Download presentation
Presentation is loading. Please wait.

1
Examples of One-Dimensional Systolic Arrays

2
Motivation & Introduction
We need a high-performance , special-purpose computer system to meet specific application. I/O and computation imbalance is a notable problem. The concept of Systolic architecture can map high-level computation into hardware structures. Systolic system works like an automobile assembly line. Systolic system is easy to implement because of its regularity and easy to reconfigure. Systolic architecture can result in cost-effective , high- performance special-purpose systems for a wide range of problems.

3
Pipelined Computations
Pipelined program divided into a series of tasks that have to be completed one after the other. Each task executed by a separate pipeline stage Data streamed from stage to stage to form computation Common Parallel Programming Paradigms Embarrassingly parallel programs Workqueue Master/Slave programs Monte Carlo methods Regular, Iterative (Stencil) Computations Pipelined Computations Synchronous Computations P1 P2 P3 P4 P5 f, e, d, c, b, a
 Computations. Pipelined Computations. Synchronous Computations. P1. P2. P3. P4. P5. f, e, d, c, b, a.")
4
Pipelined Computations
Computation consists of data streaming through pipeline stages Execution Time = Time to fill pipeline (P-1) Time to run in steady state (N-P+1) + Time to empty pipeline (P-1) P = # of processors N = # of data items (assume P < N) P1 P2 P3 P4 P5 f, e, d, c, b, a a b f e d c time P5 P4 P3 P2 P1 This slide must be explained in all detail. It is very important
 + Time to run in steady state (N-P+1) + Time to empty pipeline (P-1) P = # of processors. N = # of data items. (assume P < N) P1. P2. P3. P4. P5. f, e, d, c, b, a. a. b. f. e. d. c. time. P5. P4. P3. P2. P1. This slide must be explained in all detail. It is very important.")
5
Pipelined Example: Sieve of Eratosthenes
Goal is to take a list of integers greater than 1 and produce a list of primes E.g. For input , output is A pipelined approach: Processor P_i divides each input by the i-th prime If the input is divisible (and not equal to the divisor), it is marked (with a negative sign) and forwarded If the input is not divisible, it is forwarded Last processor only forwards unmarked (positive) data [primes]
, it is marked (with a negative sign) and forwarded. If the input is not divisible, it is forwarded. Last processor only forwards unmarked (positive) data [primes]")
6
Sieve of Eratosthenes Pseudo-Code
Code for last processor x=recv(data,P_(i-1)) If x>0 then send(x,OUTPUT) Code for processor Pi (and prime p_i): x=recv(data,P_(i-1)) If (x>0) then If (p_i divides x and p_i = x ) then send(-x,P_(i+1) If (p_i does not divide x or p_i = x) then send(x, P_(i+1)) Else Send(x,P_(i+1)) / Processor P_i divides each input by the i-th prime P2 P3 P5 P7 out
) If x>0 then send(x,OUTPUT) Code for processor Pi (and prime p_i): x=recv(data,P_(i-1)) If (x>0) then. If (p_i divides x and p_i = x ) then send(-x,P_(i+1) If (p_i does not divide x or p_i = x) then send(x, P_(i+1)) Else. Send(x,P_(i+1)) / Processor P_i divides each input by the i-th prime. P2. P3. P5. P7. out.")
7
processor does the job of three primes
Programming Issues Algorithm will take N+P-1 to run where N is the number of data items and P is the number of processors. Can also consider just the odd bnys or do some initial part separately In given implementation, number of processors must store all primes which will appear in sequence Not a scalable approach Can fix this by having each processor do the job of multiple primes, i.e. mapping logical “processors” in the pipeline to each physical processor What is the impact of this on performance? P2 P3 P5 P7 P11 P13 P17 processor does the job of three primes

