Download presentation
Presentation is loading. Please wait.

1
“Improving Pronunciation Dictionary Coverage of Names by Modelling Spelling Variation” - Justin Fackrell and Wojciech Skut Presented by Han

2
The Problem: The pronunciation of out-of-vocabulary (OOV) words is a major problem in TTS. Many OOV words are names. For English names, the orthography for names is highly irregular. Current methods of approaching this problem has low accuracy. –Using hand-written or automatically learned rules to replace a sequence of graphemes by a sequence of phonemes.

3
The Challenge

4
Their Method Scope: English surnames, forenames, street names and place names. Based on: the observation that some of the words in the above categories have same pronunciation, but slightly different spelling. Approach: learn from existing data (data- driven) of the rules of these variations, so that next time we see an OOV word, we will try to apply these rules and see if we can transform that word into an IOV word.
 of the rules of these variations, so that next time we see an OOV word, we will try to apply these rules and see if we can transform that word into an IOV word..")
5
Different Orthographical Expressions for the Same Pronunciation

6
Hypothesis Given a name that’s not in the dictionary, there’s about 10% chance that it DOES have a valid pronunciation in the dictionary. We have to somehow map it to a valid in-dictionary word.

7
A Hierarchical Approach Dictionary Filter 1 Filter 2 etc.

8
Two Ways of Using This Method and Their Results Online –Results suggested pronunciations are good in 80% of cases. Offline –For surnames, a model trained on a 23,000- entry dictionary was able to add 5,000 new entries, increasing the coverage by about 1%.

9
The Algorithm (Part I) Training 1) reverse dictionary (pron -> ortho) 2) delete one-to-one mappings 3) Each pair of spellings that share a common pronunciation generates a set of rewrite rules, r i where i = 0 to n, in the form of “A -> B / L _ R”
 Training 1) reverse dictionary (pron -> ortho) 2) delete one-to-one mappings 3) Each pair of spellings that share a common pronunciation generates a set of rewrite rules, r i where i = 0 to n, in the form of A -> B / L _ R")
10
The Algorithm (Part I) Training
 Training")
11
Each rule, r i, is then evaluated on the rest of the dictionary to see how useful it is. –MISS –OOV –DIFF –GOOD And gets four scores: n i MISS, n i OOV, n i DIFF, and n i GOOD From each set of rules generated by a pair, only one rule is chosen: shortest and n i DIFF =0.

12
The Algorithm (Part I) Predication Sort all rules by score. When given an OOV word, use the rule with the highest score that can map it into an IOV word.

13
Some Examples of Resulted Rewrite Rules

14
Some Results

15
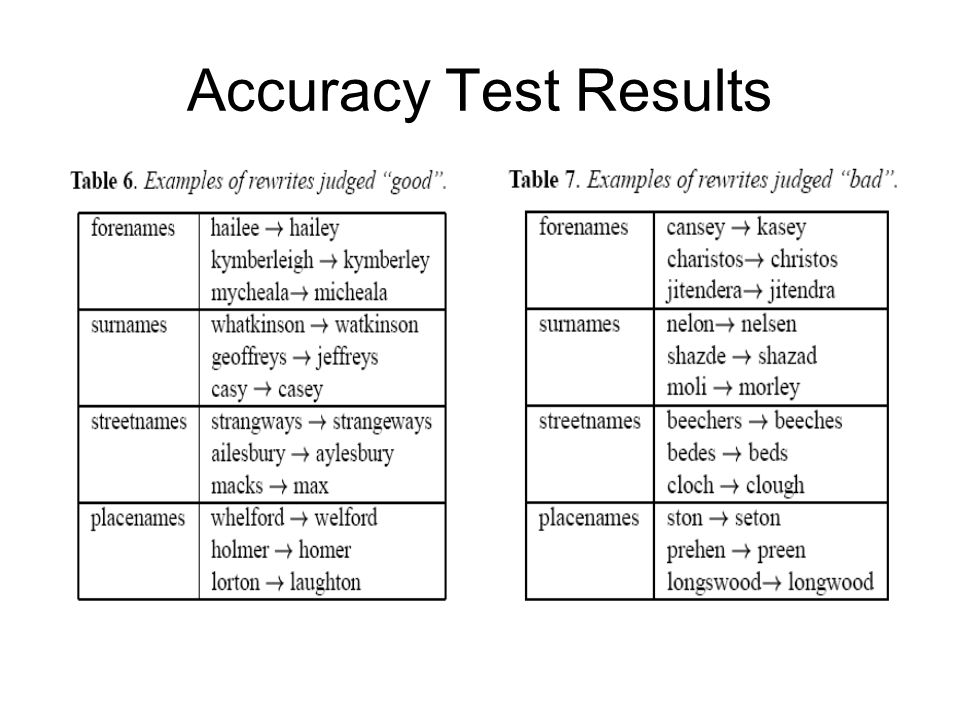
Accuracy Test Results

Similar presentations











 LING 572 Fei Xia 1/19/06.>")







