Download presentation
Presentation is loading. Please wait.

1
CS420 lecture six Loops

2
Time Analysis of loops Often easy: eg bubble sort for i in 1..(n-1) for j in 1..(n-i) if (A[j] > A[j+1) swap(A,j,j+1) 1. loop body takes constant time 2. loop body is executed times
![Time Analysis of loops Often easy: eg bubble sort for i in 1..(n-1) for j in 1..(n-i) if (A[j] > A[j+1) swap(A,j,j+1) 1.](http://images.slideplayer.com/15/4551087/slides/slide_2.jpg "loop body takes constant time 2. loop body is executed times.")
3
Convex hull Given a set of points in 2D ((x,y) coordinates), find the smallest convex polygon surrounding them all.
 coordinates), find the smallest convex polygon surrounding them all.")
5
Convex hull Given a set of points in 2D ((x,y) coordinates), find the smallest polygon surrounding them all. The problem reduces to finding line segments connecting points of the set.

6
Convex hull

7
Convex hull: first attempt Let L be a line segment connecting two points in the set. For L to be in the convex hull it is sufficient that all other points are on the same side of L’s extension to a full line.

8
Convex hull: first attempt Let L be a line segment connecting two points in the set. For L to be in the convex hull it is sufficient that all other points are on the same side of L’s extension to a full line. How do you find out all other points are on the same side?

9
Convex hull: first attempt Let L be a line segment connecting two points in the set. For L to be in the convex hull it is sufficient that all other points are on the same side of L’s extension to a full line. for i = 1 to n for j= i+1 to n for k = 1 to n if (k!=i&&k!=j) check(p i,p j,p k )
 check(p i,p j,p k ).")
10
Convex hull: first attempt for i = 1 to n for j= i+1 to n for k = 1 to n if (k!=i&&k!=j) check(p i,p j,p k ) check is O(1) so this algorithm is O(n 3 )
 check(p i,p j,p k ) check is O(1) so this algorithm is O(n 3 )")
11
the question that drives us.....

12
is there a better algorithm Find lowest point P1 Sort remaining points by angle they form with P1 and the horizontal, resulting in a sequence P2…Pn Start with P1-P2 in current hull for i from 3 to n add Pi in current hull for j from i-1 downto 3 eliminate Pj if P1 and Pi are on different side of line Pj-P(j-1); if Pj stays break
; if Pj stays break")
13
is there a better algorithm Find lowest point P1 Sort remaining points by angle they form with P1 and the horizontal, resulting in a sequence P2…Pn Start with P1-P2 in current hull for i from 3 to n add Pi in current hull for j from i-1 downto 3 eliminate Pj if P1 and Pi are on different side of line Pj-P(j-1); if Pj stays break 1 3 2 4
; if Pj stays break")
14
Complexity? find lowest: O(n) sort O(nlgn) nested add/eliminate loop outer: i from 3 to n inner: j from i-1 downto 3 O(?)
 sort O(nlgn) nested add/eliminate loop outer: i from 3 to n inner: j from i-1 downto 3 O( ).")
15
nested add/eliminate loop O(N) !! why? n-2 points considered in i loop j loop either eliminates a point, ie it will not be checked again, or stops. The total number of points considered in all j loop iterations is therefore O(n) Complex hull algorithm complexity O(n lg n)
 Complex hull algorithm complexity O(n lg n).")
16
is there a better algorithm? no

17
is there a better algorithm? no, argument is harder (lower bound arguments usually are) it can be shown that sorting can be reduced to convex hull (reduced: translated such that when the convex hull problem is solved the original sorting problem is solved) and we have shown that sorting is Ω(n lg n)
 it can be shown that sorting can be reduced to convex hull (reduced: translated such that when the convex hull problem is solved the original sorting problem is solved) and we have shown that sorting is Ω(n lg n).")
18
sort({3, 1, 2}) convex hull({(3,9), (2,4), (1,1)}) 3,9 2,4 1,1 reduction: x x,x 2
 convex hull({(3,9), (2,4), (1,1)}) 3,9 2,4 1,1 reduction: x x,x 2")
19
Sub-O Optimizations Suppose you have written an asymptotically optimal program, and still want to speed it up. Using a profiler identify which parts of your code are the hotspots of your program. 10/90 rule of thumb: 90% of the time is spent in 10% of the code: hotspots – Usually some of the innermost loops – Only improve the hotspots. Leave the rest clear and simple.

