Download presentation
Presentation is loading. Please wait.

1
Computer Architecture 2011 – Caches (lec 3-5) 1 Computer Architecture Cache Memory By Dan Tsafrir, 14/3/2011, 21/3/2011, 28/3/2011 Presentation based on slides by David Patterson, Avi Mendelson, Lihu Rappoport, and Adi Yoaz
 1 Computer Architecture Cache Memory By Dan Tsafrir, 14/3/2011, 21/3/2011, 28/3/2011 Presentation based on slides by David Patterson, Avi Mendelson, Lihu Rappoport, and Adi Yoaz")
2
Computer Architecture 2011 – Caches (lec 3-5) 2 In the olden days… u The predecessor of ENIAC (the first general-purpose electronic computer) u Designed & built in 1944-1949 by Eckert & Mauchly (who also invented ENIAC), with John Von Neumann u Unlike ENIAC, binary rather than decimal, and a “stored program” machine u Operational until 1961 EDVAC (Electronic Discrete Variable Automatic Computer)
 2 In the olden days… u The predecessor of ENIAC (the first general-purpose electronic computer) u Designed & built in by Eckert & Mauchly (who also invented ENIAC), with John Von Neumann u Unlike ENIAC, binary rather than decimal, and a stored program machine u Operational until 1961 EDVAC (Electronic Discrete Variable Automatic Computer)")
3
Computer Architecture 2011 – Caches (lec 3-5) 3 In the olden days… u In 1945, Von Neumann wrote: “…This result deserves to be noted. It shows in a most striking way where the real di ffi culty, the main bottleneck, of an automatic very high speed computing device lies: at the memory.” Von Neumann & EDVAC

4
Computer Architecture 2011 – Caches (lec 3-5) 4 In the olden days… u Later, in 1946, he wrote: “…Ideally one would desire an indefinitely large memory capacity such that any particular … word would be immediately available… …We are forced to recognize the possibility of constructing a hierarchy of memories, each of which has greater capacity than the preceding but which is less quickly accessible” Von Neumann & EDVAC
 4 In the olden days… u Later, in 1946, he wrote: …Ideally one would desire an indefinitely large memory capacity such that any particular … word would be immediately available… …We are forced to recognize the possibility of constructing a hierarchy of memories, each of which has greater capacity than the preceding but which is less quickly accessible Von Neumann & EDVAC")
5
Computer Architecture 2011 – Caches (lec 3-5) 5 Not so long ago… u In 1994, in their paper “Hitting the Memory Wall: Implications of the Obvious”, William Wulf and Sally McKee said: “We all know that the rate of improvement in microprocessor speed exceeds the rate of improvement in DRAM memory speed – each is improving exponentially, but the exponent for microprocessors is substantially larger than that for DRAMs. The difference between diverging exponentials also grows exponentially; so, although the disparity between processor and memory speed is already an issue, downstream someplace it will be a much bigger one.”

6
Computer Architecture 2011 – Caches (lec 3-5) 6 Not so long ago… DRAM 9% per yr 2X in 10 yrs CPU 60% per yr 2X in 1.5 yrs Gap grew 50% per year
 6 Not so long ago… DRAM 9% per yr 2X in 10 yrs CPU 60% per yr 2X in 1.5 yrs Gap grew 50% per year")
7
Computer Architecture 2011 – Caches (lec 3-5) 7 More recently (2008)… lower = slower Fast Slow The memory wall in the multicore era Performance (seconds) Processor cores Conventional architecture
 7 More recently (2008)… lower = slower Fast Slow The memory wall in the multicore era Performance (seconds) Processor cores Conventional architecture")
8
Computer Architecture 2011 – Caches (lec 3-5) 8 Memory Trade-Offs u Large (dense) memories are slow u Fast memories are small, expensive and consume high power u Goal: give the processor a feeling that it has a memory which is large (dense), fast, consumes low power, and cheap u Solution: a Hierarchy of memories Speed: Fastest Slowest Size: Smallest Biggest Cost: Highest Lowest Power: Highest Lowest L1 Cache CPU L2 Cache L3 Cache Memory (DRAM)
 8 Memory Trade-Offs u Large (dense) memories are slow u Fast memories are small, expensive and consume high power u Goal: give the processor a feeling that it has a memory which is large (dense), fast, consumes low power, and cheap u Solution: a Hierarchy of memories Speed: Fastest Slowest Size: Smallest Biggest Cost: Highest Lowest Power: Highest Lowest L1 Cache CPU L2 Cache L3 Cache Memory (DRAM)")
9
Computer Architecture 2011 – Caches (lec 3-5) 9 Typical levels in mem hierarchy Response timeSizeMemory level ≈ 0.5 ns≈ 100 bytesCPU registers ≈ 1 ns≈ 64 KBL1 cache ≈ 15 ns≈ 1 – 4 MBL2 cache ≈ 150 ns≈ 1 – 4 GBMain memory (DRAM) ≈ 15 ms≈ 1 – 2 TBHard disk (SATA)
 9 Typical levels in mem hierarchy Response timeSizeMemory level ≈ 0.5 ns≈ 100 bytesCPU registers ≈ 1 ns≈ 64 KBL1 cache ≈ 15 ns≈ 1 – 4 MBL2 cache ≈ 150 ns≈ 1 – 4 GBMain memory (DRAM) ≈ 15 ms≈ 1 – 2 TBHard disk (SATA)")
10
Computer Architecture 2011 – Caches (lec 3-5) 10 Why Hierarchy Works: Locality u Temporal Locality (Locality in Time): If an item is referenced, it will tend to be referenced again soon Example: code and variables in loops Keep recently accessed data closer to the processor u Spatial Locality (Locality in Space): If an item is referenced, nearby items tend to be referenced soon Example: scanning an array Move contiguous blocks closer to the processor u Due to locality, memory hierarchy is a good idea We’re going to use what we’ve just recently used And we’re going to use its immediate neighborhood
 10 Why Hierarchy Works: Locality u Temporal Locality (Locality in Time): If an item is referenced, it will tend to be referenced again soon Example: code and variables in loops Keep recently accessed data closer to the processor u Spatial Locality (Locality in Space): If an item is referenced, nearby items tend to be referenced soon Example: scanning an array Move contiguous blocks closer to the processor u Due to locality, memory hierarchy is a good idea We’re going to use what we’ve just recently used And we’re going to use its immediate neighborhood")
11
Computer Architecture 2011 – Caches (lec 3-5) 11 Programs with locality cache well... Time Memory Address (one dot per access) Spatial Locality Temporal Locality Donald J. Hatfield, Jeanette Gerald: Program Restructuring for Virtual Memory. IBM Systems Journal 10(3): 168-192 (1971) Bad locality behavior
 Spatial Locality Temporal Locality Donald J. Hatfield, Jeanette Gerald: Program Restructuring for Virtual Memory. IBM Systems Journal 10(3): (1971) Bad locality behavior.")
