Download presentation
Presentation is loading. Please wait.

1
What is a P2P system? A distributed system architecture: No centralized control Nodes are symmetric in function Large number of unreliable nodes Enabled by technology improvements Node Internet

2
How to build critical services? Many critical services use Internet Hospitals, government agencies, etc. These services need to be robust Node and communication failures Load fluctuations (e.g., flash crowds) Attacks (including DDoS)
 Attacks (including DDoS).")
3
The promise of P2P computing Reliability: no central point of failure Many replicas Geographic distribution High capacity through parallelism: Many disks Many network connections Many CPUs Automatic configuration Useful in public and proprietary settings

4
Traditional distributed computing: client/server Successful architecture, and will continue to be so Tremendous engineering necessary to make server farms scalable and robust Server Client Internet

5
The abstraction: Distributed hash table (DHT) Distributed hash table Distributed application get (key) data node …. put(key, data) Lookup service lookup(key)node IP address Application may be distributed over many nodes DHT distributes data storage over many nodes (File sharing) (DHash) (Chord)
 Lookup service lookup(key)node IP address Application may be distributed over many nodes DHT distributes data storage over many nodes (File sharing) (DHash) (Chord).")
6
A DHT has a good interface Put(key, value) and get(key) value Simple interface! API supports a wide range of applications DHT imposes no structure/meaning on keys Key/value pairs are persistent and global Can store keys in other DHT values And thus build complex data structures

7
A DHT makes a good shared infrastructure Many applications can share one DHT service Much as applications share the Internet Eases deployment of new applications Pools resources from many participants Efficient due to statistical multiplexing Fault-tolerant due to geographic distribution

8
Recent DHT-based projects File sharing [CFS, OceanStore, PAST, Ivy, …] Web cache [Squirrel,..] Archival/Backup store [HiveNet, Mojo, Pastiche] Censor-resistant stores [Eternity, FreeNet,..] DB query and indexing [PIER, …] Event notification [Scribe] Naming systems [ChordDNS, Twine,..] Communication primitives [I3, …] Common thread: data is location-independent
![Recent DHT-based projects File sharing [CFS, OceanStore, PAST, Ivy, …] Web cache [Squirrel,..] Archival/Backup store [HiveNet, Mojo, Pastiche] Censor-resistant stores [Eternity, FreeNet,..] DB query and indexing [PIER, …] Event notification [Scribe] Naming systems [ChordDNS, Twine,..] Communication primitives [I3, …] Common thread: data is location-independent](http://images.slideplayer.com/16/4965506/slides/slide_8.jpg "Recent DHT-based projects File sharing [CFS, OceanStore, PAST, Ivy, …] Web cache [Squirrel,..] Archival/Backup store [HiveNet, Mojo, Pastiche] Censor-resistant stores [Eternity, FreeNet,..] DB query and indexing [PIER, …] Event notification [Scribe] Naming systems [ChordDNS, Twine,..] Communication primitives [I3, …] Common thread: data is location-independent")
9
Roadmap One application: CFS/DHash One structured overlay: Chord Alternatives: Other solutions Geometry and performance The interface Applications