20
Data reorganization Create sentinel (value at boundary) to simplify loop control. found = false; i=0; while (i<n and not found) if (x[i]==T) found = true; else i++;
 if (x[i]==T) found = true; else i++;.")
21
Data reorganization Create sentinel to simplify loop control. found = false; i=0; while (i<n and not found) if (x[i]==T) found = true; else i++; Sentinel: value at boundary x[n]=T; i=0; while (x[i]!=T)i++; found = (i<n);
 if (x[i]==T) found = true; else i++; Sentinel: value at boundary x[n]=T; i=0; while (x[i]!=T)i++; found = (i<n);.")
22
Loop unrolling Loop unrolling is textually repeating the loop body so that the loop control is executed fewer times – Eg, a median filter operator on an image executes a 3x3 inner loop for each resulting pixel; this can be fully unrolled – some compilers (eg CUDA) allow unroll k pragmas – in a linked list, if the last element points at itself, visiting the elements can be partially unrolled
 allow unroll k pragmas – in a linked list, if the last element points at itself, visiting the elements can be partially unrolled")
23
Loop peeling When the body of a loop tests whether it is on a boundary, and has a special case for that boundary, it is often advantageous to have separate code for the boundary avoiding the conditional in the loop body. Eg, median filter

24
Loop unrolling and trivial assignments fibonacci(n) a=b=c =1; // what happens if the loop gets unrolled once? for i = 3 to n { c=a+b, a=b; b=c } return c;

25
Loop unrolling and trivial assignments fibonacci(n) a=b=c =1; for i = 3 to n { c=a+b, a=b; b=c } return c; fibonacci(n) a=b=1; for i = 1 to (n/2 -1) {a=a+b; b=a+b} if odd(n) b = a+b; return b;
 a=b=c =1; for i = 3 to n { c=a+b, a=b; b=c } return c; fibonacci(n) a=b=1; for i = 1 to (n/2 -1) {a=a+b; b=a+b} if odd(n) b = a+b; return b;")
26
Memory hierarchy (cache) issues Processor are an order of magnitude faster than memories – both have been speeding up exponentially for ~30 years: but with different bases, so their ratio has been growing exponentially as well – caches keep recently used (temporal locality) and fetch in cache lines (spatial locality)
 issues Processor are an order of magnitude faster than memories – both have been speeding up exponentially for ~30 years: but with different bases, so their ratio has been growing exponentially as well – caches keep recently used (temporal locality) and fetch in cache lines (spatial locality)")
27
cache issues memory wall getting over it: cache cache line cache replacement policy: LRU cache and memory layout of 1D representation of 2D arrays in C – row access – col access