8
Processors for such operation
In pipelined algorithm, flow of data moves through processors in lockstep. The design attempts to balance the work so that there is no bottleneck at any processor In mid-80’s, processors were developed to support in hardware this kind of parallel pipelined computation Two commercial products from Intel: Warp (1D array) iWarp (components for 2D array) Warp and iWarp were meant to operate synchronously Wavefront Array Processor (S.Y. Kung) was meant to operate asynchronously, i.e. arrival of data would signal that it was time to execute
 iWarp (components for 2D array) Warp and iWarp were meant to operate synchronously Wavefront Array Processor (S.Y. Kung) was meant to operate asynchronously, i.e. arrival of data would signal that it was time to execute.")
9
Systolic Arrays from Intel
Warp and iWarp were examples of systolic arrays Systolic means regular and rhythmic, data was supposed to move through pipelined computational units in a regular and rhythmic fashion Systolic arrays meant to be special-purpose processors or co- processors. They were very fine-grained Processors implement a limited and very simple computation, usually called cells Communication is very fast, granularity meant to be around one operation/communication!

10
Systolic Algorithms Systolic arrays were built to support systolic algorithms, a hot area of research in the early 80’s Systolic algorithms used pipelining through various kinds of arrays to accomplish computational goals: Some of the data streaming and applications were very creative and quite complex CMU a hotbed of systolic algorithm and array research (especially H.T. Kung and his group)
")
11
Example 1: “pipelined” polynomial evaluation
Polynomial Evaluation is done by using a Linear array with 2D. Expression: Y = ((((anx+an-1)*x+an-2)*x+an-3)*x……a1)*x + a0 Function of PEs in pairs 1. Multiply input by x 2. Pass result to right. 3. Add aj to result from left. 4. Pass result to right.
*x+an-2)*x+an-3)*x……a1)*x + a0. Function of PEs in pairs. 1. Multiply input by x. 2. Pass result to right. 3. Add aj to result from left. 4. Pass result to right.")
12
Example 1: polynomial evaluation
Y = ((((anx+an-1)*x+an-2)*x+an-3)*x……a1)*x + a0 Multiplying processor X is broadcasted Adding processor Using systolic array for polynomial evaluation. This pipelined array can produce a polynomial on new X value on every cycle - after 2n stages. Another variant: you can also calculate various polynomials on the same X. This is an example of a deeply pipelined computation- The pipeline has 2n stages. x an-1 an-2 an x x a0 x ………. X + X + X + X +
*x+an-2)*x+an-3)*x……a1)*x + a0. Multiplying processor. X is broadcasted. Adding processor. Using systolic array for polynomial evaluation. This pipelined array can produce a polynomial on new X value on every cycle - after 2n stages. Another variant: you can also calculate various polynomials on the same X. This is an example of a deeply pipelined computation- The pipeline has 2n stages. x. an-1. an-2. an. x. x. a0. x. ………. X. + X. + X. + X. +")
13
Example 2: Matrix Vector Multiplication
There are many ways to solve a matrix problems using systolic arrays, some of the methods are: Triangular Array performing gaussian elimination with neighbor pivoting. Triangular Array performing orthogonal triangularization. Simple matrix multiplication methods are shown in next slides.

