Download presentation
Presentation is loading. Please wait.

1
Linguistica

2
Powerpoint? This presentation borrows heavily from slides written by John Goldsmith who has graciously given me permission to use them. Thanks, John. He also says I should enjoy my trip, and one way to do that is to not have to write as many slides while I’m here!

3
Linguistica A C++ program that runs under Windows, Mac OS X, and Linux that is available at: http://humanities.uchicago.edu/ faculty/goldsmith/ There are explanations, papers, and other downloadable tools available there.

4
References (for the 1st part) Goldsmith (2001) “Unsupervised Learning of the Morphology of a Natural Language” Computational Linguistics
 Goldsmith (2001) Unsupervised Learning of the Morphology of a Natural Language Computational Linguistics")
5
Overview Look at Linguistica in action: English, French Theoretical foundations Underlying heuristics Further work

6
Linguistica A program that takes in a text in an “unknown” language… …and produces a morphological analysis: a list of stems, prefixes, suffixes; more deeply embedded morphological structure; regular allomorphy

7
Linguistica

8
Actions and outlines of information Here: lists of stems, affixes, signatures, etc. Here: some messages from the analyst to the user.

9
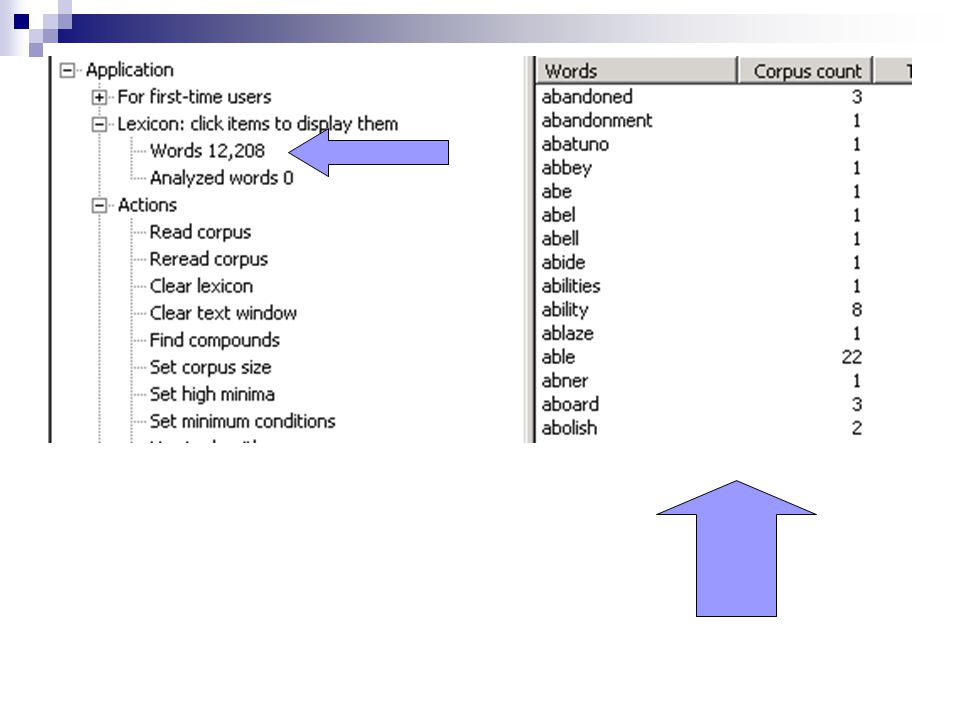
Read a corpus Brown corpus: 1,200,000 words of typical English French Encarta or anything else you like, in a text file. Set the number of words you want read, then select the file.

12
A stem’s signature is the list of suffixes it appears with in the corpus, in alphabetical order. abilit ies.yabilities, ability abolitionabolition absence.tabsence, absent absolute NULL.lyabsolute, absolutely List of stems

13
List of signatures

14
Signature: NULL.ed.ing.s for example, account accounted accounting accounts add added adding adds

15
Signature ion. NULL composite concentratecorporate détente discriminateevacuateinflateopposite participateprobateprosecutetense What is this? compositeand composition composite composit composit + ion It infers that ion deletes a stem-final ‘e’ before attaching. We’ll see how we can find a more sophisticated signature…

16
Top signatures in English

17
Over-arching theory The selection of a grammar, given the data, is an optimization problem. Optimization means finding a maximum or minimum of some objective function Minimum Description Length provides us with a means for understanding grammar selection as minimizing a function. (We’ll get to MDL in a moment)
.")
18
What’s being minimized by writing a good morphology? The number of letters is part of it Compare:

