the current potential words available from the HMMs such as I, eye, high etc. –Determine the probability of the potential HMMs to be one of these

21
Phoneme recognition Feature vectors presented to all models. Each HMM generates a feature vector and it is compared to the current input feature vector. The output probabilities determine the most likely match. Which phonemes are tested are determined by the language model and lexicon. Feature vectors P(th) = 0.51 P(r) = 0.05 P(iy) = 0.35 P(h#) = 0.001 P(p) = 0.03 P(k) = 0.015
 = 0.51 P(r) = 0.05 P(iy) = 0.35 P(h#) = P(p) = 0.03 P(k) =")
22
Concatenate phonemes to make words th(0.01) R(0.5) iy(0.065) h#(0.001) p(0.03) K(0.015)
 R(0.5) iy(0.065) h#(0.001) p(0.03) K(0.015)")
23
Probabilities multiplied to get total score Need some way of reducing complexity Obviously too many combinations –th + r + ie + h# is ok –th + z + z + d is not Tree is pruned by discarding least likely paths based on probability and lexical rules

24
–Check the validity of phoneme sequences using the lexicon –Continue to build the tree until an end of utterance is detected (silence or they may say “full stop as a command”) –From the language model, check the probability of the current possible words based on previous two words
 –From the language model, check the probability of the current possible words based on previous two words")
25
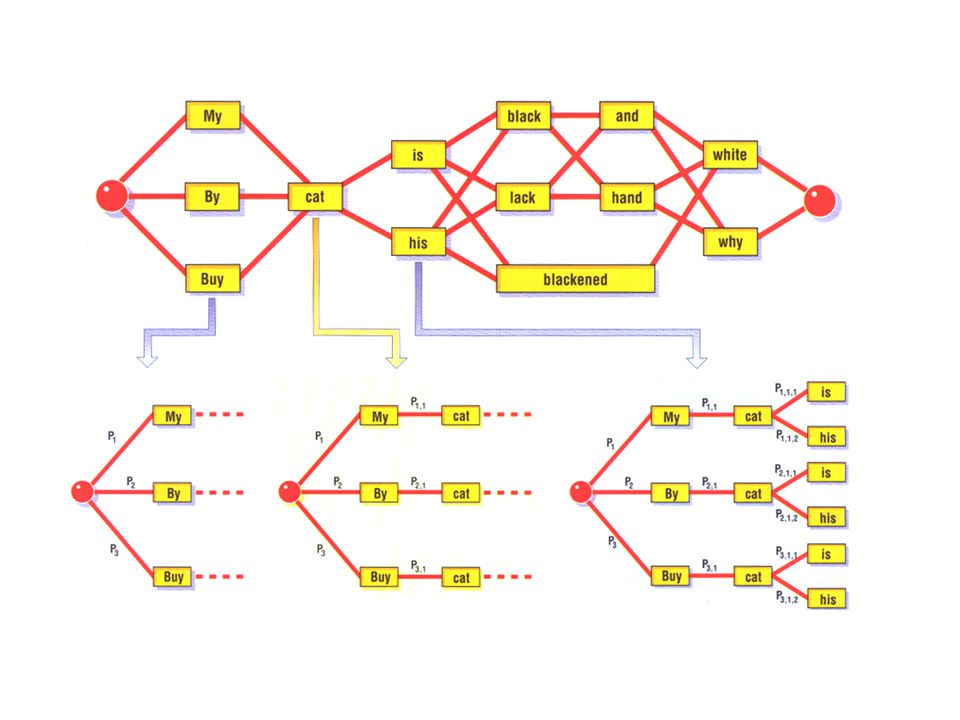
Probability tree A probability tree of possible word combinations is built and the best paths are calculated The tree can become very large and based on processing power and memory requirements, the least likely paths are dropped or the tree is pruned.

27
Sentence decomposition

Similar presentations

4 90 84 35 09 Fax. + 33 (0)4 90 84 35 01>")



>")
 Probabilistic Automata Ubiquitous in Speech/Speaker Recognition/Verification Suitable for modelling phenomena which are dynamic.>")
 Steven Salzberg CMSC 828H, Univ. of Maryland Fall 2010.>")