14
Example 2: Matrix Vector Multiplication
Each cell’s function is: 1. To multiply the top and bottom inputs. 2. Add the left input to the product just obtained. 3. Output the final result to the right. Each cell consists of an adder and a few registers. At time t0 the array receives 1, a, p, q, and r ( The other inputs are all zero). At time t1, the array receive m, d, b, p, q, and r ….e.t.c The results emerge after 5 steps.
. At time t1, the array receive m, d, b, p, q, and r ….e.t.c. The results emerge after 5 steps.")
15
Matrix Multiplication
Example 2: Matrix Vector Multiplication PE1 PE2 PE3 n m l a - d b g e c h f i z y x p q r At time t0 the array receives 1, a, p, q, and r ( The other inputs are all zero). At time t1, the array receive m, d, b, p, q, and r ….e.t.c The results emerge after 5 steps.
. At time t1, the array receive m, d, b, p, q, and r ….e.t.c. The results emerge after 5 steps.")
16
To visualize how it works it is good to do a snapshot animation
Each cell (P1, P2, P3) does just one instruction Multiply the top and bottom inputs, add the left input to the product just obtained, output the final result to the right The cells are simple Just an adder and a few registers The cleverness comes in the order in which you feed input into the systolic array At time t0, the array receives l, a, p, q, and r (the other inputs are all zero) At time t1, the array receives m, d, b, p, q, and r And so on. Results emerge after 5 steps PE1 PE2 PE3 n m l a - d b g e c h f i z y x p q r To visualize how it works it is good to do a snapshot animation
 does just one instruction. Multiply the top and bottom inputs, add the left input to the product just obtained, output the final result to the right. The cells are simple. Just an adder and a few registers. The cleverness comes in the order in which you feed input into the systolic array. At time t0, the array receives l, a, p, q, and r. (the other inputs are all zero) At time t1, the array receives m, d, b, p, q, and r. And so on. Results emerge after 5 steps. PE1. PE2. PE3. n m l. a. - d b - g e c. - h f. - - i. z y x. p. q. r. To visualize how it works it is good to do a snapshot animation.")
17
These slides are for one-dimensional only
Systolic Processors, versus Cellular Automata versus Regular Networks of Automata Data Path Block Data Path Block Data Path Block Data Path Block Systolic processor Control Block Control Block Control Block Control Block These slides are for one-dimensional only Cellular Automaton

18
Symmetric Function Evaluator
Systolic Processors, versus Cellular Automata versus Regular Networks of Automata Control Block Cellular Automaton General and Soldiers, Symmetric Function Evaluator Control Block Control Block Control Block Control Block Data Path Block Data Path Block Data Path Block Data Path Block Regular Network of Automata

19
Introduction to Convolution circuits synthesis
Perkowski

20
FIR-filter like structure
a4 b2 b1 b4 b3 + + + a4*b4

21
a3 a4 b2 b1 b4 b3 + + + a4*b4 a3*b4+a4b3

22
a2 a3 a4 b2 b1 b4 b3 + + + a4*b4 a3*b4+a4b3 a4*b2+a3*b3+a2*b4

23
+ + + a1 a2 a3 a4 b2 b1 b4 b3 a4*b4 a3*b4+a4b3 a4*b2+a3*b3+a2*b4

24
+ + + a1 a2 a3 b2 b1 b4 b3 a1*b3+a2*b2+a3*b1 a4*b4 a3*b4+a4b3
a1 a2 a3 b2 b1 b4 b3 + + + a4*b4 a3*b4+a4b3 a4*b2+a3*b3+a2*b4 a1*b4+a2*b3+a3*b2+a4*b1 a1*b3+a2*b2+a3*b1

25
We insert Dffs to avoid many levels of logic
b2 b1 b4 b3 + + + a4*b4 a4*b3 a4*b2 a4*b1

26
a1 a2 a3 b2 b1 b4 b3 + + + a4*b4 a4*b3+a3b4 a4*b2+a3b3 a3b1 a4*b1+a3b2

27
a1 a2 b2 b1 b4 b3 + + + a4*b4 a4*b3+a3b4 a4*b2+a3b3+a2b4 a4*b1+a3b2+a2b3 a2b1 a3b1+a2b2 The disadvantage of this circuit is broadcasting

28
We insert more Dffs to avoid broadcasting
b2 b1 b4 b3 + + + a4*b4

29
+ + + Does not work correctly like this, try something new…. a1 a2 a3
b2 b1 b4 b3 + + + a4*b4 a3b4 a4b3 Does not work correctly like this, try something new….