28
Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j]
![Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j]](http://images.slideplayer.com/15/4551087/slides/slide_28.jpg "Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j]")
29
Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j] B is accessed in column order. If the arrays are (as in C) stored in row major order, this causes cache misses and unnecessary reads!!
![Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j] B is accessed in column order.](http://images.slideplayer.com/15/4551087/slides/slide_29.jpg "If the arrays are (as in C) stored in row major order, this causes cache misses and unnecessary reads!!.")
30
Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j] While one row of A is read, all of B is read If the cache cannot keep all of B and uses the Least Recently Used replace policy, all reads of B will cause a cache miss
![Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j] While one row of A is read, all of B is read If the cache cannot keep all of B and uses the Least Recently Used replace policy, all reads of B will cause a cache miss](http://images.slideplayer.com/15/4551087/slides/slide_30.jpg "Data or loop reordering for improve cache performance Matrix multiply: for i = 1 to n for j= 1 to n C[i,j]=0 for k = 1 to n C[i,j]+=A[i,k]*B[k,j] While one row of A is read, all of B is read If the cache cannot keep all of B and uses the Least Recently Used replace policy, all reads of B will cause a cache miss")
31
Tiling for improved cache behavior Instead of reading a whole row of A and doing n whole row A column B inner products we can read a block of A and compute smaller inner products with sub columns of B. (Remember blocked matrix multiply in Strassen) These partial products are then added up.
 These partial products are then added up..")
32
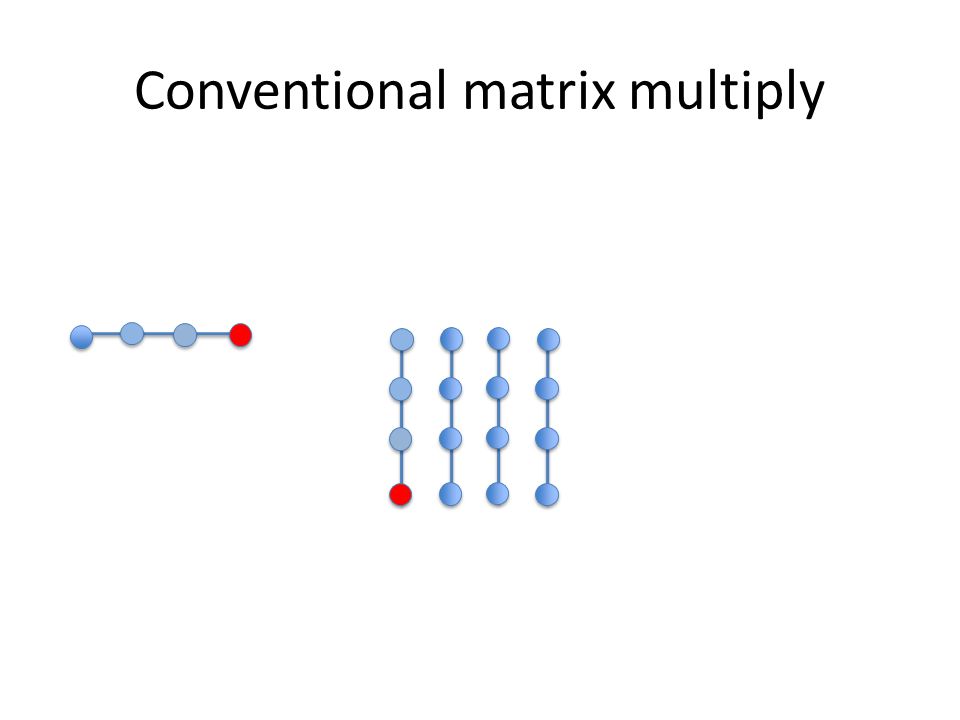
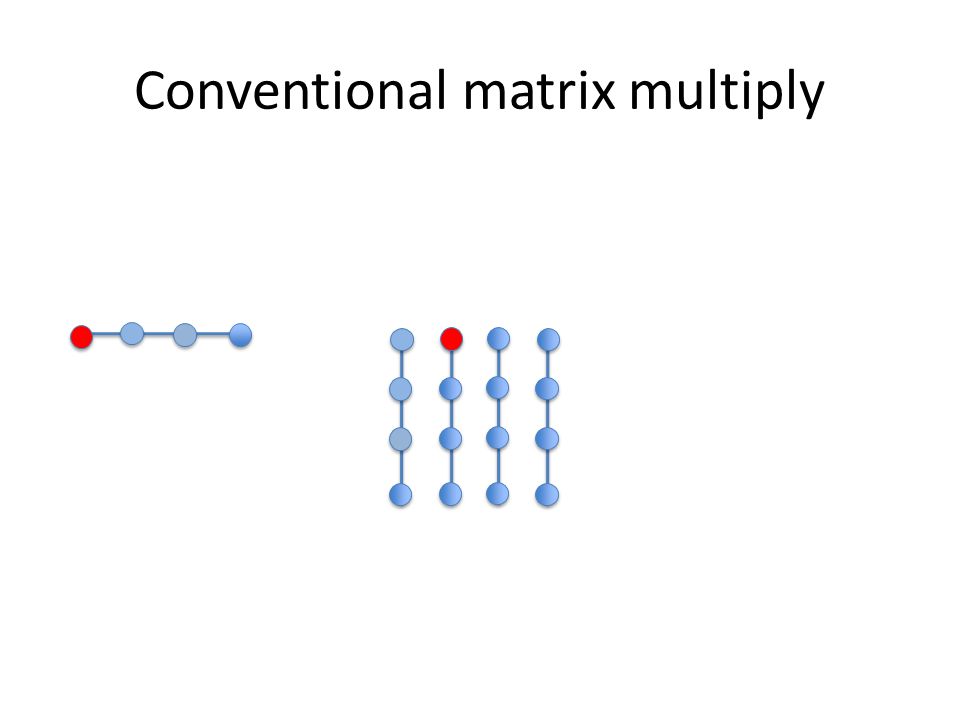
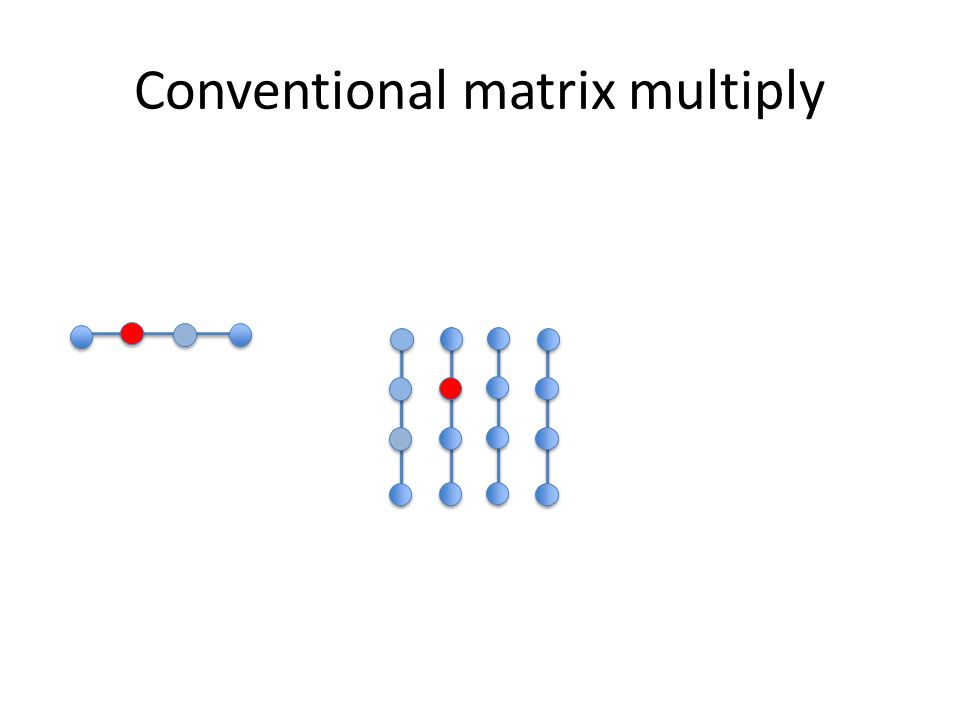
Conventional matrix multiply

