Download presentation
Presentation is loading. Please wait.

1
Statistical approaches to language learning John Goldsmith Department of Linguistics May 11, 2000

2
Trends in the study of language acquisition 1 Chomsky-inspired: “principles and parameters” (since 1979) 2 Transcribe and write a grammar 3 Compute statistics, and develop a minimum description length (MDL)
 2 Transcribe and write a grammar 3 Compute statistics, and develop a minimum description length (MDL)")
3
1 Principle and parameters The variation across languages boils down to two things: –alternate settings of a small set of “parameters” (a few hundred?), each of which has only a small number of possible settings (2? 3? 4?) –learn some arbitrary facts, like the pronunciation of words
 –learn some arbitrary facts, like the pronunciation of words.")
4
What’s a “parameter”, for instance? 1. Pro-drop parameter: yes/no. Yes? Spanish, Italian. Subject is optional; subject may appear before or after the verb; verb agrees with the subject (present or absent) with overt morphology. No? English, French. Subject is obligatory. Dummy subjects (It is raining, There is a man at the door.)
 with overt morphology. No. English, French. Subject is obligatory. Dummy subjects (It is raining, There is a man at the door.).")
5
Or, noun-adjective order… Noun precedes adjective: French, Spanish: F. la voiture rouge “the red car” but literally “the car red” Noun follows adjective: English

6
Criticisms: 1. This approach intentionally puts a lot of information into the innate language “faculty.” How can we be sure the linguist isn’t just cataloging a lot of differences between English and Spanish (e.g.) and proclaiming that this is a universal difference? 2. You don’t need an innate language faculty to realize that children have to learn whether nouns precede adjectives or not.
 and proclaiming that this is a universal difference. 2. You don’t need an innate language faculty to realize that children have to learn whether nouns precede adjectives or not..")
7
3. The theory is completely silent about the learning of morphemes and words. It implies (by the silence) that this stuff is easy to learn. But maybe it’s the hardest stuff to learn, requiring such a sophisticated learning apparatus that the grammar will be easy (by comparison) to learn.
 that this stuff is easy to learn. But maybe it’s the hardest stuff to learn, requiring such a sophisticated learning apparatus that the grammar will be easy (by comparison) to learn..")
8
2. Transcribe and write a grammar Long tradition; landmark is Roger Brown’s work in the 1960s. Value: extremely important empirical basis. Criticism: tells us very little about the how or the process of language acquisition.

9
3. Statistics and minimum description length Recent work -- probabilities in the lab: n Saffran, J., Aslin, R., & Newport, E. (1996). Statistical learning by 8-month- old infants. Science, 274, 1926-1928. She argues that even quite young children can extract information about the “chunking” of sounds into pieces on the basis of their frequent occurrences together.
. Statistical learning by 8-month- old infants. Science, 274, She argues that even quite young children can extract information about the chunking of sounds into pieces on the basis of their frequent occurrences together..")
10
The linguist’s acquisition problem: What “must” happen in order for someone to end up knowing a particular language. We (linguists) can map out models (and run them on computers) that show how easy (or hard) it is to arrive at a grammar of English (etc.) on the basis of various assumptions.
 can map out models (and run them on computers) that show how easy (or hard) it is to arrive at a grammar of English (etc.) on the basis of various assumptions..")
11
We can’t tell which kinds of information a child uses. But we can argue that learning X or Y is easier/harder/the same if you assume the child has access to certain kinds of data (e.g., semantic, grammatical).
..")
12
Probabilistic and statistical approaches The fundamental premise of probabilistic approaches to language is this: Degrees of (un)certainty can be quantified.
certainty can be quantified.")
13
Two problems of language acquisition that have been seriously tackled 2 closely related problems: 1. Segmenting an utterance into word- sized pieces (Brent, de Marcken, others) 2. Segmenting words into morphemes. (Goldsmith)
 2. Segmenting words into morphemes. (Goldsmith).")
14
Minimum Description Length Jorma Rissanen (1989) Data Analyzer Analysis Select the analyzer and analysis such that the sum of their lengths is a minimum.
 Data Analyzer Analysis Select the analyzer and analysis such that the sum of their lengths is a minimum.")
15
Data Analyzer Analysis Analyzer Analysis Analyzer Analysis Analyzer Analysis Analyzer Analysis Etc...