12
Computer Architecture 2011 – Caches (lec 3-5) 12 Memory Hierarchy: Terminology u For each memory level define the following Hit: data appears in the memory level Hit Rate: the fraction of accesses found in that level Hit Time: time to access the memory level includes also the time to determine hit/miss Miss: need to retrieve data from next level Miss Rate: 1 - (Hit Rate) Miss Penalty: Time to replace a block in the upper level + Time to deliver the block the processor u Average memory access time = t_effective = (Hit time Hit Rate) + (Miss Time Miss Rate) = (Hit time Hit Rate) + (Miss Time (1- Hit Rate)) If hit rate is close to 1, t_effective is close to Hit time
 12 Memory Hierarchy: Terminology u For each memory level define the following Hit: data appears in the memory level Hit Rate: the fraction of accesses found in that level Hit Time: time to access the memory level includes also the time to determine hit/miss Miss: need to retrieve data from next level Miss Rate: 1 - (Hit Rate) Miss Penalty: Time to replace a block in the upper level + Time to deliver the block the processor u Average memory access time = t_effective = (Hit time Hit Rate) + (Miss Time Miss Rate) = (Hit time Hit Rate) + (Miss Time (1- Hit Rate)) If hit rate is close to 1, t_effective is close to Hit time")
13
Computer Architecture 2011 – Caches (lec 3-5) 13 Effective Memory Access Time u Cache – holds a subset of the memory Hopefully – the subset being used now u Effective memory access time t effective = (t cache Hit Rate) + (t mem (1 – Hit rate)) t mem includes the time it takes to detect a cache miss u Example Assume: t cache = 10 ns, t mem = 100 nsec Hit Ratet eff (nsec) 0100 50 55 90 20 99 10.9 99.9 10.1 t mem /t cache goes up more important that hit-rate closer to 1
 13 Effective Memory Access Time u Cache – holds a subset of the memory Hopefully – the subset being used now u Effective memory access time t effective = (t cache Hit Rate) + (t mem (1 – Hit rate)) t mem includes the time it takes to detect a cache miss u Example Assume: t cache = 10 ns, t mem = 100 nsec Hit Ratet eff (nsec) t mem /t cache goes up more important that hit-rate closer to 1")
14
Computer Architecture 2011 – Caches (lec 3-5) 14 u The cache holds a small part of the entire memory Need to map parts of the memory into the cache u Main memory is (logically) partitioned into blocks Typical block size is 32 to 64 bytes Blocks are aligned u Cache partitioned to cache lines Each cache line holds a block Only a subset of the blocks is mapped to the cache at a given time The cache views an address as u Why use lines/blocks rather than words? Cache – Main Idea Block #offset memory cache 0 1 2 3 4 5 6. 90 91 92 93. 92 90 4 2

15
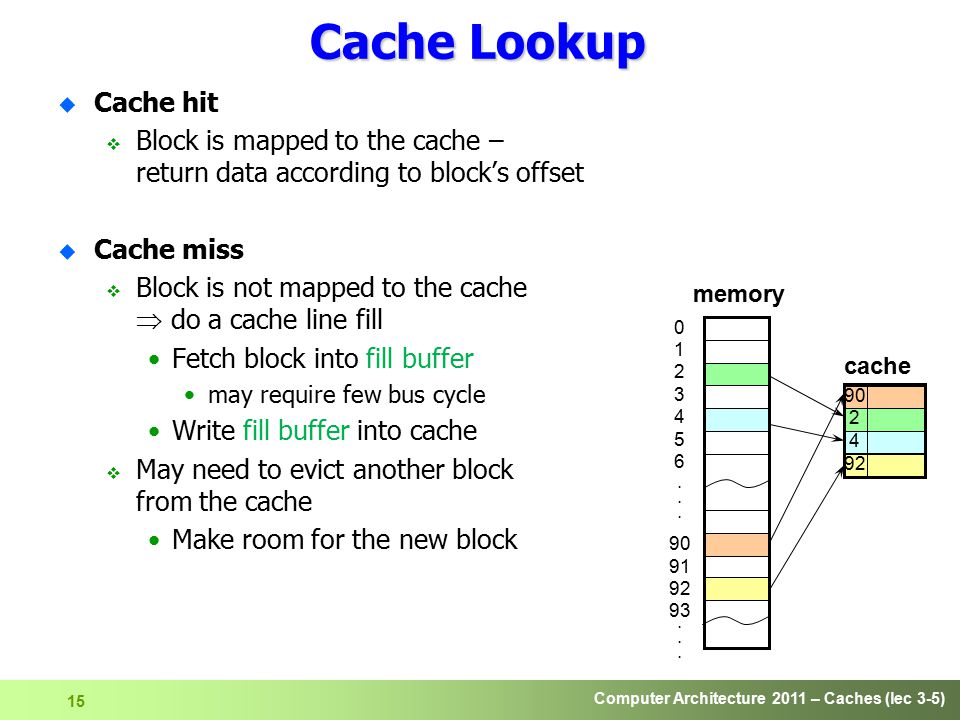
Computer Architecture 2011 – Caches (lec 3-5) 15 Cache Lookup u Cache hit Block is mapped to the cache – return data according to block’s offset u Cache miss Block is not mapped to the cache do a cache line fill Fetch block into fill buffer may require few bus cycle Write fill buffer into cache May need to evict another block from the cache Make room for the new block memory cache 0 1 2 3 4 5 6. 90 91 92 93. 92 90 4 2
16
Computer Architecture 2011 – Caches (lec 3-5) 16 Valid Bit u Initially cache is empty Need to have a “line valid” indication – line valid bit u A line may also be invalidated Line Tag Array Tag Tag = Block#Offset 04 31 Data array 031 = = = hitdata valid bit v
 16 Valid Bit u Initially cache is empty Need to have a line valid indication – line valid bit u A line may also be invalidated Line Tag Array Tag Tag = Block#Offset Data array 031 = = = hitdata valid bit v")
17
Computer Architecture 2011 – Caches (lec 3-5) 17 21-Mar-2011
 Mar-2011")
18
Computer Architecture 2011 – Caches (lec 3-5) 18 Cache organization u We will go over Direct cache map 2-way set associative cache N-way set associative cache Fully-associative cache
 18 Cache organization u We will go over Direct cache map 2-way set associative cache N-way set associative cache Fully-associative cache")
19
Computer Architecture 2011 – Caches (lec 3-5) 19 Direct Map Cache u Offset Byte within the cache-line u Set The index into the “cache array”, and to the “tag array” For a given set (an index), only one of the cache lines that has this set can reside in the cache u Tag The rest of the block bits are used as tag This is how we identify the individual cache line Namely, we compare to the tag of the address to the tag stored in the cache’s tag array Tag Array Tag Set# 0 31 TagSetOffset Address 041331 Line 5 Block number 2 9 =512 sets Data Array 14
 19 Direct Map Cache u Offset Byte within the cache-line u Set The index into the cache array , and to the tag array For a given set (an index), only one of the cache lines that has this set can reside in the cache u Tag The rest of the block bits are used as tag This is how we identify the individual cache line Namely, we compare to the tag of the address to the tag stored in the cache’s tag array Tag Array Tag Set# 0 31 TagSetOffset Address Line 5 Block number 2 9 =512 sets Data Array 14")
20
Computer Architecture 2011 – Caches (lec 3-5) 20 Direct Map Cache (cont) u Partition memory into slices slice size = cache size u Partition each slice to blocks Block size = cache line size Distance of block from slice start indicates position in cache (set) u Advantages Easy & fast hit/miss resolution Easy & fast replacement algorithm Lowest power u Disadvantage Line has only “one chance” Lines replaced due to “set conflict misses” Organization with highest miss-rate Cache Size........ x x x Mapped to set X Cache Size Cache Size

21
Computer Architecture 2011 – Caches (lec 3-5) 21 Line Size: 32 bytes 5 Offset bits Cache Size: 16KB = 2 14 Bytes #lines = cache size / line size = 2 14 /2 5 =2 9 =512 #sets = #lines = 512 #set bits = 9 bits (=5…13) #Tag bits = 32 – (#set bits + #offset bits) = 32 – (9+5) = 18 bits (=14…31) Lookup Address: 0x12345678 0001 0010 0011 0100 0101 0110 0111 1000 Direct Map Cache – Example offset= 0x18 set= 0x0B3 tag= 0x048B1 Tag SetOffset Address Fields 041331 Tag Array = Hit/Miss 514
 21 Line Size: 32 bytes 5 Offset bits Cache Size: 16KB = 2 14 Bytes #lines = cache size / line size = 2 14 /2 5 =2 9 =512 #sets = #lines = 512 #set bits = 9 bits (=5…13) #Tag bits = 32 – (#set bits + #offset bits) = 32 – (9+5) = 18 bits (=14…31) Lookup Address: 0x Direct Map Cache – Example offset= 0x18 set= 0x0B3 tag= 0x048B1 Tag SetOffset Address Fields Tag Array = Hit/Miss 514")
22
Computer Architecture 2011 – Caches (lec 3-5) 22 Direct map (tiny example) u Assume Memory size is 2^5 = 32 bytes For this, need 5-bit address A cache-line (block) is comprised of 4 bytes Thus, there are exactly 8 cache- lines u Note Need only 3-bits to identify a cache-line The offset is exclusively used within the cache lines The offset is not used do locate the cache line 00011011 000 001 010 011 100 101 110 111 Offset (within a block) Block index Address 11111 Address 01110 Address 00001