38
etc......

39
Conventional matrix multiply All elements of B are used once, while all of row A[i] are used n times. A[i] may fit in the cache, B will probably not!
![Conventional matrix multiply All elements of B are used once, while all of row A[i] are used n times.](http://images.slideplayer.com/15/4551087/slides/slide_39.jpg "A[i] may fit in the cache, B will probably not!.")
40
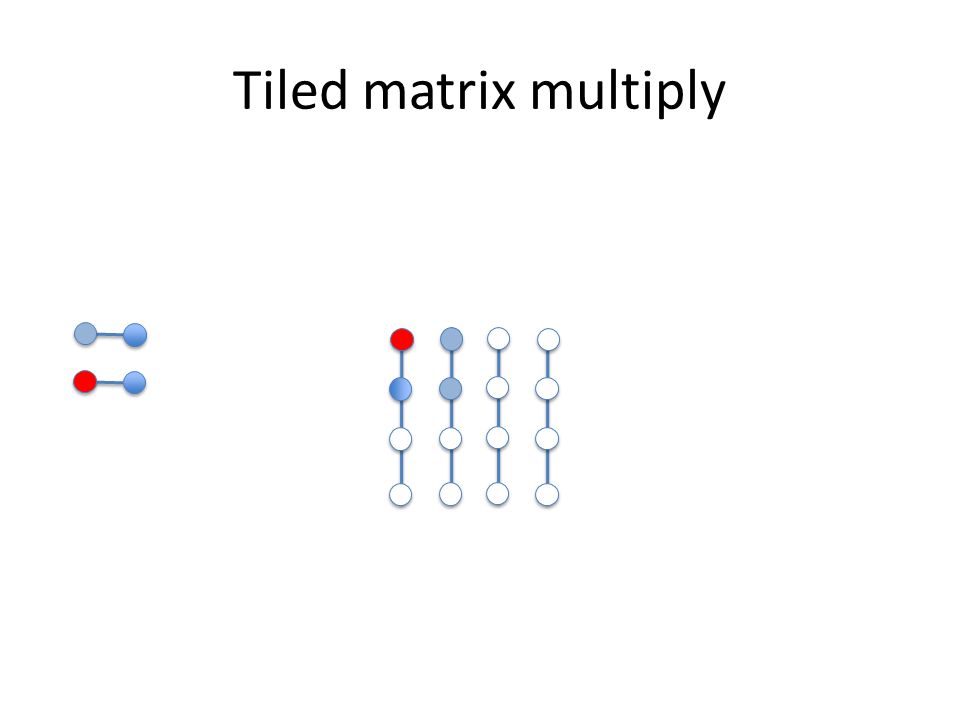
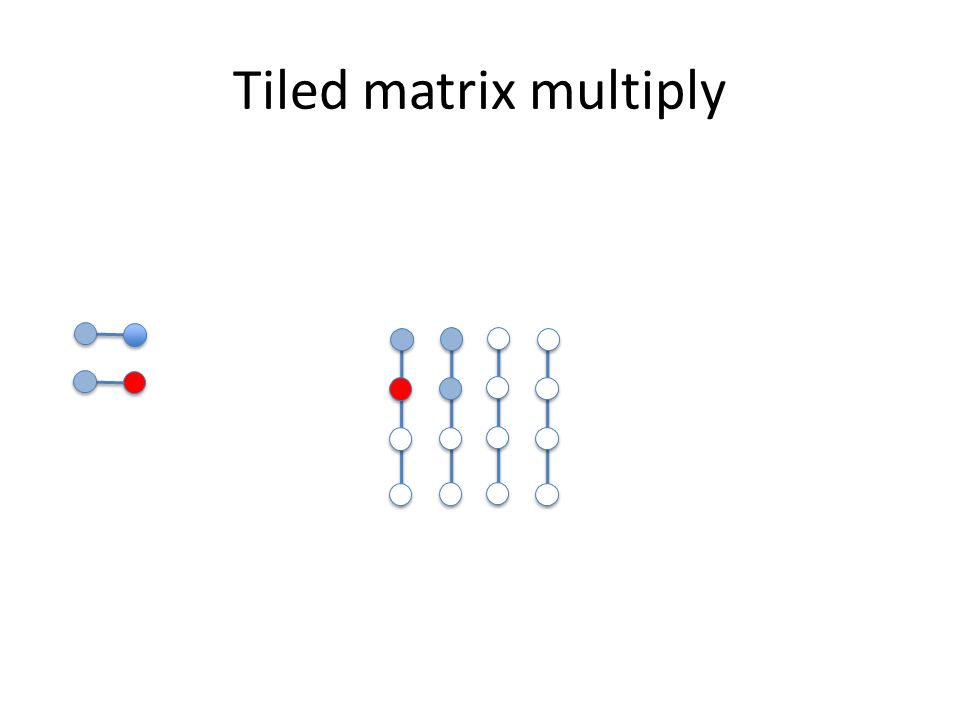
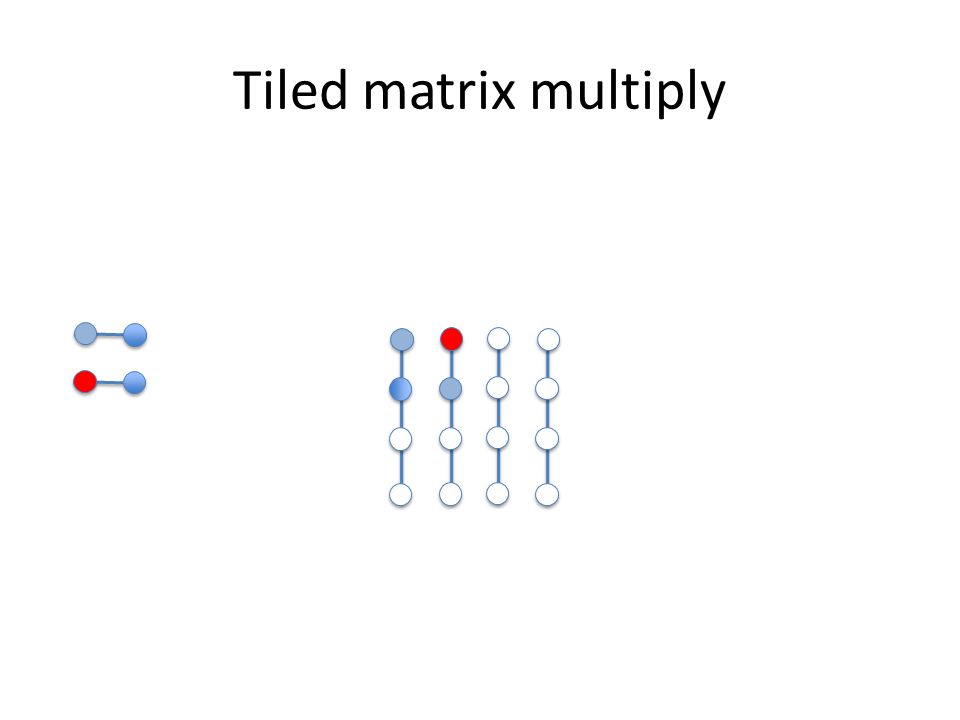
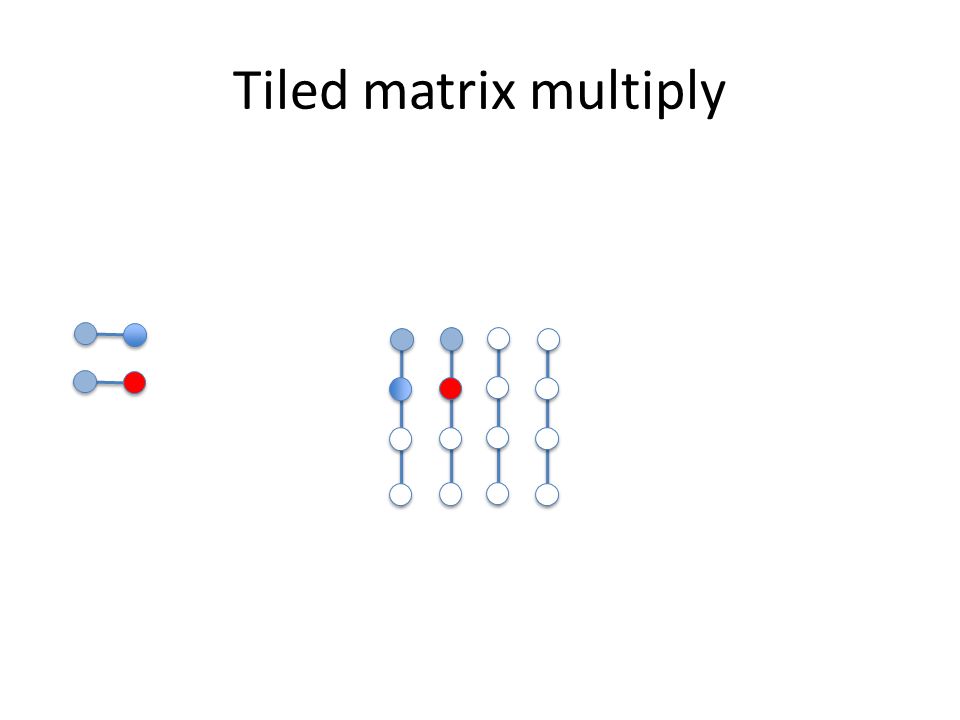
Tiled matrix multiply