30
a1 a2 a3 a4 b2 b1 b4 b3 a1b2 a2b1 a1b3 a2b2 a3b1 a1b4 a2b3 a3b2 a4b1
b2 b1 b4 b3 a1b2 a2b1 a1b3 a2b2 a3b1 a1b4 a2b3 a3b2 a4b1 a2b4 a3b3 a4b2 a3b4 a4b3 Second sum a4*b4 First sum

31
FIR-filter like structure, assume two delays
b2 b1 b4 b3 + + +

32
b2 b1 b4 b3 + + +

33
b2 b1 b4 b3 + + +

34
b2 b1 b4 b3 + + +

35
b2 b1 b4 b3 + + +

36
b2 b1 b4 b3 + + +

37
b2 b1 b4 b3 + + +

38
b2 b1 b4 b3 + + +

39
b2 b1 b4 b3 + + +

40
b2 b1 b4 b3 + + +

41
b2 b1 b4 b3 + + +

42
b2 b1 b4 b3 + + +

43
b2 b1 b4 b3 + + +

44
b2 b1 b4 b3 + + +

45
Example 3: FIR Filter or Convolution

46
Example 3: Convolution Wi ain bout aout bin aout = ain
There are many ways to implement convolution using systolic arrays, one of them is shown: u(n) : The input of sequence from left. w(n) : The weights preloaded in n PEs. y(n) : The sequence from right (Initial value: 0) and having the same speed as u(n). In this operation each cell’s function is: 1. Multiply the inputs coming from left with weights and output the input received to the next cell. 2. Add the final value to the inputs from right. Wi ain bout aout bin aout = ain bout = bin + ain * wi W0 W1 W2 W3 ui……u0 yi……y0
 : The input of sequence from left. w(n) : The weights preloaded in n PEs. y(n) : The sequence from right (Initial value: 0) and having the same speed as u(n). In this operation each cell’s function is: 1. Multiply the inputs coming from left with weights and output the input received to the next cell. 2. Add the final value to the inputs from right. Wi. ain. bout. aout. bin. aout = ain. bout = bin + ain * wi. W0. W1. W2. W3. ui……u0. yi……y0.")
47
Convolution (cont) Systolic array. W0 W1 W2 W3 ui……u0 yi……y0
The input of sequence from left. W0 W1 W2 W3 ui……u0 yi……y0 Each cell operation. Wi ain bout aout bin aout = ain bout = bin + ain * wi This is just one solution to this problem

48
Various Possible Implementations
Convolution is very important, we use it in several applications. So let us think what are all the possible ways to implement it Two loops Convolution Algorithm Various Possible Implementations

49
Bag of Tricks that can be used
Preload-repeated-value Replace-feedback-with-register Internalize-data-flow Broadcast-common-input Propagate-common-input Retime-to-eliminate-broadcasting

50
Bogus Attempt at Systolic FIR
for i=1 to n in parallel for j=1 to k in place yi += wj * x i+j-1 Inner loop realized in place Stage 1: directly from equation Stage 2: feedback = yi = yi feedback from sequential implementation Stage 3: Replace with register

51
Bogus Attempt continued: Outer Loop
for i=1 to n in parallel for j=1 to k in place yi += wj * x i+j-1 Factorize wj

52
Bogus Attempt continued: Outer Loop - 2
for i=1 to n in parallel for j=1 to k in place yi += wj * x i+j-1 Because we do not want to have broadcast, we retime the signal w, this requires also retiming of X j

53
Bogus Attempt continued: Outer Loop - 2a
for i=1 to n in parallel for j=1 to k in place yi += wj * x i+j-1 Another possibility of retiming

54
Bogus Attempt continued: Outer Loop - 3
for i=1 to n in parallel for j=1 to k in place yi += wj * x i+j-1 Yet another approach is to broadcast common input x i-1