16
The challenge Is to find a means of quantifying n the length of an analyzer, and n the length of an analysis

17
“Compressed form of data?” Think of data as a dense, rich, detailed description (evidence), and Think of compressed form as n Description in high level language + n Description of the particulars of the event in question (a.k.a. boundary conditions, etc.)...
....")
18
Example: Utterance: “theolddogandthenotsooldcatgotintotheyardwi thoutanybodynoticing ” 62 letters as it stands. Or: 1 = the 2=old 3=dog 4 = not 123and24so2catgotinto1yardwithoutanyb ody4icing. 46 symbols here, 12 above, total of 58 --

19
Compare with Early Generative Grammar (EGG) Data Linguistic Theory Analysis 1 Analysis 2 Preference: A1/A2
 Data Linguistic Theory Analysis 1 Analysis 2 Preference: A1/A2")
20
Linguistic theory Data Analysis Linguistic theory Data Analysis Yes/No Linguistic theory Analysis 1 Analysis 2 Data 1 is better/ 2 is better

21
Implicit in EGG was the notion... that the best Linguistic Theory could be selected by... Getting a set of n candidate LTs; submitting to each a set of corpora; search (using unknown heuristics) for best analyses of each corpus within each LT; The LT wins for whom the sum total of all of the analyses is the smallest.
 for best analyses of each corpus within each LT; The LT wins for whom the sum total of all of the analyses is the smallest..")
22
No cost to UG n In EGG, there was no cost associated with the size of UG -- in effect, no plausibility measure.

23
In MDL, in contrast…. n we can argue for a grammar for a given corpus. n We can also argue at the Linguistic Theory level if we so choose...

24
Distinction between heuristics and “theory” n In the context of MDL, the heuristics are extratheoretical, but from the point of view of the (psycho-)linguist, they are very important. n The heuristics propose; the theory disposes.

25
The goal: To produce a morphological analysis of a corpus from an “unknown” language automatically that is, with no knowledge of the structure of that language built in; To produce both generalizations about the language, and a correct analysis of each word in the corpus.

26
Linguistica

27
Implemented in Linguistica, a program that runs under Windows that you can download at: humanities.uchicago.edu/faculty/goldsmith

28
Other work in this area n Derrick Higgins on Thursday; n Michael Brent 1993; n Zellig Harris: 1955 and 1967, follow-up: Hafer and Weiss 1974

29
Zellig Harris:Right-branching count Right-branching count of jum: 2 jum p ( jump, jumping, jumps, jumped, jumpy ) b (jumble) Right-branching count of jump:5 e (jumped) i (jumping) jumps (jumps) y (jumpy) # (jump)
 b (jumble) Right-branching count of jump:5 e (jumped) i (jumping) jumps (jumps) y (jumpy) # (jump)")
30
Zellig Harris:Right-branching count a c c e p t i n g 19 9 6 3 1 3 1 1 able ing lerate (“accelerate”) nted (“accented”) ident (“accident”) laim (“acclaim”) omodate (“accomodate”) reditated (“accredited”) used (“accused”) predicted break
 nted ( accented ) ident ( accident ) laim ( acclaim ) omodate ( accomodate ) reditated ( accredited ) used ( accused ) predicted break")
31
5 Zellig Harris:Right-branching count d a e i o 9 a b debate, debuting c decade, december, decide d dedicate, deduce, deduct e deep f edefeat, defend, defer ideficit, deficiency rdefraud ddead fdeaf ldeal ndean tdeath 18 3 Bad predictions Good predictions

32
Zellig Harris:Right-branching count c o n s e r v a t i v e s 9 18 11 6 4 1 2 1 1 2 1 1 wrong rightwrong

33
The problem with Harris’ approach it cannot distinguish between n phonological freedom due to phonological patterns (C after V, V after C) n phonological freedom due to morphological pattern (...any morpheme after a +...) But that’s the problem it’s supposed to solve.
 n phonological freedom due to morphological pattern (...any morpheme after a +...) But that’s the problem it’s supposed to solve.")
34
Global approach n Focus on devising a method for evaluating a hypothesis, given the data. n Finding explicit methods of discovery is important, but those methods play no role in evaluating the analysis for a given corpus. (Very similar in conception to Chomsky’s notion of an evaluation metric.)
.")
35
Framework for evaluation: Jorma Rissanen’s Minimum Description Length (“MDL”). Quite intricate; but we can get a very good feel for the general idea with a naïve version of MDL...