10
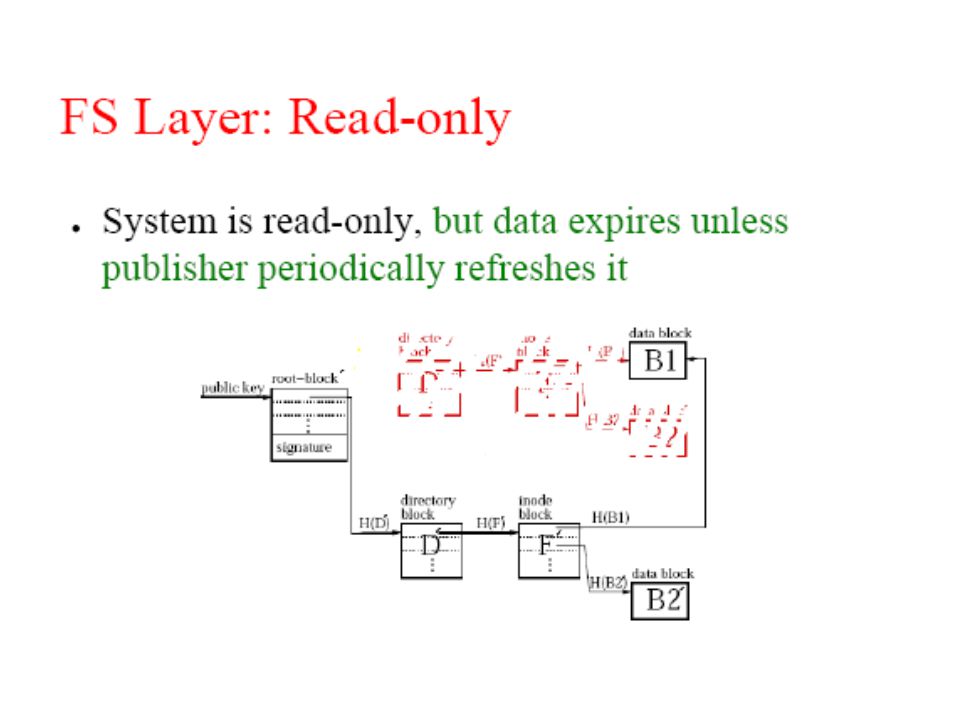
CFS: Cooperative file sharing DHT used as a robust block store Client of DHT implements file system Read-only: CFS, PAST Read-write: OceanStore, Ivy Distributed hash tables File system get (key) block node …. put (key, block)
.")
11
CFS Design

12
File representation: self-authenticating data Signed blocks: – Root blocks; Chord ID = H(publisher's public key) Unsigned blocks – Directory blocks, inode blocks, data blocks; – Chord ID = H(block contents) 995: key=901 key=732 Signature File System key=995 ………… “a.txt” ID=144 key=431 key=795 … … (root block) (directory blocks) (i-node block) (data) 901= SHA-1 144 = SHA-1 431=SHA-1
 Unsigned blocks – Directory blocks, inode blocks, data blocks; – Chord ID = H(block contents) 995: key=901 key=732 Signature File System key=995 ………… a.txt ID=144 key=431 key=795 … … (root block) (directory blocks) (i-node block) (data) 901= SHA = SHA-1 431=SHA-1")
13
DHT distributes blocks by hashing IDs Internet Node A Node C Node B Node D 995: key=901 key=732 Signature Block 732 Block 901 247: key=407 key=992 key=705 Signature Block 992 Block 407 Block 705 DHT replicates blocks for fault tolerance DHT caches popular blocks for load balance

17
DHT implementation challenges 1.Scalable lookup 2.Balance load (flash crowds) 3.Handling failures 4.Coping with systems in flux 5.Network-awareness for performance 6.Robustness with untrusted participants 7.Programming abstraction 8.Heterogeneity 9.Anonymity 10.Indexing Goal: simple, provably-good algorithms
 3.Handling failures 4.Coping with systems in flux 5.Network-awareness for performance 6.Robustness with untrusted participants 7.Programming abstraction 8.Heterogeneity 9.Anonymity 10.Indexing Goal: simple, provably-good algorithms")
18
1. The lookup problem Internet N1N1 N2N2 N3N3 N6N6 N5N5 N4N4 Publisher Put (Key=sha-1(data), Value=data…) Client Get(key=sha-1(data)) ? Get() is a lookup followed by check Put() is a lookup followed by a store
, Value=data…) Client Get(key=sha-1(data)) . Get() is a lookup followed by check Put() is a lookup followed by a store.")
19
Centralized lookup (Napster) Publisher@ Client Lookup(“title”) N6N6 N9N9 N7N7 DB N8N8 N3N3 N2N2 N1N1 SetLoc(“title”, N4) Simple, but O( N ) state and a single point of failure Key=“title” Value=file data… N4N4
 Client Lookup( title ) N6N6 N9N9 N7N7 DB N8N8 N3N3 N2N2 N1N1 SetLoc( title , N4) Simple, but O( N ) state and a single point of failure Key= title Value=file data… N4N4")
20
Flooded queries (Gnutella) N4N4 Publisher@ Client N6N6 N9N9 N7N7 N8N8 N3N3 N2N2 N1N1 Robust, but worst case O( N ) messages per lookup Key=“title” Value=MP3 data… Lookup(“title”)
 N4N4 Client N6N6 N9N9 N7N7 N8N8 N3N3 N2N2 N1N1 Robust, but worst case O( N ) messages per lookup Key= title Value=MP3 data… Lookup( title )")
21
Algorithms based on routing Map keys to nodes in a load-balanced way Hash keys and nodes into a string of digit Assign key to “closest” node Examples: CAN, Chord, Kademlia, Pastry, Tapestry, Viceroy, …. K20 K5 K80 Circular ID space N32 N90 N105 N60 Forward a lookup for a key to a closer node Join: insert node in ring