19
Naive Minimum Description Length Corpus: jump, jumps, jumping laugh, laughed, laughing sing, sang, singing the, dog, dogs total: 61 letters Analysis: Stems: jump laugh sing sang dog (20 letters) Suffixes: s ing ed (6 letters) Unanalyzed: the (3 letters) total: 29 letters. Notice that the description length goes UP if we analyze sing into s+ing

20
Minimum Description Length (MDL) Rissanen (1989) (not a CL paper) The best “theory” of a set of data is the one which is simultaneously: 1. most compact or concise, and 2. provides the best modeling of the data “Most compact” can be measured in bits, using information theory “Best modeling” can also be measured in bits…

21
Essence of MDL

22
Description Length = Conciseness: Length of the morphology. It’s almost as if you count up the number of symbols in the morphology (in the stems, the affixes, and the rules). Length of the modeling of the data. We want a measure which gets bigger as the morphology is a worse description of the data. Add these two lengths together = Description Length
. Length of the modeling of the data. We want a measure which gets bigger as the morphology is a worse description of the data. Add these two lengths together = Description Length.")
23
Conciseness of the morphology Sum all the letters, plus all the structure inherent in the description, using information theory.

24
Entropy was the weighted (by p(x) ) sum of the information content or optimal compressed length ( –log 2 p(x) ) of x. It’s called that because it is always possible to develop a compression scheme by which a symbol x, emitted with probability p(x), is represented by a placeholder of length - log 2 p(x) bits. Remember Entropy?
, is represented by a placeholder of length - log 2 p(x) bits. Remember Entropy .")
25
Optimal Compressed Length The reason this is mentioned is that we will have lots of pieces of information in our model, and we’d like to figure out how much “space” it takes up. Remember, we want the smallest model possible, so we are going to want the best compression for anything in our model Also, remember this:

26
Conciseness of stem list and suffix list Number of letters in stem cost of setting up this entity: length of pointer in bits Number of letters in suffix = number of bits/letter < 5

27
Signature list length list of pointers to signatures indicates the number of distinct elements in X

28
Length of the modeling of the data Probabilistic morphology: the measure: -1 * log probability ( data ) where the morphology assigns a probability to any data set. This is known in information theory as the optimal compressed length of the data (given the model).
..")
29
Probability of a data set? A grammar can be used not (just) to specify what is grammatical and what is not, but to assign a probability to each string (or structure). If we have two grammars that assign different probabilities, then the one that assigns a higher probability to the observed data is the better one.
 to specify what is grammatical and what is not, but to assign a probability to each string (or structure). If we have two grammars that assign different probabilities, then the one that assigns a higher probability to the observed data is the better one..")
30
This follows from the basic principle of rationality in the Universe: Maximize the probability of the observed data.

31
From all this, it follows: There is an objective answer to the question: which of two analyses of a given set of data is better? However, there is no general, practical guarantee of being able to find the best analysis of a given set of data. Hence, we need to think of (this sort of) linguistics as being divided into two parts:
 linguistics as being divided into two parts:.")
32
An evaluator (which computes the Description Length); and A set of heuristics, which create grammars from data, and which propose modifications of grammars, in the hopes of improving the grammar. (Remember, these “things” are mathematical things: algorithms.)
.")
33
Let’s step back for a minute Why is this problem so hard at first? Because figuring out the best analysis of any given word generally requires having figured out the rough outlines of the whole overall morphology. (Same is true for other parts of the grammar!). How do we start?
. How do we start .")
34
You all know the answer to this question already… We start with Zellig Harris’ successor frequency! Although we got some good answers, we also saw that it made lots of mistakes So…

35
As a boot-strapping method to construct a first approximation of the signatures: Harris’ method is pretty good. We accept only stems of 5 letters or more; Only cuts where the SuccFreq is > 1, and where the neighboring SuccFreq is 1. (This setup was experiment 16 from the lab on Monday)
.")
36
Let’s look at how the work is done (in the abstract), step by step...
, step by step...")
37
Corpus Pick a large corpus from a language -- 5,000 to 1,000,000 words.

38
Corpus Bootstrap heuristic Feed it into the “bootstrapping” heuristic...

39
Corpus Out of which comes a preliminary morphology, which need not be superb. Morphology Bootstrap heuristic

40
Corpus Morphology Bootstrap heuristic incremental heuristics Feed it to the incremental heuristics (…which we haven’t seen yet)
")
41
Corpus Morphology Bootstrap heuristic incremental heuristics modified morphology Out comes a modified morphology.

42
Corpus Morphology Bootstrap heuristic incremental heuristics modified morphology Is the modification an improvement? Ask MDL!