55
Attempt at Systolic FIR: now internal loop is in parallel
1 3 2
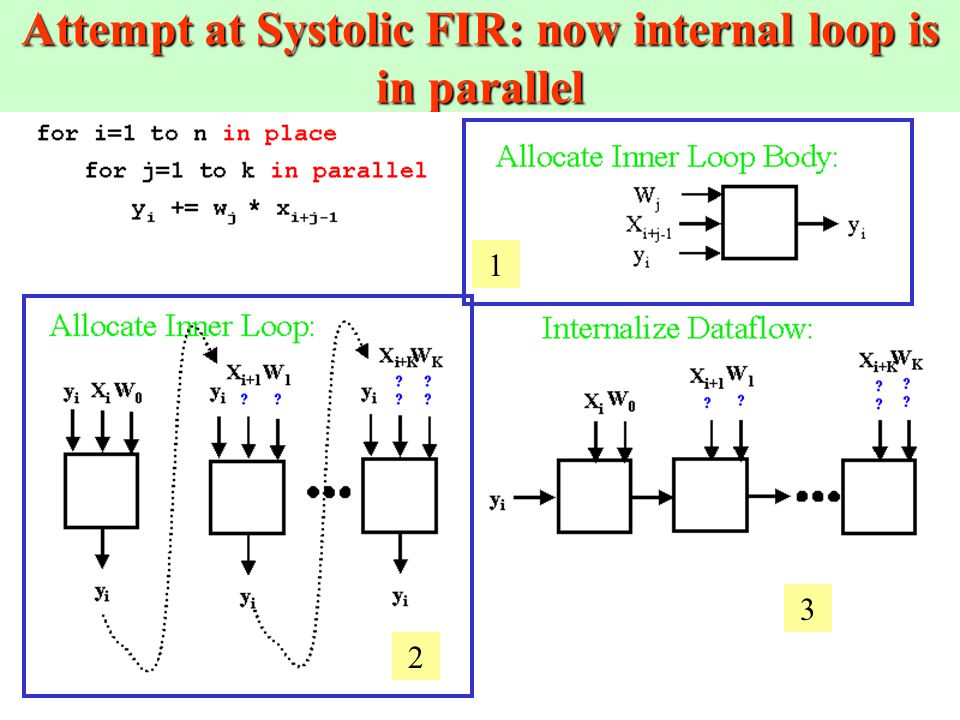
56
Outer Loop continuation for FIR filter

57
Continue: Optimize Outer Loop Preload-repeated Value
Based on previous slide we can preload weights Wi

58
Continue: Optimize Outer Loop Broadcast Common Value
This design has broadcast. Some purists tell this is not systolic as systolic should have all short wires.

59
Continue: Optimize Outer Loop Retime to Eliminate Broadcast
We delay these signals yi

60
The design becomes not intuitive
The design becomes not intuitive. Therefore, we have to explain in detail “How it works” y1=x1w1 y1=x1w1 x1 x2

61
Types of systolic structure
Polynomial Multiplication of 1-D convolution problem Types of systolic structure Convolution problem weight : {w1, w2, ..., wk} inputs : {x1, x2, ..., xn} results : {y1, y2, ..., yn+k-1} yi = w1xi + w2xi wkxi+k-1 (combining two data streams) H. T. Kung’s grouping work assume k = 3
 H. T. Kung’s grouping work. assume k = 3.")
62
A family of systolic designs for convolution computation
Given the sequence of weights {w1 , w2 , , wk} And the input sequence {x1 , x2 , , xk} , Compute the result sequence {y1 , y2 , , yn+1-k} Defined by yi = w1 xi + w2 xi wk xi+k-1

63
Design B1 - Broadcast input , move results systolically, weights stay
Previously proposed for circuits to implement a pattern matching processor and for circuit to implement polynomial multiplication. - Broadcast input , move results systolically, weights stay - (Semi-systolic convolution arrays with global data communication