 22 Direct map (tiny example) u Assume Memory size is 2^5 = 32 bytes For this, need 5-bit address A cache-line (block) is comprised of 4 bytes Thus, there are exactly 8 cache- lines u Note Need only 3-bits to identify a cache-line The offset is exclusively used within the cache lines The offset is not used do locate the cache line Offset (within a block) Block index Address Address Address 00001")
23
Computer Architecture 2011 – Caches (lec 3-5) 23 Direct map (tiny example) u Further assume The size of our cache is 2 cache- lines u The address divides like so b4 b3| b2| b1 b0 tag| set| offset 00011011 000 001 010 011 100 101 110 111 Offset (within a block) Block index 00011011 0 1 b3b4 0 1 tag array (bits) cache array (bytes) memory array (bytes) even cache lines odd cache lines
 23 Direct map (tiny example) u Further assume The size of our cache is 2 cache- lines u The address divides like so b4 b3| b2| b1 b0 tag| set| offset Offset (within a block) Block index b3b4 0 1 tag array (bits) cache array (bytes) memory array (bytes) even cache lines odd cache lines")
24
Computer Architecture 2011 – Caches (lec 3-5) 24 Direct map (tiny example) u Accessing address 0 0 0 1 0 (=C) u The address divides like so b4 b3| b2| b1 b0 tag (00)| set (0)| offset (10) 00011011 ABCD000 001 010 011 100 101 110 111 Offset (within a block) Block index 00011011 ABCD0 1 b3b4 000 1 tag array (bits) cache array (bytes) memory array (bytes)
 24 Direct map (tiny example) u Accessing address (=C) u The address divides like so b4 b3| b2| b1 b0 tag (00)| set (0)| offset (10) ABCD Offset (within a block) Block index ABCD0 1 b3b tag array (bits) cache array (bytes) memory array (bytes)")
25
Computer Architecture 2011 – Caches (lec 3-5) 25 Direct map (tiny example) u Accessing address 0 1 0 1 0 (=Y) u The address divides like so b4 b3| b2| b1 b0 tag (01)| set (0)| offset (10) 00011011 000 001 WXYZ010 011 100 101 110 111 Offset (within a block) Block index 00011011 WXYZ0 1 b3b4 100 1 tag array (bits) cache array (bytes) memory array (bytes)
 25 Direct map (tiny example) u Accessing address (=Y) u The address divides like so b4 b3| b2| b1 b0 tag (01)| set (0)| offset (10) WXYZ Offset (within a block) Block index WXYZ0 1 b3b tag array (bits) cache array (bytes) memory array (bytes)")
26
Computer Architecture 2011 – Caches (lec 3-5) 26 Direct map (tiny example) u Accessing address 1 0 0 1 0 (=Q) u The address divides like so b4 b3| b2| b1 b0 tag (10)| set (0)| offset (10) 00011011 000 001 010 011 TRQP100 101 110 111 Offset (within a block) Block index 00011011 TRQP0 1 b3b4 010 1 tag array (bits) cache array (bytes) memory array (bytes)
 26 Direct map (tiny example) u Accessing address (=Q) u The address divides like so b4 b3| b2| b1 b0 tag (10)| set (0)| offset (10) TRQP Offset (within a block) Block index TRQP0 1 b3b tag array (bits) cache array (bytes) memory array (bytes)")
27
Computer Architecture 2011 – Caches (lec 3-5) 27 Direct map (tiny example) u Accessing address 1 1 0 1 0 (=J) u The address divides like so b4 b3| b2| b1 b0 tag (11)| set (0)| offset (10) 00011011 000 001 010 011 100 101 LKJI110 111 Offset (within a block) Block index 00011011 LKJI0 1 b3b4 110 1 tag array (bits) cache array (bytes) memory array (bytes)
 27 Direct map (tiny example) u Accessing address (=J) u The address divides like so b4 b3| b2| b1 b0 tag (11)| set (0)| offset (10) LKJI Offset (within a block) Block index LKJI0 1 b3b tag array (bits) cache array (bytes) memory array (bytes)")
28
Computer Architecture 2011 – Caches (lec 3-5) 28 Direct map (tiny example) u Accessing address 0 0 1 1 0 (=B) u The address divides like so b4 b3| b2| b1 b0 tag (00)| set (1)| offset (10) 00011011 000 DCBA001 010 011 100 101 110 111 Offset (within a block) Block index 00011011 0 DCBA1 b3b4 0 001 tag array (bits) cache array (bytes) memory array (bytes)
 28 Direct map (tiny example) u Accessing address (=B) u The address divides like so b4 b3| b2| b1 b0 tag (00)| set (1)| offset (10) DCBA Offset (within a block) Block index DCBA1 b3b tag array (bits) cache array (bytes) memory array (bytes)")
29
Computer Architecture 2011 – Caches (lec 3-5) 29 Direct map (tiny example) u Accessing address 0 1 1 1 0 (=Y) u The address divides like so b4 b3| b2| b1 b0 tag (01)| set (1)| offset (10) 00011011 000 001 010 WZYX011 100 101 110 111 Offset (within a block) Block index 00011011 0 WZYX1 b3b4 0 101 tag array (bits) cache array (bytes) memory array (bytes)
 29 Direct map (tiny example) u Accessing address (=Y) u The address divides like so b4 b3| b2| b1 b0 tag (01)| set (1)| offset (10) WZYX Offset (within a block) Block index WZYX1 b3b tag array (bits) cache array (bytes) memory array (bytes)")
30
Computer Architecture 2011 – Caches (lec 3-5) 30 Direct map (tiny example) u Now assume The size of our cache is 4 cache- lines u The address divides like so b4| b3 b2| b1 b0 tag| set| offset 00011011 000 001 010 011 DCBA100 101 110 111 Offset (within a block) Block index 00011011 DCBA00 01 10 11 b4 100 01 10 11 tag array (bits) cache array (bytes) memory array (bytes)
 30 Direct map (tiny example) u Now assume The size of our cache is 4 cache- lines u The address divides like so b4| b3 b2| b1 b0 tag| set| offset DCBA Offset (within a block) Block index DCBA b tag array (bits) cache array (bytes) memory array (bytes)")
31
Computer Architecture 2011 – Caches (lec 3-5) 31 Direct map (tiny example) u Now assume The size of our cache is 4 cache- lines u The address divides like so b4| b3 b2| b1 b0 tag| set| offset 00011011 WZYX000 001 010 011 100 101 110 111 Offset (within a block) Block index 00011011 WZYX00 01 10 11 b4 000 01 10 11 tag array (bits) cache array (bytes) memory array (bytes)
 31 Direct map (tiny example) u Now assume The size of our cache is 4 cache- lines u The address divides like so b4| b3 b2| b1 b0 tag| set| offset WZYX Offset (within a block) Block index WZYX b tag array (bits) cache array (bytes) memory array (bytes)")
32
Computer Architecture 2011 – Caches (lec 3-5) 32 2-Way Set Associative Cache u Each set holds two line (way 0 and way 1) Each block can be mapped into one of two lines in the appropriate set (HW check both ways in parallel) u Cache effectively partitioned into two Example: Line Size: 32 bytes Cache Size 16KB #of lines512 lines #sets256 Offset bits5 bits Set bits8 bits Tag bits19 bits Address 0 0001 0010 0011 01000101 0110 0111 1000 Offset: 1 1000 = 0x18 = 24 Set: 1011 0011 = 0x0B3 = 179 Tag: 000 1001 0001 1010 0010 = = 0x091A2 LineTag Line TagSetOffset Address Fields 041231 Cache storage Way 1 Tag Array Set# 031Way 0 Tag Array Set# 031Cache storage WAY #1WAY #0 513
 32 2-Way Set Associative Cache u Each set holds two line (way 0 and way 1) Each block can be mapped into one of two lines in the appropriate set (HW check both ways in parallel) u Cache effectively partitioned into two Example: Line Size: 32 bytes Cache Size 16KB #of lines512 lines #sets256 Offset bits5 bits Set bits8 bits Tag bits19 bits Address Offset: = 0x18 = 24 Set: = 0x0B3 = 179 Tag: = = 0x091A2 LineTag Line TagSetOffset Address Fields Cache storage Way 1 Tag Array Set# 031Way 0 Tag Array Set# 031Cache storage WAY #1WAY #0 513")