36
Naive description length Count the total number of letters in the list of stems and affixes: the fewer, the better.

37
Intuition: A word which is morphologically complex reveals that composite character by virtue of being composed of (one or more) strings of letters which have a relatively high frequency throughout the corpus.
 strings of letters which have a relatively high frequency throughout the corpus.")
38
Naive description length: 2 Lexicographers know what they are doing when they indicate the entry for the verb laugh as laugh, ~s, ~ed, ~ing -- They recognize that the tilde “ ~” allows them to utilize the regularities of the language in order to save space and specification, and implicitly to underscore the regularity of the pattern that the stem possesses.

39
Morphological analysis is not merely a matter of frequency. Not every word that ends in –ing is morphologically complex: string, sing, etc.

40
Every word that ends in –ity also ends in –ty. Hence: –ty’s frequency > –ity’s frequency. Yet -ty is a suffix only in a few words (like six- ty); ity is a suffix in far more words, despite its lower frequency (insan-ity, precoc-ity, etc.). frequency( y ) > frequency (ty) > frequency (ity); y is a suffix in some words (dirt-y, runn-y, etc.), but not in insan-ity, precoc-ity, etc. Frequencies are important but far from the whole story:
; ity is a suffix in far more words, despite its lower frequency (insan-ity, precoc-ity, etc.). frequency( y ) > frequency (ty) > frequency (ity); y is a suffix in some words (dirt-y, runn-y, etc.), but not in insan-ity, precoc-ity, etc. Frequencies are important but far from the whole story:.")
41
Naive Minimum Description Length : Analyze the words of a corpus into stem + suffix with the requirement that every stem and every suffix must be used in at least 2 distinct words. Tally up the total number of letters in (a) each of the proposed stems, (b) each of the proposed suffixes, and (c) each of the unanalyzed words, and call that total the “naive description length”.
 each of the proposed stems, (b) each of the proposed suffixes, and (c) each of the unanalyzed words, and call that total the naive description length ..")
42
Naive Minimum Description Length Corpus: jump, jumps, jumping laugh, laughed, laughing sing, sang, singing the, dog, dogs total: 62 letters Analysis: Stems: jump laugh sing sang dog (20 letters) Suffixes: s ing ed (6 letters) Unanalyzed: the (3 letters) total: 29 letters. Notice that the description length goes UP if we analyze sing into s+ing

43
Frequencies matter, but only in the overarching context of a total morphological analysis of all of the words of the language.

44
Let’s look at how the work is done, step by step...

45
Corpus Pick a large corpus from a language -- 5,000 to 1,000,000 words.

46
Corpus Bootstrap heuristic Feed it into the “bootstrapping” heuristic...

47
Corpus Out of which comes a preliminary morphology, which need not be superb. Morphology Bootstrap heuristic

48
Corpus Morphology Bootstrap heuristic incremental heuristics Feed it to the incremental heuristics...

49
Corpus Morphology Bootstrap heuristic incremental heuristics modified morphology Out comes a modified morphology.

50
Corpus Morphology Bootstrap heuristic incremental heuristics modified morphology Is the modification an improvement? Ask MDL!

51
Corpus Morphology Bootstrap heuristic modified morphology If it is an improvement, replace the morphology... Garbage

52
Corpus Bootstrap heuristic incremental heuristics modified morphology Send it back to the incremental heuristics again...