64
Types of systolic structure: design B1
wider systolic path (partial result yi move) Please analyze this circuit drawing snapshots like in an animated movie of data in subsequent moments of time broadcast x3 x2 x1 y3 y2 y1 W1 W2 W3 yin xin yout yout = yin + W×xin W Results move out Discuss disadvantages of broadcast
 Please analyze this circuit drawing snapshots like in an animated movie of data in subsequent moments of time. broadcast. x3. x2. x1. y3. y2. y1. W1. W2. W3. yin. xin. yout. yout = yin + W×xin. W. Results move out. Discuss disadvantages of broadcast.")
65
Types of systolic structure: Design B2
Inputs broadcast Weights move Results stay wi circulate use multiplier-accumulator hardware wi has a tag bit (signals accumulator to output results) needs separate bus (or other global network for collecting output) x3 x2 x1 y1 y2 y3 W2 W3 W1 xin Win Wout y = y + Win×xin Wout = Win y
 needs separate bus (or other global network for collecting output) x3. x2. x1. y1. y2. y3. W2. W3. W1. xin. Win. Wout. y = y + Win×xin. Wout = Win. y.")
66
Design B2 Broadcast input , move weights , results stay
The path for moving yi’s is wider then wi’s because of yi’s carry more bits then wi’s in numerical accuracy. The use of multiplier-accumulators may also help increase precision of the result , since extra bit can be kept in these accumulators with modest cost. Broadcast input , move weights , results stay [(Semi-) systolic convolution arrays with global data communication] Semisystolic because of broadcast
 systolic convolution arrays with. global data communication] Semisystolic because of broadcast.")
67
Types of systolic structure: design F
Input move Weights stay Partial results fan-in needs adder applications : signal processing, pattern matching x3 x2 x1 W3 W2 W1 ADDER y1’s Zout xout xin W Zout = W×xin xout = xin

68
Design F - Fan-in results, move inputs, weights stay
When number of cell is large , the adder can be implemented as a pipelined adder tree to avoid large delay. Design of this type using unbounded fan-in. - Fan-in results, move inputs, weights stay - Semi-systolic convolution arrays with global data communication

69
Types of systolic structure: Design R1
Inputs and weights move in the opposite directions Results stay can use tag bit no bus (systolic output path is sufficient) one-half the cells are work at any time applications : pattern matching y = y + Win×xin xout = xin Wout = Win x1 x3 x2 W1 W2 y3 y2 y1 Win xin Wout y xout
 one-half the cells are work at any time. applications : pattern matching. y = y + Win×xin. xout = xin. Wout = Win. x1. x3. x2. W1. W2. y3. y2. y1. Win. xin. Wout. y. xout.")
70
Design R1 Design R1 has the advan-tage that it dose not require a bus , or any other global net-work , for collecting output from cells. The basic ideal of this de-sign has been used to imple-ment a pattern matching chip. - Results stay, inputs and weights move in opposite directions - Pure-systolic convolution arrays with global data communication

71
Types of systolic structure: design R2
Inputs and weights move in the same direction at different speeds Results stay xj’s move twice as fast as the wj’s all cells work at any time need additional registers (to hold w value) applications : pipeline multiplier W1 W2 W3 W4 W5 x3 x2 x1 y1 y2 y3 W y Win Wout xin xout y = y + Win×xin W = Win Wout = W xout = xin
 applications : pipeline multiplier. W1. W2. W3. W4. W5. x3. x2. x1. y1. y2. y3. W. y. Win. Wout. xin. xout. y = y + Win×xin. W = Win. Wout = W. xout = xin.")
72
Design R2 - Results stay , inputs and weights move in the
Multiplier-accumulator can be used effectively and so can tag bit method to signal the output of each cell. Compared with R1 , all cells work all the time when additional register in each cell to hold a w value. - Results stay , inputs and weights move in the same direction but at different speeds - Pure-systolic convolution arrays with global data communication

73
Types of systolic structure: design W1
Inputs and results move in the opposite direction Weights stay one-half the cells are work constant response time applications : polynomial division x1 x3 x2 W1 W2 y W3 yin xin yout W xout yout = yin + W×xin xout = xin

74
Design W1 -Weights stay, inputs and results move in opposite direction
This design is fundamental in the sense that it can be naturally extend to perform recursive filtering. This design suffers the same drawback as R1 , only appro-ximately 1/2 cells work at any given time unless two inde-pendent computation are in-terleaved in the same array. -Weights stay, inputs and results move in opposite direction - Pure-systolic convolution arrays with global data communication