33
Computer Architecture 2011 – Caches (lec 3-5) 33 2-Way Cache – Hit Decision TagSetOffset 041231 Way 0 Tag Set# Data = Hit/Miss MUX Data Out Data Tag Way 1 = 513
 33 2-Way Cache – Hit Decision TagSetOffset Way 0 Tag Set# Data = Hit/Miss MUX Data Out Data Tag Way 1 = 513")
34
Computer Architecture 2011 – Caches (lec 3-5) 34 2-Way Set Associative Cache (cont) u Partition memory into “slices” or “ways” slice size = way size = ½ cache size u Partition each slice to blocks Block size = cache line size Distance of block from slice-start indicates position in cache (set) u Compared to direct map cache Half size slice 2× number of slices 2× number of blocks mapped to each set in the cache But in each set we can have 2 blocks at a given time More logic, warmer, more power consuming, but less collision/eviction Way Size........ x x x Mapped to set X Way Size Way Size

35
Computer Architecture 2011 – Caches (lec 3-5) 35 N-way set associative cache u Similarly to 2-way u At the extreme, every cache line is a way…
 35 N-way set associative cache u Similarly to 2-way u At the extreme, every cache line is a way…")
36
Computer Architecture 2011 – Caches (lec 3-5) 36 Fully Associative Cache u An address is partitioned to offset within block block number u Each block may be mapped to each of the cache lines Lookup block in all lines u Each cache line has a tag All tags are compared to the block# in parallel Need a comparator per line If one of the tags matches the block#, we have a hit Supply data according to offset u Best hit rate, but most wasteful Must be relatively small Tag Array Tag Tag = Block#Offset Address Fields 0431 Data array 031 Line = = = hitdata
 36 Fully Associative Cache u An address is partitioned to offset within block block number u Each block may be mapped to each of the cache lines Lookup block in all lines u Each cache line has a tag All tags are compared to the block# in parallel Need a comparator per line If one of the tags matches the block#, we have a hit Supply data according to offset u Best hit rate, but most wasteful Must be relatively small Tag Array Tag Tag = Block#Offset Address Fields 0431 Data array 031 Line = = = hitdata")
37
Computer Architecture 2011 – Caches (lec 3-5) 37 Cache organization summary u Increasing set associativity Improves hit rate Increases power consumption Increases access time u Strike a balance
 37 Cache organization summary u Increasing set associativity Improves hit rate Increases power consumption Increases access time u Strike a balance")
38
Computer Architecture 2011 – Caches (lec 3-5) 38 Cache Read Miss u On a read miss – perform a cache line fill Fetch entire block that contains the missing data from memory u Block is fetched into the cache line fill buffer May take a few bus cycles to complete the fetch e.g., 64 bit (8 byte) data bus, 32 byte cache line 4 bus cycles Can stream the critical chunk into the core before the line fill ends u Once the entire block fetched into the fill buffer It is moved into the cache
 38 Cache Read Miss u On a read miss – perform a cache line fill Fetch entire block that contains the missing data from memory u Block is fetched into the cache line fill buffer May take a few bus cycles to complete the fetch e.g., 64 bit (8 byte) data bus, 32 byte cache line 4 bus cycles Can stream the critical chunk into the core before the line fill ends u Once the entire block fetched into the fill buffer It is moved into the cache")
39
Computer Architecture 2011 – Caches (lec 3-5) 39 Cache Replacement u Direct map cache – easy A new block is mapped to a single line in the cache Old line is evicted (re-written to memory if needed) u N-way set associative cache – harder Choose a victim from all ways in the appropriate set But which? To determine, use a replacement algorithm u Replacement algorithms FIFO (First In First Out) Random LRU (Least Recently used) Optimum (theoretical, postmortem, called “Belady”) u Aside from the theoretical optimum, of the above, LRU is the best But not that much better than random
 Random LRU (Least Recently used) Optimum (theoretical, postmortem, called Belady ) u Aside from the theoretical optimum, of the above, LRU is the best But not that much better than random.")
40
Computer Architecture 2011 – Caches (lec 3-5) 40 LRU Implementation u 2 ways 1 bit per set to mark latest way accessed in set Evict way not pointed by bit u k-way set associative LRU Requires full ordering of way accesses Need a log 2 k bit counter per line When way i is accessed x = counter[i] counter[i] = k-1 for (j = 0 to k-1) if( (j i) && (counter[j]>x) ) counter[j]--; When replacement is needed evict way with counter = 0 Expensive even for small k-s Because invoked for every load/store Initial State Way 0 1 2 3 Count 0 1 2 3 Access way 2 Way 0 1 2 3 Count 0 1 3 2 Access way 0 Way 0 1 2 3 Count 3 0 2 1
![Computer Architecture 2011 – Caches (lec 3-5) 40 LRU Implementation u 2 ways 1 bit per set to mark latest way accessed in set Evict way not pointed by bit u k-way set associative LRU Requires full ordering of way accesses Need a log 2 k bit counter per line When way i is accessed x = counter[i] counter[i] = k-1 for (j = 0 to k-1) if( (j i) && (counter[j]>x) ) counter[j]--; When replacement is needed evict way with counter = 0 Expensive even for small k-s Because invoked for every load/store Initial State Way Count Access way 2 Way Count Access way 0 Way Count](http://images.slideplayer.com/16/4926455/slides/slide_40.jpg "Computer Architecture 2011 – Caches (lec 3-5) 40 LRU Implementation u 2 ways 1 bit per set to mark latest way accessed in set Evict way not pointed by bit u k-way set associative LRU Requires full ordering of way accesses Need a log 2 k bit counter per line When way i is accessed x = counter[i] counter[i] = k-1 for (j = 0 to k-1) if( (j i) && (counter[j]>x) ) counter[j]--; When replacement is needed evict way with counter = 0 Expensive even for small k-s Because invoked for every load/store Initial State Way Count Access way 2 Way Count Access way 0 Way Count")
41
Computer Architecture 2011 – Caches (lec 3-5) 41 Pseudo LRU (PLRU) u In practice, it’s sufficient to efficiently approximate LRU Maintain k-1 bits, instead of k ∙ log 2 k bits u Assume k=4, and let’s enumerate the way’s cache lines We need 2 bits: cache line 00, cl-01, cl-10, and cl-11 u Use a binary search tree to represent the 4 cache lines Set each of the 3 (=k-1) internal nodes to hold a bit variable: B 0, B 1, and B 2 u Whenever accessing a cache line b 1 b 0 Set the bit variable B j to be the corresponding cache line bit b k Can think about the bit value as B j “right side was referenced more recently” u Need to evict? Walk tree as follows: Go left if B j = 1; go right if B j = 0 Evict the leaf you’ve reached (= the opposite direction relative to previous insertions) 00 01 11 10 0 01 1 10 B0B0 B1B1 B2B2 cache lines
 B0B0 B1B1 B2B2 cache lines.")