53
Morphology incremental heuristics modified morphology Continue until there are no improvements to try.

54
Bootstrapping... initial hypothesis = initial morphology of the corpus

55
First: a set of candidate suffixes for the language Using some interesting statistics.

56
1. Observed frequency of a string (e.g., ing) 2. Predicted frequency of the same string if there were no morphemes in the language 3. The computed “stickiness” of that string 4. Weight the stickiness (3) by how often the string shows up in the corpus
 by how often the string shows up in the corpus.")
57
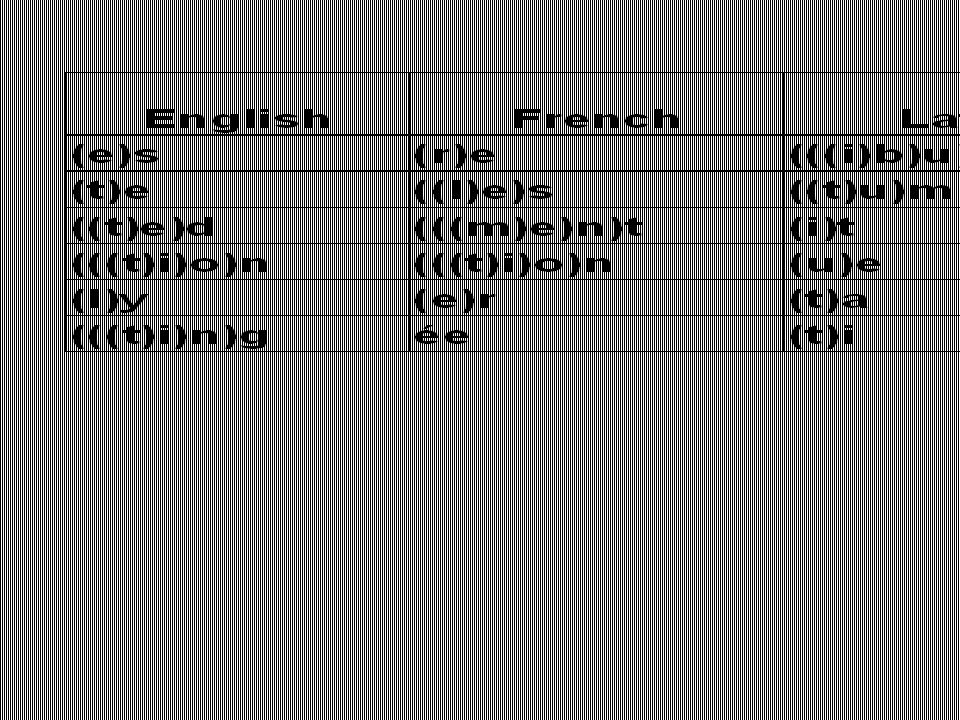
n Rank all word-final sequences of letters (of length 1-4 letters); n This gives us an excellent first guess of the suffixes of the language. n See Handout for English, French, Spanish, and Latin.

59
Given a candidate set of 100 suffixes... n It is not difficult to find the set of stems that gives us the largest number of analyses employing only those suffixes. n We use these to find the major signatures present in the corpus...

60
Discovery of signatures: The first 8 stems in the largest signature in a 500,000 word corpus of English. Set of suffixes that appears with all of these stems

61
Minimum Description Length The real thing, this time: Rissanen 1989. Evaluate a morphology by: 1. How well the morphology extracts generalizations present in the data: how well it describes the data. 2. How concise the morphology is. The “naïve MDL” we just looked at only covered the second point, and only crudely.

62
Measure how well the morphology fits the data: 1. Compute the predicted inverse log frequency of each word in the corpus, and sum: This is a well-understood quantity in information theory, called the “optimal compressed length” of the corpus based on the probability distribution defined by the morphology.

63
Conciseness Sum all the letters, plus all the structure inherent in the description, using information theory.

64
Number of letters structure + Signatures, which we’ll get to shortly

65
Information contained in the Signature component list of pointers to signatures indicates the number of distinct elements in X

66
Results…

67
Suffixes of English Look at your handout.

69
French

70
Spanish

71
Latin

72
Future directions Develop it to work with languages with greater complexity; and Use it as an aide in the task of learning syntax in the same unsupervised fashion.

Similar presentations















 What is language/what is involved in language? 2) What are the stages of language development? 3) Is language.>")



 Sequence Comparisons –Problems in molecular biology involve finding the minimum number of edit.>")