75
Overlapping the executions of multiply-and-add in design W1

76
Types of systolic structure: design W2
Inputs and results move in the same direction at different speeds Weights stay all cells work (high throughputs rather than fast response) W1 W2 x5 W3 x7 x3 x2 x1 y1 y2 y3 W x4 x6 x W xin xout yin yout yout = yin + Win×xin x = xin xout = x
 W1. W2. x5. W3. x7. x3. x2. x1. y1. y2. y3. W. x4. x6. x. W. xin. xout. yin. yout. yout = yin + Win×xin. x = xin. xout = x.")
77
Design W2 - Pure-systolic convolution arrays with
This design lose one advan-tage of W1 , the constant response time. This design has been extended to implement 2-D convolution , where high throughputs rather than fast response are of concern. -Weights stay, inputs and results move in the same direction but at different speeds - Pure-systolic convolution arrays with global data communication

78
Remarks on Linear Arrays
Above designs are all possible systolic designs for the convolution problem. (some are semi-) Using a systolic control path , weight can be selected on- the-fly to implement interpolation or adaptive filtering. We need to understand precisely the strengths and drawbacks of each design so that an appropriate design can be selected for a given environment. For improving throughput, it may be worthwhile to implement multiplier and adder separately to allow overlapping of their execution. (Such as next page show) When chip pin is considered: pure-systolic requires four I/O ports; semi-systolic requires three I/O ports.
 Using a systolic control path , weight can be selected on- the-fly to implement interpolation or adaptive filtering. We need to understand precisely the strengths and. drawbacks of each design so that an appropriate design. can be selected for a given environment. For improving throughput, it may be worthwhile to. implement multiplier and adder separately to allow. overlapping of their execution. (Such as next page show) When chip pin is considered: pure-systolic requires four I/O ports; semi-systolic requires three I/O ports.")
79
FIR circuit: initial design
Pipelining of xi delays

80
FIR circuit: registers added below weight multipliers
Notice changed timing here

81
FIR Summary: comparison of sequential and systolic

82
Conclusions on 1D and 1.5D Systolic Arrays
Systolic arrays are more than processor arrays which execute systolic algorithms. A systolic cell takes on one of the following forms: A special purpose cell with hardwired functions, A vector-computer-like cell with instruction decoding and a processing element, A systolic processor complete with a control unit and a processing unit. Smarter processor for SAT, Petrick, etc.

83
Large Systolic Arrays as general purpose computers
Originally, systolic architectures were motivated for high performance special purpose computational systems that meet the constraints of VLSI, However, it is possible to design systolic systems which: have high throughputs yet are not constrained to a single VLSI chip.

84
Problems with systolic array design
1. Hard to design - hard to understand low level realization may be hard to realize 2. Hard to explain remote from the algorithm function can’t readily be deduced from the structure 3. Hard to verify

85
Key architectural issues in designing special-purpose systems
Simple and regular design Simple, regular design yields cost-effective special systems. Concurrency and communication Design algorithm to support high concurrency and meantime to employ only simple blocks. Balancing computation with I/O A special-purpose system should be a match to a variety of I/O bandwidths.

86
Two Dimensional Systolic Arrays
In 1978, the first systolic arrays were introduced as a feasible design for special purpose devices which meet the VLSI constraints. These special purpose devices were able to perform four types of matrix operations at high processing speeds: matrix-vector multiplication, matrix-matrix multiplication, LU-decomposition of a matrix, Solution of triangular linear systems.

87
General Systolic Organization

88
Example 2: Matrix-Matrix Multiplication
All previously shown tricks can be applied Example 2: Matrix-Matrix Multiplication

89
Sources Seth Copen Goldstein, CMU A.R. Hurson 2. David E. Culler, UC. Berkeley, Syeda Mohsina Afroze and other students of Advanced Logic Synthesis, ECE 572, 1999 and 2000.

Similar presentations




. But we also need cells that can be designed to fit the specific.>")




.>")
.>")