42
Computer Architecture 2011 – Caches (lec 3-5) 42 Pseudo LRU (PLRU) – Example u Access 3 (11), 0 (00), 2 (10), 1 (01) => next victim is 3 (11), as expected 00 01 11 10 0 01 1 10 B0B0 B1B1 B2B2 00 01 11 10 0 01 1 10 0 1 0 cache lines 00 01 11 10 0 01 1 10 1 1 00 01 11 10 0 01 1 10 0 0 1 00 01 11 10 0 01 1 10 1 0 0 3 02 1 B1B1
 42 Pseudo LRU (PLRU) – Example u Access 3 (11), 0 (00), 2 (10), 1 (01) => next victim is 3 (11), as expected B0B0 B1B1 B2B cache lines B1B1")
43
Computer Architecture 2011 – Caches (lec 3-5) 43 LRU vs. Random vs. FIFO u LRU: hardest u FIFO: easier, approximates LRU (oldest rather the LRU) u Random: easiest u Results: Misses per 1000 instructions in L1 (data), on average Average across ten SPECint2000 / SPECfp2000 benchmarks Size2-way4-way8-way LRURandFIFOLRURandFIFOLRURandFIFO 16K114.1117.3115.5111.7115.1113.1109.0111.8110.4 64K103.4104.3103.9102.4102.3103.199.7100.5100.3 256K92.292.192.592.1 92.592.1 92.5
 u Random: easiest u Results: Misses per 1000 instructions in L1 (data), on average Average across ten SPECint2000 / SPECfp2000 benchmarks Size2-way4-way8-way LRURandFIFOLRURandFIFOLRURandFIFO 16K K K")
44
Computer Architecture 2011 – Caches (lec 3-5) 44 Effect of Cache on Performance u MPI (miss per instruction) Fraction of instructions (out of total) that experience a miss Memory accesses per instruction = fraction of instructions that access the memory MPI = Memory accesses per instruction × Miss rate u Memory stall cycles = Memory accesses × Miss rate × Miss penalty = IC × MPI × Miss penalty u CPU time = (CPU execution cycles + Memory stall cycles) × cycle time = IC × (CPI execution + MPI × Miss penalty) × cycle time
 44 Effect of Cache on Performance u MPI (miss per instruction) Fraction of instructions (out of total) that experience a miss Memory accesses per instruction = fraction of instructions that access the memory MPI = Memory accesses per instruction × Miss rate u Memory stall cycles = Memory accesses × Miss rate × Miss penalty = IC × MPI × Miss penalty u CPU time = (CPU execution cycles + Memory stall cycles) × cycle time = IC × (CPI execution + MPI × Miss penalty) × cycle time")
45
Computer Architecture 2011 – Caches (lec 3-5) 45 28-Mar-2011
 Mar-2011")
46
Computer Architecture 2011 – Caches (lec 3-5) 46 Memory Update Policy on Writes u Write back (lazy writes to DRAM; prefer cache) u Write through (immediately writing to DRAM)
 46 Memory Update Policy on Writes u Write back (lazy writes to DRAM; prefer cache) u Write through (immediately writing to DRAM)")
47
Computer Architecture 2011 – Caches (lec 3-5) 47 Write Back u Store operations that hit the cache Write only to cache; main memory not accessed u Line marked as “modified” or “dirty” When evicted, line written to memory only if dirty u Pros: Saves memory accesses when line updated more than once Attractive for multicore/multiprocessor u Cons: On eviction, the entire line must be written to memory (there’s no indication which bytes within the line were modified) Read miss might require writing to memory (evicted line is dirty) More susceptible to “soft errors” Transient errors; can be detectable but unrecoverable Especially problematic for supercomputers
 47 Write Back u Store operations that hit the cache Write only to cache; main memory not accessed u Line marked as modified or dirty When evicted, line written to memory only if dirty u Pros: Saves memory accesses when line updated more than once Attractive for multicore/multiprocessor u Cons: On eviction, the entire line must be written to memory (there’s no indication which bytes within the line were modified) Read miss might require writing to memory (evicted line is dirty) More susceptible to soft errors Transient errors; can be detectable but unrecoverable Especially problematic for supercomputers")
48
Computer Architecture 2011 – Caches (lec 3-5) 48 Write Through u Stores that hit the cache Write to cache, and Write to memory u Need to write only the bytes that were changed Not entire line Less work u When evicting, no need to write to DRAM Never dirty, so don’t need to be written Still need to throw stuff out, though u Use write buffers To mask waiting for lower level memory
 48 Write Through u Stores that hit the cache Write to cache, and Write to memory u Need to write only the bytes that were changed Not entire line Less work u When evicting, no need to write to DRAM Never dirty, so don’t need to be written Still need to throw stuff out, though u Use write buffers To mask waiting for lower level memory")
49
Computer Architecture 2011 – Caches (lec 3-5) 49 Write through: need write-buffer u A write buffer between cache & memory Processor core: writes data into cache & write buffer Memory controller: writes contents of buffer to memory u Works ok if store frequency << DRAM write cycle Otherwise store buffer overflows no matter how big it is u Write combining Combine adjacent writes to same location in write buffer u Note: on cache miss need to lookup write buffer (or drain it) Processor Cache Write Buffer DRAM
 49 Write through: need write-buffer u A write buffer between cache & memory Processor core: writes data into cache & write buffer Memory controller: writes contents of buffer to memory u Works ok if store frequency << DRAM write cycle Otherwise store buffer overflows no matter how big it is u Write combining Combine adjacent writes to same location in write buffer u Note: on cache miss need to lookup write buffer (or drain it) Processor Cache Write Buffer DRAM")
50
Computer Architecture 2011 – Caches (lec 3-5) 50 Cache Write Miss u The processor is not waiting for data continues to work u Option 1: Write allocate: fetch the line into the cache Goes with write back policy Assumes more writes/reads are needed Hopes that subsequent writes to the line hit the cache u Option 2: Write no allocate: do not fetch line into cache Goes with write through policy Subsequent writes would update memory anyhow
 50 Cache Write Miss u The processor is not waiting for data continues to work u Option 1: Write allocate: fetch the line into the cache Goes with write back policy Assumes more writes/reads are needed Hopes that subsequent writes to the line hit the cache u Option 2: Write no allocate: do not fetch line into cache Goes with write through policy Subsequent writes would update memory anyhow")
51
Computer Architecture 2011 – Caches (lec 3-5) 51 WT vs. WB – Summary Write-ThroughWrite-Back Policy Data written to cache block also written to lower- level memory Write data only to the cache Update lower level when a block falls out of the cache ComplexityLessMore Do read misses produce writes? NoYes Do repeated writes make it to lower level? YesNo Upon write miss Write no allocateWrite allocate

52
Computer Architecture 2011 – Caches (lec 3-5) 52 Write Buffers for WT – Summary Write Buffers for WT – Summary Q. Why a write buffer ? Processor Cache Write Buffer Lower Level Memory Holds data awaiting write-through to lower level memory A. So CPU doesn’t stall Q. Why a buffer, why not just one register ? A. Bursts of writes are common. Q. Are Read After Write (RAW) hazards an issue for write buffer? A. Yes! Drain buffer before next read, or send read 1 st after check write buffers.
 hazards an issue for write buffer. A. Yes. Drain buffer before next read, or send read 1 st after check write buffers..")