22
Chord’s routing table: fingers N80 ½ ¼ 1/8 1/16 1/32 1/64 1/128

23
Lookups take O( log(N) ) hops N32 N10 N5 N20 N110 N99 N80 N60 Lookup(K19) K19 Lookup: route to closest predecessor
 ) hops N32 N10 N5 N20 N110 N99 N80 N60 Lookup(K19) K19 Lookup: route to closest predecessor")
24
Can we do better? Caching Exploit flexibility at the geometry level Iterative vs. recursive lookups

25
2. Balance load N32 N10 N5 N20 N110 N99 N80 N60 Lookup(K19) K19 Hash function balances keys over nodes For popular keys, cache along the path K19
 K19 Hash function balances keys over nodes For popular keys, cache along the path K19.")
26
Why Caching Works Well N20 Only O(log N) nodes have fingers pointing to N20 This limits the single-block load on N20
 nodes have fingers pointing to N20 This limits the single-block load on N20")
27
3. Handling failures: redundancy N32 N10 N5 N20 N110 N99 N80 N60 Each node knows IP addresses of next r nodes Each key is replicated at next r nodes N40 K19

28
Lookups find replicas N40 N10 N5 N20 N110 N99 N80 N60 N50 Block 17 N68 1. 3. 2. 4. Lookup(BlockID=17) RPCs: 1. Lookup step 2. Get successor list 3. Failed block fetch 4. Block fetch
 RPCs: 1. Lookup step 2. Get successor list 3. Failed block fetch 4. Block fetch.")
29
First Live Successor Manages Replicas N40 N10 N5 N20 N110 N99 N80 N60 N50 Block 17 N68 Copy of 17 Node can locally determine that it is the first live successor

30
4. Systems in flux Lookup takes log(N) hops If system is stable But, system is never stable! What we desire are theorems of the type: 1.In the almost-ideal state, ….log(N)… 2.System maintains almost-ideal state as nodes join and fail
… 2.System maintains almost-ideal state as nodes join and fail.")
31
Half-life [Liben-Nowell 2002] Doubling time: time for N joins Halfing time: time for N/2 old nodes to fail Half life: MIN(doubling-time, halfing-time) N nodes N new nodes join N/2 old nodes leave
![Half-life [Liben-Nowell 2002] Doubling time: time for N joins Halfing time: time for N/2 old nodes to fail Half life: MIN(doubling-time, halfing-time) N nodes N new nodes join N/2 old nodes leave](http://images.slideplayer.com/16/4965506/slides/slide_31.jpg "Half-life [Liben-Nowell 2002] Doubling time: time for N joins Halfing time: time for N/2 old nodes to fail Half life: MIN(doubling-time, halfing-time) N nodes N new nodes join N/2 old nodes leave")
32
Applying half life For any node u in any P2P network: If u wishes to stay connected with high probability, then, on average, u must be notified about (log N) new nodes per half life And so on, …
 new nodes per half life And so on, …")
33
5. Optimize routing to reduce latency Nodes close on ring, but far away in Internet Goal: put nodes in routing table that result in few hops and low latency N20 N41 N80 N40