43
Corpus Morphology Bootstrap heuristic modified morphology If it is an improvement, replace the morphology... Garbage

44
Corpus Bootstrap heuristic incremental heuristics modified morphology Send it back to the incremental heuristics again...

45
Morphology incremental heuristics modified morphology Continue until there are no improvements to try.

46
The details of learning morphology There is nothing sacred about the particular choice of heuristic steps

47
Steps Successor Frequency: strict Extend signatures to cases where a word is composed of a known stem and a known suffix. Loose fit: Look at all unanalyzed words. Look to see if they can cut: stem + suffix, where the suffix already exists. Do this in all possible ways. See if any of these lead to stems with signatures that already exist. If so, take the “best” one. If not, compute the utility of the signature using MDL.

48
Check existing signatures: Using MDL to find best stem/suffix cut. Examples…

49
Check signatures (English) on/ve → ion/ive an/en → man/men l/tion → al/ation m/t → alism/alist, etc. How?

50
Check signatures Signature l/tion with stems: federainauguraorientasubstantia We need to compute the Description Length of the analysis as it stands versus as it would be if we shifted varying parts of the stems to the suffixes.

51
“Check signatures” French: NULL nt r >> a ant ar NULL nt >> i int ent t >> oient oit NULL r >> i ir f on ve >> sif sion sive eur ion >> seur sion ce t >> ruce rut se x >> ouse oux l ux >> al aux me te >> ume ute eurs ion >> teurs tion f ve >> dif dive it nt >> ait ant que sme >> ïque ïsme NULL s ur >> e es eur ient nt >> aient ant f on >> sif sion nt r >> ent er

52
100,000 tokens, 12,208 types Zellig redux1,403 stems 140 signatures 68 suffixes Extend signatures 226 signatures Loose fit2,395702 signatures 68 suffixes Check signatures 2,409730110 Smooth stems 2,400735115

53
Allomorphy Find relations among stems: find principles of allomorphy, like “delete stem-final e before –ing” on the grounds that this simplifies the collection of Signatures: Compare the signatures NULL.ing, and e.ing.

54
NULL.ing and e.ing NULL.ing: its stems do not end in –e -ing (almost) never appears after stem- final e. (ex. singeing) So e.ing and NULL.ing can both be subsumed under: ing.NULL, where ing means a suffix ing which deletes a preceding e.
 So e.ing and NULL.ing can both be subsumed under: ing.NULL, where ing means a suffix ing which deletes a preceding e..")
55
Find layers of affixation Find roots (from among the Stem collection) In other words, recursively look through our list of Stems and see if we could (or should) be analyzing them again: readings = reading+s = read+ing+s Etc.
 In other words, recursively look through our list of Stems and see if we could (or should) be analyzing them again: readings = reading+s = read+ing+s Etc.")
56
What’s the future work? 1. Identifying suffixes through syntactic behavior ( syntax) 2. Better allomorphy ( phonology) 3. Languages with more morphemes/ word (“rich” morphology)
 3. Languages with more morphemes/ word ( rich morphology).")
57
“Using eigenvectors of the bigram graph to infer grammatical features and categories” (Belkin & Goldsmith 2002)
")
58
Method Build a graph in which “similar” words are adjacent; Compute the normalized laplacian (linear algebra -- it just sound fancy!) of that graph; Compute the eigenvectors with the lowest non- zero eigenvalues; (more linear algebra) Plot them.
 of that graph; Compute the eigenvectors with the lowest non- zero eigenvalues; (more linear algebra) Plot them.")
59
Left-side similarities: A word’s left neighbors is the set of words that appear immediately to its left in a corpus. That’s a vector v L in a space of size V = size of vocabulary. For any given word w*, what are the N words whose left- neighbors are most similar to w*’s left-neighbors? Cosine of angle between v i and w* is

60
Map 1,000 English words by left- hand neighbors non-finite verbs: be, do, go, make, see, get, take, go, say, put, find, give, provide, keep, run… finite verbs: was, had, has, would, said, could, did, might, went, thought, told, knew, took, asked… world, way, same, united, right, system, city, case, church, problem, company, past, field, cost, department, university, rate, door, ?: and, to, in that, for, he, as, with, on, by, at, or, from…

61
Map 1,000 English words by right- hand neighbors adjectives social national white local political personal private strong medical final black French technical nuclear british Prepositions: of in for on by at from into after through under since during against among within along across including near

62
End

Similar presentations






 Source Coding and Compression>")



 Array –Unordered Add, delete, search –Ordered Linked List –??>")