53
Computer Architecture 2011 – Caches (lec 3-5) 53 Optimizing the Hierarchy
 53 Optimizing the Hierarchy")
54
Computer Architecture 2011 – Caches (lec 3-5) 54 Cache Line Size u Larger line size takes advantage of spatial locality Too big blocks: may fetch unused data While possibly evicting useful date miss rate goes up u Larger line size means larger miss penalty Longer time to fill line (critical chunk first reduces the problem) Longer time to evict u avgAccessTime = missPenalty × missRate + hitTime × (1 – missRate)
 54 Cache Line Size u Larger line size takes advantage of spatial locality Too big blocks: may fetch unused data While possibly evicting useful date miss rate goes up u Larger line size means larger miss penalty Longer time to fill line (critical chunk first reduces the problem) Longer time to evict u avgAccessTime = missPenalty × missRate + hitTime × (1 – missRate)")
55
Computer Architecture 2011 – Caches (lec 3-5) 55 Classifying Misses: 3 Cs u Compulsory First access to a block which is not in the cache Block must be brought into cache Cache size does not matter Solution: prefetching u Capacity Cache cannot contain all blocks needed during program execution Blocks are evicted and later retrieved Solution: increase cache size, stream buffers u Conflict Occurs in set associative or direct mapped caches when too many blocks are mapped to the same set Solution: increase associativity, victim cache
 55 Classifying Misses: 3 Cs u Compulsory First access to a block which is not in the cache Block must be brought into cache Cache size does not matter Solution: prefetching u Capacity Cache cannot contain all blocks needed during program execution Blocks are evicted and later retrieved Solution: increase cache size, stream buffers u Conflict Occurs in set associative or direct mapped caches when too many blocks are mapped to the same set Solution: increase associativity, victim cache")
56
Computer Architecture 2011 – Caches (lec 3-5) 56 Conflict 3Cs in SPEC92 Compulsory Capacity Miss rate (fraction)
 56 Conflict 3Cs in SPEC92 Compulsory Capacity Miss rate (fraction)")
57
Computer Architecture 2011 – Caches (lec 3-5) 57 Multi-ported Cache u N-ported cache enables n accesses in parallel Parallelize cache access in different pipeline stages Parallelize cache access in a super-scalar processors u For n=2, about doubles the cache die size u One solution: “banked cache” Each line is divided to n banks Can fetch data from k n different banks in possibly different lines
 57 Multi-ported Cache u N-ported cache enables n accesses in parallel Parallelize cache access in different pipeline stages Parallelize cache access in a super-scalar processors u For n=2, about doubles the cache die size u One solution: banked cache Each line is divided to n banks Can fetch data from k n different banks in possibly different lines")
58
Computer Architecture 2011 – Caches (lec 3-5) 58 Separate Code / Data Caches u Parallelize data access and instruction fetch u Code cache is a read only cache No need to write back line into memory when evicted Simpler to manage u What about self modifying code ? Whenever executing a memory write snoop code cache Requires a dedicated snoop port: read tag array + match tag (Otherwise snoops would stall fetch) If the code cache contains the written address Invalidate the corresponding cache line Flush the pipeline – it may contain stale code
 If the code cache contains the written address Invalidate the corresponding cache line Flush the pipeline – it may contain stale code.")
59
Computer Architecture 2011 – Caches (lec 3-5) 59 L2 cache u L2 cache is bigger, but with higher latency Reduces L1 miss penalty – saves access to memory On modern processors L2 cache is located on-chip u Usually contains L1 All addresses in L1 are also contained in L2 Address evicted from L2 snoop invalidate it in L1 Data in L1 may be more updated than in L2 When evicting a modified line from L1 write to L2 When evicting a line from L2 which is modified in L1 Snoop invalidate to L1 generates a write from L1 to L2 Line marked as modified in L2 Line written to memory Since L2 contains L1 it needs to be significantly larger e.g., if L2 is only 2× L1, half of L2 is duplicated in L1 u L2 is unified (code / data)
 59 L2 cache u L2 cache is bigger, but with higher latency Reduces L1 miss penalty – saves access to memory On modern processors L2 cache is located on-chip u Usually contains L1 All addresses in L1 are also contained in L2 Address evicted from L2 snoop invalidate it in L1 Data in L1 may be more updated than in L2 When evicting a modified line from L1 write to L2 When evicting a line from L2 which is modified in L1 Snoop invalidate to L1 generates a write from L1 to L2 Line marked as modified in L2 Line written to memory Since L2 contains L1 it needs to be significantly larger e.g., if L2 is only 2× L1, half of L2 is duplicated in L1 u L2 is unified (code / data)")
60
Computer Architecture 2011 – Caches (lec 3-5) 60 Core 2 Duo Die Photo L2 Cache
 60 Core 2 Duo Die Photo L2 Cache")
61
Computer Architecture 2011 – Caches (lec 3-5) 61 AMD Phenom II Six Core
 61 AMD Phenom II Six Core")
62
Computer Architecture 2011 – Caches (lec 3-5) 62 Victim Cache u Per set load may be non-uniform Some sets may have more conflict misses than others Solution: allocate ways to sets dynamically u Victim cache gives a 2 nd chance to evicted lines A line evicted from L1 cache is placed in the victim cache If victim cache is full evict its LRU line On L1 cache lookup, in parallel, also search victim cache u On victim cache hit Line is moved back to cache Evicted line moved to the victim cache Same access time as cache hit u Especially effective for direct mapped cache Enables to combine the fast hit time of a direct mapped cache and still reduce conflict misses
 62 Victim Cache u Per set load may be non-uniform Some sets may have more conflict misses than others Solution: allocate ways to sets dynamically u Victim cache gives a 2 nd chance to evicted lines A line evicted from L1 cache is placed in the victim cache If victim cache is full evict its LRU line On L1 cache lookup, in parallel, also search victim cache u On victim cache hit Line is moved back to cache Evicted line moved to the victim cache Same access time as cache hit u Especially effective for direct mapped cache Enables to combine the fast hit time of a direct mapped cache and still reduce conflict misses")
63
Computer Architecture 2011 – Caches (lec 3-5) 63 Stream Buffers u Before inserting a new line into cache Put new line in a stream buffer u If the line is expected to be accessed again Move the line from the stream buffer into cache E.g., if the line hits in the stream buffer u Example: Scanning a very large array (much larger than the cache) Each item in the array is accessed just once If the array elements are inserted into the cache The entire cache will be thrashed If we detect that this is just a scan-once operation E.g., using a hint from the software Can avoid putting the array lines into the cache u Interestingly, probabilistic approaches can work quite well Insert block to cache with probability p (works because some blocks “buy” many, many more lottery tickets)
 63 Stream Buffers u Before inserting a new line into cache Put new line in a stream buffer u If the line is expected to be accessed again Move the line from the stream buffer into cache E.g., if the line hits in the stream buffer u Example: Scanning a very large array (much larger than the cache) Each item in the array is accessed just once If the array elements are inserted into the cache The entire cache will be thrashed If we detect that this is just a scan-once operation E.g., using a hint from the software Can avoid putting the array lines into the cache u Interestingly, probabilistic approaches can work quite well Insert block to cache with probability p (works because some blocks buy many, many more lottery tickets)")
64
Computer Architecture 2011 – Caches (lec 3-5) 64 Prefetching u Instruction Prefetching On a cache miss, prefetch sequential cache lines into stream buffers Branch predictor directed prefetching Let branch predictor run ahead u Data Prefetching - predict future data accesses Next sequential Stride General pattern u Software Prefetching Special prefetching instructions that cannot cause faults u Prefetching relies on extra memory bandwidth Otherwise it slows down demand fetches
 64 Prefetching u Instruction Prefetching On a cache miss, prefetch sequential cache lines into stream buffers Branch predictor directed prefetching Let branch predictor run ahead u Data Prefetching - predict future data accesses Next sequential Stride General pattern u Software Prefetching Special prefetching instructions that cannot cause faults u Prefetching relies on extra memory bandwidth Otherwise it slows down demand fetches")
65