34
“close” metric impacts choice of nearby nodes Chord’s numerical close and (original) routing table restrict choice Should new nodes be able to choose their own ID Other allows for more choice (e.g., prefix based, XOR) N32N103 N105 N60 N06 USA Europe USA Far east USA K104
 routing table restrict choice Should new nodes be able to choose their own ID Other allows for more choice (e.g., prefix based, XOR) N32N103 N105 N60 N06 USA Europe USA Far east USA K104")
35
6. Malicious participants Attacker denies service Flood DHT with data Attacker returns incorrect data [detectable] Self-authenticating data Attacker denies data exists [liveness] Bad node is responsible, but says no Bad node supplies incorrect routing info Bad nodes make a bad ring, and good node joins it Basic approach: use redundancy

36
Sybil attack [Douceur 02] Attacker creates multiple identities Attacker controls enough nodes to foil the redundancy N32 N10 N5 N20 N110 N99 N80 N60 N40 Need a way to control creation of node IDs
![Sybil attack [Douceur 02] Attacker creates multiple identities Attacker controls enough nodes to foil the redundancy N32 N10 N5 N20 N110 N99 N80 N60 N40 Need a way to control creation of node IDs](http://images.slideplayer.com/16/4965506/slides/slide_36.jpg "Sybil attack [Douceur 02] Attacker creates multiple identities Attacker controls enough nodes to foil the redundancy N32 N10 N5 N20 N110 N99 N80 N60 N40 Need a way to control creation of node IDs")
37
One solution: secure node IDs Every node has a public key Certificate authority signs public key of good nodes Every node signs and verifies messages Quotas per publisher

38
Another solution: exploit practical byzantine protocols A core set of servers is pre-configured with keys and perform admission control [OceanStore] The servers achieve consensus with a practical byzantine recovery protocol [Castro and Liskov ’99 and ’00] The servers serialize updates [OceanStore] or assign secure node Ids [Configuration service] N32N103 N105 N60 N06 N N N N
![Another solution: exploit practical byzantine protocols A core set of servers is pre-configured with keys and perform admission control [OceanStore] The servers achieve consensus with a practical byzantine recovery protocol [Castro and Liskov ’99 and ’00] The servers serialize updates [OceanStore] or assign secure node Ids [Configuration service] N32N103 N105 N60 N06 N N N N](http://images.slideplayer.com/16/4965506/slides/slide_38.jpg "Another solution: exploit practical byzantine protocols A core set of servers is pre-configured with keys and perform admission control [OceanStore] The servers achieve consensus with a practical byzantine recovery protocol [Castro and Liskov ’99 and ’00] The servers serialize updates [OceanStore] or assign secure node Ids [Configuration service] N32N103 N105 N60 N06 N N N N")
39
A more decentralized solution: weak secure node IDs ID = SHA-1 (IP-address node) Assumption: attacker controls limited IP addresses Before using a node, challenge it to verify its ID
 Assumption: attacker controls limited IP addresses Before using a node, challenge it to verify its ID")
40
Using weak secure node IDS Detect malicious nodes Define verifiable system properties Each node has a successor Data is stored at its successor Allow querier to observe lookup progress Each hop should bring the query closer Cross check routing tables with random queries Recovery: assume limited number of bad nodes Quota per node ID

41
Summary http://project-iris.net

Similar presentations


 Partially based on Hellerstein’s presentation at VLDB2004.>")


 Distributed Storage 1Dennis Kafura – CS5204 – Operating Systems.>")






 UCL Computer Science CS M038 / GZ06 27 th January, 2009.>")



 to each node and key 2. Define a metric topology in this space, that is, the space of keys.>")
 provide some service that helps.>")


 Systems Gabi Kliot - Computer Science Department, Technion Concurrent and Distributed Computing Course 28/06/2006 The.>")