49
Reuse of tile of B A k x k tile of A (which can fit in the cache) block multiplies with a k x k tile of B (which can fit in the cache) and thus reuses the B tile k times, potentially providing better cache use We can parameterize our program with k and experiment Data and loop reordering matrix multiply: assignment 2
 block multiplies with a k x k tile of B (which can fit in the cache) and thus reuses the B tile k times, potentially providing better cache use We can parameterize our program with k and experiment Data and loop reordering matrix multiply: assignment 2")
50
Experiments you can do Transpose B for better cache line behavior Tile the loop as in the example In array access A[i*N+j] avoid the multiply by doing pointer increments and dereferences You will have a number of versions of your code. Make a 2D table of results. Then make observations about your results. In a follow up discussion, exchange your experiences
![Experiments you can do Transpose B for better cache line behavior Tile the loop as in the example In array access A[i*N+j] avoid the multiply by doing pointer increments and dereferences You will have a number of versions of your code.](http://images.slideplayer.com/15/4551087/slides/slide_50.jpg "Make a 2D table of results. Then make observations about your results. In a follow up discussion, exchange your experiences.")
51
Tiling Loops become nested loops – outer loop visits tile origins – inner loops visit the tile points

52
Can every loop be tiled??? Tile this for i=1 to n for j=1 to n if (i==1 && j==1) A[i,j]=1 elif j==1 A[i,j]=A[i-1,n] else A[i,j]=A[i,j-1]
 A[i,j]=1 elif j==1 A[i,j]=A[i-1,n] else A[i,j]=A[i,j-1].")
53
Tiling cont' Tiling is loop reordering. The reordered loop must obey the data dependences in the original loop. Let iteration i',j',k' occur before iteration i,j,k – true dependence: i,j,k uses a value that i',j',k produced – anti dependence: i,j,k redefines a value that i',j',k' used – output dependence: i,j,k redefines a value that i',j',k' defined in all these cases the reordered loop must obey the original ordering of the two iterations.

Similar presentations








 Parallelism & Locality Optimization.>")



 Graham scan Divide and conquer Convex Hull for line intersections.>")






>")
>")

 Jan Maluszynski - HT 20068.1 Sorting: –Intro: aspects of sorting, different strategies –Insertion.>")
>")
. Lecture Outline Memory Hierarchy Management Register Allocation –Register interference graph –Graph coloring.>")