Computer Architecture 2011 – Caches (lec 3-5) 65 Critical Word First u Reduce Miss Penalty u Don’t wait for full block to be loaded before restarting CPU Early restart As soon as the requested word of the block arrives, send it to the CPU and let the CPU continue execution Critical Word First Request the missed word first from memory and send it to the CPU as soon as it arrives Let the CPU continue execution while filling the rest of the words in the block Also called wrapped fetch and requested word first u Example: Pentium 8 byte bus, 32 byte cache line 4 bus cycles to fill line Fetch date from 95H 80H-87H88H-8FH90H-97H98H-9FH 1432
 65 Critical Word First u Reduce Miss Penalty u Don’t wait for full block to be loaded before restarting CPU Early restart As soon as the requested word of the block arrives, send it to the CPU and let the CPU continue execution Critical Word First Request the missed word first from memory and send it to the CPU as soon as it arrives Let the CPU continue execution while filling the rest of the words in the block Also called wrapped fetch and requested word first u Example: Pentium 8 byte bus, 32 byte cache line 4 bus cycles to fill line Fetch date from 95H 80H-87H88H-8FH90H-97H98H-9FH 1432")
66
Computer Architecture 2011 – Caches (lec 3-5) 66 Non-Blocking Cache u Hit Under Miss Allow cache hits while one miss is in progress Another miss has to wait Relevant for an out-of-order execution CPU u Miss Under Miss, Hit Under Multiple Misses Allow hits and misses when other misses in progress Memory system must allow multiple pending requests Manage a list of outstanding cache misses When miss is served and data gets back, update list
 66 Non-Blocking Cache u Hit Under Miss Allow cache hits while one miss is in progress Another miss has to wait Relevant for an out-of-order execution CPU u Miss Under Miss, Hit Under Multiple Misses Allow hits and misses when other misses in progress Memory system must allow multiple pending requests Manage a list of outstanding cache misses When miss is served and data gets back, update list")
67
Computer Architecture 2011 – Caches (lec 3-5) 67 Compiler Optimizations: Merging Arrays u Merge 2 arrays into a single array of compound elements /* BEFORE: two sequential arrays */ int val[SIZE]; int key[SIZE]; /* AFTER: One array of structures */ struct merge { int val; int key; } merged_array[SIZE]; Reduce conflicts between val and key u Improves spatial locality
![Computer Architecture 2011 – Caches (lec 3-5) 67 Compiler Optimizations: Merging Arrays u Merge 2 arrays into a single array of compound elements /* BEFORE: two sequential arrays */ int val[SIZE]; int key[SIZE]; /* AFTER: One array of structures */ struct merge { int val; int key; } merged_array[SIZE]; Reduce conflicts between val and key u Improves spatial locality](http://images.slideplayer.com/16/4926455/slides/slide_67.jpg "Computer Architecture 2011 – Caches (lec 3-5) 67 Compiler Optimizations: Merging Arrays u Merge 2 arrays into a single array of compound elements /* BEFORE: two sequential arrays */ int val[SIZE]; int key[SIZE]; /* AFTER: One array of structures */ struct merge { int val; int key; } merged_array[SIZE]; Reduce conflicts between val and key u Improves spatial locality")
68
Computer Architecture 2011 – Caches (lec 3-5) 68 Compiler Optimizations: Loop Fusion u Combine 2 independent loops that have same looping and some variables overlap Assume each element in a is 4 bytes, 32KB cache, 32 B / line for (i = 0; i < 10000; i++) a[i] = 1 / a[i]; for (i = 0; i < 10000; i++) sum = sum + a[i]; First loop: hit 7/8 of iterations Second loop: array > cache same hit rate as in 1 st loop u Fuse the loops for (i = 0; i < 10000; i++) { a[i] = 1 / a[i]; sum = sum + a[i]; } First line: hit 7/8 of iterations Second line: hit all
![Computer Architecture 2011 – Caches (lec 3-5) 68 Compiler Optimizations: Loop Fusion u Combine 2 independent loops that have same looping and some variables overlap Assume each element in a is 4 bytes, 32KB cache, 32 B / line for (i = 0; i < 10000; i++) a[i] = 1 / a[i]; for (i = 0; i < 10000; i++) sum = sum + a[i]; First loop: hit 7/8 of iterations Second loop: array > cache same hit rate as in 1 st loop u Fuse the loops for (i = 0; i < 10000; i++) { a[i] = 1 / a[i]; sum = sum + a[i]; } First line: hit 7/8 of iterations Second line: hit all](http://images.slideplayer.com/16/4926455/slides/slide_68.jpg "Computer Architecture 2011 – Caches (lec 3-5) 68 Compiler Optimizations: Loop Fusion u Combine 2 independent loops that have same looping and some variables overlap Assume each element in a is 4 bytes, 32KB cache, 32 B / line for (i = 0; i < 10000; i++) a[i] = 1 / a[i]; for (i = 0; i < 10000; i++) sum = sum + a[i]; First loop: hit 7/8 of iterations Second loop: array > cache same hit rate as in 1 st loop u Fuse the loops for (i = 0; i < 10000; i++) { a[i] = 1 / a[i]; sum = sum + a[i]; } First line: hit 7/8 of iterations Second line: hit all")
69
Computer Architecture 2011 – Caches (lec 3-5) 69 Compiler Optimizations: Loop Interchange u Change loops nesting to access data in order stored in memory u Two dimensional array in memory: x[0][0] x[0][1] … x[0][99] x[1][0] x[1][1] … /* Before */ for (j = 0; j < 100; j++) for (i = 0; i < 5000; i++) x[i][j] = 2 * x[i][j]; /* After */ for (i = 0; i < 5000; i++) for (j = 0; j < 100; j++) x[i][j] = 2 * x[i][j]; u Sequential accesses instead of striding through memory every 100 words Improved spatial locality
![Computer Architecture 2011 – Caches (lec 3-5) 69 Compiler Optimizations: Loop Interchange u Change loops nesting to access data in order stored in memory u Two dimensional array in memory: x[0][0] x[0][1] … x[0][99] x[1][0] x[1][1] … /* Before */ for (j = 0; j < 100; j++) for (i = 0; i < 5000; i++) x[i][j] = 2 * x[i][j]; /* After */ for (i = 0; i < 5000; i++) for (j = 0; j < 100; j++) x[i][j] = 2 * x[i][j]; u Sequential accesses instead of striding through memory every 100 words Improved spatial locality](http://images.slideplayer.com/16/4926455/slides/slide_69.jpg "Computer Architecture 2011 – Caches (lec 3-5) 69 Compiler Optimizations: Loop Interchange u Change loops nesting to access data in order stored in memory u Two dimensional array in memory: x[0][0] x[0][1] … x[0][99] x[1][0] x[1][1] … /* Before */ for (j = 0; j < 100; j++) for (i = 0; i < 5000; i++) x[i][j] = 2 * x[i][j]; /* After */ for (i = 0; i < 5000; i++) for (j = 0; j < 100; j++) x[i][j] = 2 * x[i][j]; u Sequential accesses instead of striding through memory every 100 words Improved spatial locality")
70
Computer Architecture 2011 – Caches (lec 3-5) 70 Case Study u Direct map used mostly for embedded due to poor performance u Can we make direct-map outperform alternatives? Etsion & Feitelson, "L1 Cache Filtering Through Random Selection of Memory References“, in International Conference on Parallel Architectures & Compilation Techniques (PACT), 2007 http://www.cs.huji.ac.il/~etsman/papers/CorePact.pdf http://www.cs.huji.ac.il/~etsman/papers/CorePact.pdf u Understand Figures 1, 2, 3, 8, 9
, u Understand Figures 1, 2, 3, 8, 9.")
71
Computer Architecture 2011 – Caches (lec 3-5) 71 Improving Cache Performance u Reduce cache miss rate Larger cache Reduce compulsory misses Larger Block Size HW Prefetching (Instr, Data) SW Prefetching (Data) Reduce conflict misses Higher Associativity Victim Cache Stream buffers Reduce cache thrashing Compiler Optimizations u Reduce the miss penalty Early Restart and Critical Word First on miss Non-blocking Caches (Hit under Miss, Miss under Miss) 2nd/3rd Level Cache u Reduce cache hit time On-chip caches Smaller size cache (hit time increases with cache size) Direct map cache (hit time increases with associativity)
 71 Improving Cache Performance u Reduce cache miss rate Larger cache Reduce compulsory misses Larger Block Size HW Prefetching (Instr, Data) SW Prefetching (Data) Reduce conflict misses Higher Associativity Victim Cache Stream buffers Reduce cache thrashing Compiler Optimizations u Reduce the miss penalty Early Restart and Critical Word First on miss Non-blocking Caches (Hit under Miss, Miss under Miss) 2nd/3rd Level Cache u Reduce cache hit time On-chip caches Smaller size cache (hit time increases with cache size) Direct map cache (hit time increases with associativity)")
72
Computer Architecture 2011 – Caches (lec 3-5) 72 Memory Coherency
 72 Memory Coherency")
73
Computer Architecture 2011 – Caches (lec 3-5) 73 Multiprocessor system u When there’s only one core Caching doesn’t affect correctness u But what happens when ≥ 2 cores work simultaneously on same memory location? If both are reading, not a problem Otherwise, one might use a stale, out-of-date copy of the data The inconsistencies might lead to incorrect execution u Solution Need coherency protocol Exact meaning determined by the “consistency model” (sometimes also called the “memory model”) Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory
 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory.")
74
Computer Architecture 2011 – Caches (lec 3-5) 74 Consistency model u From most strict to most relaxed Strict consistency Sequential consistency Weak consistency Release consistency […many more…] u Stricter models are More complex Harder to implement Slower Involves more communication Wastes more energy
![Computer Architecture 2011 – Caches (lec 3-5) 74 Consistency model u From most strict to most relaxed Strict consistency Sequential consistency Weak consistency Release consistency […many more…] u Stricter models are More complex Harder to implement Slower Involves more communication Wastes more energy](http://images.slideplayer.com/16/4926455/slides/slide_74.jpg "Computer Architecture 2011 – Caches (lec 3-5) 74 Consistency model u From most strict to most relaxed Strict consistency Sequential consistency Weak consistency Release consistency […many more…] u Stricter models are More complex Harder to implement Slower Involves more communication Wastes more energy")
75
Computer Architecture 2011 – Caches (lec 3-5) 75 Consistency model u Strict consistency (“linearizability”) All memory operations are ordered in time Any read to location X returns the most recent write op to X This is the intuitive notion of memory consistency
 75 Consistency model u Strict consistency ( linearizability ) All memory operations are ordered in time Any read to location X returns the most recent write op to X This is the intuitive notion of memory consistency")
76
Computer Architecture 2011 – Caches (lec 3-5) 76 Consistency model u Sequential consistency Relaxation of strict (defined by Lamport) Writes to X seen by all cores as occurring in some consistent order This order can be different than what “really” happened Left is sequentially consistent (can be ordered as in the right) What if we flip the order of P2’s reads (on left)? W(x)1P1: R(x)2R(x)1P2: R(x)2R(x)1P3: W(x)2P4: W(x)1P1: R(x)2R(x)1P2: R(x)2R(x)1P3: W(x)2P4:
1P1: R(x)2R(x)1P2: R(x)2R(x)1P3: W(x)2P4: W(x)1P1: R(x)2R(x)1P2: R(x)2R(x)1P3: W(x)2P4:.")
77
Computer Architecture 2011 – Caches (lec 3-5) 77 Consistency model u Weak consistency Access to “synchronization variables” are sequentially consistent No access to a synchronization variable is allowed to be performed until all previous writes have completed everywhere. No data access (read or write) is allowed to be performed until all previous accesses to synchronization variables have been performed. In other words, the processor doesn’t need to broadcast values at all, until a synchronization access happens But then it broadcasts all values to all cores Serves as a “barrier” SW(x)2W(x)1P1: R(x)2S R(x)0P2: R(x)2SR(x)1P3:
 is allowed to be performed until all previous accesses to synchronization variables have been performed. In other words, the processor doesn’t need to broadcast values at all, until a synchronization access happens But then it broadcasts all values to all cores Serves as a barrier SW(x)2W(x)1P1: R(x)2S R(x)0P2: R(x)2SR(x)1P3:.")
78
Computer Architecture 2011 – Caches (lec 3-5) 78 Consistency model u Release consistency Before accessing shared variable Acquire op must be completed Before a release allowed All accesses must be completed Acquire/release calls are sequentially consistent Serves as “lock”
 78 Consistency model u Release consistency Before accessing shared variable Acquire op must be completed Before a release allowed All accesses must be completed Acquire/release calls are sequentially consistent Serves as lock")
79
Computer Architecture 2011 – Caches (lec 3-5) 79 MESI Protocol u Each cache line can be on one of 4 states Invalid – Line data is not valid (as in simple cache) Shared – Line is valid and not dirty, copies may exist in other caches Exclusive – Line is valid and not dirty, other processors do not have the line in their local caches Modified – Line is valid and dirty, other processors do not have the line in their local caches u (MESI = Modified, Exclusive, Shared, Invalid)
 79 MESI Protocol u Each cache line can be on one of 4 states Invalid – Line data is not valid (as in simple cache) Shared – Line is valid and not dirty, copies may exist in other caches Exclusive – Line is valid and not dirty, other processors do not have the line in their local caches Modified – Line is valid and dirty, other processors do not have the line in their local caches u (MESI = Modified, Exclusive, Shared, Invalid)")
80
Computer Architecture 2011 – Caches (lec 3-5) 80 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory [1000]: 5 miss Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 [1000]: 5 [1000] miss [1000]: 5 [1000]: 6 EM 00 10
![Computer Architecture 2011 – Caches (lec 3-5) 80 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory [1000]: 5 miss Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 [1000]: 5 [1000] miss [1000]: 5 [1000]: 6 EM 00 10](http://images.slideplayer.com/16/4926455/slides/slide_80.jpg "Computer Architecture 2011 – Caches (lec 3-5) 80 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory [1000]: 5 miss Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 [1000]: 5 [1000] miss [1000]: 5 [1000]: 6 EM 00 10")
81
Computer Architecture 2011 – Caches (lec 3-5) 81 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory MS [1000]: 5 Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 u P2 reads 1000 u L2 snoops 1000 u P1 writes back 1000 u P2 gets 1000 [1000]: 5 [1000]: 6 [1000] miss [1000]: 6 S 10 11
![Computer Architecture 2011 – Caches (lec 3-5) 81 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory MS [1000]: 5 Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 u P2 reads 1000 u L2 snoops 1000 u P1 writes back 1000 u P2 gets 1000 [1000]: 5 [1000]: 6 [1000] miss [1000]: 6 S 10 11](http://images.slideplayer.com/16/4926455/slides/slide_81.jpg "Computer Architecture 2011 – Caches (lec 3-5) 81 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory MS [1000]: 5 Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 u P2 reads 1000 u L2 snoops 1000 u P1 writes back 1000 u P2 gets 1000 [1000]: 5 [1000]: 6 [1000] miss [1000]: 6 S 10 11")
82
Computer Architecture 2011 – Caches (lec 3-5) 82 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory MS [1000]: 5 Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 u P2 reads 1000 u L2 snoops 1000 u P1 writes back 1000 u P2 gets 1000 [1000]: 6 S 10 11 u P2 requests for ownership with write intent [1000] I 01 [1000] E
![Computer Architecture 2011 – Caches (lec 3-5) 82 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory MS [1000]: 5 Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 u P2 reads 1000 u L2 snoops 1000 u P1 writes back 1000 u P2 gets 1000 [1000]: 6 S u P2 requests for ownership with write intent [1000] I 01 [1000] E](http://images.slideplayer.com/16/4926455/slides/slide_82.jpg "Computer Architecture 2011 – Caches (lec 3-5) 82 Processor 1 L1 cache Processor 2 L1 cache L2 cache (shared) Memory MS [1000]: 5 Multi-processor System: Example u P1 reads 1000 u P1 writes 1000 u P2 reads 1000 u L2 snoops 1000 u P1 writes back 1000 u P2 gets 1000 [1000]: 6 S u P2 requests for ownership with write intent [1000] I 01 [1000] E")
Similar presentations









 1 Computer Architecture Memory Coherency & Consistency By Dan Tsafrir, 11/4/2011 Presentation.>")

 (Caches, Main Memory and.>")



www.cse.psu.edu/~mji www.cse.psu.edu/~cg431.>")

>")

>")